
- 1Payoneer注册、收款、提现常见问题_payoneer提现手续费
- 2PCL库教程_pcl教程
- 3面试题整理_es查看执行计划
- 4李宏毅LLM——生成式学习的两种策略_llm生成式 模板 学习
- 5ChatGPT又多了一个强有力的竞争对手:Meta发布Llama 3开源模型!附体验地址_meta ai llama 3模型下载
- 6Redux详解(二)
- 7Linux部署自动化运维平台Spug_运维自动部署平台
- 8jmeter最大请求数_jmeter 测试某网页最大并发用户数;
- 9【Thunder送书 | 第三期 】「Python系列丛书」_python从入门到精通(微课精编版)怎么样
- 10微信小程序点餐系统的开发与实现_基于微信小程序点餐系统设计与实现
李宏毅LLM——生成式学习的两种策略_llm生成式 模板 学习
赞
踩
生成式学习的两种策略:各个击破和一次到位
对应视频的 P7-P11
生成有结构的复杂物件也是由小的结构组成
文句:token 中文:字;英文: word piece。原因:英文的词汇无穷多
影像:像素点
语音:采样
策略一:各个击破

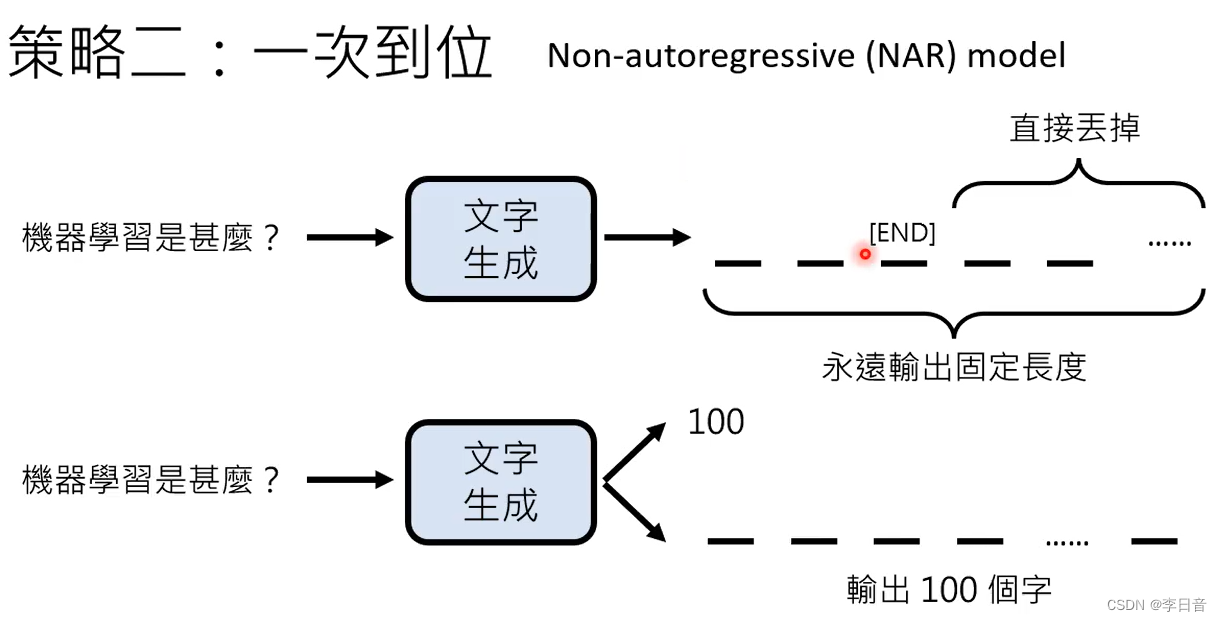
策略二:一次到位
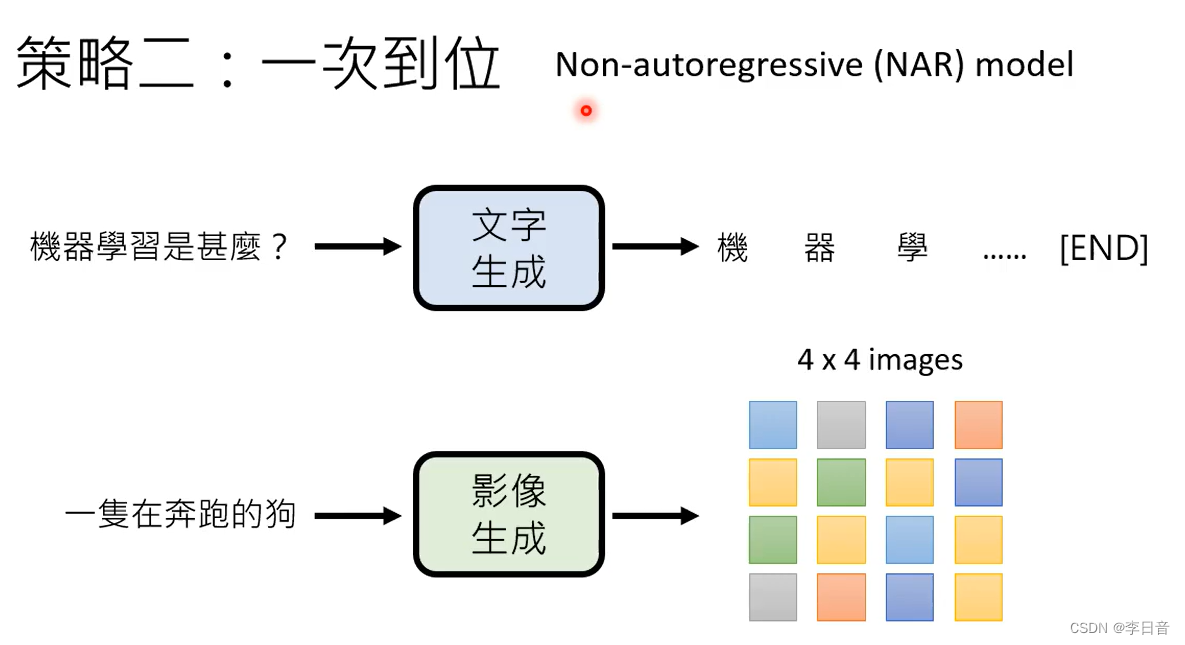
问题:怎么知道什么时候结束?
