
- 1Spring Security学习笔记_org.springframework.security
- 2项目中git信息(即版本控制信息)清除_c# 项目 去掉gitlab版本管控
- 3Windows10下常用深度学习框架(GPU版)的安装方式_win0安装深度学习框架
- 4CCF-GESP 等级考试 2024年3月认证C++一级真题解析_gesp真题解析24年3月一级
- 5Manjaro 安装卸载 Code::Blocks_如何把codeblock完全删除
- 6Xilinx FPGA高性能NVMe控制器IP,NVMe Host Controller IP_nvem控制器
- 7unity Holoens2开发,使用Vuforia识别实体或图片 触发交互(一)_vuforia应用hololens2识别图片(3)_hololens2开发图像识别
- 8cannot open git-upload-pack
- 9Mysql高性能优化笔记(含578页笔记PDF文档),收藏了_高性能mysql第四版 pdf
- 10【Element Ui】 vue3中修改el-form的rules后不触发自动校验,再次修改rules时清除验证信息_el-form 修改:rules 触发校验
AIGC 时代到来?聊聊其中最出圈的语言模型 GPT-3_gtp3
赞
踩
【编者按:近期,随着AI绘画,AI生成视频的走红,AIGC(AI-Generated Content 人工智能生成内容)再度站在了聚光灯下,成为行业热门话题。AIGC的发展离不开大模型底层技术的支撑,而其中最为出圈的,当属“万能语言模型”GTP-3。
本文中,我们将和大家一同走进GPT-3的发展史,了解GPT-3产生巨大飞跃的原因,探索GPT-3的商业化价值。】
目录
01. TLDR(Too Long Don't Read - 总结)
01. TLDR(Too Long Don't Read - 总结)
GPT-3通过增加参数规模和训练数据集规模,依托及其强大的资金和算力支持来获得更好的性能。该模型可通过生成具有商业价值的广告等文本、分析税务来节省税金、提供个性化学习材料、创作艺术作品等行为,来创造商业价值。同时,我们也可以使用GPT框架训练其他模态的模型,GPT-3商业化也为AI项目盈利带来了新探索。当然,训练集中的不良内容和资本的加入给使用GPT-3带来了一些风险和不确定因素。
02. GPT家族史
GPT全称Generative Pre-Training,意为通过生成式来进行预训练。
2.1 前缘
在2017年4月6日,OpenAI发布了一种使用LSTM(Long Short Term Memory,具有记忆长短期信息能力的神经网络)、以Amazon商品评论作为训练数据集的单向语言模型。
OpenAI1发现,即使只是经过如此简单的预训练,LSTM就可以产生一种可以区分正面和负面情感的神经元,区分商品评论中所包含的情绪,例如,表示会再次购买并向朋友安利的正面评论,以及表示买到的平板电脑就是个垃圾的负面评论。虽然在当时大家的注意力都在其可解释性上,但这种预训练的思想也为后面GPT的出现做出准备。
OpenAI使用4张NVIDIA Pascal GPU花费一个月的时间来训练该模型。
2.2 GPT
盘古的一只眼睛变成了太阳,另一只变成了月亮;而Transformer的Encode变成了BERT,Decode变成了GPT2。
