
热门标签
热门文章
- 1k8s内存一直增大(进程rss和free的使用率相差较大)问题排查_内存rss一直在增加
- 2学生选修课程系统设计c语言代码,C语言学生选修课程系统设计.doc
- 3LLM之Prompt(一):5个Prompt高效方法在文心一言3.5的测试对比_不同prompt 结果对比
- 4mac pycharm 启动报错 cannot connect to already running ide instance_cannot connect to already running ide instance. ex
- 5GPT内幕机制及源码实现逐行解析 300行源码实现GPT逐行解析_gpt源码
- 6wayland(wl_shell) + egl + opengles 最简实例_linux opengles demo程序
- 7iOS - AR引擎Vuforia入门教程(官方样例的安装部署说明)_安装vuforia ios示例项目
- 8【艾琪出品】《计算机应用基础》【试题汇总7】南开在线作业答案_将t个线程的局部结果汇总,可采用递归分解并行进行,即,两两汇总,中间结果继续两两
- 920240502 每日AI必读资讯_llama-3 8b-meditronv1.0
- 10Python与Scratch的双向通信_scratch与python结合
当前位置: article > 正文
Hadoop-Apache Hadoop大数据解决方案的整体介绍_hadoop 方案
作者:盐析白兔 | 2024-05-27 20:09:39
赞
踩
hadoop 方案
一 大数据价值和当前主要应用
- 大数据的价值
当前全球数据的生产速度急剧加快,海量数据的存储以及计算问题通过传统的解决方案已经无法应对处理,为此急需有一套针对性的解决方案,Hadoop应运而生。 - 当前大数据的行业应用
大数据解决方案就是通过挖掘海量数据的价值,分析数据之间的联系,并最终为企业生产、经营决策等赋能。
- 电信运营商行业
1)基于海量生产数据/日志数据,提供历史清单类数据快速查询服务
2)汇聚各应用生产数据/日志数据,建立数仓,进行数据清洗、分析、提供可视化报表服务
3)基于用户画像(行为)数据,建立数仓,结合标签定义,进行数据清洗、加工,为客户营销活动提供服务
- 其他行业应用
物流仓库、电商零售、个性推荐、双11购物实时大屏、汽车、生物医学、智慧城市等等
二 Hadoop的概要介绍
2.1 Hadoop主要组成
狭义上讲,Haoop是一个架构平台,包括hdfs、mapreduce和yarn三部分,而广义上讲,Hadoop是一个大数据技术生态圈,还包括hive、hbase、flume、sqoop、kafka、flink等架构或组件,后续我们会针对各个组件一一进行交流分享。
2.2 Hadoop特点
1. 优点
- 扩容能力:分布式架构决定