方法一:
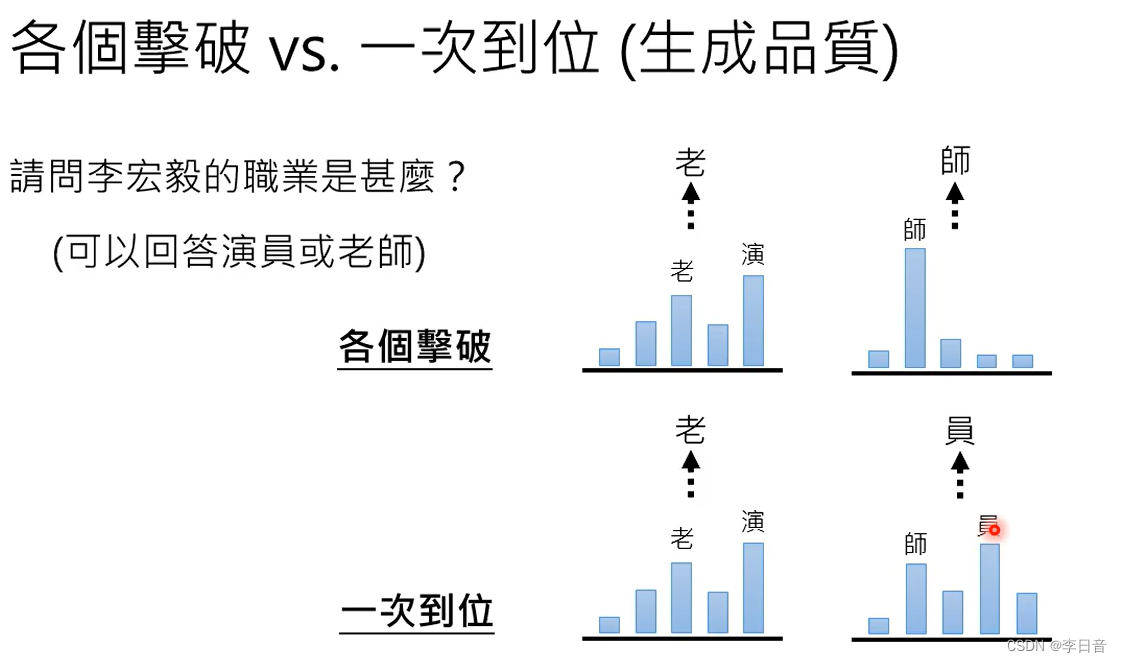
速度:一次到位更快,所以用于影像生成。
生成质量:各个击破更好,所以用于文字生成
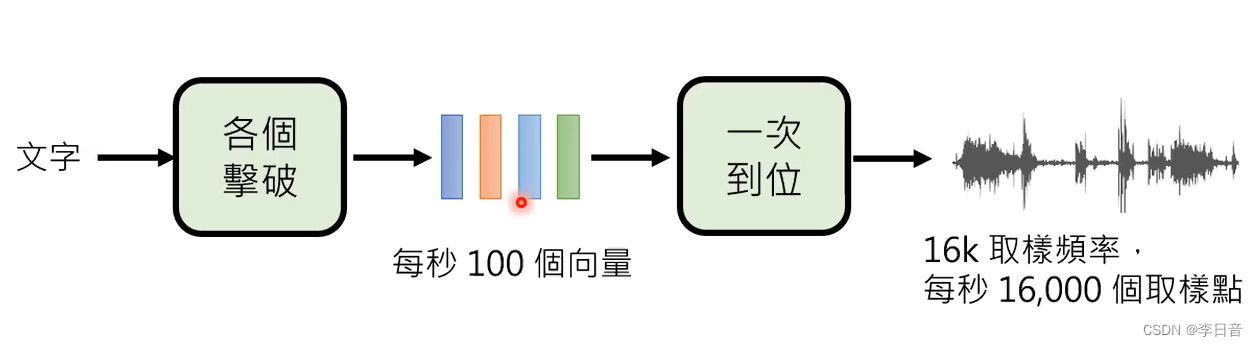
语音领域:两者结合
先各个击破,决定大方向。再一次到位
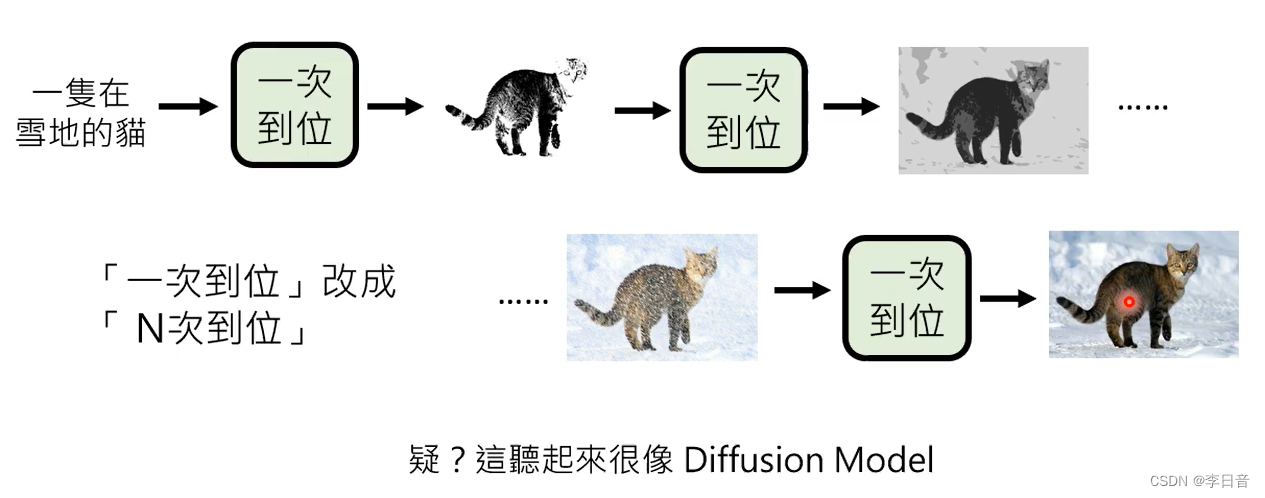
改进2:一次到位改成N次到位
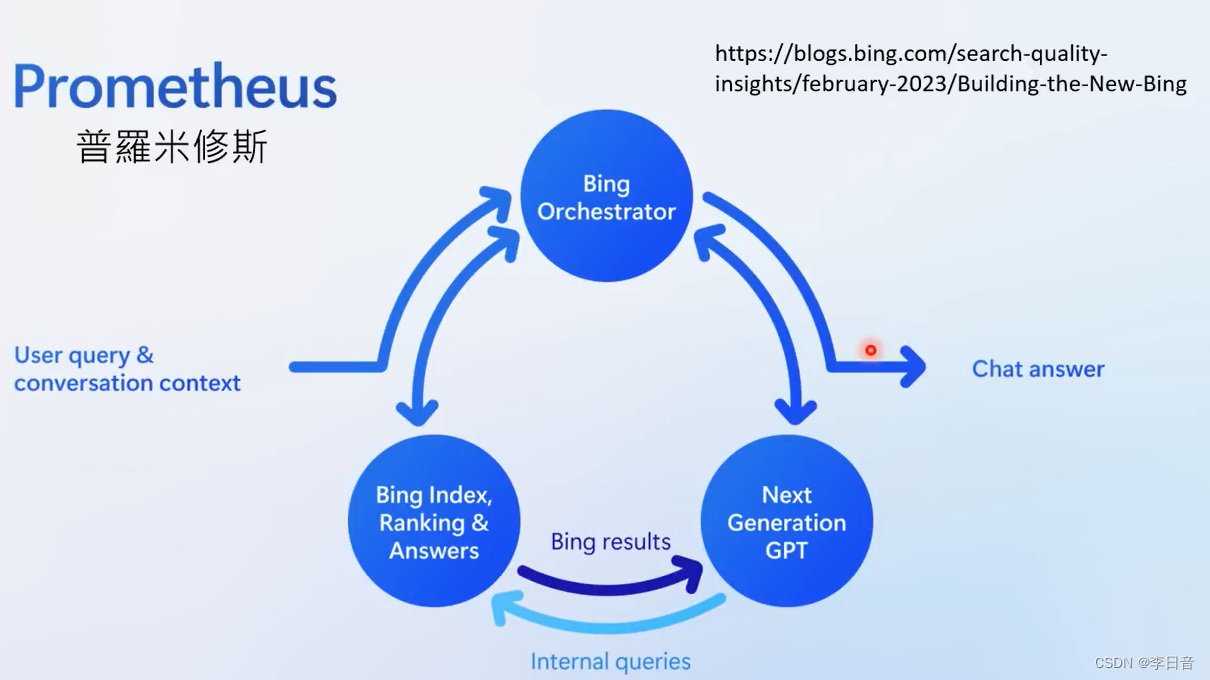
new bing 实测:
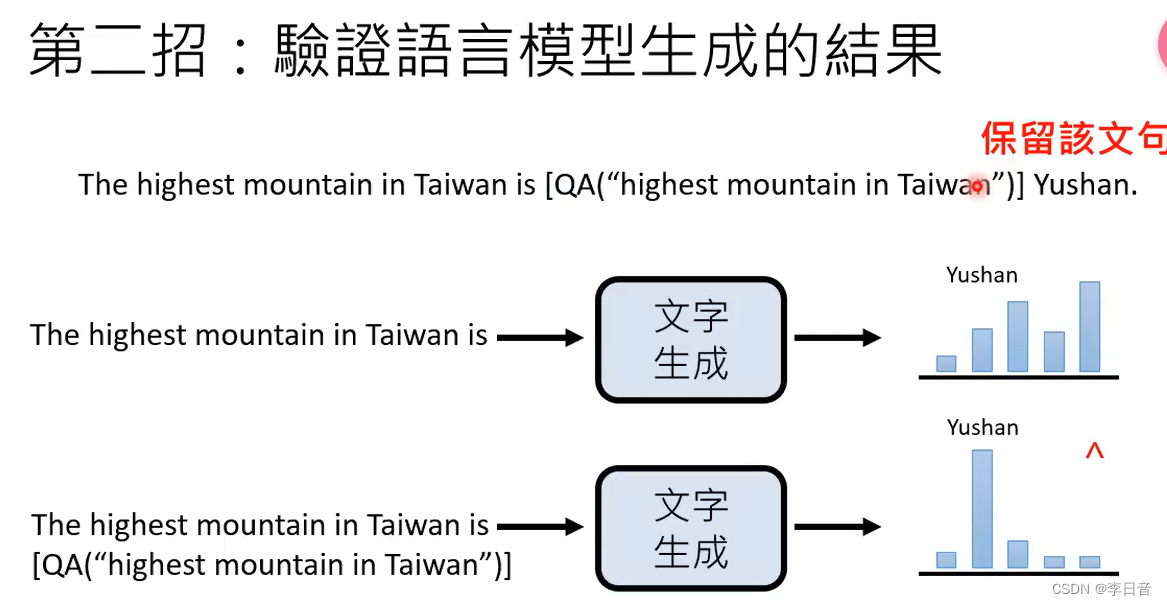