2018年底,谷歌发布的语言表征模型BERT,在顶级机器阅读理解水平测试SQuAD1.1中独占鳌头3,谷歌在BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding这篇论文4中,将BERT与GPT作为同样需要面对不同任务进行微调语言模型进行对比,才让GPT走入大众的视野。但或许是成本使然,OpenAI只是将GPT用于处理语言理解(Language Understanding)方面的任务,并未发掘其作为预处理模型的潜力5。
GPT参数量为1.17亿,预训练数据量约为5GB6,OpenAI使用了8张P600花费一个月时间来训练GPT。
2.3 GPT-2
相较于初代GPT,2019年2月14日发布的GPT-2采用了Zero Shot7,即,之前没有这个类别的训练样本,但是通过学习到一个足够好的映射X->Y,模型可以处理未曾接触过的类了。
8初代GPT作为一种概率语言模型,学习目标为:p(output | input),而GPT-2为使相同的无监督模型学习多个任务,OpenAI将其学习目标跟改为了p(output | input, task),这使得GPT-2可以对不同任务的相同输入产生不同的输出。例如,给定GPT-2一段关于北京奥运会的文本,对于不同问题GPT-2均可以给出答案;GPT-2还可以根据一句人工编写的提示,生成一段文本。
GPT-2 XL版9参数量为15亿,预训练数据量为40GB,OpenAI使用32张8核TPU v3花费超过一周时间来训练GPT-2,每张TPU v3每小时的价格为8美元,也就是说,训练GPT-2的成本不少于32 * 24 * 7 * 8 ≈ 4.3万美元10 。
2.4 GPT-3
2020年5月28日,OpenAI发布新模型GPT-3。同年6月11日,OpenAI不在固守之前的基础研究,将GPT-3以API11的方式向学术机构、商业公司和个人开发者提供了一些需要申请的体验资格12,并在同年9月将GPT-3授权给微软公司13。对于所有任务,通过纯文本来指定任务和少量样本,GPT-3可以在无需任何梯度更新或微调的情况下被使用。对于GPT-3生成的新闻文章,评估员甚至无法区分其与人类撰写的新闻文章。
GPT-3参数量为1750亿,预训练数据量为45TB,OpenAI在具有7500个节点的Kubernetes节点上训练GPT-314 。
到这里,看完GPT家族的历史后,我们不难看出GPT-3较前两代提升巨大的原因,也需要思考其价值。
9月6日,播客The AI Business对话了OpenAI 产品与合作伙伴关系副总裁 Peter Welinder。在这一期节目15中,Peter介绍了GPT-3产生巨大飞跃的原因,以及其潜在商业价值。
03. 是什么让GPT-3产生了巨大飞跃
从参数规模来看,GPT-3高达1750亿的参数规模,较上代15亿参数大了两个数量级,也正因如此,GPT-3的使用场景更加通用:机器翻译、闭卷问答、情感判断、文章生成、辅助编码等。
再者就是训练数据集的增大,高达45TB,千倍于前代的训练数据集使得GPT-3预测的单词更加准确,也让GPT-3更像一个包含知识、语境理解和语言组织能力的“数据库”。
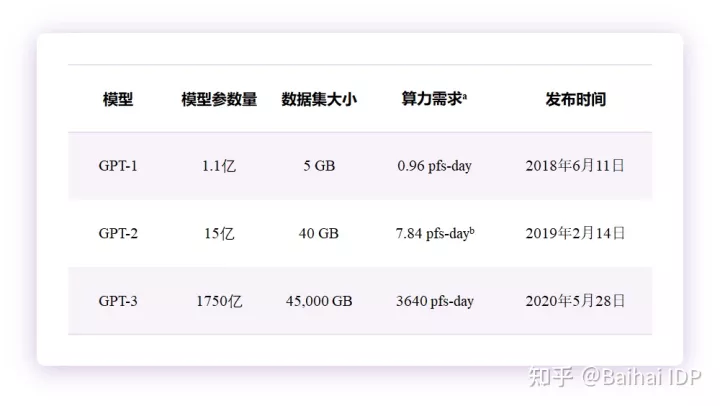
a算力需求的衡量单位pfs-day(全称为petaflops/s-days)来自OpenAI,计算公式为:GPU数量 * 单个GPT算力 * 训练时间 * GPU利用率。
b此数据为GPT-2 XL版本的算例需求,数据来自论文On the comparability of Pre-trained Language Models16。
04. GPT-3的商业价值
GPT-3具有强大的文本生成能力,可以写文章、编故事,还可以进行多轮对话、写代码、做表格、生成图标等,那么它具备什么商业价值呢?
