
- 1Payoneer注册、收款、提现常见问题_payoneer提现手续费
- 2PCL库教程_pcl教程
- 3面试题整理_es查看执行计划
- 4李宏毅LLM——生成式学习的两种策略_llm生成式 模板 学习
- 5ChatGPT又多了一个强有力的竞争对手:Meta发布Llama 3开源模型!附体验地址_meta ai llama 3模型下载
- 6Redux详解(二)
- 7Linux部署自动化运维平台Spug_运维自动部署平台
- 8jmeter最大请求数_jmeter 测试某网页最大并发用户数;
- 9【Thunder送书 | 第三期 】「Python系列丛书」_python从入门到精通(微课精编版)怎么样
- 10微信小程序点餐系统的开发与实现_基于微信小程序点餐系统设计与实现
Pytorch学习笔记(1):基本概念、安装、张量操作、逻辑回归
赞
踩

目录
一、Pytorch简介
1.1Pytorch的诞生
2017 年 1 月,FAIR(Facebook AI Research)发布了 PyTorch。PyTorch 是在 Torch 基础上用 python 语言重新打造的一款深度学习框架。Torch 是采用 Lua 语言为接口的机器学习框架,但是因为 Lua 语言较为小众,导致 Torch 学习成本高,因此知名度不高。
1.2Pytorch的发展
- 2017 年 1 月正式发布 PyTorch。
- 2018 年 4 月更新 0.4.0 版,支持 Windows 系统,caffe2 正式并入 PyTorch。
- 2018 年 11 月更新 1.0 稳定版,已成为 Github 上增长第二快的开源项目。
- 2019 年 5 月更新 1.1.0 版,支持 TensorBoard,增强可视化功能。
- 2019 年 8 月更新 1.2.0 版,更新 Torchvision,torchaudio 和 torchtext,支持更多功能。
- 目前 PyTorch 有超越 Tensorflow 的趋势。
1.3Pytorch的优点
- 上手快,掌握 Numpy 和基本深度学习概念即可上手。
- 代码简洁灵活,使用 nn.Module 封装使得网络搭建更加方便 。基于动态图机制,更加灵活。
- 资源多,arXiv 中新论文的算法大多有 PyTorch 实现。
- 开发者多,Github 上贡献者(Contributors)已经超过 1100+
1.4 Pytorch实现模型训练的 5 大要素
- 数据:包括数据读取,数据清洗,进行数据划分和数据预处理,比如读取图片如何预处理及数据增强。
- 模型:包括构建模型模块,组织复杂网络,初始化网络参数,定义网络层。
- 损失函数:包括创建损失函数,设置损失函数超参数,根据不同任务选择合适的损失函数。
- 优化器:包括根据梯度使用某种优化器更新参数,管理模型参数,管理多个参数组实现不同学习率,调整学习率。
- 迭代训练:组织上面 4 个模块进行反复训练。包括观察训练效果,绘制 Loss/ Accuracy 曲线,用 TensorBoard 进行可视化分析。
1.5Pytorch主要模块
| torch模块 | 包含激活函数和主要的张量操作 |
| torch.Tensor模块 | 定义了张量的数据类型(整型、浮点型等)另外张量的某个类方法会返回新的张量,如果方法后缀带下划线,就会修改张量本身。比如Tensor.add是当前张量和别的张量做加法,返回新的张量。如果是ensor.add_就是将加和的张量结果赋值给当前张量。 |
| torch.cuda | 定义了CUDA运算相关的函数。如检查CUDA是否可用及序号,清除其缓存、设置GPU计算流stream等。 |
| torch.nn | 神经网络模块化的核心,包括卷积神经网络nn.ConvNd和全连接层(线性层)nn.Linear等,以及一系列的损失函数。 |
| torch,nn.functional | 定义神经网络相关的函数,例如卷积函数、池化函数、log_softmax函数等部分激活函数。torch.nn模块一般会调用torch.nn.functional的函数。 |
| torch.nn.init | 权重初始化模块。包括均匀初始化torch.nn.init.uniform_和正态分布归一化torch.nn.init.normal_。(_表示直接修改原张量的数值并返回) |
| torch.optim | 定义一系列优化器,如optim.SGD、optim.Adam、optim.AdamW等。以及学习率调度器torch.optim.lr_scheduler。并可以实现多种学习率衰减方法等。具体参考官方教程。 |
| torch.autograd | 自动微分算法模块。定义一系列自动微分函数,例如torch.autograd.backward反向传播函数和torch.autograd.grad求导函数(一个标量张量对另一个张量求导)。以及设置不求导部分。 |