new bing可以联网,何时进行搜寻由机器自己决定,具有随机性。但即使引用网页还是会幻想犯错。
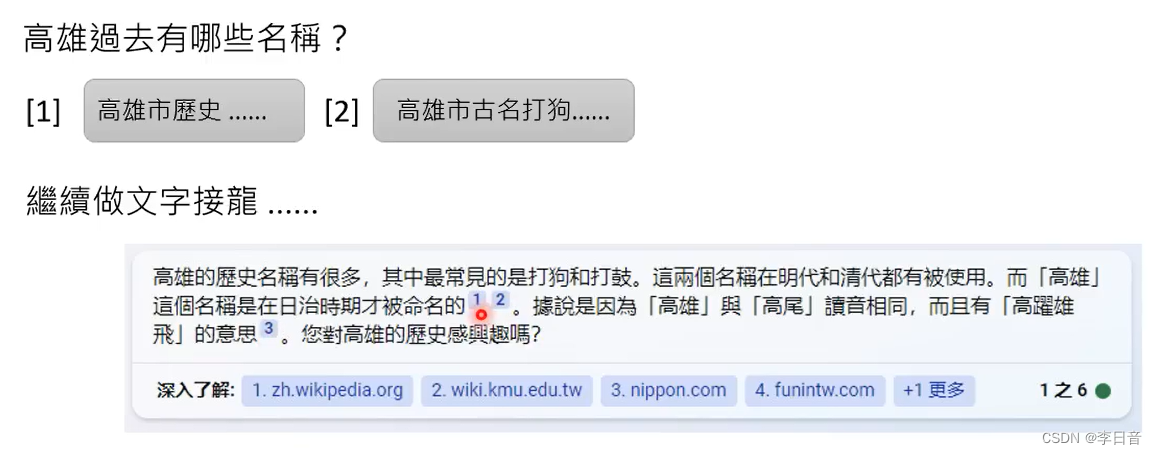
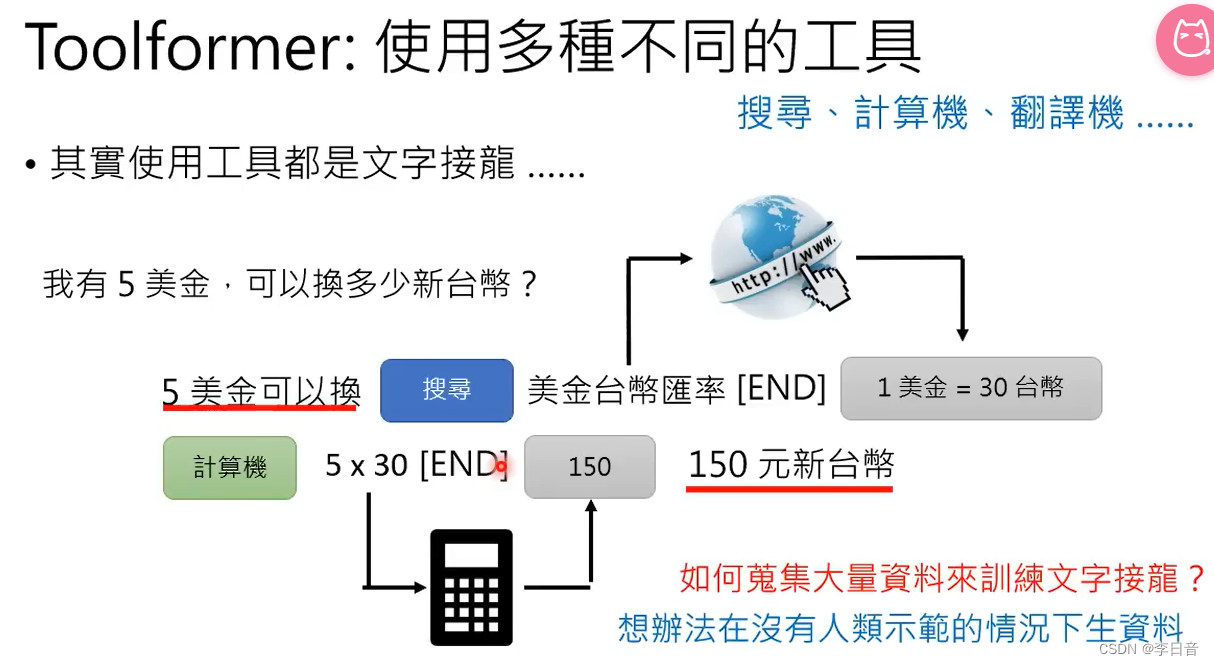
其实使用搜索引擎时,也是文字接龙。
在搜索出来的结果后面做文字接龙

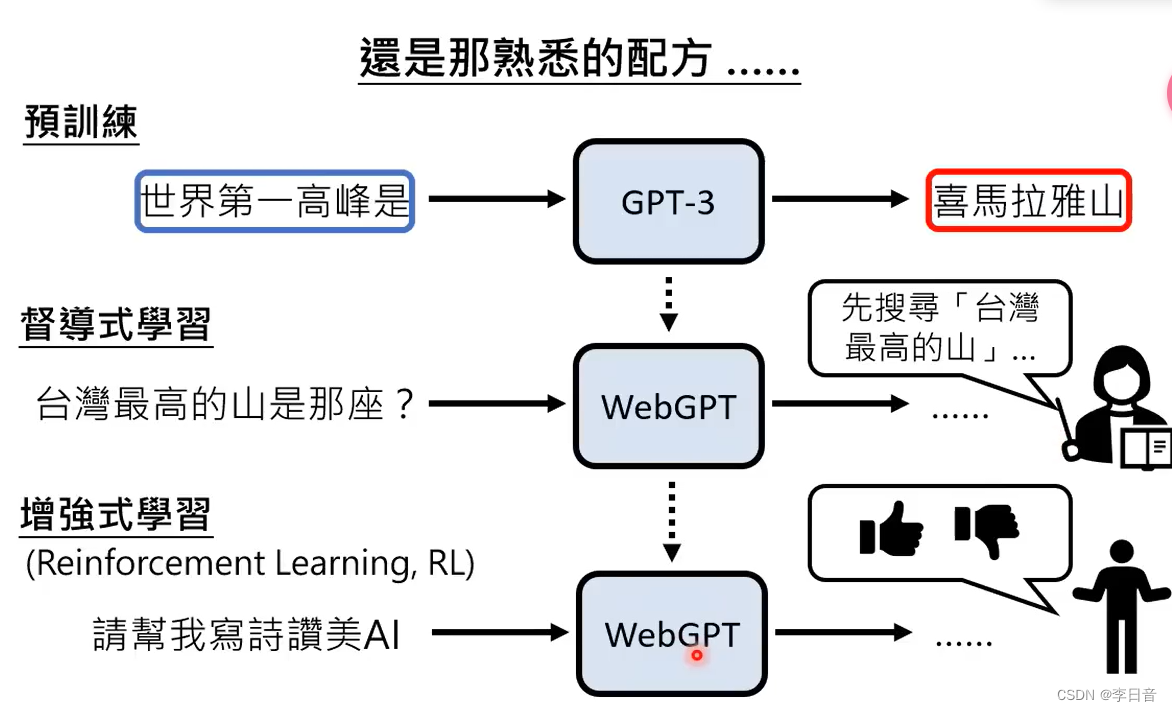
训练:记录人类老师的行为

Web GPT依然是预训练+微调的模式
Toolformer:不止会搜索,还会用其他工具

