
- 1如何让大模型变得更聪明?
- 2CUDA的安装 — 用自己电脑的GPU跑深度学习模型_显卡跑深度学习
- 3pytorch入门10--循环神经网络(RNN)_pytorch rnn
- 4数组和广义表 讲义实现_数组与广义表基本操作c
- 5贝叶斯条件概率/贝叶斯网络_多元贝叶斯公式
- 6世界第一个AI软件工程师DEVIN AI 问世!_世界首位ai工程师
- 7数据库——JDBC(Java DataBase Connection数据库连接)_database connection: usm 172.18.195.11:54321 usm
- 8来自各大面经的一股清流 腾讯三面+华为三面【面试经验分享篇】_华为 面经 反问
- 9内网渗透神器(Mimikatz)——使用教程,你会的还只有初级工程师的技术吗_mimikatz.exe
- 10聚类算法之k均值聚类(K-Means)_k均值聚类算法
Hadoop学习_hdfs setfacl命令
赞
踩
Hadoop的安转
一 、准备工作
1、设置静态地址(必须的)
为了防止IP变化集群中的节点无法沟通
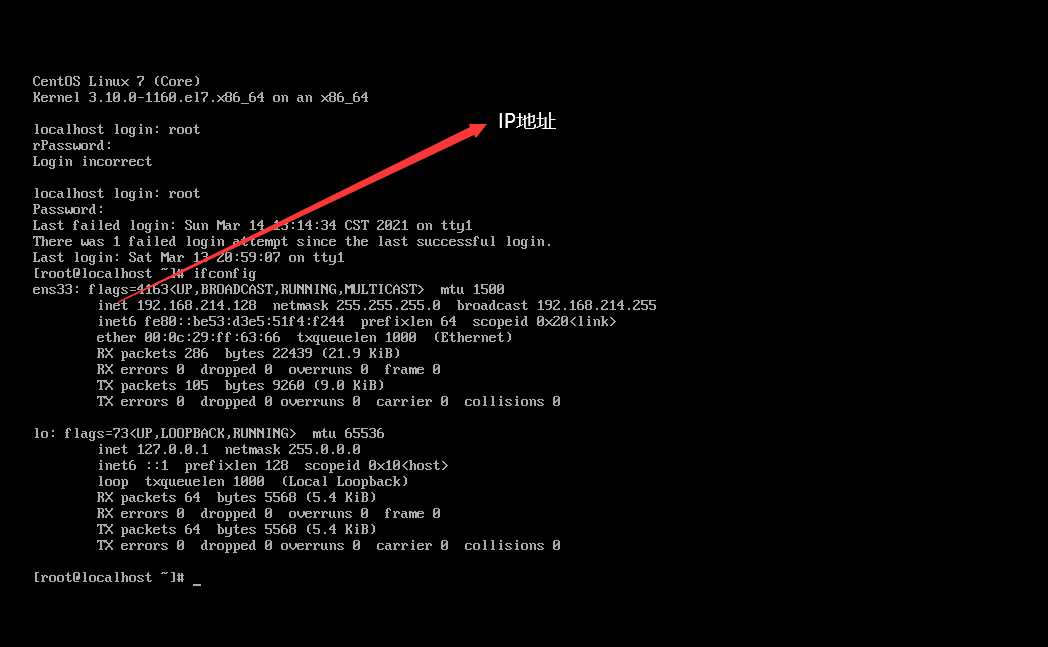
sudo vim /etc/sysconfig//network-scripts/ifcfg-ens33
如果提示你找不到命令就参考如下博客
执行完成后会进入如下界面输入(:set nu) 会出现行号,输入 i 进入插入模式,修改第四行的dhcp(表示动态的)改为static(表示静态)
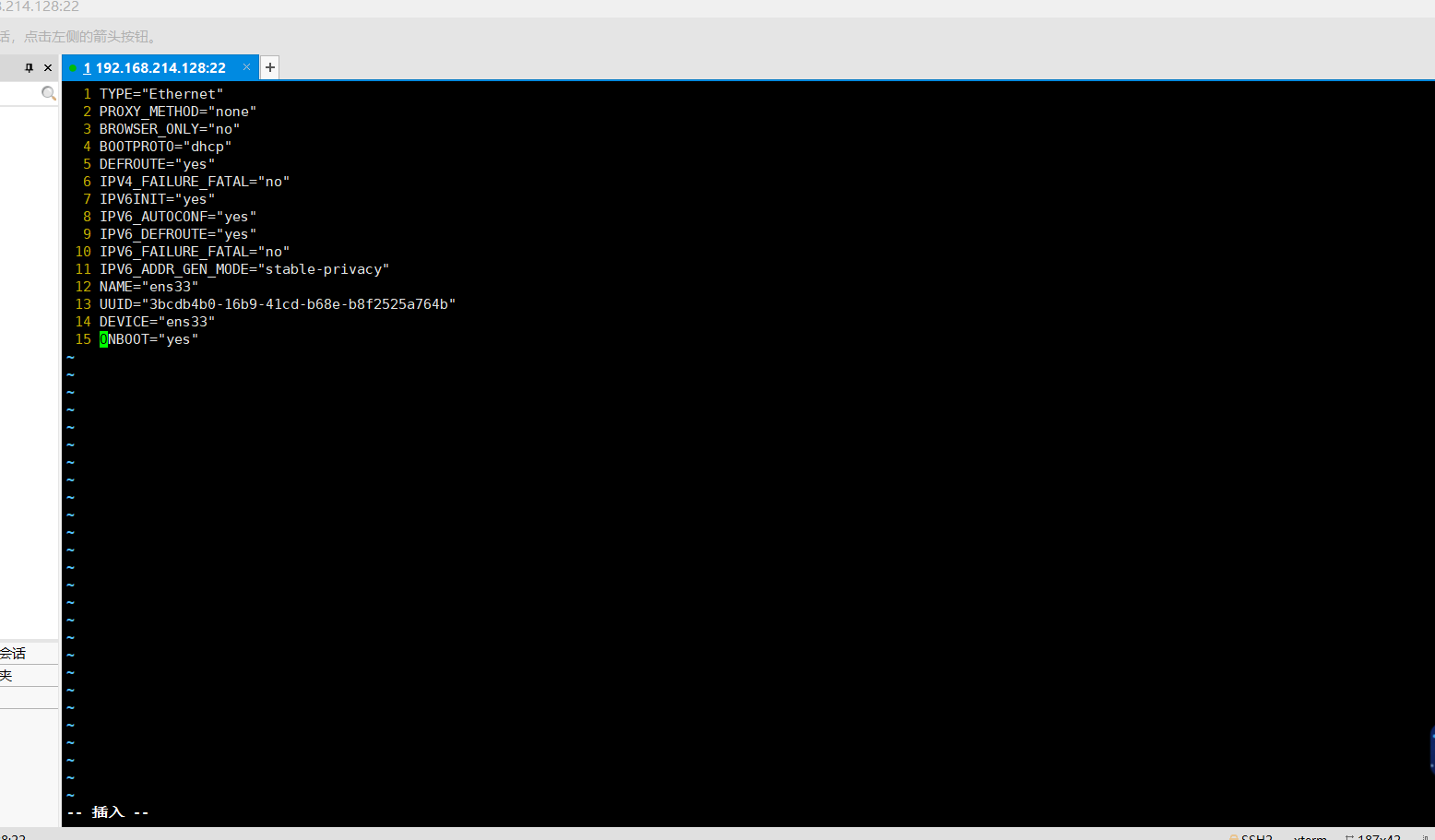
改为如下界面
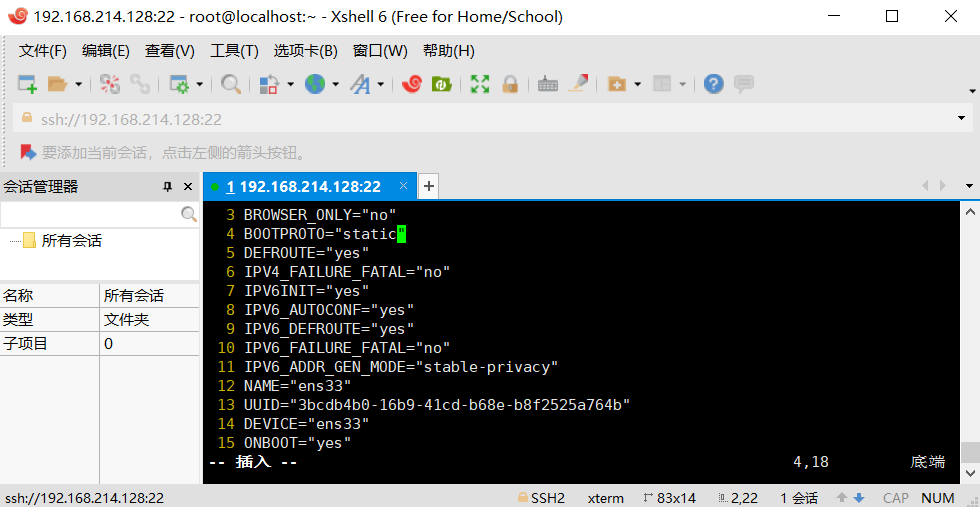
查看自己的IP
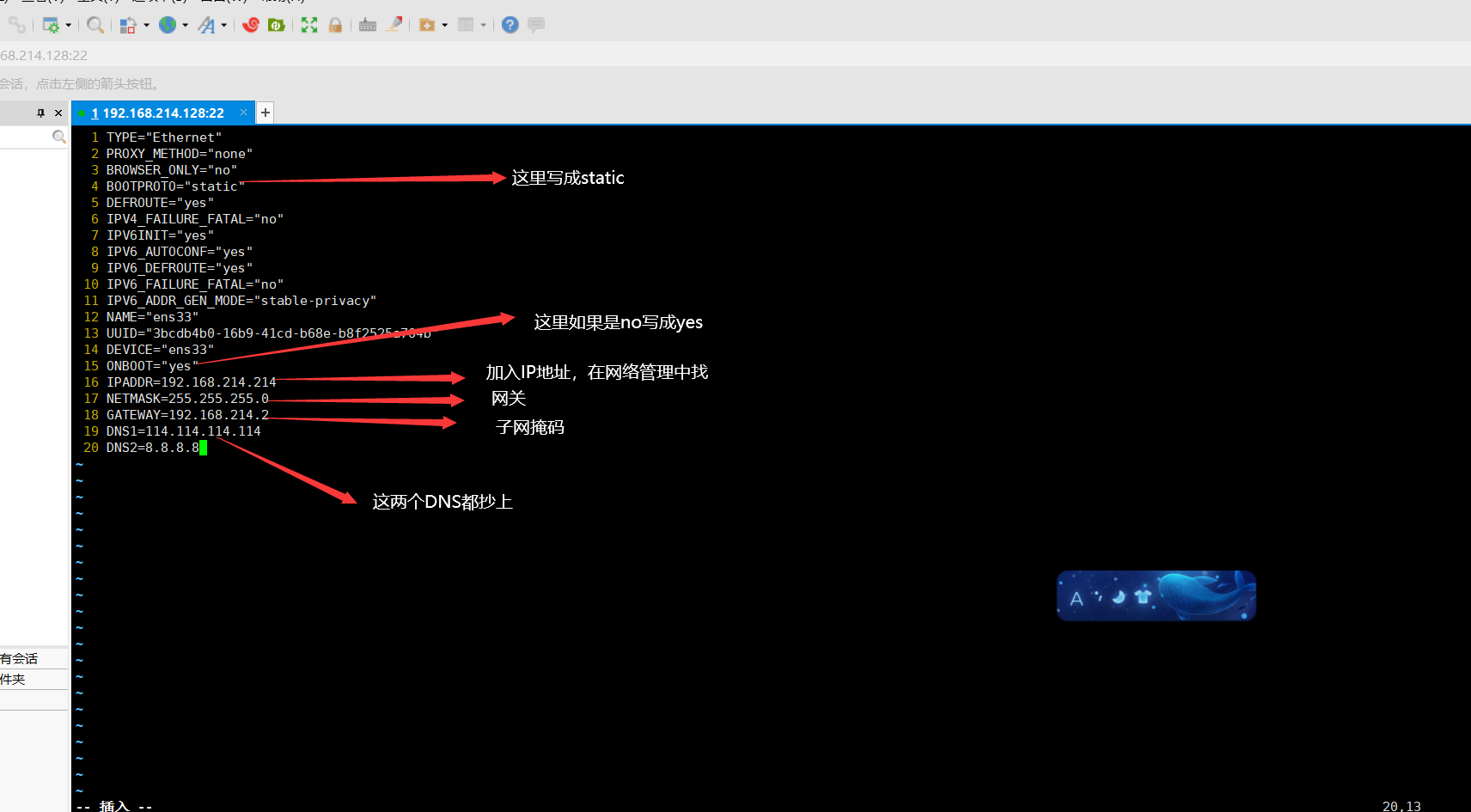
改完以后按esc键退出插入模式,然后按**:wq**
重新启动网络服务:sudo systemctl restart network
2、修改主机名(必须)
命令:sudo vim /etc/hostname
在如下界面中按两次 d 在输入 i 进入插入模式在输入新的主机名如:bigdata 然后按esc键退出插入模式,输入命令 :wq 保存退出
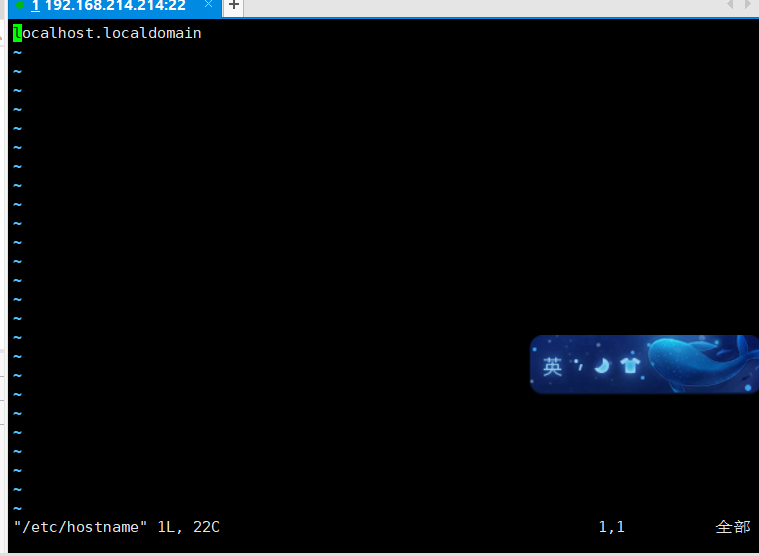
修改之后输入命令:reboot 重启之后就可以看到主机名被改了
3、修改hosts文件(IP地址和主机映射必须的)
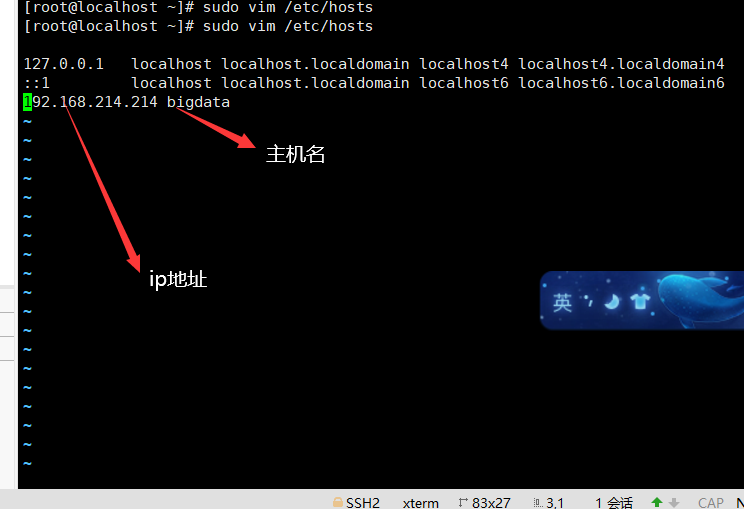
输入命令:sudo vim /etc/hosts
然后输入 i 进入插入模式 输入完成后,在按esc键退出插入模式,然后再输入**:wq**保存退出
4、关闭防火墙
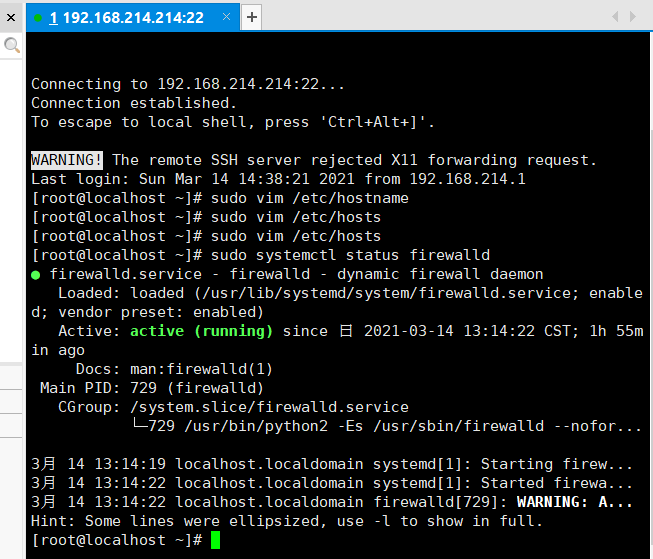
输入命令:sudo systemctl status firewalld
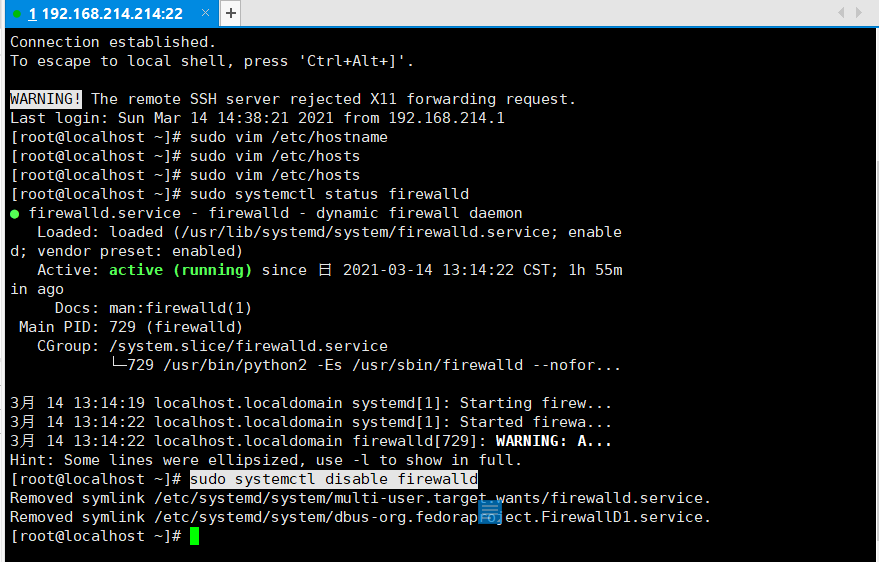
永久关闭防火墙:sudo systemctl disable firewalld
5、关闭selinux-linux系统
先进入插入模式修改完在退出插入模式在保存退出