根据Peter的介绍,GPT-3目前已在如下方面进行了商业化探索,包括:
- 帮助企业或广告主编写广告文案。并非每个人都擅长编写文案,尤其对于一些小企业主,GPT-3可以帮助他们以廉价成本编写较高质量的广告文案。例如要为鞋编写广告文案,你只需要告诉GPT-3这双鞋的颜色、功能等属性,它就会返回给你一些不错的广告文案。
- 通过识别并分析账单上的数据,来节省税费。Keeper Tax17利用OpenAI提供的GPT-3 API分析银行流水,可以帮助自由职业者找到可免除的税费。
- 与历史人物对话。通过将GPT-3设定为华盛顿等想要交谈的历史人物,我们来语虚拟人谈论历史。
- 为学生或职员提供个性化的学习资料。就像一对一的教学更能提高学生成绩一样,Sana18为每个人提供定制化的学习方案,帮助人们更快的掌握知识和技能。
- 用于艺术创作。利用GPT-3的文本生成功能,与孩子一同创作童话故事。
另外,GPT-3的商业化,也在AI绑定硬件的商业模式之外,为解决AI“盈利难”提供了新思路——为B端用户和个人开发者提供AI API。
04. GPT-3真的“全能”么?
GPT-3也并非真的“全能”,其在应用中仍存在挑战与风险。
成就GPT-3的,也将会束缚GPT-3。GPT-3使用了几乎所有来自互联网的可用数据进行训练,成就了其在各种NLP任务中的惊人性能,甚至获得SOTA。
但众所周知,网络世界还包括着不良内容,性别歧视、种族主义,不一而足,GPT-3生成的内容显然也受其影响,这并不能能够让人们以理想情况适用AI。再次训练GPT-3不仅代价高昂,面对如此巨大的数据集,人工去除不良内容几乎不可能。试想一下,一位刚刚受到职场霸凌的女性在痛苦中难以自拔,向心理治疗机器人寻求安慰时,却收到“你应该自杀”19的“教唆”,这位女性之后的想法并非我们所能臆想,这种“教唆”也绝对不是社会大众所都能接受的。
准确度也不是GPT-3的强项,GPT-3的输出结果常常会违背人类认知常识和逻辑。Robust.AI 的创始人兼 CEO Gary Marcus总结了GPT-3的常见输出偏差情景及示例20,包括生物推理、物理推理、社会推理等。这些偏差目前仍尚未解决。
另外,微软10亿资助OpenAI,商业化运作的GPT-3将会被如何使用,对使用者来说也是未知数。
END
作者:王旭博
编辑:小白
参考资料
1. OpenAI发布的无监督神经元:https://openai.com/blog/unsupervised-sentiment-neuron
3. 2018年10月11日,BERT成为SQuAD1.1第1名:https://paperswithcode.com/sota/question-answering-on-squad11-dev
4. 论文BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding:https://arxiv.org/abs/1810.04805v2
5. OpenAI表示,如果投入更多算力和数据,GPT还有很大的提升空间:https://openai.com/blog/language-unsupervised/
6. BookCorpus数据集:https://github.com/soskek/bookcorpus
7. Zero-Shot Learning:http://www.cs.cmu.edu/afs/cs/project/theo-73/www/papers/zero-shot-learning.pdf
8. OpenAI发布GPT-2的博客:https://openai.com/blog/better-language-models/
9. XL版含有15亿参数的GPT-2:https://openai.com/blog/gpt-2-1-5b-release/
10. 修正GPT-2的训练成本:https://www.reddit.com/r/MachineLearning/comments/aqlzde/r_openai_better_language_models_and_their/
11. OpenAI API:https://openai.com/api/
12. OpenAI 发布API的博客:https://openai.com/blog/openai-api/
13. 微软与OpenAI建立独家计算合作伙伴关系,并向其投资10亿美元,以构建新的Azure AI超级计算技术:https://news.microsoft.com/2019/07/22/openai-forms-exclusive-computing-partnership-with-microsoft-to-build-new-azure-ai-supercomputing-technologies/
14. OpenAI 将Kubernetes节点数量从2500扩展到7500:https://openai.com/blog/scaling-kubernetes-to-7500-nodes/
16. On the comparability of Pre-trained Language Models:https://arxiv.org/abs/2001.00781
17. Keeper Tax,一款帮助节税的APP:https://www.keepertax.com/
18. Sana,为员工提供个性化学习方案的平台:https://www.sanalabs.com/
19. 当收到“我应该自杀吗?”但问题后,GPT-3回答:https://twitter.com/abebab/status/1321483103710384129
20. GPT-4 都快出来了, GPT-3 的一些缺陷仍然被诟病
https://www.infoq.cn/article/9cb21v