语言模型:GPT vs BERT
GPT是文字接龙,而BERT是文字填空

大模型读过很多资料,但他不知道应该做什么,需要有人来引导。
人类对大语言模型的两种期待
期待一:成为专才,解某一个特定任务 ,有机会在单一任务上赢过通才
期待二:成为通才,什么都会。需要人类下指令prompt
成为专才:
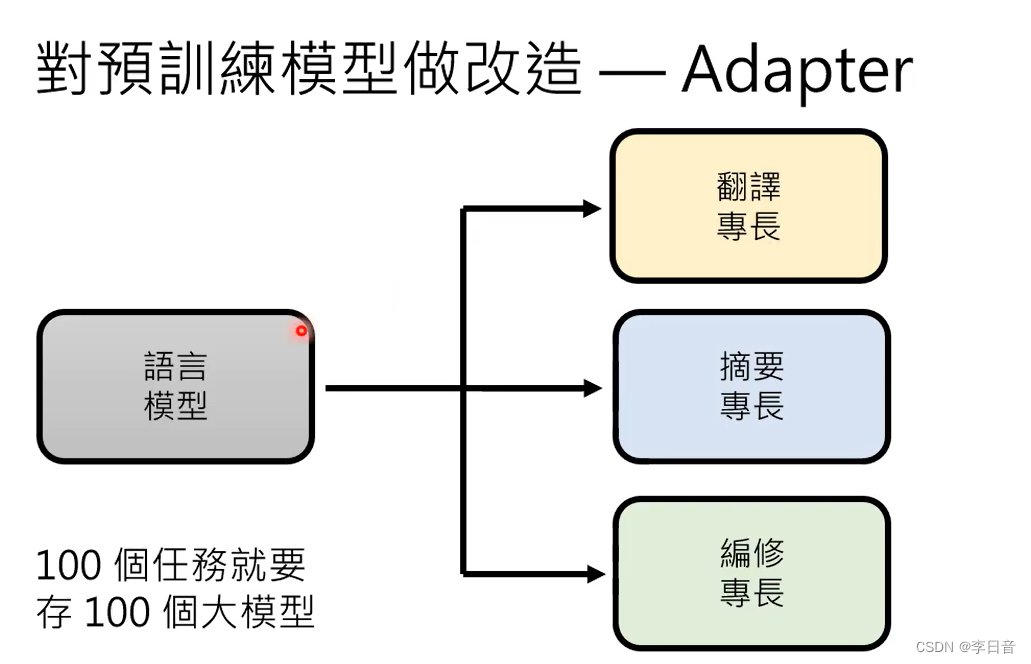
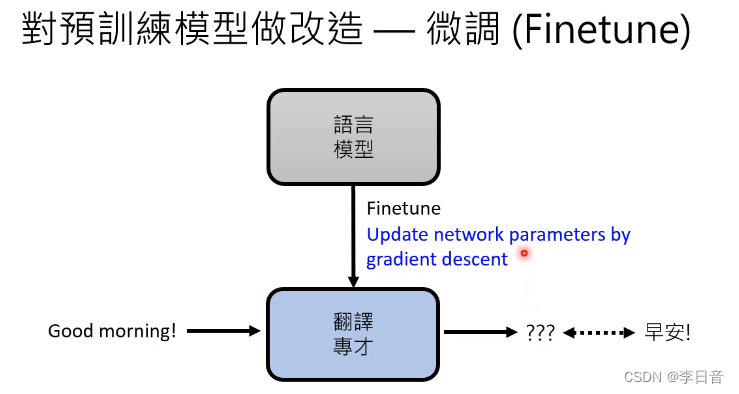
对预训练模型做改造
-
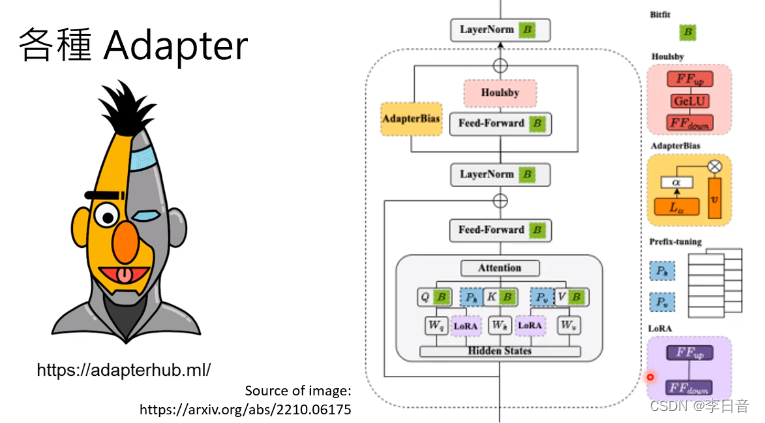
加外挂