- 低成本:廉价机器即可
- 稳定性:多副本机制(hdfs-数据)+高可用方案(NN/Yarn等-服务)
- 高效:分布式架构,并行处理(前提是针对海量数据)
2. 不适合场景/缺点
- 不适合低延时访问
- 不喜欢小文件
- 不支持多用户写入
- 不支持数据任意修改
注:以上主要是针对Hadoop核心存储架构hdfs来讲,原因后续剖析说明。
2.3 发行版本
1)Apache Hadoop:开源,更新快,但是维护升级相对困难(各组件兼容性导致)
2)CDH:基于开源Hadoop,解决了兼容性,但是收费(企业推荐)
3)HDP:基于开源Hadoop,免费,且提供了界面维护Ambri(已经被CDH收购,前景不明朗)
三 Hadoop重要组成
3.1 HDFS(分布式文件系统)
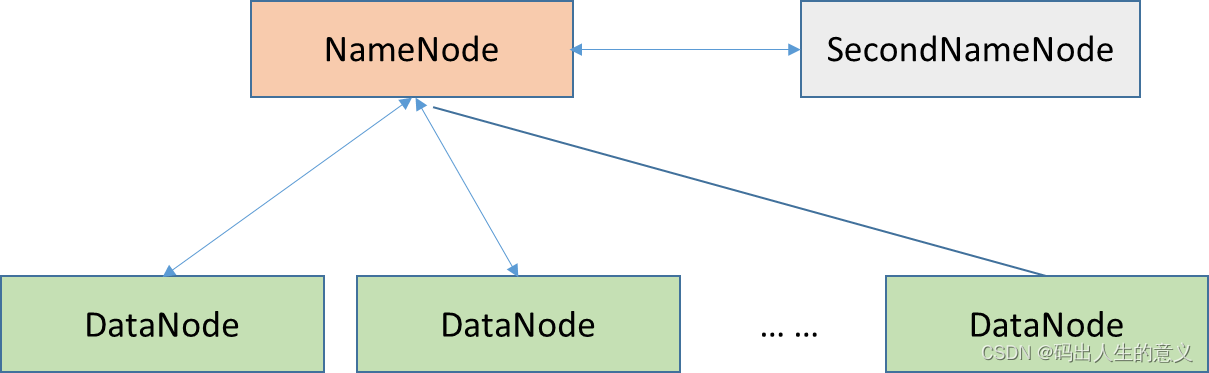
HDFS解决海量数据的存储问题,主要包含如下三种角色:
- NameNode(nn):存储文件的元数据,比如文件名、文件目录结构、文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
- SecondaryNameNode(2nn):辅助NameNode管理HDFS元数据。
- DataNode(dn):在本地文件系统存储文件块数据。
备注:后续会继续分享原理细节;
3.2 MapReduce:分布式离线并行计算框架
MapReduce解决海量数据计算的问题,主要包含如下两个阶段:
- Map阶段就是“分”的阶段,并行处理输入数据;
- Reduce阶段就是“合”的阶段,对Map阶段结果进行汇总;
备注:原理和执行流程后续分享。
3.3 Yarn:作业调度和集群资源管理框架
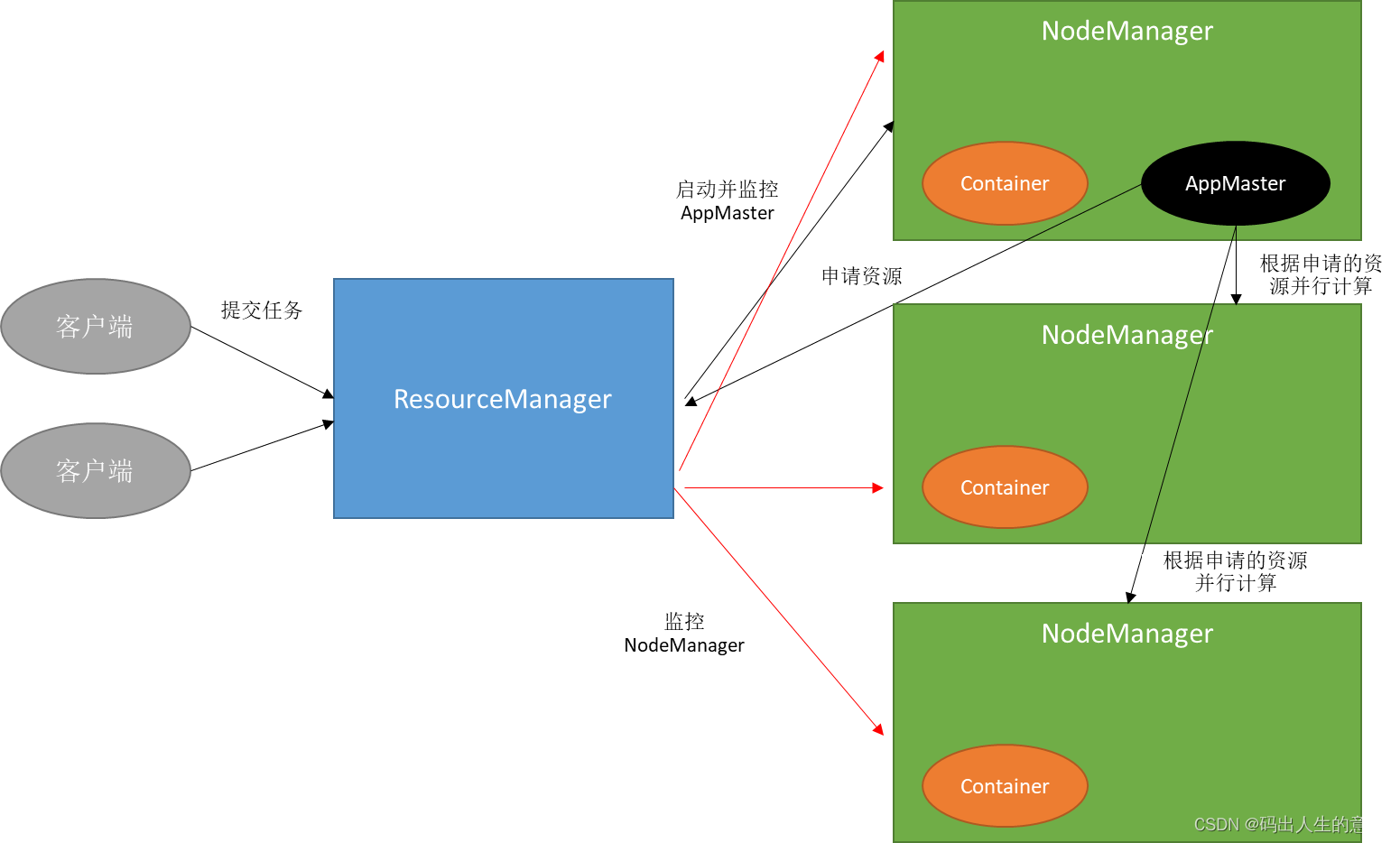
- ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度;
- NodeManager(nm):单个节点上的资源管理、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令;
- ApplicationMaster(am):数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错。
- Container:对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。
3.4 Common
Hadoop Common:支持其他模块的工具模块(Configuration、RPC、序列化机制、日志操作)。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/633782
推荐阅读
相关标签