| torch.distributed | 分布式计算模块。设定并行运算环境 |
| torch.distributions | 强化学习等需要的策略梯度法(概率采样计算图) 无法直接对离散采样结果求导,这个模块可以解决这个问题 |
| torch.hub | 提供一系列预训练模型给用户使用。torch.hub.list获取模型的checkpoint,torch.hub.load来加载对应模型。 |
| torch.random | 保存和设置随机数生成器。manual_seed设置随机数种子,initial_seed设置程序初始化种子。set_rng_state设置当前随机数生成器状态,get_rng_state获取前随机数生成器状态。设置统一的随机数种子,可以测试不同神经网络的表现,方便进行调试。 |
| torch.jit | 动态图转静态图,保存后被其他前端支持(C++等)。关联的还有torch.onnx(深度学习模型描述文件,用于和其它深度学习框架进行模型交换) |
| torch.utils.benchmark | 记录深度学习模型中各模块运行时间,通过优化运行时间,来优化模型性能 |
| torch.utils.checkpoint | 以计算时间换空间,优化模型性能。因为反向传播时,需要保存中间数据,大大增加内存消耗。此模块可以记录中间数据计算过程,然后丢弃中间数据,用的时候再重新计算。这样可以提高batch_size,使模型性能和优化更稳定。 |
| torch.utils.data | 主要是Dataset和DataLoader。 |
| torch.utils.tensorboard | pytorch对tensorboard的数据可视化支持工具。显示模型训练过程中的 损失函数和张量权重的直方图,以及中间输出的文本、视频等。方便调试程序。 |
二、Pytorch的安装
安装过程推荐大家看我同门的这篇文章,步骤非常详细:Win11上Pytorch的安装并在Pycharm上调用PyTorch最新超详细_win11安装pytorch
三、张量的简介与创建
3.1张量的简介
(1)概念
张量(Tensor),是Pytorch中最基础的概念。Pytorch提供专门的torch.Tensor类,根据张量的数据格式和存储设备(CPU/GPU)来存储张量。Tensors 类似于Numpy 的 ndarrays ,同时 Tensors 可以使用 GPU 进行计算。
简单来说,张量就是PyTorch中的一个n (n>=0)维的数组结构。除数组原有的属性外,张量还支持一些其他增强功能,使其具有独特性。例如:除CPU外,还可以加载它们到GPU上以进行更快的计算;也可以通过设置.requires_grad = True(自己定义的Tensor的默认属性为False,神经网络中表达权重的Tensor默认属性为True),以跟踪所有对于该张量的操作,便于后面通过调用.backward()自动计算梯度。
在PyTorch比较早期的版本中,可以使用torch.autograd.Variable类进行创建支持梯度计算和跟踪的张量,torch.autograd.Variable包含以下5个属性:data、grad、grad_fn、requires_grad、is_leaf。但较新的PyTorch版本已经不太推荐使用Variable类了,而转为使用 torch.Tensor,他在torch.autograd.Variable的基础上,又增加了dtype、shape、device三个属性。
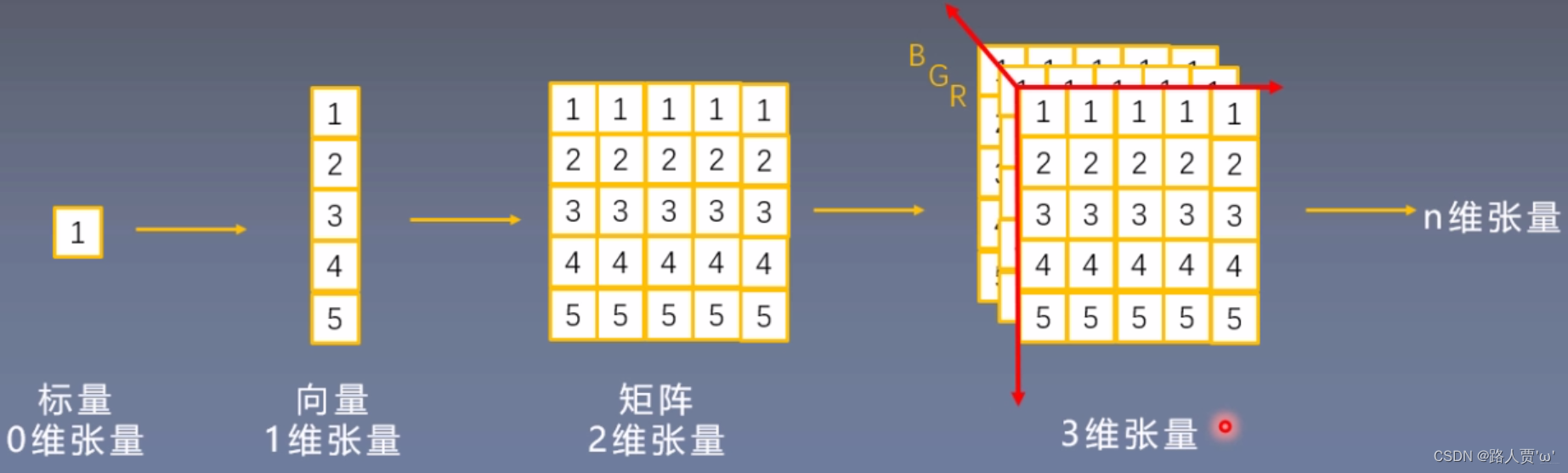
(2)Tensor与Variable
Variable是torch.autograd中的数据类型,主要用于封装Tensor,进行求导。
Variable的5个属性:
data:被包装的Tensor
grad:data的梯度
grad_fn:创建Tensor的Function,是自动求导的关键
requires_grad:指示是否需要梯度
is_leaf: 指示是否是叶子结点(张量)
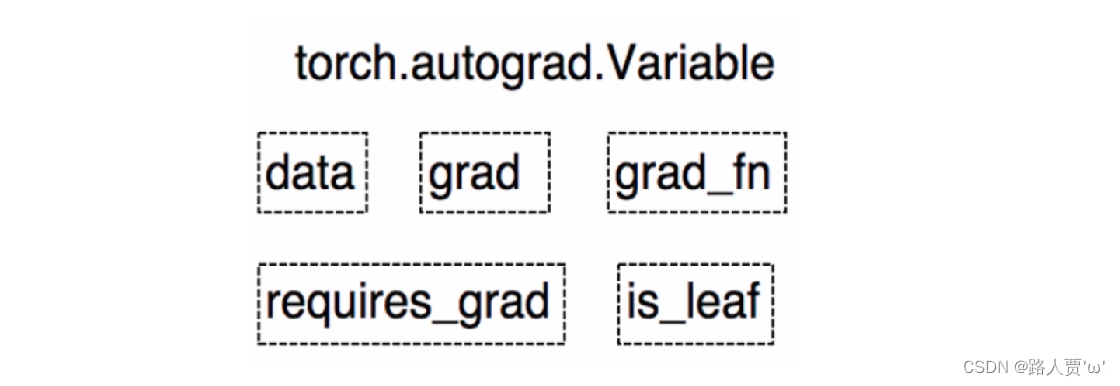
(3)Tensor
在 PyTorch 0.4.0 之后,Variable 并入了 Tensor。在之后版本的 Tensor 中,除了具有上面 Variable 的 5 个属性,还有另外 3 个属性。
dtype:张量的数据类型,如,torch.FloatTensor,torch.cuda.FloatTensor
shape:张量的形状,如(1,3,512,512)->(batch_size,channel,height,width)
device: 张量所在设备,GPU/CPU,是加速的关键
3.2张量的创建
3.2.1 直接创建
(1)torch.tensor()
功能:从data创建tensor