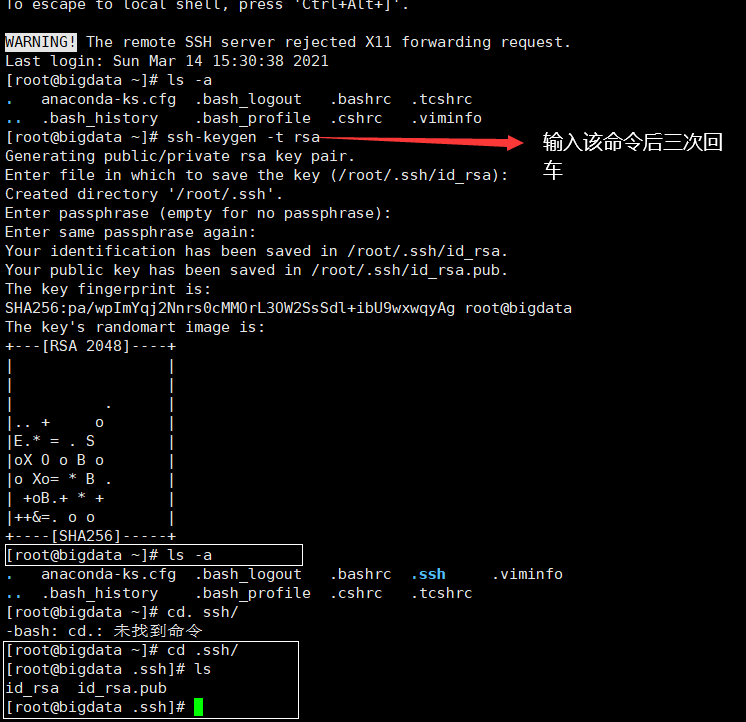
6、SSH免密登陆
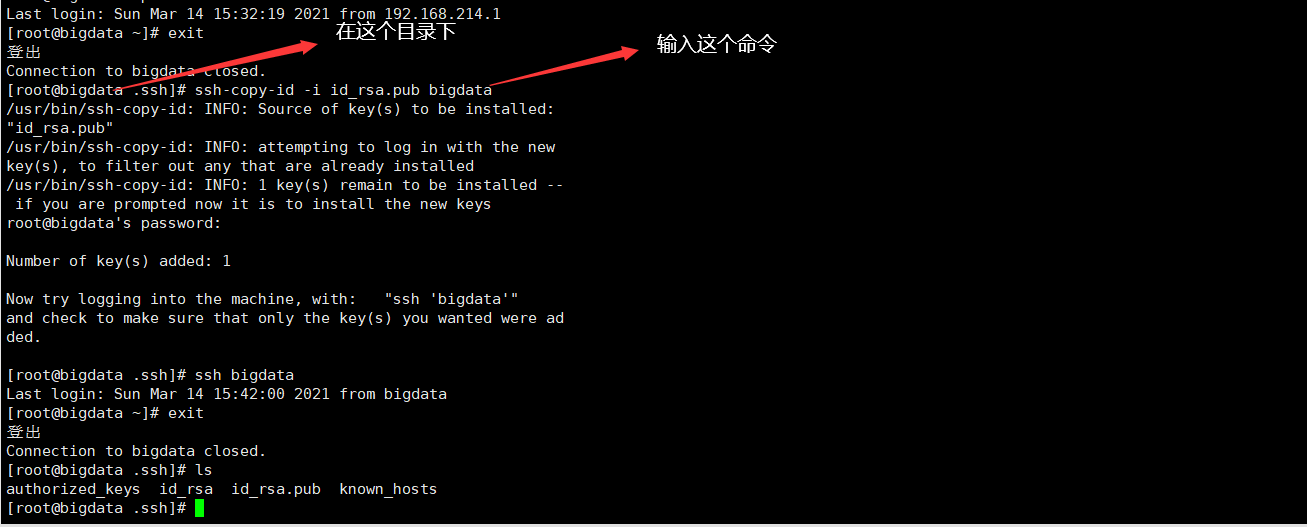
二、安转Java
1、卸载原来的Java

2、上传Java
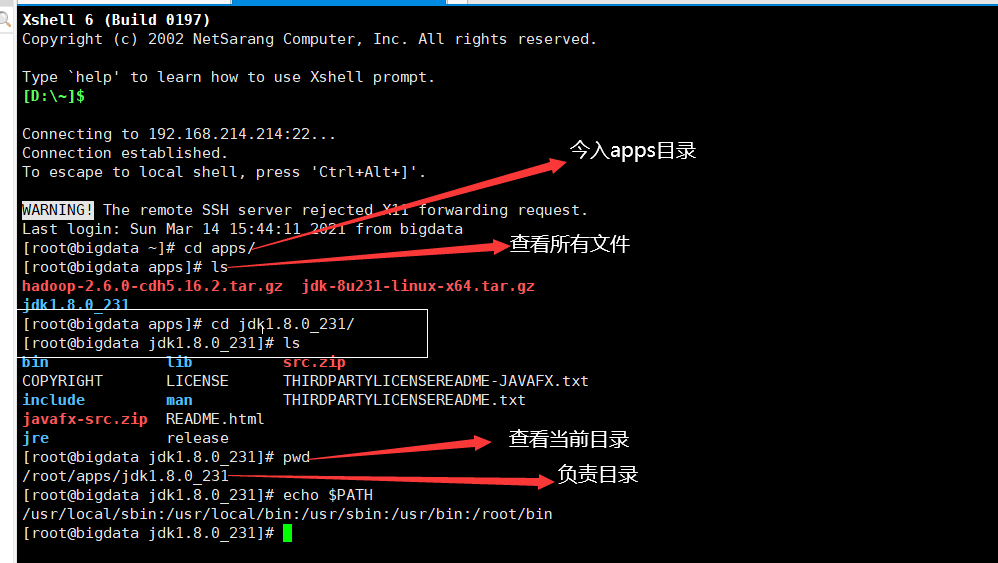
- 在家目录下创建一个apps目录:mkdir apps
- 让后上传安装包到apps目录下
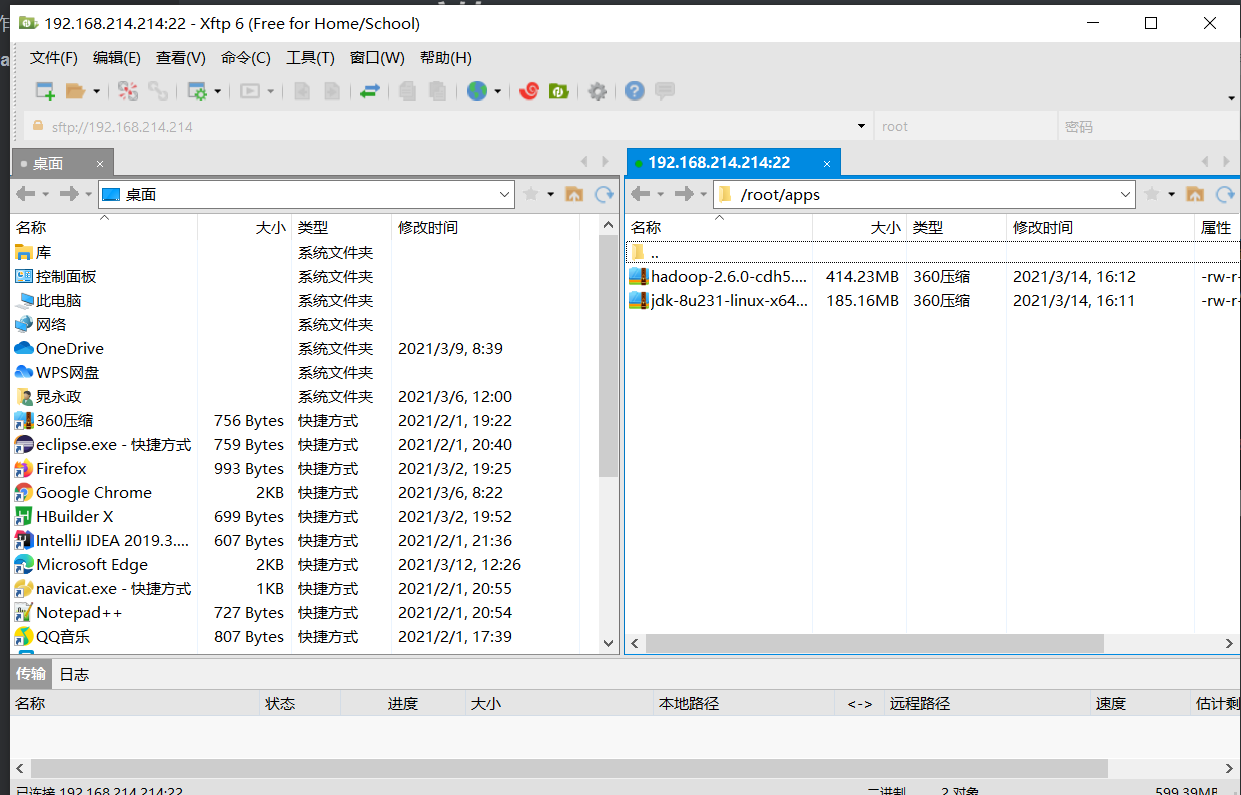
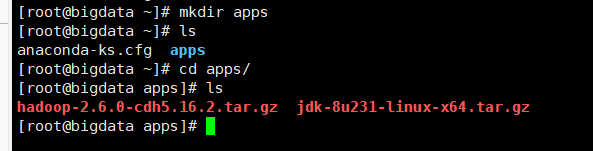
3、解压Java
输入下图命令:


4、配置环境变量
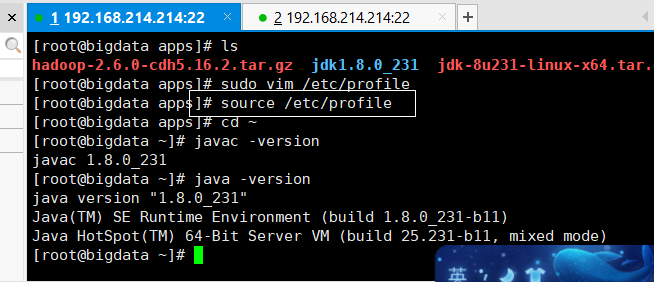
输入命令:sudo vim /etc/profile
进入如下界面:
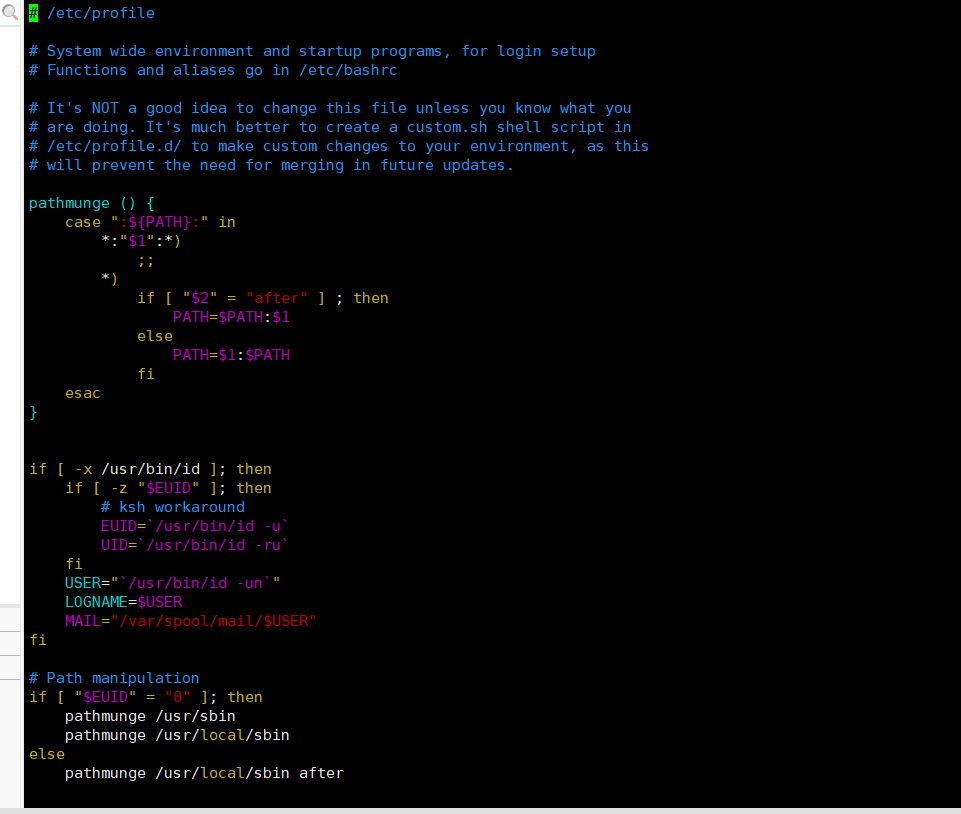
然后点开大写键在输入g就可以把光标移到最下面如下图:
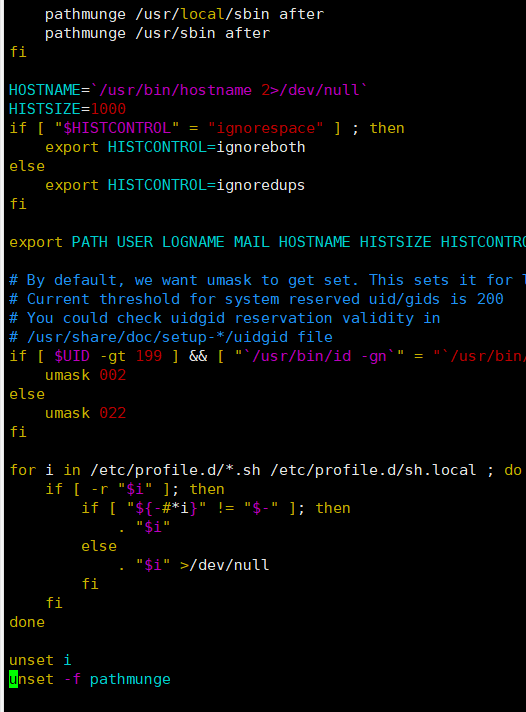
然后
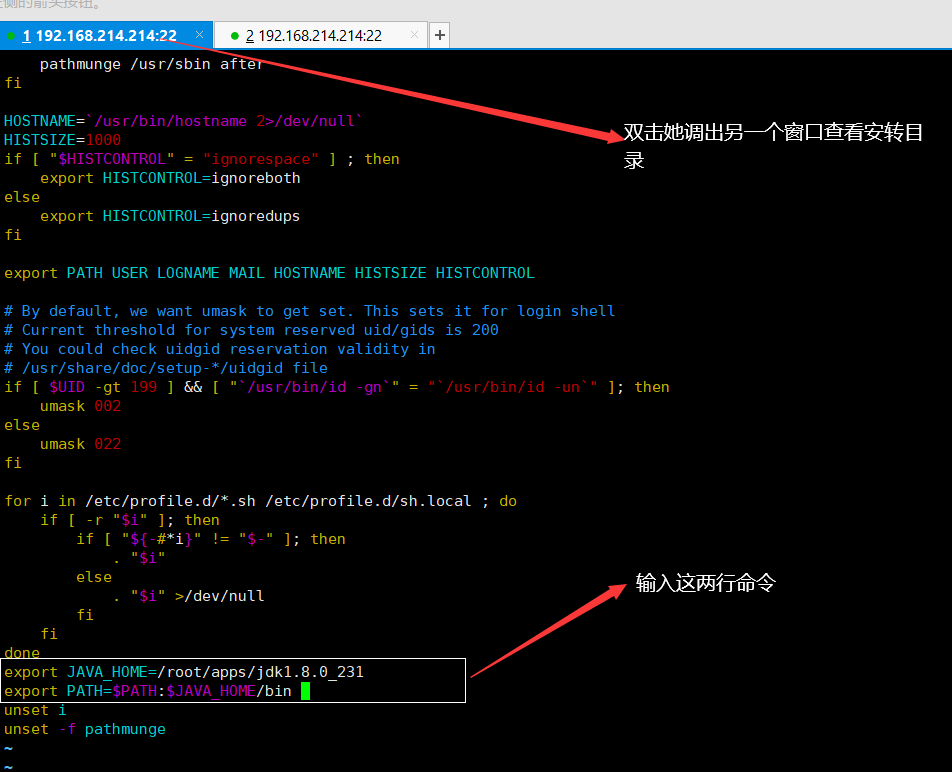
最后输入source
三、配置Hadoop环境变量
输入命令:
-
export HADOOP_HOME=/root/apps/hadoop-2.6.0-cdh5.16.2
-
export PATH= P A T H : PATH: PATH:JAVA_HOME/bin: H A D O O P H O M E / b i n : HADOOP_HOME/bin: HADOOPHOME/bin:HADOOP_HOME/sbin
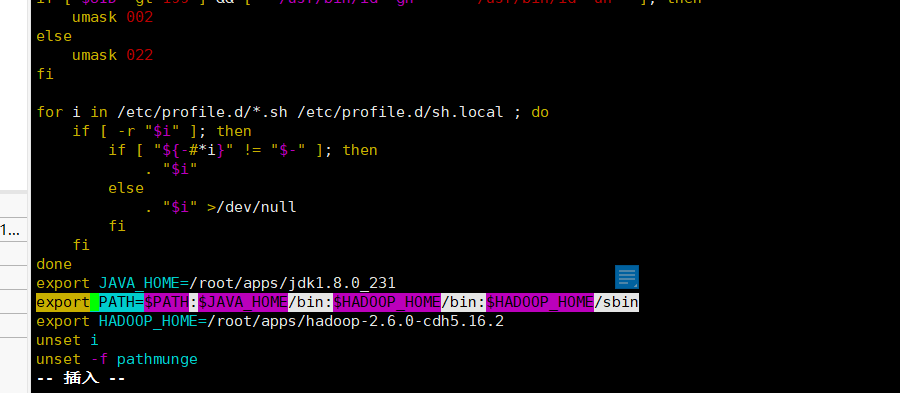
-
hadoop version:查看hadoop安装的版本

四、配置HDFS
1、修改hadoop-env.sh
输入命令:cd /root/apps/hadoop-2.6.0-cdh5.16.2/etc/hadoop/hadoop-env.sh
vim hadoop-env.sh:打开该文件
export JAVA_HOME=/root/apps/jdk1.8.0_231/:jdk的安装目录
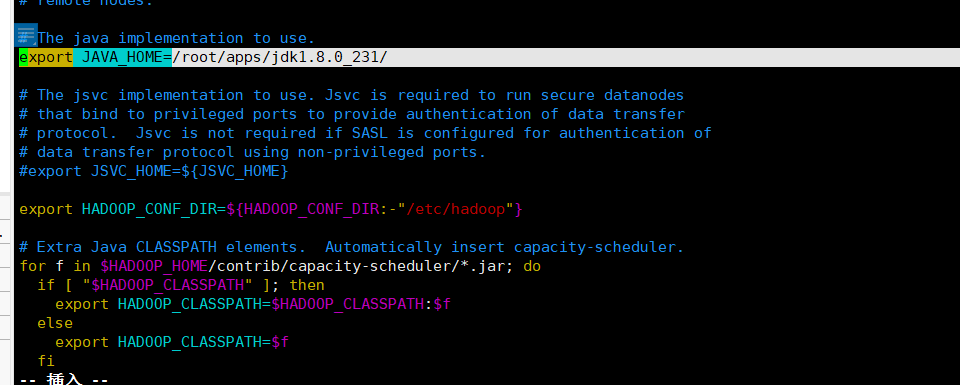
2、修改core-site.xml文件
-
打开core-site.xml:vim core-site.xml
-
fs.defaultFS hdfs://bigdata:9000 hadoop.tmp.dir /root/tmp/hadoop
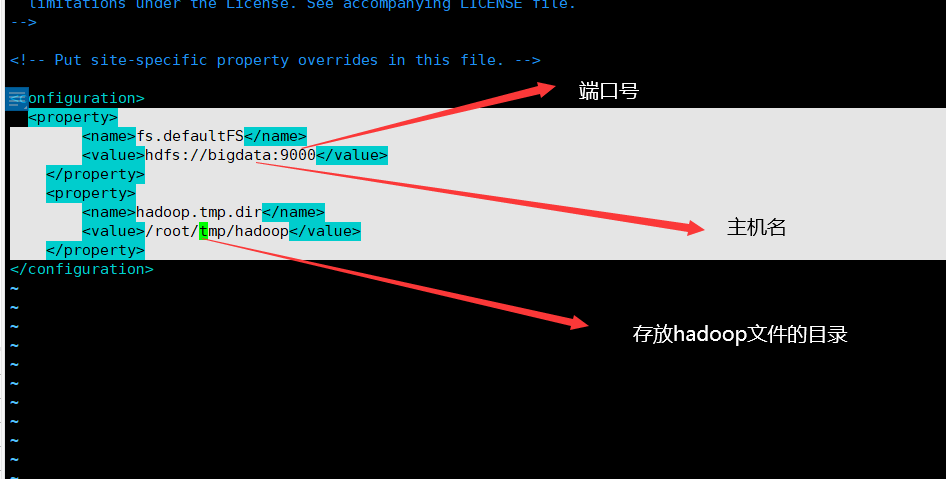
3、修改hdfs-site.xml文件
-
打开hdfs-site.xml文件:vim hdfs-site.xml
-
dfs.replication
1