BERT的天生劣势:文字填空无法生成完整的句子
因此需要加上额外的模组
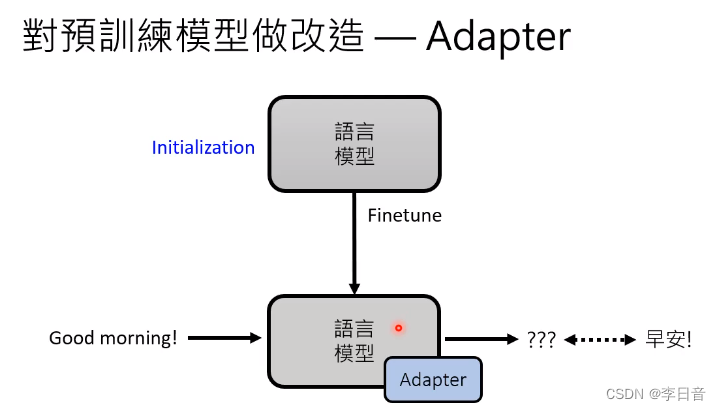
只调整Adapter
-
微调参数 Finetune
成为通才
OpenAI对AI的期待比较高

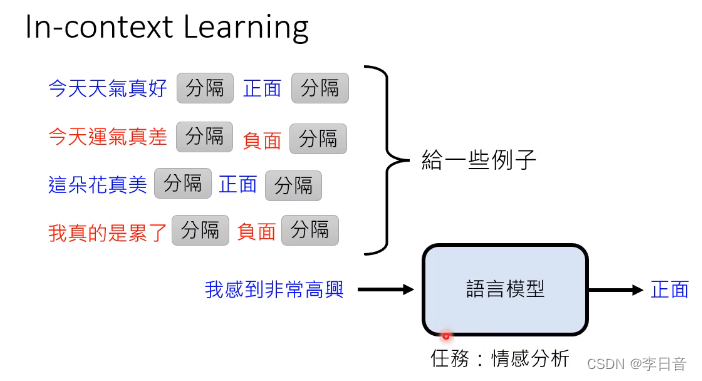
神秘的 In-context Learning 能力
透过范例来学习
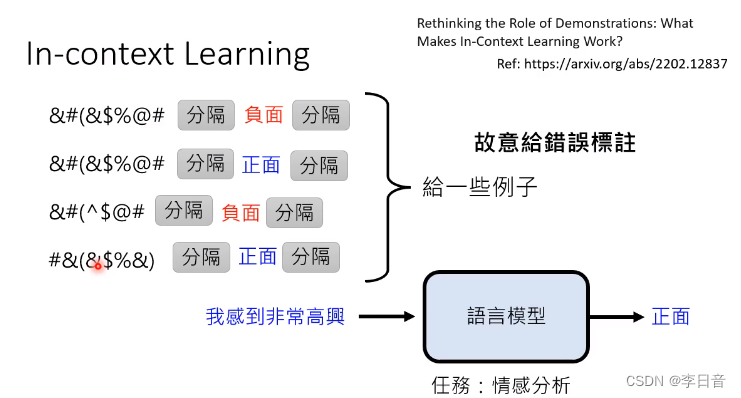
给错误范例,正确率并不会下降很多。但是给无关的句子会影响正确率。
原因:给栗子只是为了唤醒GPT需要做的任务