• data:数据,可以使list,numpy
• dtype:数据类型,默认与data的一致
• device:所在设备,cuda/cpu。device=‘cuda’
• requires_grad:是否需要梯度
• pin_memory: 是否存于锁页内存,通常设为false
具体代码段如下:
- arr = np.ones((3, 3))
- print('ndarry的数据类型:', arr.dtype)
-
- t = torch.tensor(arr, device='cuda')
- print(t)
-
- # 结果如下:
- ndarry的数据类型: float64
- tensor([[1., 1., 1.],
- [1., 1., 1.],
- [1., 1., 1.]], device='cuda:0', dtype=torch.float64)
(2)torch.from_numpy(ndarry)
功能:从numpy创建tensor
注意事项:从torch.from_numpy创建的tensor与原ndarray共享内存,当修改其中一个的数据,另一个也将会被改动。
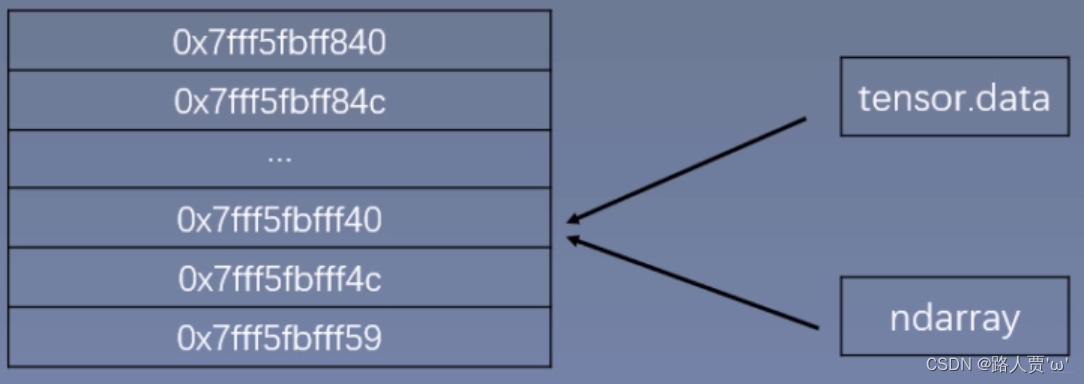
具体代码段如下(共享内存):
- arr = np.array([[1, 2, 3], [4, 5, 6]])
- t = torch.from_numpy(arr)
-
- print(arr, '\n',t)
- arr[0, 0] = 0
- print('*' * 10)
- print(arr, '\n',t)
- t[1, 1] = 100
- print('*' * 10)
- print(arr, '\n',t)
-
- # 结果:
- [[1 2 3]
- [4 5 6]]
- tensor([[1, 2, 3],
- [4, 5, 6]], dtype=torch.int32)
- **********
- [[0 2 3]
- [4 5 6]]
- tensor([[0, 2, 3],
- [4, 5, 6]], dtype=torch.int32)
- **********
- [[ 0 2 3]
- [ 4 100 6]]
- tensor([[ 0, 2, 3],
- [ 4, 100, 6]], dtype=torch.int32)
3.2 根据数值创建
(1)torch.zeros()
功能:依size创建全0张量