4、启动测试HDFS
第一步:必须要先格式化(第一次启动)
执行命令:hdfs namenode -format
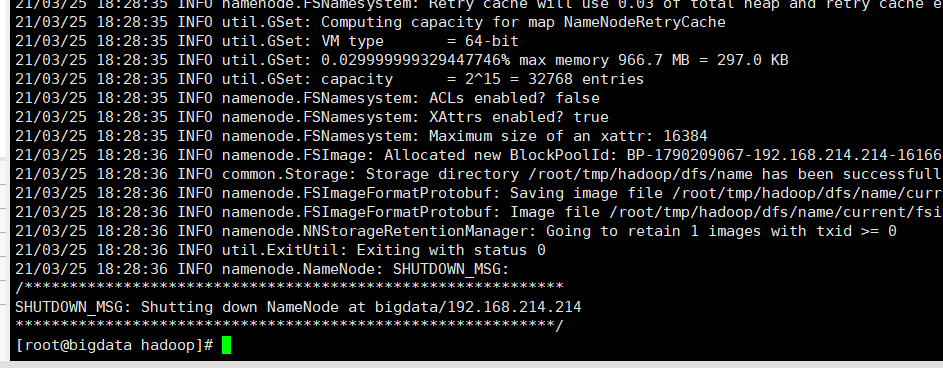
第二步,启动hdfs
start-dfs.sh
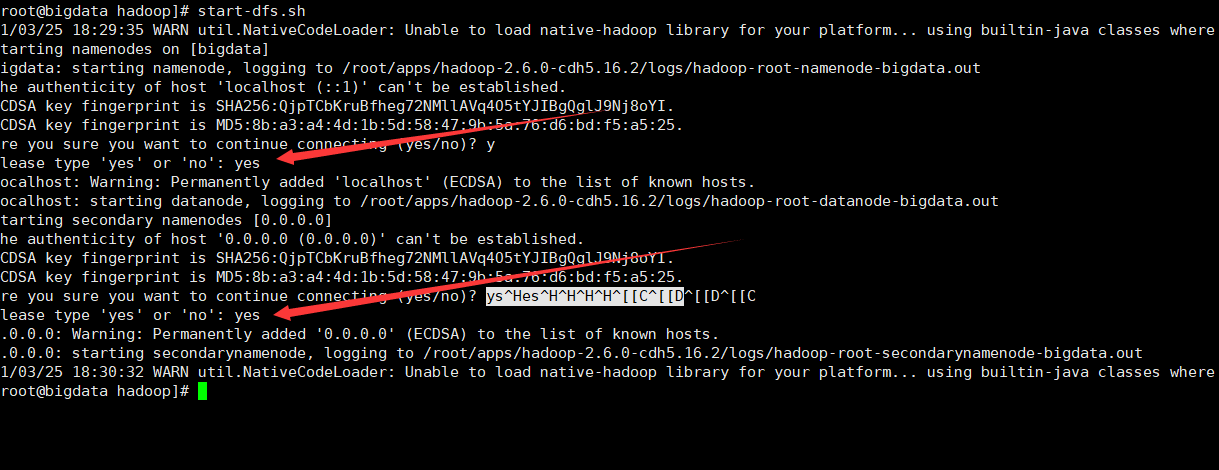
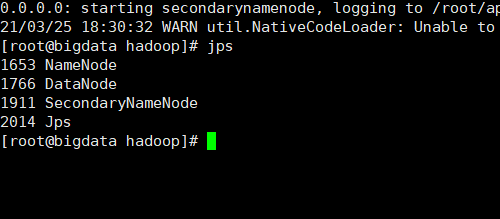
第三步:查看进程
jps
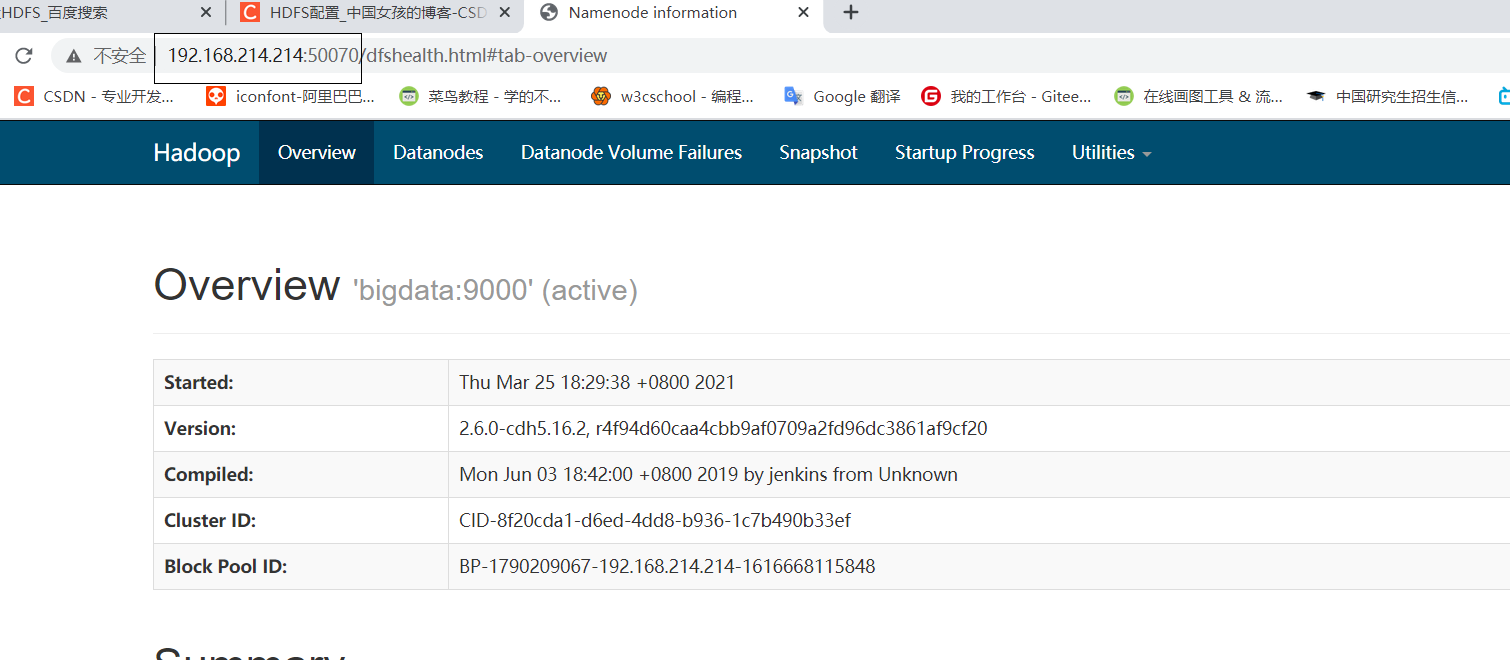
Web网页测试
Ip:50070
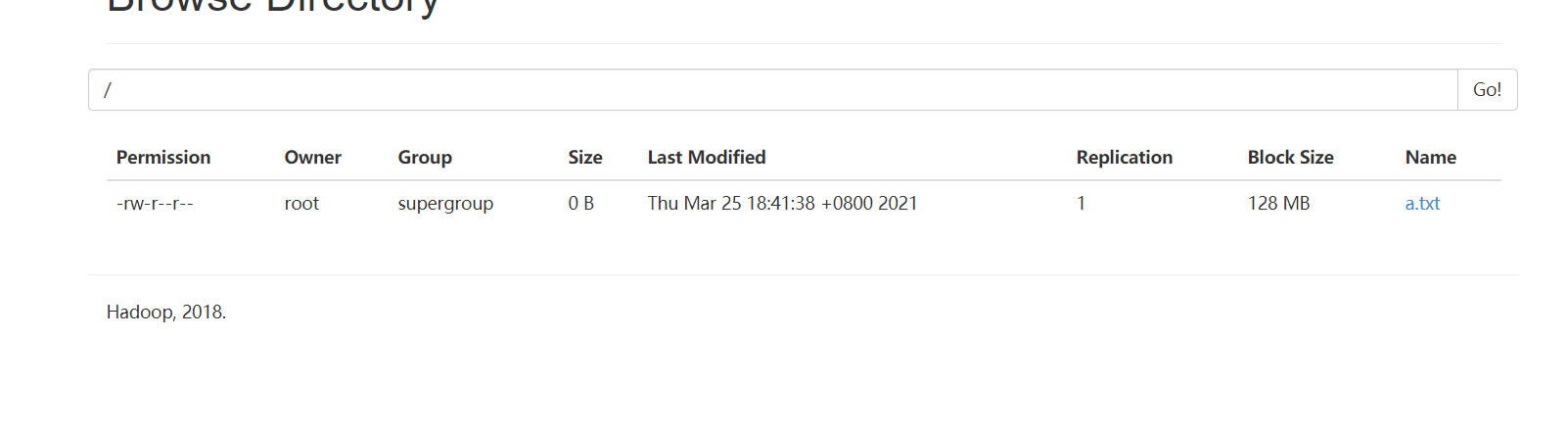
hadoop fs -ls /
touch a.txt
hadoop fs -ls /
hadoop fs -put a.txt /
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ie2IA18L-1617287560119)(C:/Users/晁永政/AppData/Roaming/Typora/typora-user-images/image-20210325184326139.png)]
5、配置YARN及MapReduce
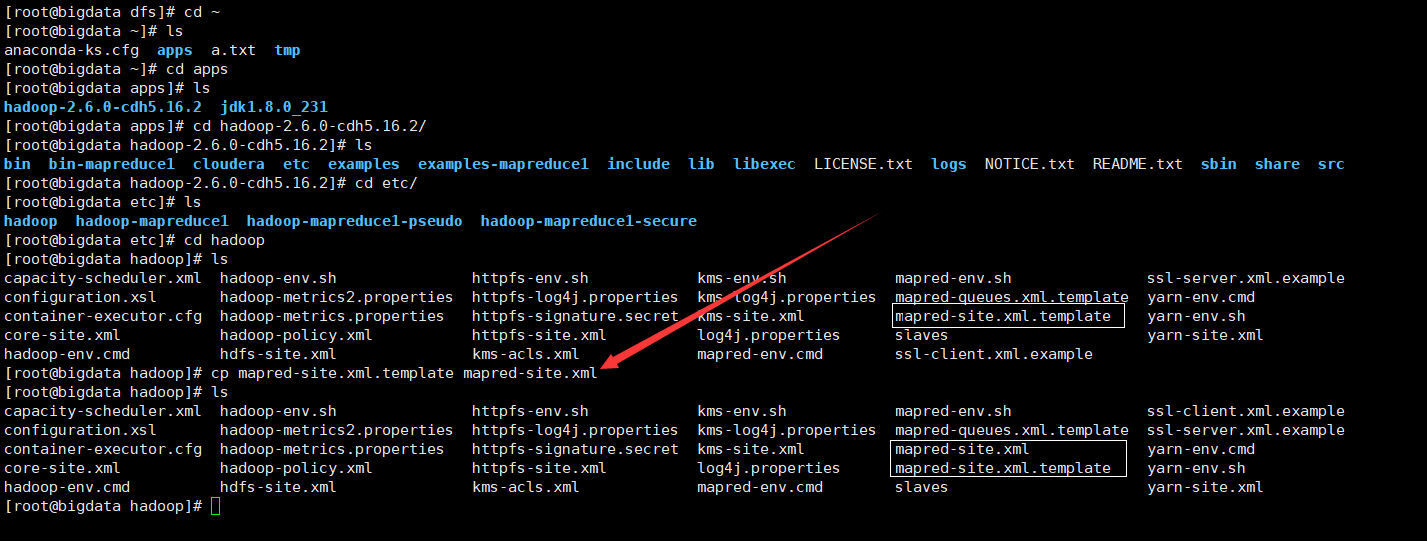
(1)修改mapred-site.xml
通过mapred-site.xml.template创建mapred-site.xml文件
执行 :cp mapred-site.xml.template mapred-site.xml
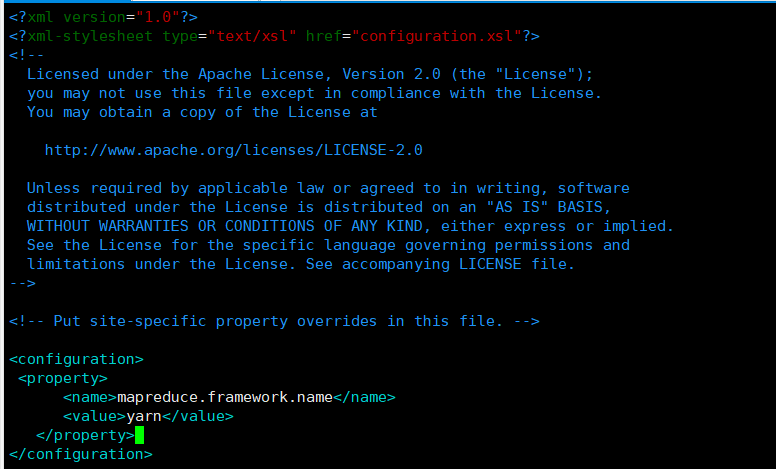
mapreduce.framework.name
yarn
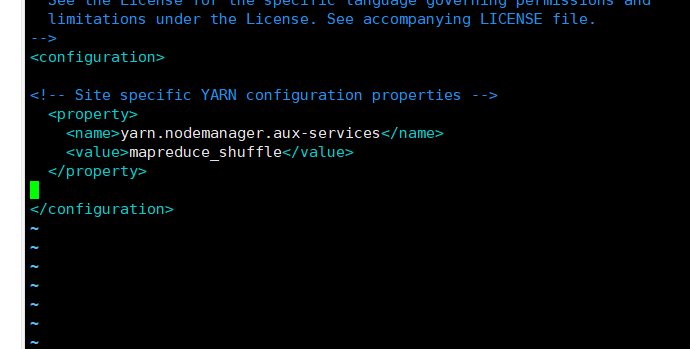
vim yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
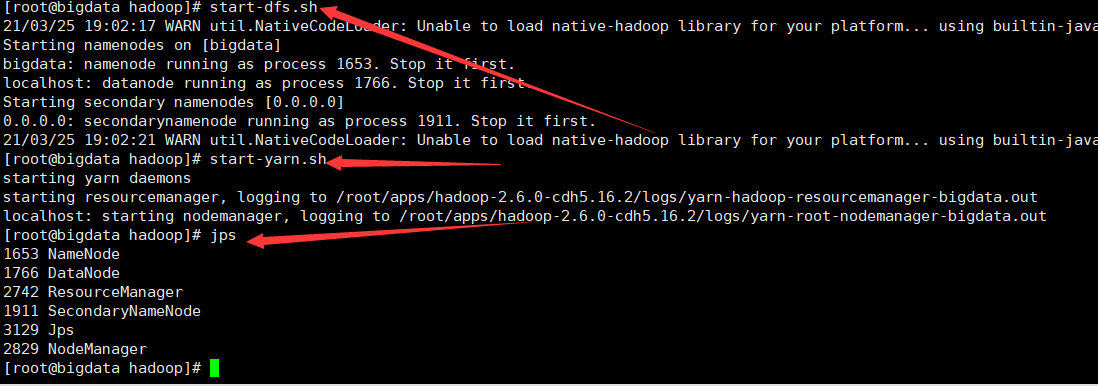
启动hdfs start-dfs.sh hdfs是一个java程序,需要启动
启动 yarn start-yarn.sh yarn是一个java程序,需要启动
Mapreduce只是一个计算框架,他不是一个程序,也不是一个服务
启动测试YARN
start –yarn.sh
Jps进程查看
Web****网页查看
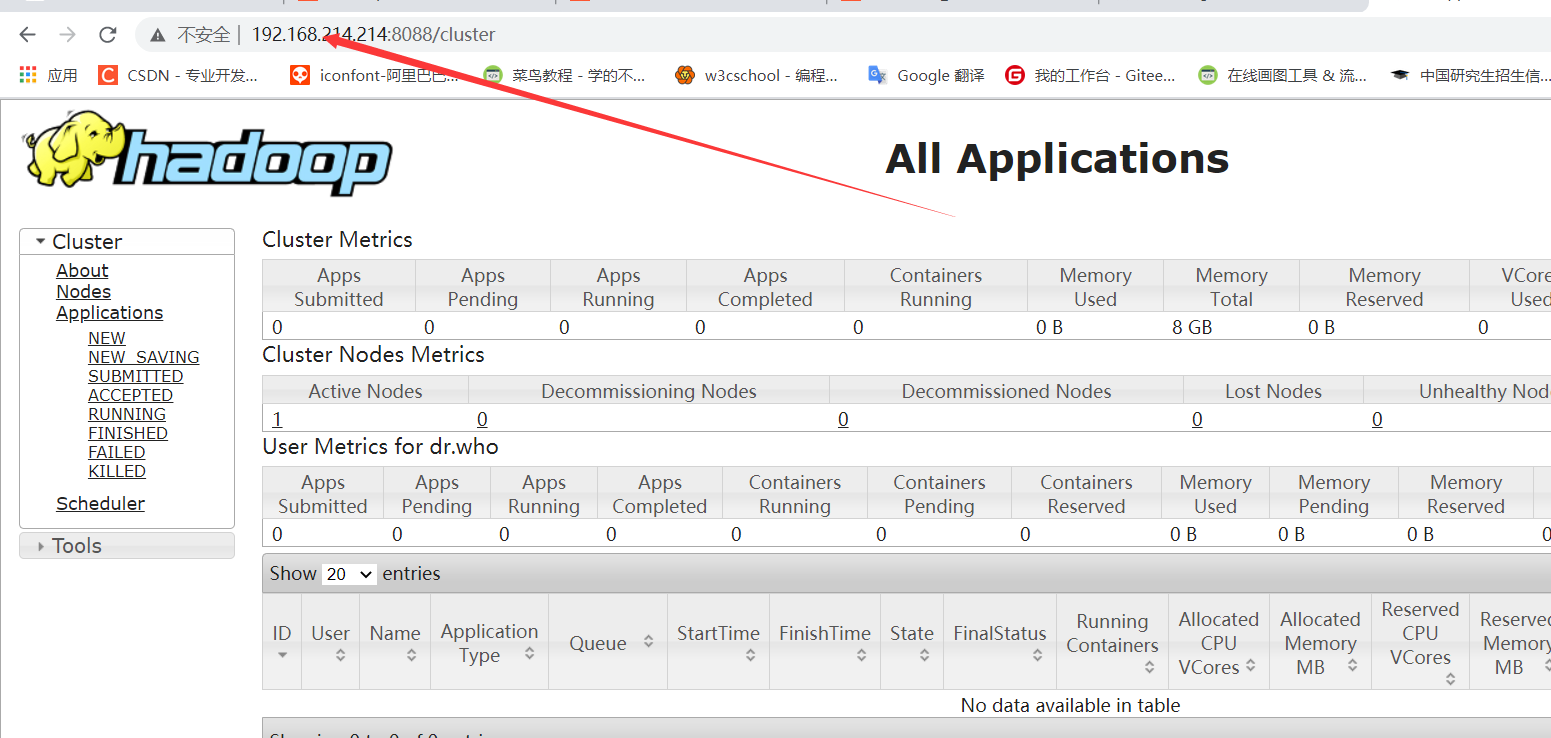
五、集群搭建中遇到的问题
(1)格式化的时候报错
可能是配置文件出错
主机找不到 (1)ip配置出错,(2)ip和主机映射文件出问题
core-site.xml
配置的保存数据的文件 /home/stud,要根据自己的实际目录进行配置
如:/home/xxx/
(2)关于hdfs的格式化问题
如果格式化成功之后,就不要再进行格式化了
如果格式化失败,边修改边进行格式化,一直到必须成功
为什么格式化成功之后不能再进行格式化:
hdfs namenode -format
在格式化的时候,创建了name文件夹(包括里面的文件) VERSION
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LFZtqeWq-1617287560124)(C:/Users/晁永政/AppData/Local/Temp/msohtmlclip1/01/clip_image002.jpg)]
操作hdfs在data的目录中也会有VERSION文字
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lA6OyTQu-1617287560125)(C:/Users/晁永政/AppData/Local/Temp/msohtmlclip1/01/clip_image004.jpg)]
如果再进行一次格式化
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fjXSIUkY-1617287560125)(C:/Users/晁永政/AppData/Local/Temp/msohtmlclip1/01/clip_image006.jpg)]
通过JPS查看的进程就没有datanode
解决以上问题的方法:
. 关闭所有的进程hdfs
. 删除name和data目录,或者把整个/home/stud/tmp
. 重新进行格式化
六、完全分布式安装(以3台为例)
1.进行集群规划
主机名称
IP
HDFS进程
YARN进程
node1
192.168.100.101
Namenode 、datanode
Nodemanager
node2
192.168.100.102
Seconarynamenode、datanode
Nodemanager
node3
192.168.100.103
datanode
Nodemanager、ResourceManager
2.准备工作
2.1修改主机名称
三台机器分别执行 sudo vim /etc/hostname
第一台机器->node1
第二台机器->node2
第三台机器->node3
2.2设置静态的IP的
node1 -> 192.168.100.101
node2-> 192.168.100.102
node3 -> 192.168.100.103
三台主机分别执行sudo vim /etc/sysconfig/network-scripts/ifcfg-ens33,修改静态IP
IPADDR=192.168.214.133
NETMASK=255.255.255.0
GATEWAY=192.168.214.2
DNS1=114.114.114
DNS2=8.8.8.8
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WusjDyvU-1617287560126)(C:/Users/晁永政/AppData/Local/Temp/msohtmlclip1/01/clip_image008.jpg)]
2.3配置hosts文件(主机与IP的映射)
每台主机都执行: sudo vim /etc/hosts,添加以下内容
192.168.100.101 node1
192.168.100.102 node2
192.168.100.103 node3
2.4设置免密码登录(从一台机器登录到另一台机器)
2.4.1生成密钥
在三台机器分别执行ssh-keygen -t rsa
Xshell可以在撰写中将当前的命令发送到全部的窗口执行。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jpkWlgM2-1617287560127)(C:/Users/晁永政/AppData/Local/Temp/msohtmlclip1/01/clip_image010.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xIribL3x-1617287560129)(C:/Users/晁永政/AppData/Local/Temp/msohtmlclip1/01/clip_image012.jpg)]
2.4.2三台主机都要执行下面的操作
互相复制公钥到每台机器(在每台机器中都执行以下三个命令)
ssh-copy-id -i ~/.ssh/id_rsa.pub node1
ssh-copy-id -i ~/.ssh/id_rsa.pub node2
ssh-copy-id -i ~/.ssh/id_rsa.pub node3
2.5关闭防火墙和selinux
关闭防火墙命令:
sudo systemctl stop firewalld
sudo systemctl disable firewalld
关闭selinux:
sudo vim /ect/selinux/config
2.6对主机进行时间同步(让所有的主机时间是一样的)
如果三台主机的时间相差太大,是没办法通信,所以要让所有的主机都在一个时间
如果不能联网则采用date命令设置时间: date –s “2021-04-1 00:00:00”
如果可以联网:使用ntpdate 公用时间服务器
下载ntpdata服务:yum –y install ntpdate
在时间服务器获取时间:ntpdate -u ntp1.aliyun.com (时间服务器可以百度ntp服务器)
3.解压JDK和Hadoop并配置环境变量(在node1中操作)
把JDk和Hadoop的安装包通过xftp工具从win上传到linux
tar -zxvf hadoop-2.6.0-cdh5.16.2.tar.gz
tar -zxvf jdk-8u171-linux-x64.tar.gz
配置环境量:
用户环境变量:.bashrc 或.bash_profile
系统环境变量: /etc/profile
这一次配置用户环境变量:在家目录下执行vim .bash_profile命令,添加以下内容
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dMTLLr3X-1617287560132)(C:/Users/晁永政/AppData/Local/Temp/msohtmlclip1/01/clip_image014.jpg)]
source /etc/profile
4.修改配置文件(在node1中操作)
4.1配置hadoop-env.sh