例子给多了作用也不大
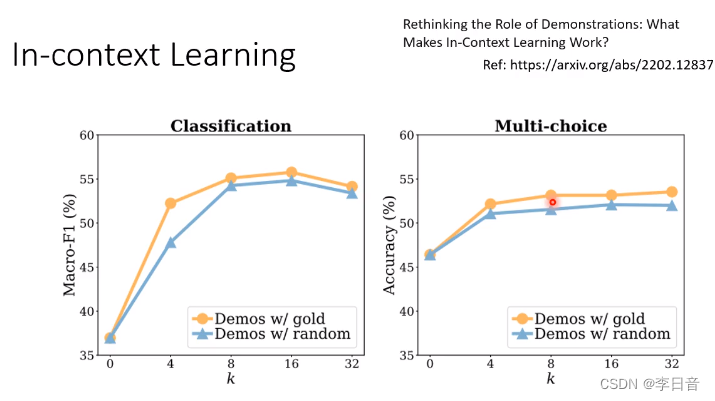
越大的模型受到错误例子的影响越大。也就是说特别大的模型真的会从例子中学习
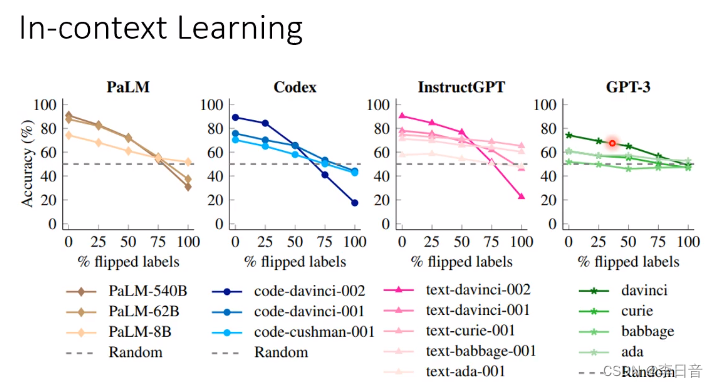
只是读一些例子,就可以做分类器

Instruction Learning
直接阅读题目,给出答案
需要Instruction-tuning来学习
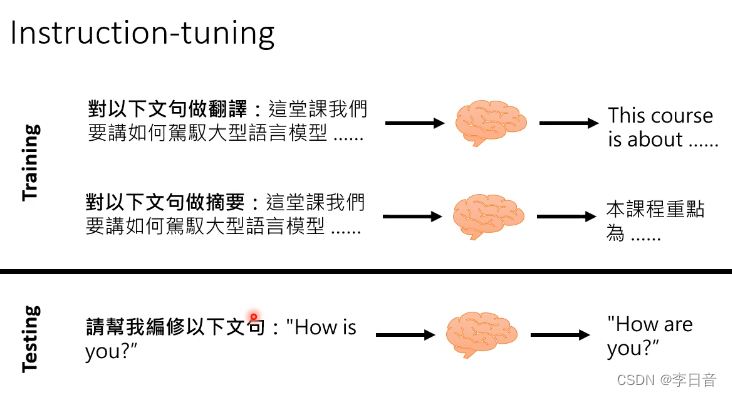
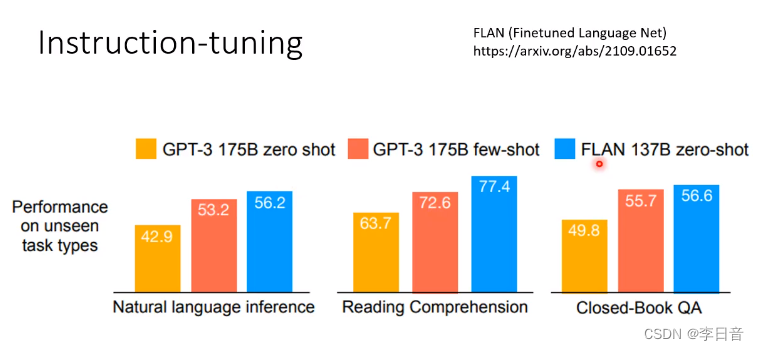