• size:张量的形状,如(3,3)、(3,224,224)
• out:表示输出张量,就是再把这个张量赋值给别的一个张量,但是这两个张量时一样的,指的同一个内存地址
• layout: 内存中布局形式,有strided(默认),sparse_coo(稀疏张量设置)等,一般采用默认
• device:所在设备,gpu/cpu
• requires_grad:是否需要梯度
具体代码段如下:
- out_t = torch.tensor([1])
- t = torch.zeros((3, 3), out=out_t)
-
- print(out_t, '\n', t)
- print(id(t), id(out_t), id(t) == id(out_t)) # 这个看内存地址
-
- # 结果:
- tensor([[0, 0, 0],
- [0, 0, 0],
- [0, 0, 0]])
- tensor([[0, 0, 0],
- [0, 0, 0],
- [0, 0, 0]])
- 2575719258696 2575719258696 True
(2)torch.zeros_like()
功能:创建与input同形状的全0张量

• input:创建与input同形状的全0张量
• dtype:数据类型
• layout:内存中布局形式
具体代码段如下:
- t = torch.zeros_like(out_t) # 这里的input要是个张量
- print(t)
-
- tensor([[0, 0, 0],
- [0, 0, 0],
- [0, 0, 0]])
(3)torch.full()
功能:自定义数值张量

• size:张量的形状,如(3,3)、(3,224,224)
• fill_value:张量的值 i
具体代码段如下:
- t = torch.full((3,3), 10)
- tensor([[10., 10., 10.],
- [10., 10., 10.],
- [10., 10., 10.]])
(4)torch.arange()
功能:创建等差的一维张量
注意事项:数值区间为[start,end),右开,取不到最后的值

• start:数列起始值
• end:数列“结束值”
• step:步长,数列公差,默认为1
具体代码段如下:
t = torch.arange(2, 10, 2) # tensor([2, 4, 6, 8])
(5)torch.linspace()
功能:创建均分的1维张量
注意事项:数值区间为[start,end],右闭,能取到最后的值

• start:数列起始值
• end:数列结束值
• steps:数列长度,不是步长!
[步长计算:(end-start)/(steps - 1)]
具体代码段如下:
- t = torch.linspace(2, 10, 5) # tensor([2, 4, 6, 8, 10])
-
- # 那么如果不是那么正好呢? 步长应该是多少?
- t = torch.linspace(2, 10, 6) # tensor([2, 3.6, 5.2, 6.8, 8.4, 10])
-
- # 这个步长是怎么算的? (end-start) / (steps-1)
3.3 根据概率创建
(1)torch.normal()
功能:生成正态分布(高斯分布)

• mean:均值
• std:标准差
四种模式:
mean为标量,std为标量
mean为标量,std为张量
mean为张量,std为标量
mean为张量,std为张量
注意事项:当mean和std均为标量时, 应设定size来规定张量的长度,分别各有两种取值,所以这里会有四种模式。
具体代码段如下:
- # 第一种模式 - 均值是标量, 方差是标量 - 此时产生的是一个分布, 从这一个分部种抽样相应的个数,所以这个必须指定size,也就是抽取多少个数
- t_normal = torch.normal(0, 1, size=(4,))
- print(t_normal) # 来自同一个分布
-
- # 第二种模式 - 均值是标量, 方差是张量 - 此时会根据方差的形状大小,产生同样多个分布,每一个分布的均值都是那个标量
- std = torch.arange(1, 5, dtype=torch.float)
- print(std.dtype)
- t_normal2 = torch.normal(1, std)
- print(t_normal2) # 也产生来四个数,但是这四个数分别来自四个不同的正态分布,这些分布均值相等
-
- # 第三种模式 - 均值是张量,方差是标量 - 此时也会根据均值的形状大小,产生同样多个方差相同的分布,从这几个分布中分别取一个值作为结果
- mean = torch.arange(1, 5, dtype=torch.float)
- t_normal3 = torch.normal(mean, 1)
- print(t_normal3) # 来自不同的分布,但分布里面方差相等
-
- # 第四种模式 - 均值是张量, 方差是张量 - 此时需要均值的个数和方差的个数一样多,分别产生这么多个正太分布,从这里面抽取一个值
- mean = torch.arange(1, 5, dtype=torch.float)
- std = torch.arange(1, 5, dtype=torch.float)
- t_normal4 = torch.normal(mean, std)
- print(t_normal4) # 来自不同的分布,各自有自己的均值和方差
-
(2)torch.randn()
功能:生成标准正态分布

• size:张量的形状
四、张量的操作与线性回归
4.1张量的操作
4.1.1张量拼接与拆分
(1)torch.cat()
功能:将张量按维度dim进行拼接

• tensors:张量序列
• dim:要拼接的维度
注意:.cat是在原来的基础上根据行和列,进行拼接, 浮点数类型拼接才可以,long类型拼接会报错。
具体代码段如下:
- # 张量的拼接
- t = torch.ones((2, 3))
- print(t)
-
- t_0 = torch.cat([t, t], dim=0) # 行拼接
- t_1 = torch.cat([t, t], dim=1) # 列拼接
- print(t_0, t_0.shape)
- print(t_1, t_1.shape)
-
- # 结果:
- tensor([[1., 1., 1.],
- [1., 1., 1.]])
- tensor([[1., 1., 1.],
- [1., 1., 1.],
- [1., 1., 1.],
- [1., 1., 1.]]) torch.Size([4, 3])
- tensor([[1., 1., 1., 1., 1., 1.],
- [1., 1., 1., 1., 1., 1.]]) torch.Size([2, 6])
(2)torch.stack()
功能:在新创建的维度dim上进行拼接