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uA60Fbtm-1617287560133)(C:/Users/晁永政/AppData/Local/Temp/msohtmlclip1/01/clip_image016.jpg)]
4.2配置 core-site.xml
fs.default.name
hdfs://node1:9000
hadoop.tmp.dir
/home/wangjian/apps/tmp/hadoop
</configuration
4.3配置hdfs-site.xml
dfs.namenode.name.dir
/home/wangjian/apps/tmp/hadoop/dfs/name
dfs.datanode.data.dir
/home/wangjian/apps/tmp/hadoop/dfs/data
dfs.replication
3
dfs.namenode.secondary.http-address
node2:50090
4.4配置mapred-site.xml
先执行这个命令:cp mapred-site.xml.template mapred-site.xml
mapreduce.framework.name
yarn
4.5.配置yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
node3
4.6配置从节点(必须要)
hadoop /etc/hadoop/slaves
datanode和nodemanager运行在哪个节点就写那些节点的主机名
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TtmLYnm9-1617287560134)(C:/Users/晁永政/AppData/Local/Temp/msohtmlclip1/01/clip_image018.jpg)]
5.分发安装包到nod2 node3
将apps目录分发到另外两台机器
scp -r /home/wangjian/apps wangjian@node2:/home/wangjian
scp -r /home/wangjian/apps wangjian@node3:/home/wangjian
将.bashrc(配置环境变量的文件)分发到另外两台机器
scp .bashrc wangjian@node2 :/home/wangjian
scp .bashrc wangjian@node3:/home/wangjian
分别在node2和node3执行source .bashrc命令
6.HDFS格式化(在namenode主节点格式化)
hdfs namenode -format
7.启动HDFS
9.1执行启动命令
在任何一个节点都可以启动hdfs,但是建议在namenode的节点上启动(node1)
在node1上执行:start-dfs.sh
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-685NR1xs-1617287560135)(C:/Users/晁永政/AppData/Local/Temp/msohtmlclip1/01/clip_image020.jpg)]
9.2JSP查看每个节点的进程
9.3通过web网页查看
8.启动YARN(必须在yarn的主节点启动)
8.1执行启动命令
必须要在配置的resourcemanager节点上启动(现在规划的是在node3)
所以必须在node3上执行start-yarn.sh
8.2JPS查看每个节点的进程
wangjian/apps wangjian@node3:/home/wangjian
将.bashrc(配置环境变量的文件)分发到另外两台机器
scp .bashrc wangjian@node2 :/home/wangjian
scp .bashrc wangjian@node3:/home/wangjian
分别在node2和node3执行source .bashrc命令
6.HDFS格式化(在namenode主节点格式化)
hdfs namenode -format
7.启动HDFS
9.1执行启动命令
在任何一个节点都可以启动hdfs,但是建议在namenode的节点上启动(node1)
在node1上执行:start-dfs.sh
[外链图片转存中…(img-685NR1xs-1617287560135)]
9.2JSP查看每个节点的进程
9.3通过web网页查看
8.启动YARN(必须在yarn的主节点启动)
8.1执行启动命令
必须要在配置的resourcemanager节点上启动(现在规划的是在node3)
所以必须在node3上执行start-yarn.sh
8.2JPS查看每个节点的进程
8.3网页web查看
第四章 分布式文件系统 HDFS
一、分布式文件系统
1.分布式文件系统
数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统 。
2.特点
是一种允许文件通过网络在多台主机上分享的文件系统,可让多台机器上的多用户分享文件和存储空间。
通透性。让实际上是通过网络来访问文件的动作,由程序与用户看来,就像是访问本地的磁盘一般。
容错。即使系统中有某些节点脱机,整体来说系统仍然可以持续运作而不会有数据损失。
适用于一次写入多次查询的情况,不支持并发写情况,不合适小文件的保存。
二、HDFS概述
1.HDFS简介
Hadoop分布式文件系统(HDFS)是一种旨在商品硬件上运行的分布式文件系统。它与现有的分布式文件系统有很多相似之处。但是,与其他分布式文件系统的区别很明显。HDFS具有高度的容错能力,旨在部署在低成本硬件上。HDFS提供对应用程序数据的高吞吐量访问,并且适用于具有大数据集的应用程序。HDFS放宽了一些POSIX要求,以实现对文件系统数据的流式访问。HDFS最初是作为Apache Nutch Web搜索引擎项目的基础结构而构建的。HDFS是Apache Hadoop Core项目的一部分。
HDFS****的设想和目标:
常态的硬件错误
海量数据集
流式访问需求
一致性的困难
分布式计算的支持(数据在哪里,计算就在哪里)
平台移植的困难
2.HDFS架构
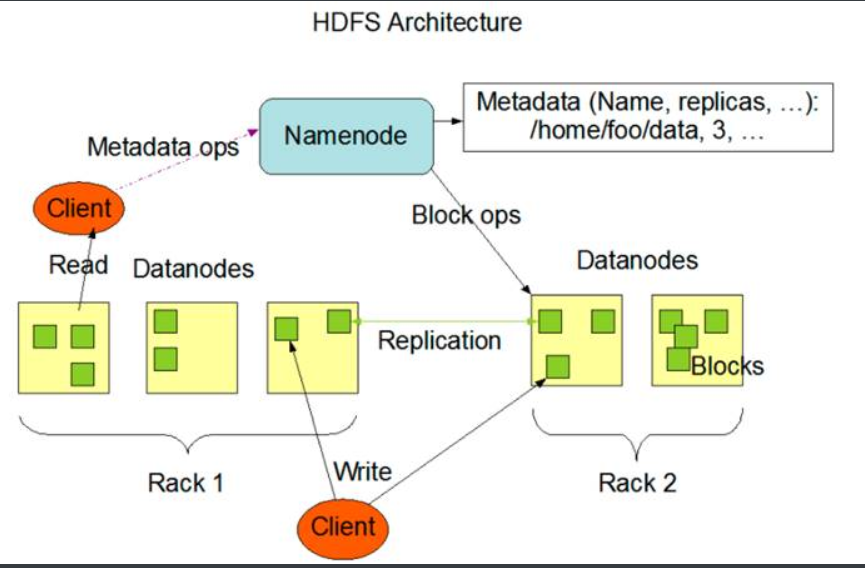
**HDFS****具有主/****从(master/slave)**体系架构。
(1) Client**(客户端):**
HDFS文件系统的使用者,进行读写操作。
(2**)NameNode****(主节点):**
整个HDFS集群的协调者,负责文件系统命名空间和负责客户端的请求
负责维护元数据信息(抽象的目录树,文件名和数据块的映射,DataNode和数据块的关系)
负责系统状态监控与调度
(3**)DataNode****(从节点):**
负责处理来自文件系统客户端的读写请求。
存储文件的数据块,执行块的创建和删除。
定期向NameNode发送心跳信息,包括本身信息和block信息。
(4**)SecondaryNameNode(**非高可靠)
一般运行在单独的物理计算机上,与NameNode进行通信,按照一定的时间间隔保持文件系统元数据的快照,是HA的一种解决方案,在生成环境的集群中,没有这个进程,当NameNode挂掉之后,可以帮助NameNode重启启动并恢复数据。
三、HDFS的基本概念
1.命名空间(namespace)与块存储服务
HDFS使用的是传统的分级文件组织结构。
namespace负责管理文件系统中的树状目录结构。
块存储服务,负责管理文件系统中文件的物理块与实际存储位置的映射关系。
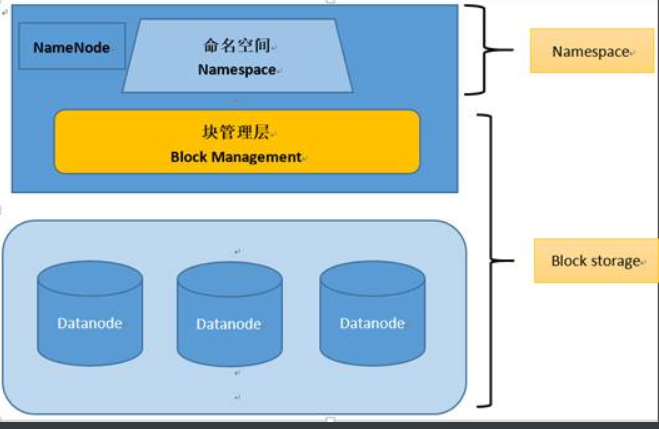
2.数据块block
HDFS旨在在大型群集中的计算机之间可靠地存储非常大的文件。它将每个文件存储为一系列块。
默认的块的大小是128M**(Hadoop2.0****)。**
文件中除最后一个块外的所有块都具有相同的大小(128M),而在添加了对可变长度块的支持后,用户可以在不填充最后一个块的情况下开始新的块,而不用配置块大小。如果一个文件的最后一个块的大小不足128M,也不会与其他的文件的块合并(因为是不同的文件)
3.数据复制data replication
复制文件的块是为了容错,每个文件都可以配置块大小和复制因子。配置属性:dfs.replaction,默认的副本系数是3。
相同block块的不同的副本不会存储在同一个节点上。
应用程序可以指定文件的副本数。复制因子可以在文件创建时指定,以后可以更改。HDFS中的文件只能写入一次(追加和截断除外),并且在任何时候都只能具有一个写入器。
NameNode定期从群集中的每个DataNode接收Heartbeat和Blockreport。收到心跳意味着DataNode正常运行。Blockreport包含DataNode上所有块的列表。
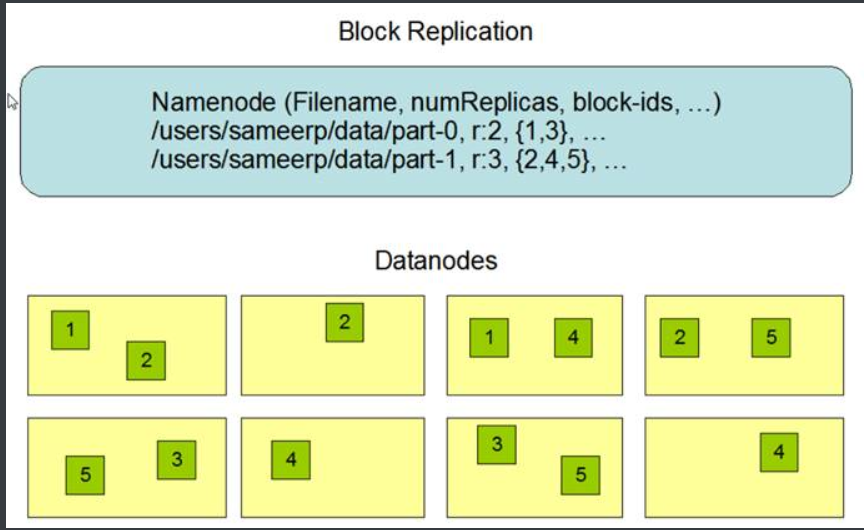
4.机架感知的副本放置策略
三份副本的放置策略如下:
第一个副本放置在客户端所在的节点,若客户端为远程访问则随机选择一个节点。
第二个副本放置在与第一个副本同机架的另外一个节点上
第三个副本放置在不同机架的节点上
5.心跳检测与副本恢复
DataNode会定期的向NameNode去发送心跳信息(本身的状况还有块的信息)
定期:DataNode多长时间去发送一次心跳信息,默认的时间是3S,如果进行配置的话,可以修改以下配置:

如果DataNode宕机了,NameNode接收不到心跳, NameNode不会立即认为该DataNode死亡,他会等10次,如果10次接收到DataNode发送信息的话,他也不会立即认为他死亡了,他会在第10次应该发送心跳信息的时间点之后的5min,向DataNode发送一次检查。
NameNode向DataNode发送检查的默认的间隔时间

如果DataNode故障之后,3_10+5_60=330S,NameNode会向DataNode发送第一次检查,发送检查如果没有收到回应,再当前的时间点再过5min发送第2次检查,如果第二次检查没有响应的话,才会认为DataNode宕机。
NameNode确认DataNode宕机的时间是 3_10+5_2*60=630S
四、HDFS的shell命
启动HDFS的服务:start-dfs.sh,HDFS安装好之后只有一个根目录(/),没有其他的目录和文件
hadoop fs 命令
hdfs dfs 命令
在操作HDFS的时候是没有相对路径,只有绝对路径(不管你操作的文件或目录在那个地方,都是从根目录开始操作)
1.hadoop fs(hdfs dfs)命令
1.1.-mkdir
将Path作为参数创建目录,用法:
hadoop fs -mkdir [-p] …或hdfs dfs -mkdir [-p] …
选项:
-p是创建多级目录
(1) 在/目录下创建a目录
hadoop fs -mkdir /a
(2) 在/目录下创建b目录,并在b目录中创建one目录
hadoop fs -mkdir -p /b/one #创建多级目录需要添加-p选项
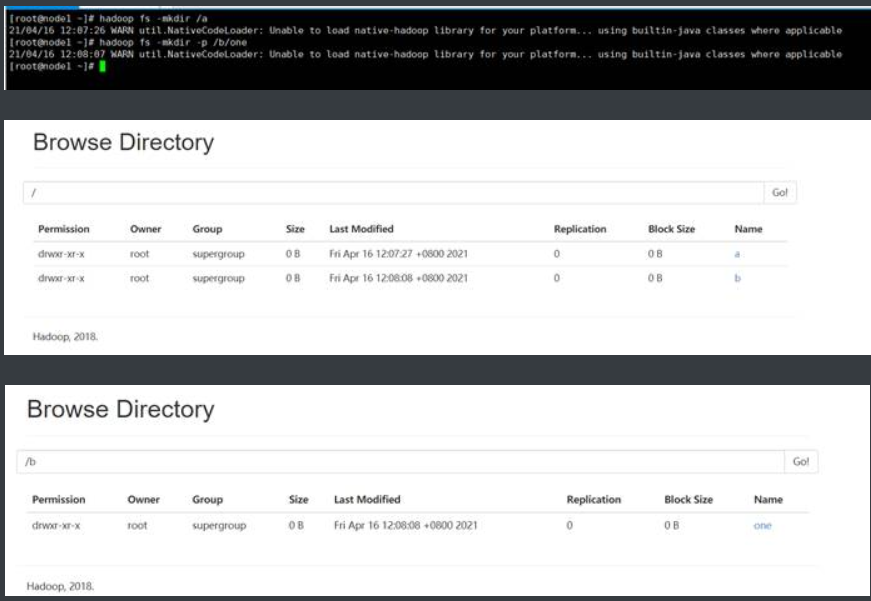
1.2.-ls
列出path中的目录或文件,用法:
hadoop fs -ls [-d] [-h] [-R] [ …]或hdfs dfs -ls [-d] [-h] [-R] [ …]
选项:
-d:目录被列为纯文件
-h:以易于阅读的格式设置文件大小
-R:递归列出遇到的子目录
示例:
(1)查看/目录中的子目录或文件
(2)查询/目录中所有的目录和文件(-R选项)
(3)文件大小以易于阅读的格式(-h选项)
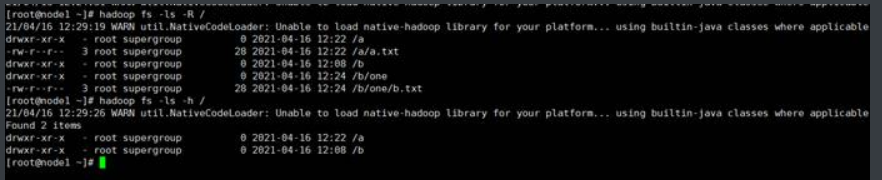
1.3.-cat
将源路径复制到标准输出,用法:
hadoop fs -cat [-ignoreCrc] URI [URI …]或
hdfs dfs –cat [-ignoreCrc] URI [URI …]
选项:
-ignoreCrc:禁用checkshum验证。
示例:查看/a/a.txt的文件内容

1.4.-put
将单个src或多个src从本地文件系统(一般Linux)复制到目标文件系统(HDFS)。
hadoop fs -put [-f] [-p] [-l] [-d] [-| …].或
hdfs dfs -put [-f] [-p] [-l] [-d] [-| …].
选项:
-p:保留访问和修改时间,所有权和权限。(假设权限可以在文件系统之间传播)
-f:如果目标文件已经存在,则将其覆盖。
-l:允许DataNode将文件延迟保存到磁盘,强制复制因子为1。此标志将导致持久性降低。小心使用。
-d:跳过带有后缀._COPYING_的临时文件的创建。
示例:将本地的a.txt文件上传到/目录中

1.5. –copyFromLocal
类似于put命令,将本地文件复制到HDFS中

1.6. -moveFromLocal
与put命令类似,不同之处在于复制后将源localsrc删除

1.7. –appendToFile
将本地文件系统中的单个src或多个src追加到目标文件系统。还从stdin读取输入,并将其追加到目标文件系统。用法:
hadoop fs -appendToFile … 或
hdfs dfs -appendToFile …
示例:
将本地b.txt的内容追加到HDFS中的/a.txt
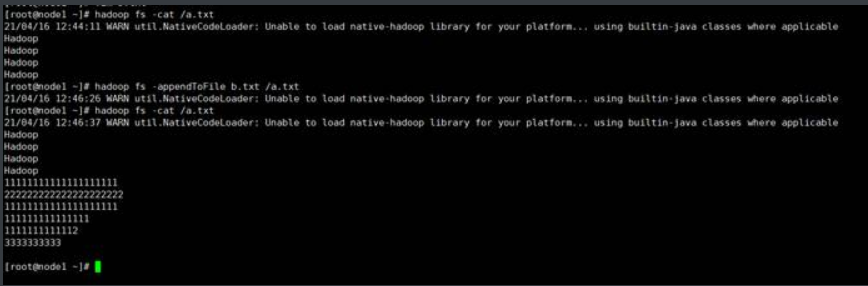
1.8.-get
将文件复制到本地文件系统,用法:
hadoop fs -get [-ignorecrc] [-crc] [-p] [-f] 或
hdfs dfs -get [-ignorecrc] [-crc] [-p] [-f]
选项:
-p:保留访问和修改时间,所有权和权限。(假设权限可以在文件系统之间传播)。
-ignorecrc:对下载的文件跳过CRC检查。
-crc:为下载的文件写入CRC校验和
示例:将/a.txt下载到本地当前目录
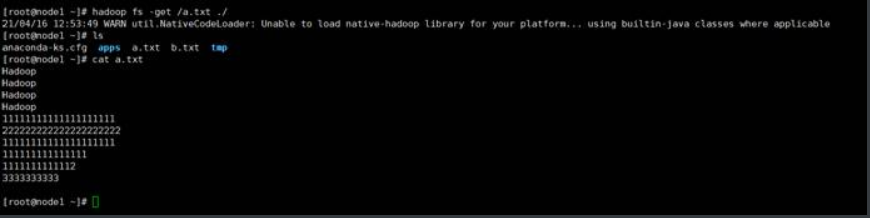
1.9.-getmerge
将源目录和目标文件作为输入,并将src中的文件串联到目标本地文件中。可以选择将-nl设置为启用,以在每个文件的末尾添加换行符(LF)。用法:
hadoop fs -getmerge [-nl] 或
hdfs dfs -getmerge [-nl]
示例:
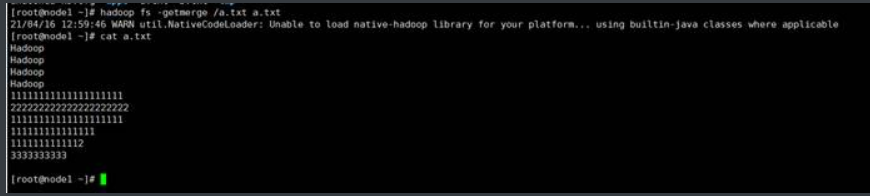
(1) 将/a. txt内容与本地的a.txt内容合
如果你指定了一个hdfs的文件,hdfs的文件会覆盖本地的文件
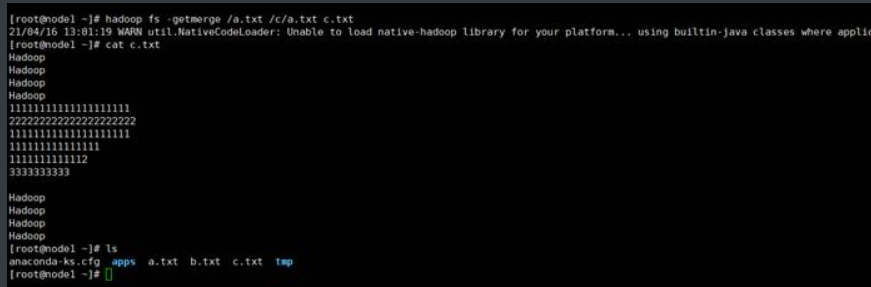
(2)将HDFS中的/a.txt与/b/a.txt文件下载到本地新文件c.txt
1.10.-copyToLocal
与get命令类似,将HDFS文件复制到本地