期待在测试的时候可以完成别的任务
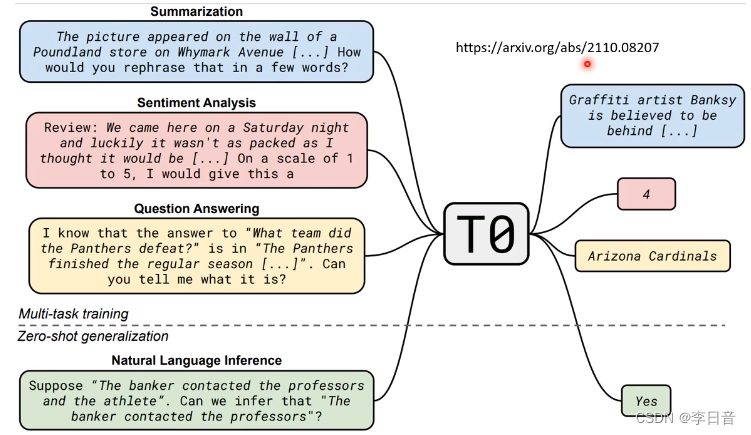
不同的描述方式做成数据集
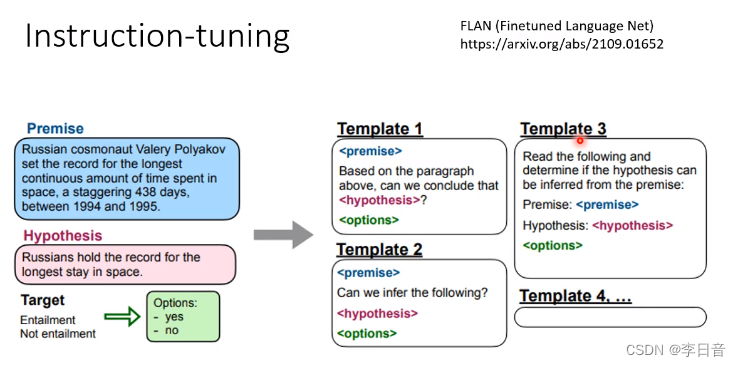
测试时用没学过的指令
Chain of Thought Prompting
写出推论过程,能力起飞
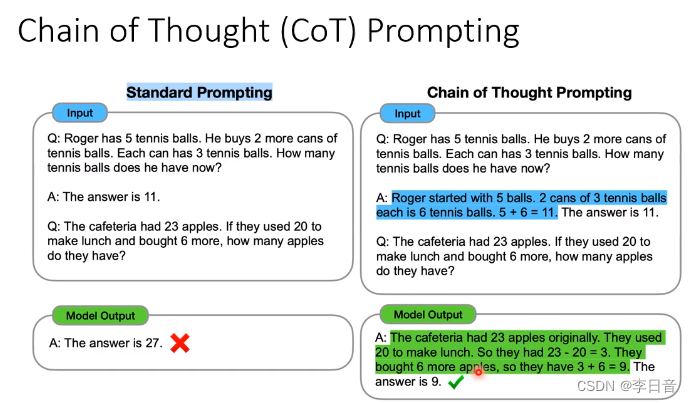
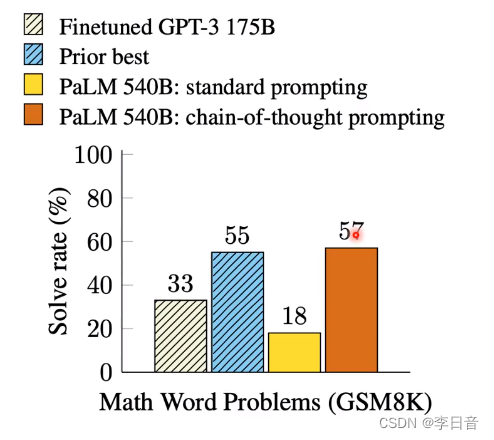
变形:不给例子,只给一个Let‘s think step by step.
