
- 1模型迁移学习:将知识迁移到新领域
- 2数据结构【顺序表】
- 3二叉树总结_new treenode
- 4【正点原子STM32连载】 第九章 STM32启动过程分析 摘自【正点原子】MiniPro STM32H750 开发指南_V1.1_正点原子stm32h7驱动
- 5Oracle Linux ISO 全系列下载地址_oracle linux 下载
- 6HiveSQL常用优化技巧_大数据hive sql优化
- 7幕后的谢尔曼:如何在Unity中创建电影品质的照明
- 8找不到xinput1_3.dll要怎么去处理?全面分析四种修复xinput1_3.dll的方法
- 9java: Annotation processing is not supported for module cycles. Please ensure that all modules......
- 10基于Python卷积神经网络人脸识别驾驶员疲劳检测与预警系统设计-计算机毕业源码设计_面部疲劳检测算法
布隆过滤器(BloomFilter)原理 | 亿级数据过滤解决方案_处理百亿数据 过滤器
赞
踩
1970 年,布隆先生提出了一种很优秀的过滤器算法,用来判断一个元素是否在集合中
「布隆过滤器算法」
故事开始→_→
先看本故事结构
就当前互联网环境来说,头部的互联网生态越来越往高并发、分布式的形态发展。举例来说,各大网页的黑名单系统,爬虫的重复率判断。这些场景越来越多。
举例来说,实时状态下可能会对超过百亿级别的 URL 需要进行判断是否符合规范或者存在于系统中,能否正常使用。
通常情况下,每个 URL 的大小为 64B(字节),那么就按照100亿的 URL 数量来看,大概需要640GB的内存容量【 64 × 100 亿 / 102 4 3 64 \times 100\text{亿}/1024^3 64×100亿/10243】,对于当前线上服务器来说,… 这个值依然还是很大的!但如果利用布隆过滤器的优势,在没有失误率的情况下只需要100亿个比特,即:1.2GB,即使为了降低失误率,也不会超过几十GB的空间【失误率后面会谈到】
那么在这种情况下,利用布隆过滤器来解决的确是很优秀,优秀到维基百科这样说「它的优点是空间效率和查询时间都远远超过一般的算法」,空间复杂度和时间复杂度都远超一般的算法,布隆过滤器存储空间和插入/查询时间都是常数O(1)!注意:远超!!
看着来自各方面这么牛B 的吹嘘,咱们把布隆过滤器安排到方方面面,来具体看看它的原理是怎么样的…
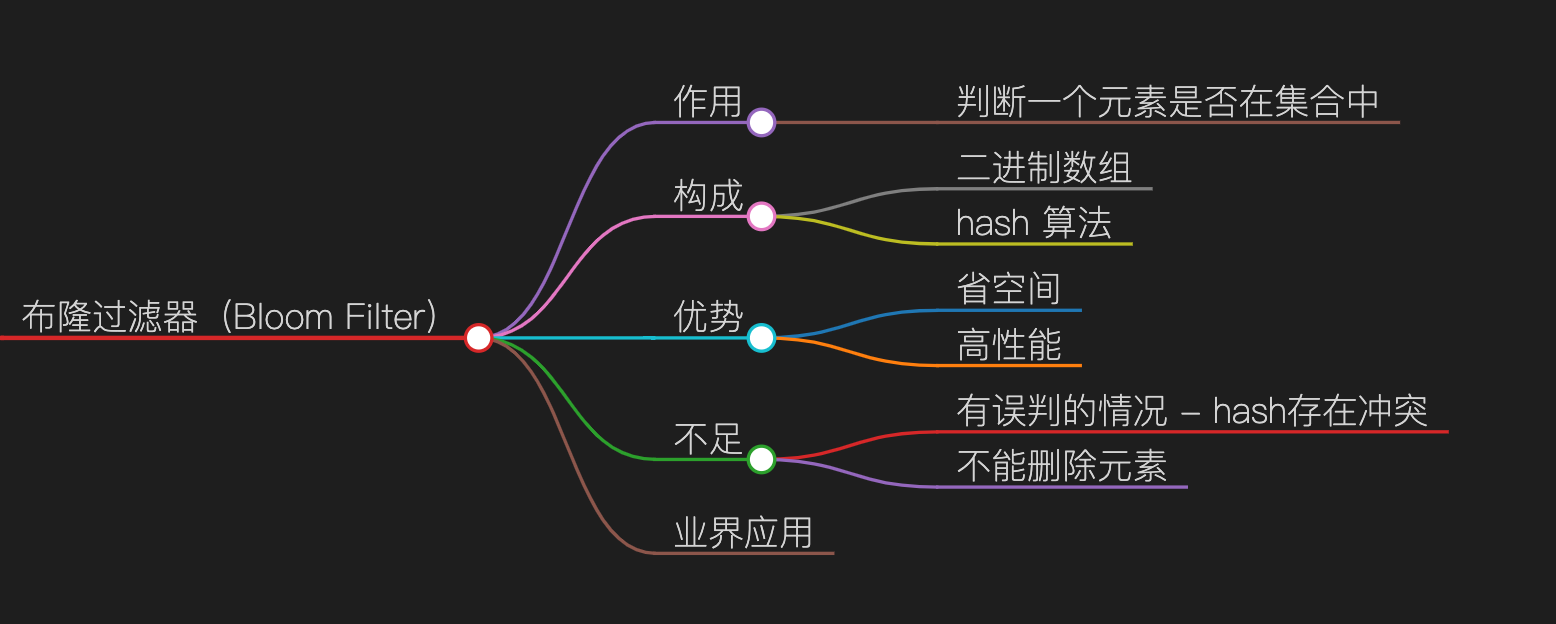
维基百科的概念:布隆过滤器实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。基于这个解释,下面从
等方面系统性的说道说道…
【1】
主要作用:判断一个元素是否在集合中
这样的场景会有很多。会去判断,要查询的元素是否存在于集合当中。【该网站是否允许该用户登录、该网站共是否接受这样的 url 请求】
通常在查询的时候,一般会先从 cache 中进行查询,如果没有的话会直接到磁盘或者数据库查询,这样的方式看起来很合理,但是如果在中间再加一层布隆顾虑器,这样就会更加合理了!为什么?
假设要查询的一个元素,而该元素不存在
a. 如果没有 BloomFilter,从cache中查询完就会直接到数据库做查询了,这样带来的现象是“慢”,毕竟从库中查耗时是比较长的,很大程度上对服务的性能产生影响。
b. 中间存在 BloomFilter,从cache中查询完就会首先查询 BloomFilter,就会发现该元素不存在,就可以不往后面进行查询了,而 BloomFilter 的性能是极其优越的。这样,对于机器或者说服务性能避免了很大不