• tensors:张量序列
• dim:要拼接的维度
注意:.stack是根据给定的维度新增了一个新的维度,在这个新维度上进行拼接,这个.stack与其说是从新维度上拼接,不太好理解,其实是新加了一个维度Z轴,只不过dim=0和dim=1的视角不同罢了。 dim=0的时候,是横向看,dim=1是纵向看。
具体代码段如下:
- t_stack = torch.stack([t,t,t], dim=0)
- print(t_stack)
- print(t_stack.shape)
-
- t_stack1 = torch.stack([t, t, t], dim=1)
- print(t_stack1)
- print(t_stack1.shape)
-
- # 结果:
- tensor([[[1., 1., 1.],
- [1., 1., 1.]],
-
- [[1., 1., 1.],
- [1., 1., 1.]],
-
- [[1., 1., 1.],
- [1., 1., 1.]]])
- torch.Size([3, 2, 3])
- tensor([[[1., 1., 1.],
- [1., 1., 1.],
- [1., 1., 1.]],
-
- [[1., 1., 1.],
- [1., 1., 1.],
- [1., 1., 1.]]])
- torch.Size([2, 3, 3])
(3)torch.chunk()
功能:将张量按维度dim进行平均切分
返回值:张量列表
注意事项:若不能整除,最后一份张量小于其他张量

• input:要切分的张量
• chunks:要切分的份数
• dim:要切分的维度(在哪个维度进行切分)
具体代码段如下:
- a = torch.ones((2, 7)) # 7
- list_of_tensors = torch.chunk(a, dim=1, chunks=3) # 第一个维度切成三块, 那么应该是(2,3), (2,3), (2,1) 因为7不能整除3,所以每一份应该向上取整,最后不够的有多少算多少
- print(list_of_tensors)
- for idx, t in enumerate(list_of_tensors):
- print("第{}个张量:{}, shape is {}".format(idx+1, t, t.shape))
-
- # 结果:
- (tensor([[1., 1., 1.],
- [1., 1., 1.]]), tensor([[1., 1., 1.],
- [1., 1., 1.]]), tensor([[1.],
- [1.]]))
- 第1个张量:tensor([[1., 1., 1.],
- [1., 1., 1.]]), shape is torch.Size([2, 3])
- 第2个张量:tensor([[1., 1., 1.],
- [1., 1., 1.]]), shape is torch.Size([2, 3])
- 第3个张量:tensor([[1.],
- [1.]]), shape is torch.Size([2, 1])
(4)torch.split()
功能:将张量按维度dim进行切分(可以指定维度)
返回值:张量列表

• tensor:要切分的张量
• split_size_or_sections:为int时,表示每一份的长度;为list时,按list元素切分(和为当前维度的长度,否则报错)
• dim:要切分的维度
具体代码段如下:
- # split
- t = torch.ones((2, 5))
-
- list_of_tensors = torch.split(t, [2, 1, 2], dim=1) # [2 , 1, 2], 这个要保证这个list的大小正好是那个维度的总大小,这样才能切
- for idx, t in enumerate(list_of_tensors):
- print("第{}个张量:{}, shape is {}".format(idx+1, t, t.shape))
-
- ## 结果
- 第1个张量:tensor([[1., 1.],
- [1., 1.]]), shape is torch.Size([2, 2])
- 第2个张量:tensor([[1.],
- [1.]]), shape is torch.Size([2, 1])
- 第3个张量:tensor([[1., 1.],
- [1., 1.]]), shape is torch.Size([2, 2])
4.1.2 张量索引
(1)torch.index_select()
功能:按照索引查找,需要先指定一个tensor的索引量,然后指定类型是long的
返回值:依index索引数据拼接的张量

• input:要索引的张量
• dim:要索引的维度
• index:要索引数据的序号
注意事项:index的数据类型是long类型
[将索引的张量按在dim进行拼接]
具体代码段如下:
- t = torch.randint(0, 9, size=(3, 3)) # 从0-8随机产生数组成3*3的矩阵
- print(t)
- idx = torch.tensor([0, 2], dtype=torch.long) # 这里的类型注意一下,要是long类型
- t_select = torch.index_select(t, dim=1, index=idx) #第0列和第2列拼接返回
- print(t_select)
-
- # 结果:
- tensor([[3, 7, 3],
- [4, 3, 7],
- [5, 8, 0]])
- tensor([[3, 3],
- [4, 7],
- [5, 0]])
(2)torch.masked_select()
功能:就是按照值的条件进行查找,需要先指定条件作为mask,一般用来筛选数据
返回值:一维张量(因为不能确定张量中True的个数)
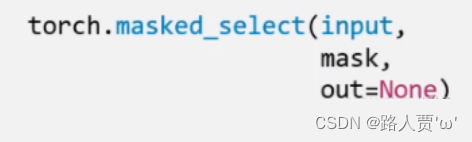
• input:要索引的张量
• mask:与input同形状的布尔类型张量
具体代码段如下:
- mask = t.ge(5) # le表示<=5, ge表示>=5 gt >5 lt <5
- print("mask: \n", mask)
- t_select1 = torch.masked_select(t, mask) # 选出t中大于5的元素
- print(t_select1)
-
- # 结果:
- mask:
- tensor([[False, True, False],
- [False, False, True],
- [ True, True, False]])
- tensor([7, 7, 5, 8])
4.1.3张量变换
(1)torch.reshape()
功能: 变换张量形状
注意事项:当张量在内存中是连续时,新张量与input共享数据内存

