
热门标签
热门文章
- 12024年最新AI测试|Windows下跑起大模型(Llama)操作笔记_软件测试大模型,2024大厂软件测试面试必问题目_windows下跑大模型
- 2Android10.0 日志系统分析(三)-logd、logcat读写日志源码分析-[Android取经之路]_android logd代码移植
- 3论文阅读之Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer(2020)
- 4为开发者们准备的超棒的jQuery插件_icheck damir sultanov
- 5MindOpt APL,可以支持调用几十种求解器的建模语言_求解器数据建模语言
- 6Windows-Pycharm-Docker-cuda11.4配置镜像-常用命令记录_win10 docker cuda
- 7uni-app在hbuilderx打开微信开发工具运行_hbuild 微信开发者工具路径
- 8微型四轴飞行器(5)九轴姿态融合算法A_九轴融合算法
- 9在C++使用内联函数的一些限制_内联函数可以用静态吗
- 10Mysql高性能优化笔记(含578页笔记PDF文档),收藏了_高性能mysql第四版 pdf
当前位置: article > 正文
自然语言处理--哈工大LTP的基本使用方法_sentencesplitter
作者:盐析白兔 | 2024-05-28 12:39:14
赞
踩
sentencesplitter
导入
from pyltp import SentenceSplitter,Segmentor, Postagger, Parser,NamedEntityRecognizer, SementicRoleLabeller
sentence='小勇硕士毕业于北京语言大学,目前在中科院软件所工作。'
- 1
- 2
SentenceSplitter——————————分句
Segmentor ————————————分词(cws.model)
Postagger—————————————词性标注(pos.model)
Parser——————————————依存句法分析(parser.model)
NamedEntityRecognizer——————命名实体识别 (ner.model)
SementicRoleLabeller———————词义角色标注(pisrl_win.model)
对应如下五个模型