1.11.-mv
将文件从源文件移动到目标目录。此命令也允许多个源,在这种情况下,目标位置必须是目录。不允许跨文件系统移动文件(源是HDFS中的,目标也是HDFS中)。用法:
hadoop fs -mv URI [URI …] 或
hdf dfs -mv URI [URI …]
示例:

1.12. –cp
将文件从源复制到目标。此命令也允许多个源,在这种情况下,目标必须是目录(不允许跨文件系统,操作的都是HDFS的文件或目录)。用法:
hadoop fs -cp [-f] [-p | -p [topax]] URI [URI …] 或
hdfs dfs -cp [-f] [-p | -p [topax]] URI [URI …]
示例:将/a/profile复制到/b目录中

1.13. –rm
删除指定为args的文件。用法:
hadoop fs -rm [-f] [-r | -R] [-skipTrash] URI [URI …]
hdfs dfs -rm [-f] [-r | -R] [-skipTrash] URI [URI …]
选项:
-f:如果文件不存在,-f选项将不显示诊断消息或修改退出状态以反映错误。
-R选项以递归方式删除目录及其下的任何内容。
-r选项等效于-R。
-skipTrash选项将绕过垃圾桶(如果启用),并立即删除指定的文件。当需要从超配额目录中删除文件时,这很有用。
示例:
(1)删除文件

(2)删除目录(-r参数,删除目录也可用hadoop fs –rmdir命令或-rmr)

1.14.-chmod
更改文件的权限。使用-R,通过目录结构递归进行更改。用户必须是文件的所有者,或者是超级用户,用法:
hadoop fs -chmod [-R] <MODE [,MODE] … | OCTALMODE> URI [URI …]或
hdfs dfs -chmod [-R] <MODE [,MODE] … | OCTALMODE> URI [URI …]
文件的权限

上图中的第一组的d rwx r-x r-x
第一个代表的文件的类型:d-目录 -普通文件
第二个是rwx 代表的是属主的权限
第三个是r-x 代表与文件的属主同一组的其他的用户的权限
第三个r-x 代表的是其他组的用户的权限
权限: r-读的权限 w-写的权限 x-执行的权限 -没有权限
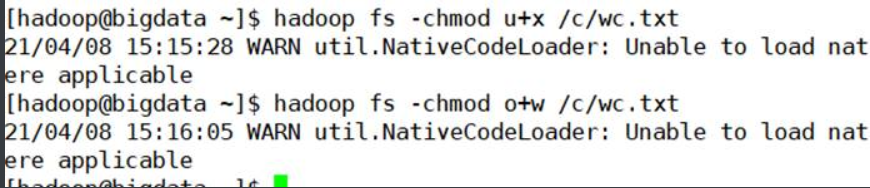
设置权限
第一种文字法设置
第一组的rwx指的是属主,u
第二组的rwx指的是同组用户,g
第三组的rwx指的的其他组的用户,o
加权限 + 减权限-
u+r o+x
第二种数字法设置
rwx :位置是不可变的,
第一个就是读的权限,如果有读的权限r ,如果没有没有读的权限- 2^2=4
第二个是写的权限,有则是w,没有是- 读权限代表数是 2^1=2
第三个是执行的全新,有x,没有- 执行的权限代表数字是2^0=1
-代表的数字是0
rwx代表数字4+2+1=7
r-x代表的数组4+0+1=5

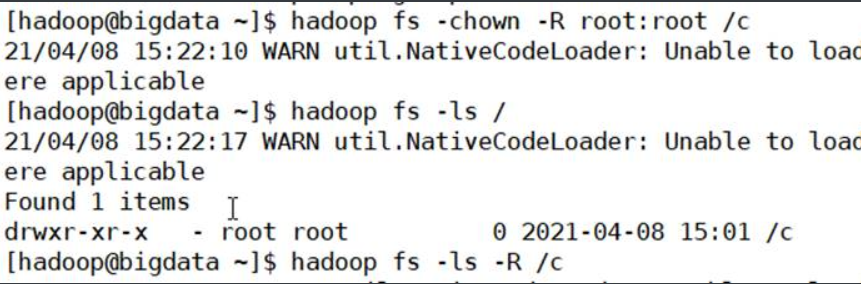
1.15.-chown
更改文件的所有者和组。该用户必须是超级用户。-R选项将通过目录结构递归进行更改。用法:
hadoop fs -chown [-R] [所有者] [:[组]] URI [URI]或
hdf dfs -chown [-R] [所有者] [:[组]] URI [URI]
示例:将/b的属主和属组改为root
1.16.-chgrp
更改文件的组关联。用法:
hadoop fs -chgrp [-R] GROUP URI [URI …]或
hdfs dfs -chgrp [-R] GROUP URI [URI …]
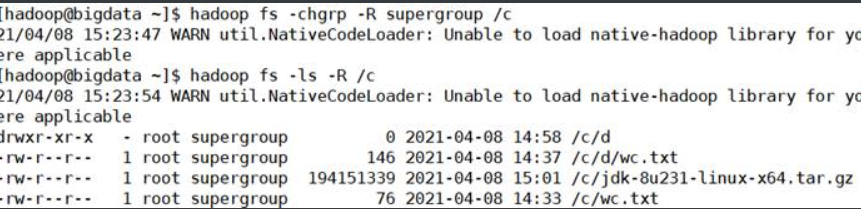
1.17. –df
显示可用空间。用法:
hadoop fs -df [-h] URI [URI …]或
hdfs dfs -df [-h] URI [URI …]
选项:
-h选项将以“人类可读”的方式格式化文件大小(例如64.0m而不是67108864)

1.18.-du
显示给定目录中包含的文件和目录的大小,或仅在文件的情况下显示文件的长度。用法:
hadoop fs -du [-s] [-h] URI [URI …]或
hdfs dfs -du [-s] [-h] URI [URI …]
选项:
-s选项将导致显示文件长度的汇总摘要,而不是单个文件的摘要。
-h选项将以“人类可读”的方式格式化文件大小(例如64.0m而不是67108864)

1.19 –tail
查看文件末尾1KB的内容,用法:
hadoop fs -tail [-f] 或
hdfs dfs –tail [-f]
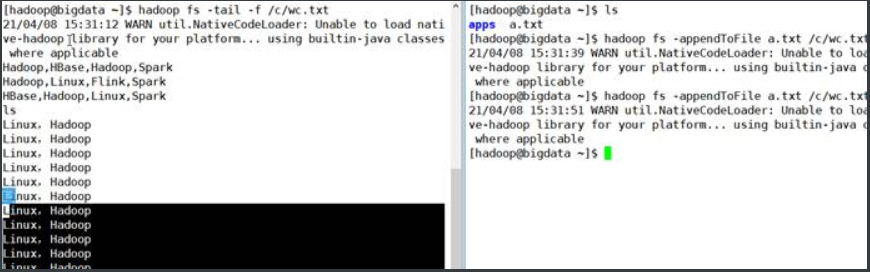
1.20. –count
计算与指定文件模式匹配的路径下的目录,文件和字节数,用法:
hadoop fs -count [-q] [-h] …或
hdfs dfs -count [-q] [-h] …
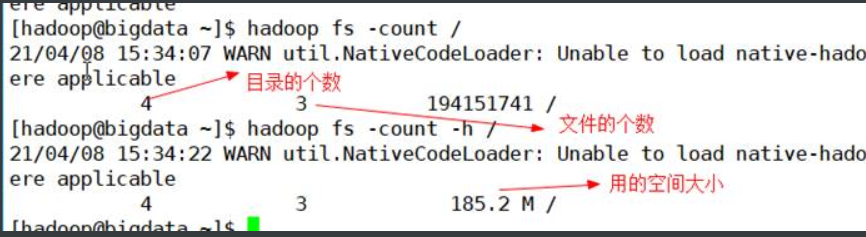
2. hdfs dfsadmin命令
2.1-report
报告基本文件系统信息和统计信息
hdfs dfsadmin -report [-live] [-dead] [-decominging]
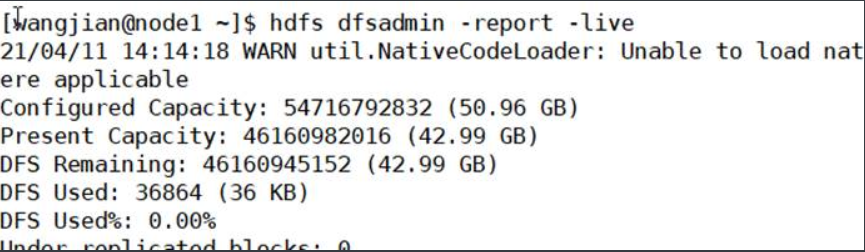
2.2-safemode
安全模式维护命令。安全模式是Namenode状态,其中
1.不接受对名称空间的更改(HDFS是只读,不能上传、创建、修改、复制、移动,但是可以查看、下载文件)
2.不复制或删除块。
安全模式在Namenode启动时自动进入,并在配置的最小块百分比满足最小复制条件时自动退出安全模式。也可以手动进入安全模式,但是随后也只能手动将其关闭。(当Namenode启动时,会将磁盘上的fsimage(元数据快照)这些文件加载到内存中)
hdfs dfsadmin -safemode enter|leave|get|wait
. 获取安全状态