• input:要变换的张量
• shape:新张量的形状
[新张量的大小与原张量要匹配,若维度为-1,则表示该维度不需要关心,它会根据其他维度的大小进行计算]
具体代码段如下:
- # torch.reshape
- t = torch.randperm(8) # randperm是随机排列的一个函数
- print(t)
-
- t_reshape = torch.reshape(t, (-1, 2, 2)) # -1的话就是根据后面那两个参数,计算出-1这个值,然后再转
- print("t:{}\nt_reshape:\n{}".format(t, t_reshape))
-
- t[0] = 1024
- print("t:{}\nt_reshape:\n{}".format(t, t_reshape))
- print("t.data 内存地址:{}".format(id(t.data)))
- print("t_reshape.data 内存地址:{}".format(id(t_reshape.data))) # 这个注意一下,两个是共内存的
-
- # 结果:
- tensor([2, 4, 3, 1, 5, 6, 7, 0])
- t:tensor([2, 4, 3, 1, 5, 6, 7, 0])
- t_reshape:
- tensor([[[2, 4],
- [3, 1]],
-
- [[5, 6],
- [7, 0]]])
- t:tensor([1024, 4, 3, 1, 5, 6, 7, 0])
- t_reshape:
- tensor([[[1024, 4],
- [ 3, 1]],
-
- [[ 5, 6],
- [ 7, 0]]])
- t.data 内存地址:1556953167336
- t_reshape.data 内存地址:1556953167336
(2)torch.transpose()
功能:交换张量的两个维度,矩阵的转置和图像的预处理中常用。

• input:要变换的张量
• dim0:要交换的维度
• dim1:要交换的维度
具体代码段如下:
- # torch.transpose
- t = torch.rand((2, 3, 4)) # 产生0-1之间的随机数
- print(t)
- t_transpose = torch.transpose(t, dim0=0, dim1=2) # c*h*w h*w*c, 这表示第0维和第2维进行交换
- print("t shape:{}\nt_transpose shape: {}".format(t.shape, t_transpose.shape))
-
- # 结果:
- tensor([[[0.7480, 0.5601, 0.1674, 0.3333],
- [0.4648, 0.6332, 0.7692, 0.2147],
- [0.7815, 0.8644, 0.6052, 0.3650]],
-
- [[0.2536, 0.1642, 0.2833, 0.3858],
- [0.8337, 0.6173, 0.3923, 0.1878],
- [0.8375, 0.2109, 0.4282, 0.4974]]])
- t shape:torch.Size([2, 3, 4])
- t_transpose shape: torch.Size([4, 3, 2])
- tensor([[[0.7480, 0.2536],
- [0.4648, 0.8337],
- [0.7815, 0.8375]],
-
- [[0.5601, 0.1642],
- [0.6332, 0.6173],
- [0.8644, 0.2109]],
-
- [[0.1674, 0.2833],
- [0.7692, 0.3923],
- [0.6052, 0.4282]],
-
- [[0.3333, 0.3858],
- [0.2147, 0.1878],
- [0.3650, 0.4974]]])
(3)torch.t()
功能:2维张量转置,对矩阵而言,等价于torch.transpose(input,0,1)

(4)torch.squeeze()
功能:压缩长度为1的维度(轴)

• dim:若为None,移除所有长度为1的轴;若指定维度,当且仅当该轴长度为1时,可以被移除;
具体代码段如下:
- # torch.squeeze
- t = torch.rand((1, 2, 3, 1))
- t_sq = torch.squeeze(t)
- t_0 = torch.squeeze(t, dim=0)
- t_1 = torch.squeeze(t, dim=1)
- print(t.shape) # torch.Size([1, 2, 3, 1])
- print(t_sq.shape) # torch.Size([2, 3])
- print(t_0.shape) # torch.Size([2, 3, 1])
- print(t_1.shape) # torch.Size([1, 2, 3, 1])
(5)torch.unsqueeze()
功能:依据dim扩展维度
• dim:扩展的维度