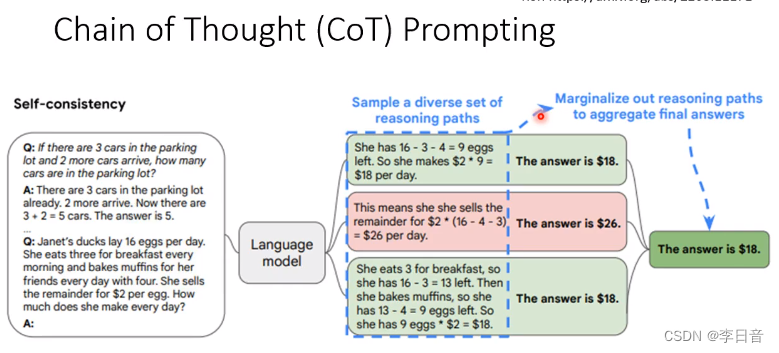
生成多个答案并投票出结果
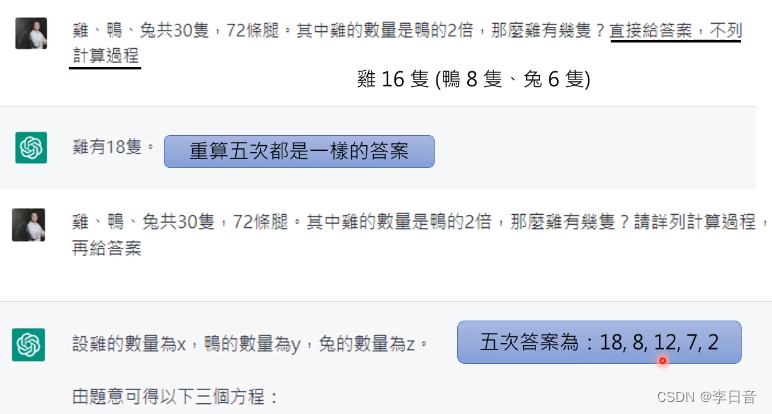
测试:鸡鸭兔同笼问题
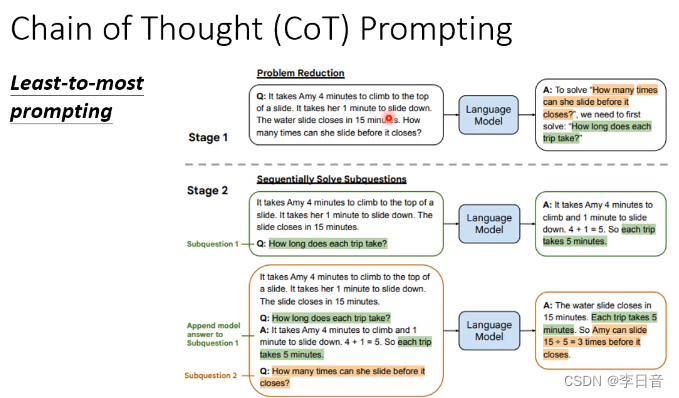
数学问题太难,拆解问题
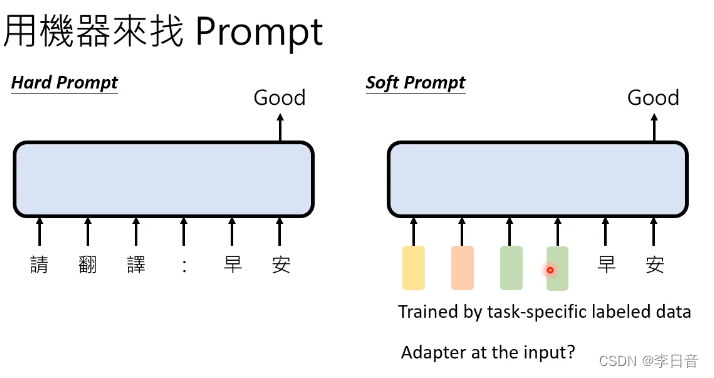
用机器自动找prompt
- 用向量而不是文字
- 强化学习
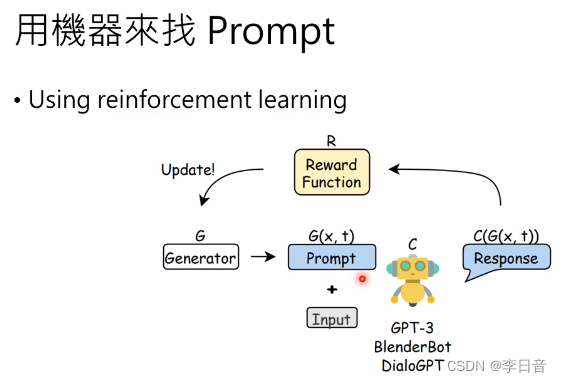
- LLM直接想出来prompt

机器自己想的Prompt效果优于人类提供的