1.SentenceSplitter 分句
sents = SentenceSplitter.split('语言是人类区别其他动物的本质特性。在所有生物中,只有人类才具有语言能力。')
print(type(sents))
print(list(sents))
- 1
- 2
- 3
输出:
<class 'pyltp.VectorOfString'>
['语言是人类区别其他动物的本质特性。', '在所有生物中,只有人类才具有语言能力。']
- 1
- 2
2.Segmentor分词(cws.model)
segmentor = Segmentor()
segmentor.load("C:/Users/angel/Desktop/text-analysis/model/cws.model")
words=segmentor.segment(sentence)
print(type(words))
words=list(words)
print(words)
segmentor.release()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
输出:
<class 'pyltp.VectorOfString'>
['小勇', '硕士', '毕业', '于', '北京', '语言', '大学', ',', '目前', '在', '中科院', '软件所', '工作', '。']
- 1
- 2
3.Postagger词性标注(pos.model)
postagger=Postagger()
postagger.load("C:/Users/angel/Desktop/text-analysis/model/pos.model")
postags=postagger.postag(words)
print(type(postags))
postags=list(postags)
print(postags)
postagger.release()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
输出;
<class 'pyltp.VectorOfString'>
['nh', 'n', 'v', 'p', 'ns', 'n', 'n', 'wp', 'nt', 'p', 'j', 'n', 'v', 'wp']
- 1
- 2
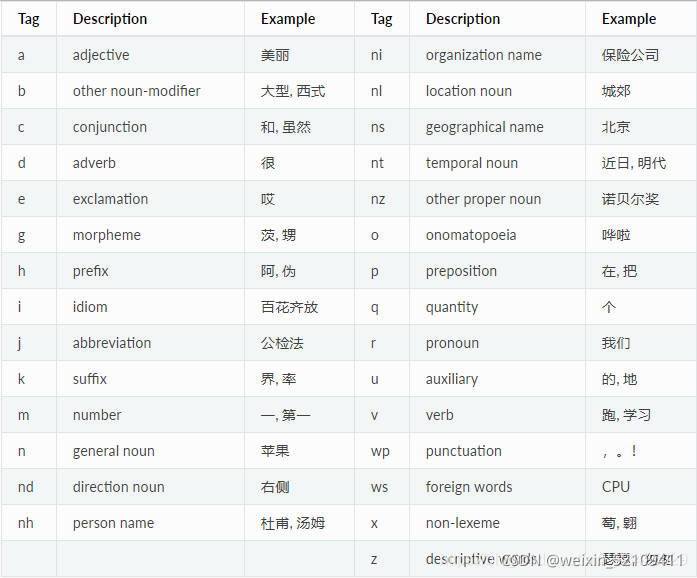
4.Parser依存句法分析(parser.model)
parser = Parser()
parser.load("C:/Users/angel/Desktop/text-analysis/model/parser.model")
arcs=parser.parse(words, postags)
print(type(arcs))
for index,i in enumerate(arcs):
print(words[i.head-1],'\t',words[index],'\t',i.relation)
parser.release()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
arc.head表示依存弧的父节点词的索引。ROOT节点的索引是0,第一个词开始的索引依次为1,2,3…
arc.relation表示依存弧的关系
输出:
<class 'pyltp.VectorOfParseResult'>
硕士 小勇 ATT
毕业 硕士 SBV
。 毕业 HED
毕业 于 CMP
大学 北京 ATT
大学 语言 ATT
于 大学 POB
毕业 , WP
工作 目前 ADV
工作 在 ADV
软件所 中科院 ATT
在 软件所 POB
毕业 工作 COO
毕业 。 WP
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
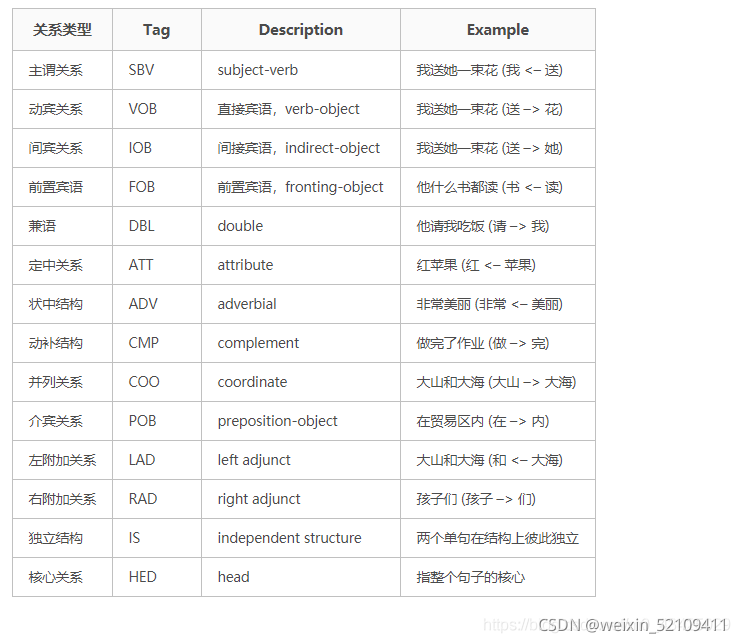
5.NamedEntityRecognizer命名实体识别(ner.model)
recognizer = NamedEntityRecognizer()
recognizer.load("C:/Users/angel/Desktop/text-analysis/model/ner.model")
recognize_name=recognizer.recognize(words, postags)
print(type(recognize_name))
recognize_name=list(recognize_name)
print(recognize_name)
recognizer.release()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
输出:
<class 'pyltp.VectorOfString'>
['S-Nh', 'O', 'O', 'O', 'B-Ni', 'I-Ni', 'E-Ni', 'O', 'O', 'O', 'O', 'O', 'O', 'O']
- 1
- 2

6.SementicRoleLabeller词义角色标注(pisrl_win.model)
labeller = SementicRoleLabeller()
labeller.load("C:/Users/angel/Desktop/text-analysis/model/pisrl_win.model")
roles=labeller.label(words, postags, arcs)
print(type(roles))
roles_dict = {}
for role in roles:
roles_dict = [(arg.name, arg.range.start, arg.range.end) for arg in role.arguments]
print(roles_dict)
labeller.release()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
输出:
[dynet] random seed: 1509254310
[dynet] allocating memory: 2000MB
[dynet] memory allocation done.
<class 'pyltp.SementicRoles'>
[('TMP', 8, 8), ('LOC', 9, 11)]
- 1
- 2
- 3
- 4
- 5

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/637609
推荐阅读
相关标签