4.1.4张量数学运算
Pytorch中提供了丰富的数学运算,可以分为三大类: 加减乘除, 对数指数幂函数,三角函数

torch.add()
功能:逐元素计算input+alpha*other

• input:第一个张量
• alpha:乘项因子
• other:第二个张量
具体代码段如下:
- t_0 = torch.randn((3, 3))
- t_1 = torch.ones_like(t_0)
- t_add = torch.add(t_0, 10, t_1)
-
- print("t_0:\n{}\nt_1:\n{}\nt_add_10:\n{}".format(t_0, t_1, t_add))
-
- # 结果:
- t_0:
- tensor([[-0.4133, 1.4492, -0.1619],
- [-0.4508, 1.2543, 0.2360],
- [ 1.0054, 1.2767, 0.9953]])
- t_1:
- tensor([[1., 1., 1.],
- [1., 1., 1.],
- [1., 1., 1.]])
- t_add_10:
- tensor([[ 9.5867, 11.4492, 9.8381],
- [ 9.5492, 11.2543, 10.2360],
- [11.0054, 11.2767, 10.9953]])
4.2线性回归
线性回归是分析一个变量与另外一(多)个变量之间关系的方法
因变量:y 自变量:x 关系:线性
y=wx+b
任务:求解w,b
求解步骤:
(1)确定模型 model:y=wx+b
(2)选择损失函数 MSE(均方差):
(3)求解梯度并更新w,b
w=w-LR*w.grad
b=b-LR*w.grad
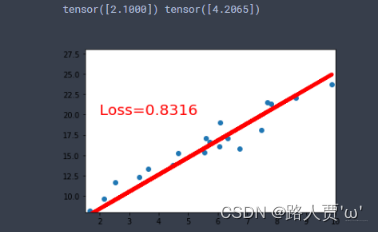
下面开始写一个线性回归模型:
- # 首先我们得有训练样本X,Y, 这里我们随机生成
- x = torch.rand(20, 1) * 10
- y = 2 * x + (5 + torch.randn(20, 1))
-
- # 构建线性回归函数的参数
- w = torch.randn((1), requires_grad=True)
- b = torch.zeros((1), requires_grad=True) # 这俩都需要求梯度
-
- for iteration in range(100):
- # 前向传播
- wx = torch.mul(w, x)
- y_pred = torch.add(wx, b)
-
- # 计算loss
- loss = (0.5 * (y-y_pred)**2).mean()
-
- # 反向传播
- loss.backward()
-
- # 更新参数
- b.data.sub_(lr * b.grad) # 这种_的加法操作时从自身减,相当于-=
- w.data.sub_(lr * w.grad)
-
- # 梯度清零
- w.grad.data.zero_()
- b.grad.data.zero_()
-
- print(w.data, b.data)
结果
五、autograd与逻辑回归
5.1autograd:自动求导系统
概念:autograd包为张量上的所有操作提供了自动求导的功能,他生成了一个动态循环图,并在该图上记录了张量所有执行的操作历史。此图的“叶”为输入张量,“根”为输出张量,梯度的计算过程是通过从根到叶跟踪图并使用链法则将每个梯度相乘。
(1)torch.autograd.backward
功能:自动求取梯度

• tensors:用于求导的张量,如loss
• retain_graph:保存计算图, 由于Pytorch采用了动态图机制,在每一次反向传播结束之后,计算图都会被释放掉。如果我们不想被释放,就要设置这个参数为True
• create_graph:表示创建导数计算图,用于高阶求导。
• grad_tensors:表示多梯度权重。如果有多个loss需要计算梯度的时候,就要设置这些loss的权重比例。
backward()是通过将参数(默认为1x1单位张量)通过反向图追踪所有对于该张量的操作,使用链式求导法则从根张量追溯到每个叶子节点以计算梯度。下图描述了pytorch对于函数z = (a + b)(b - c)构建的计算图,以及从根节点z到叶子节点a,b,c的求导过程:
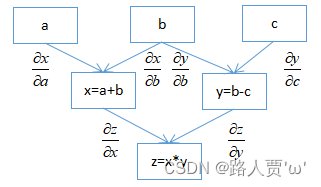
注意:计算图已经在前向传递过程中已经被动态创建了,反向传播仅使用已存在的计算图计算梯度并将其存储在叶子节点中。
具体代码段如下:
- grad_tensors = torch.tensor([1., 1.])
- loss.backward(gradient=grad_tensors)
- print(w.grad) # 这时候会是tensor([7.]) 5+2
-
- grad_tensors = torch.tensor([1., 2.])
- loss.backward(gradient=grad_tensors)
- print(w.grad) # 这时候会是tensor([9.]) 5+2*2
(2)torch.autograd.grad
功能:求取梯度

• outputs:用于求导的张量,如loss
• inputs:需要梯度的张量
• create_graph:创建导数计算图,用于高阶求导
• retain_graph:保存计算图
• grad_outputs:多梯度权重
注意事项:
- 梯度不自动清零(梯度叠加,需手动清零,w.grad.zero_())
- 依赖于叶子结点的结点,requires_grad默认为True
- 叶子结点不可执行in-place,因为反向传播时还需要用到叶子结点的数据,故叶子结点不能改变(zero_的下划线表示原位操作)
具体代码段如下:
- x = torch.tensor([3.], requires_grad=True)
- y = torch.pow(x, 2) # y=x^2
-
- # 一次求导
- grad_1 = torch.autograd.grad(y, x, create_graph=True) # 这里必须创建导数的计算图, grad_1 = dy/dx = 2x
- print(grad_1) # (tensor([6.], grad_fn=<MulBackward0>),) 这是个元组,二次求导的时候我们需要第一部分
-
- # 二次求导
- grad_2 = torch.autograd.grad(grad_1[0], x) # grad_2 = d(dy/dx) /dx = 2
- print(grad_2) # (tensor([2.]),)
5.2逻辑回归
逻辑回归是线性的二分类模型

机器学习模型训练的步骤:

- 数据模块(数据采集,清洗,处理等)
- 建立模型(各种模型的建立)
- 损失函数的选择(根据不同的任务选择不同的损失函数),有了loss就可以求取梯度
- 得到梯度之后,我们会选择某种优化方式去进行优化
- 然后迭代训练
下面就基于上面的五个步骤,看看Pytorch是如何建立一个逻辑回归模型,并分类任务的。我们下面一步一步来:
(1)数据生成
这里我们使用随机生成的方式,生成2类样本(用0和1表示), 每一类样本100个, 每一个样本两个特征。
- """数据生成"""
- torch.manual_seed(1)
-
- sample_nums = 100
- mean_value = 1.7
- bias = 1
-
- n_data = torch.ones(sample_nums, 2)
- x0 = torch.normal(mean_value*n_data, 1) + bias # 类别0 数据shape=(100,2)
- y0 = torch.zeros(sample_nums) # 类别0, 数据shape=(100, 1)
- x1 = torch.normal(-mean_value*n_data, 1) + bias # 类别1, 数据shape=(100,2)
- y1 = torch.ones(sample_nums) # 类别1 shape=(100, 1)
-
- train_x = torch.cat([x0, x1], 0)
- train_y = torch.cat([y0, y1], 0)
(2)建立模型
这里我们使用两种方式建立我们的逻辑回归模型,一种是Pytorch的sequential方式,这种方式就是简单,易懂,就类似于搭积木一样,一层一层往上搭。 另一种方式是继承nn.Module这个类搭建模型,这种方式非常灵活,能够搭建各种复杂的网络。
- """建立模型"""
- class LR(torch.nn.Module):
- def __init__(self):
- super(LR, self).__init__()
- self.features = torch.nn.Linear(2, 1) # Linear 是module的子类,是参数化module的一种,与其名称一样,表示着一种线性变换。输入2个节点,输出1个节点
- self.sigmoid = torch.nn.Sigmoid()
-
- def forward(self, x):
- x = self.features(x)
- x = self.sigmoid(x)
-
- return x
-
- lr_net = LR() # 实例化逻辑回归模型
另外一种方式,Sequential的方法:
- lr_net = torch.nn.Sequential(
- torch.nn.Linear(2, 1),
- torch.nn.Sigmoid()
- )
(3)选择损失函数
这里我们使用二分类交叉熵损失
- """选择损失函数"""
- loss_fn = torch.nn.BCELoss()
(4)选择优化器
这里我们就用比较常用的SGD优化器。关于这些参数,这里不懂没有问题,后面会单独的讲, 这也就是为啥要系统学习一遍Pytorch的原因, 就比如这个优化器,我们虽然知道这里用了SGD,但是我们可能并不知道还有哪些常用的优化器,这些优化器通常用在什么情况下。
- """选择优化器"""
- lr = 0.01
- optimizer = torch.optim.SGD(lr_net.parameters(), lr=lr, momentum=0.9)
(5)迭代训练模型
这里就是我们的迭代训练过程了, 基本上也比较简单,在一个循环中反复训练,先前向传播,然后计算梯度,然后反向传播, 更新参数,梯度清零。
- """模型训练"""
- for iteration in range(1000):
-
- # 前向传播
- y_pred = lr_net(train_x)
-
- # 计算loss
- loss = loss_fn(y_pred.squeeze(), train_y)
-
- # 反向传播
- loss.backward()
-
- # 更新参数
- optimizer.step()
-
- # 清空梯度
- optimizer.zero_grad()
-
- # 绘图
- if iteration % 20 == 0:
-
- mask = y_pred.ge(0.5).float().squeeze() # 以0.5为阈值进行分类
- correct = (mask == train_y).sum() # 计算正确预测的样本个数
- acc = correct.item() / train_y.size(0) # 计算分类准确率
-
- plt.scatter(x0.data.numpy()[:, 0], x0.data.numpy()[:, 1], c='r', label='class 0')
- plt.scatter(x1.data.numpy()[:, 0], x1.data.numpy()[:, 1], c='b', label='class 1')
-
- w0, w1 = lr_net.features.weight[0]
- w0, w1 = float(w0.item()), float(w1.item())
- plot_b = float(lr_net.features.bias[0].item())
- plot_x = np.arange(-6, 6, 0.1)
- plot_y = (-w0 * plot_x - plot_b) / w1
-
- plt.xlim(-5, 7)
- plt.ylim(-7, 7)
- plt.plot(plot_x, plot_y)
-
- plt.text(-5, 5, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 20, 'color': 'red'})
- plt.title("Iteration: {}\nw0:{:.2f} w1:{:.2f} b: {:.2f} accuracy:{:.2%}".format(iteration, w0, w1, plot_b, acc))
- plt.legend()
-
- plt.show()
- plt.pause(0.5)
-
- if acc > 0.99:
- break
结果:

本文参考: 系统学习Pytorch笔记二:Pytorch的动态图、自动求导及逻辑回归 PyTorch 学习笔记汇总(完结撒花) - 知乎 (zhihu.com)