2.进入安装模式

. 测试创建一个目录和上传一个文件
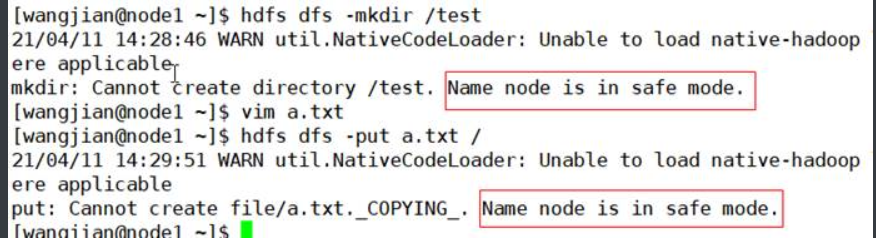
4.离开安全模式

5.上传文件,然后再进入安全模式,然后再查看和下载文件
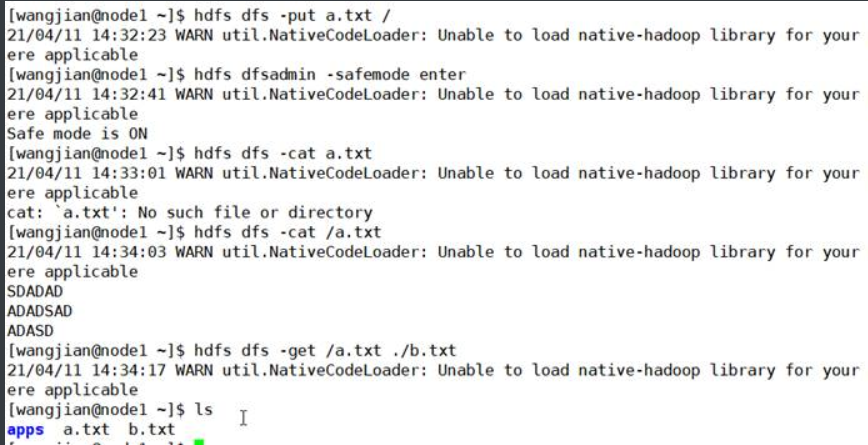
2.3 -refreshNodes
重新读取主机并排除文件,以更新允许连接到Namenode以及应停用或重新启用的Datanode集合
hdfs dfsadmin –refreshNodes
五、HDFS数据读写流程
1.数据写入流程
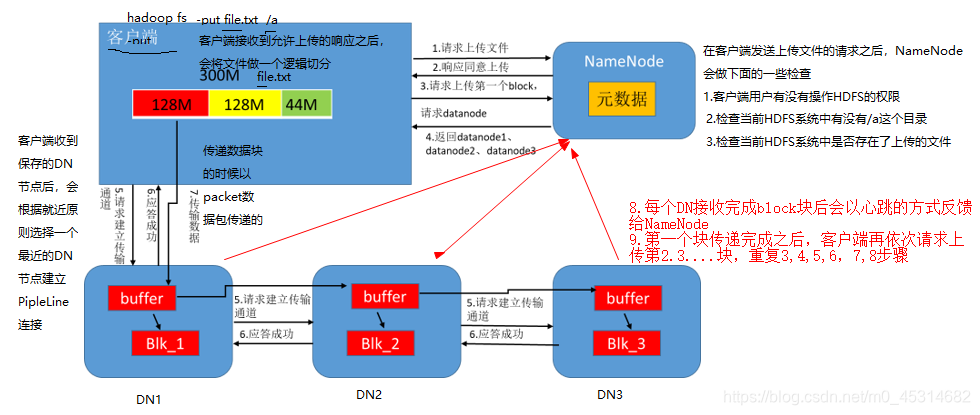
2.数据读取流程
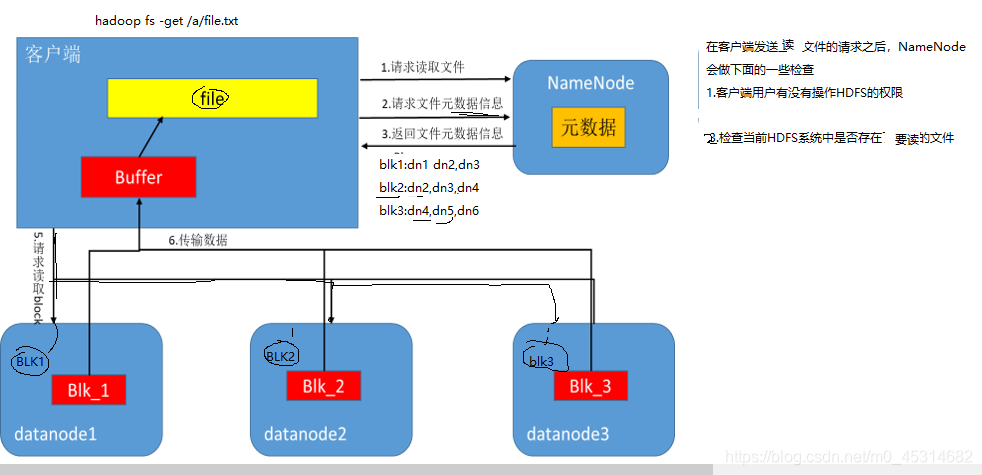
3.读写的单元
Block:文件存储的最小单元(128M)
Packet: 64K(网络传递的基本单元)
Chunk: 校验单元 512bit
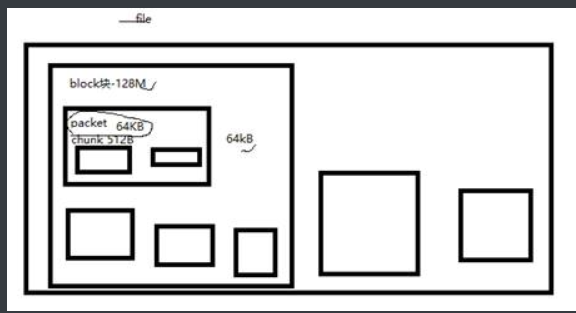
六、HDFS元数据管理机制
1.元数据
元数据(对你的文件数据做描述的一些数据)有NameNode维护
(1)文件目录结构信息(抽象的目录树),及其自身的属性信息。
(2)文件存储信息
文件分块信息:file1->blk1,blk2,blk3,blk4
block和节点对应信息: dn1,dn2,dn3->blk1
dn2,dn3,dn4-blk2,blk3
dn5,dn6,dn7->blk4
需要注意的是block和节点的对应关系是临时构建的,并不会持久化存储
(3)Datanode信息。
2.元数据存储机制
2.1元数据保存在哪
元数据信息保存在内存中,也会保存在磁盘中
保存在内存中提高元数据的读写速度,从而也提高了数据的读写速度
(1)文件目录结构信息 (2)文件和数据库的映射关系 (3)block块与节点的映射关系
保存在磁盘中为了持久化元数据,防止节点宕机导致内存中的元数据丢失。
(1) 文件目录结构信息 (2)文件和数据库的映射关系
Block与节点的映射关系不会持久化到磁盘中,当HDFS启动的时候,先启动NameNode,NameNode启动后会先进入安全模式,接着启动DataNode,DataNode启动起来之后就像NameNode通过心跳发送信息,当报告完成之后,NameNode退出安全模式。
2.2持久化文件
(1)元数据快照文件
fsimage_0000000000000000069
fsimage_0000000000000000069.md5
fsimage_0000000000000000077
fsimage_0000000000000000077.md5
(2) 日志文件
历史日志文件
edits_0000000000000000001-0000000000000000002
edits_0000000000000000003-0000000000000000003
edits_0000000000000000004-0000000000000000040
edits_0000000000000000041-0000000000000000069 edits_0000000000000000070-0000000000000000077
(2)现在正在写入的日志文件
edits_inprogress_0000000000000000078
seen_txid:记录当前向哪个一个文件记录日志
3.元数据合并机制
3.1内存中元数据、fsimage和edits的关系
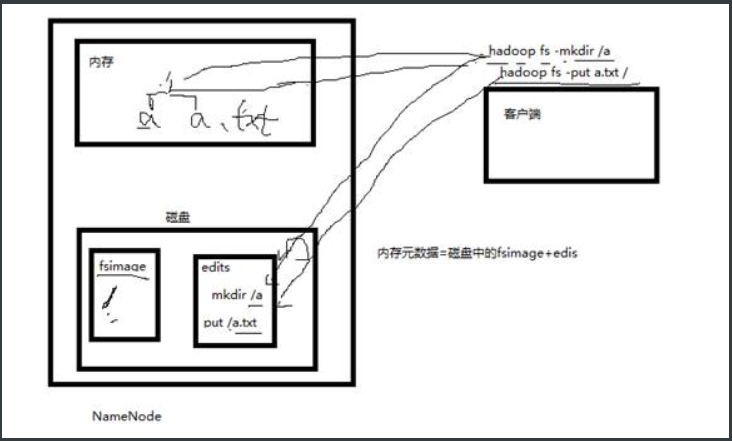
3.2合并机制
伪分布式和非高可靠分布式集群:合并是secondaryNameNode完成的
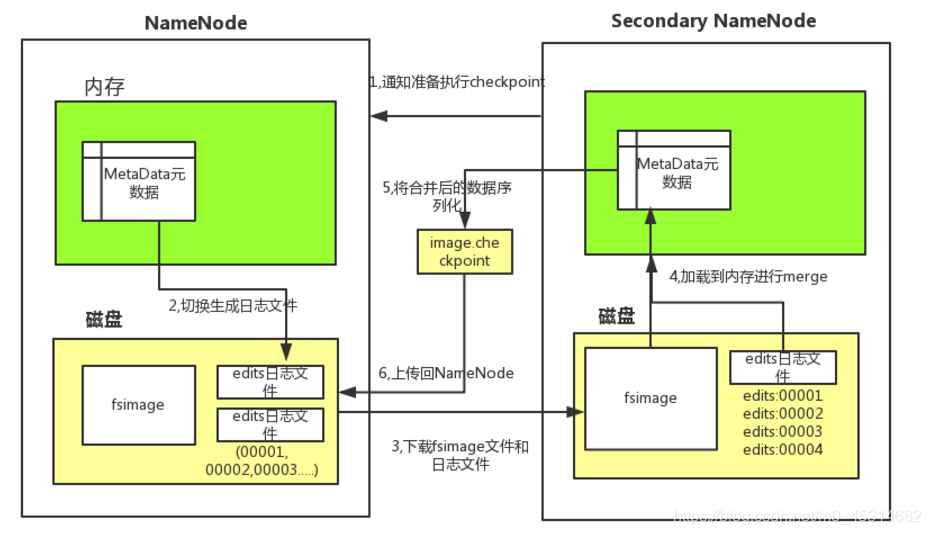
高可靠的集群中由备用的namenode节点进行Checkpoint
Checkpoint:检查点(合并点) hdfs-default.xml
dfs.namenode.checkpoint.period:设置两次相邻CheckPoint之间的时间间隔,默认是1小时;
dfs.namenode.checkpoint.txns:设置的未经检查的事务的数量,默认为1百万次。
MAVEN
七、Java API应用
1.开发环境搭建
1.1介绍
项目构建工具: maven+Eclipse
apache的顶级项目,通过maven构建项目,
(1) 添加依赖包的时候,只添加核心的依赖包,maven会将核心的依赖包以及该包依赖的其他的包都导入的项目里面去。
(2) 自动下载源代码,不需要手动的导入源码
(3) 所有项目的依赖都会下载的本地的仓库中,仓库中的所有的依赖是共享的,节约了磁盘空间
(4) 项目的构建、打包、编译等等。
1.2开发HDFS项目的准备工作
第一步:在windows中安装hadoop的环境
1.将安装包进行解压,解压的目录不要有中文和空格
2…hadoop.dll和winutils.exe,将winutils.exe复制到hadoop解压目录下的bin,需要将hadoop.dll复制到hadoop解压目录下的bin目录下和C:WindowsSystem32目录下
3.在WIN配置环境变量:HADOOP_HOME和PATH
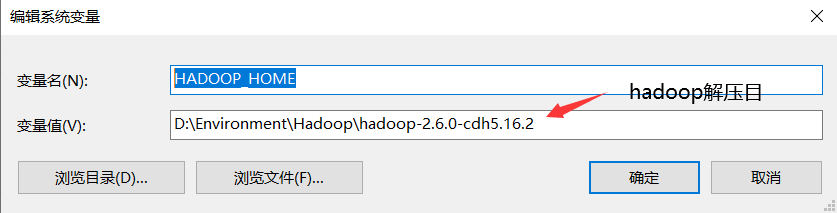
PATH:%HADOOP_HOME%in
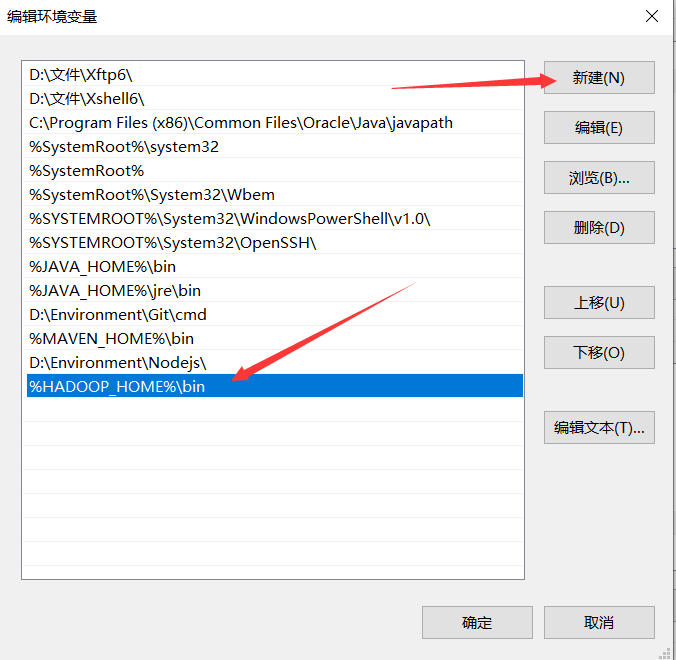
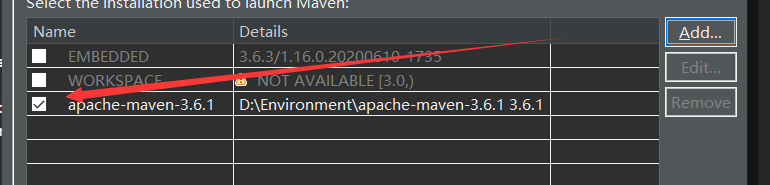
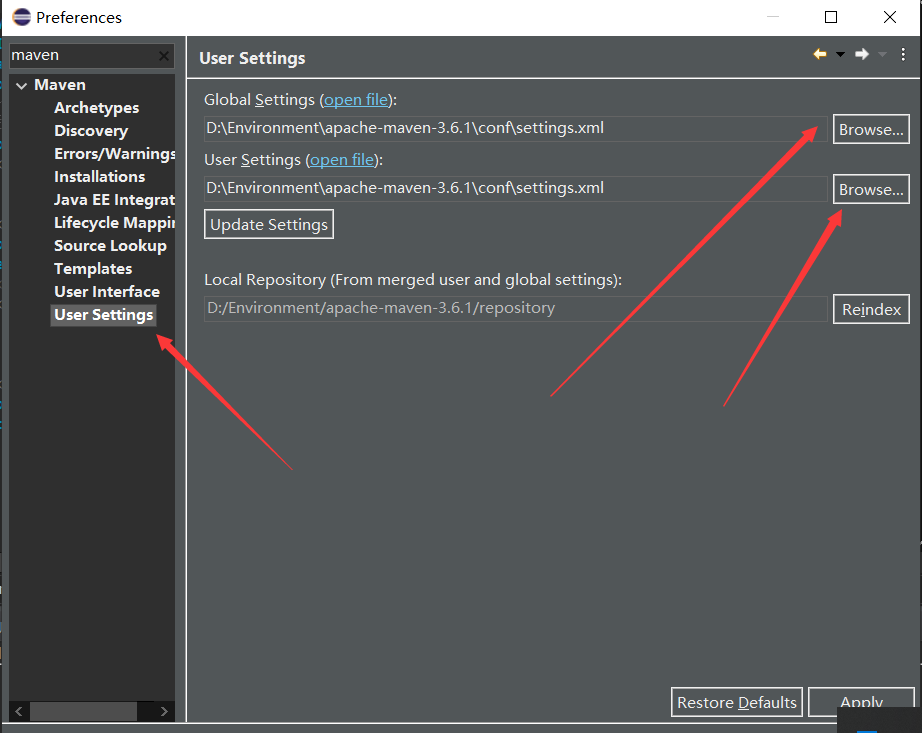
第二步:配置Maven(使用Eclipse自带的Maven)
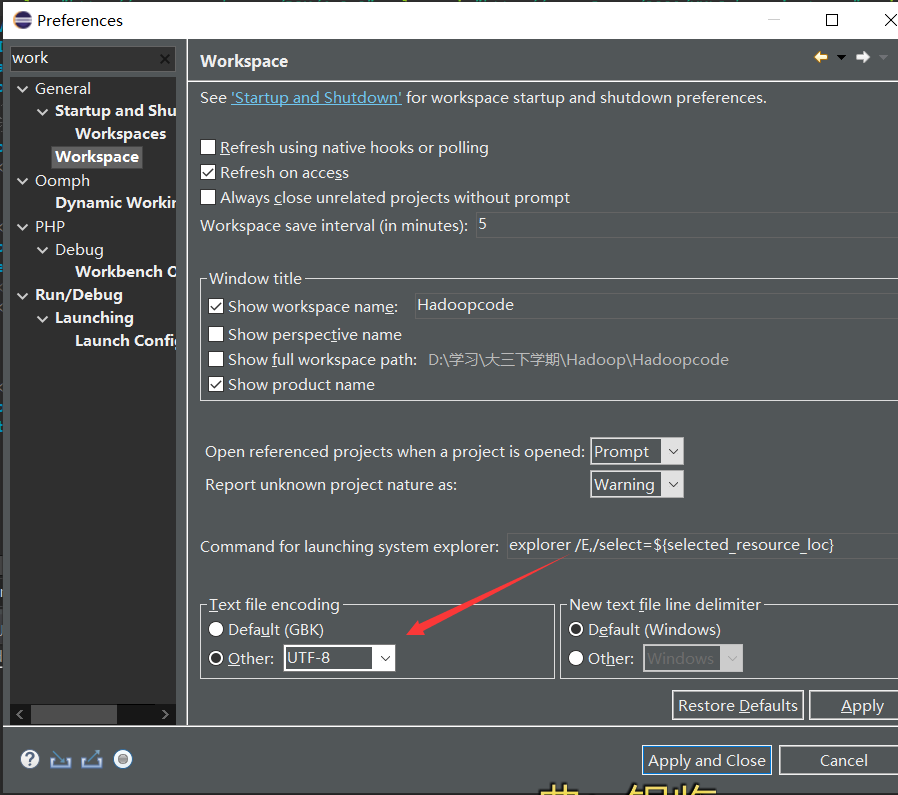
1.让eclipse中的maven使用我们自己的settings.xml文件
如果你创建的工作空间,需要修改编码,需要把工作空间的编码修改UTF-8
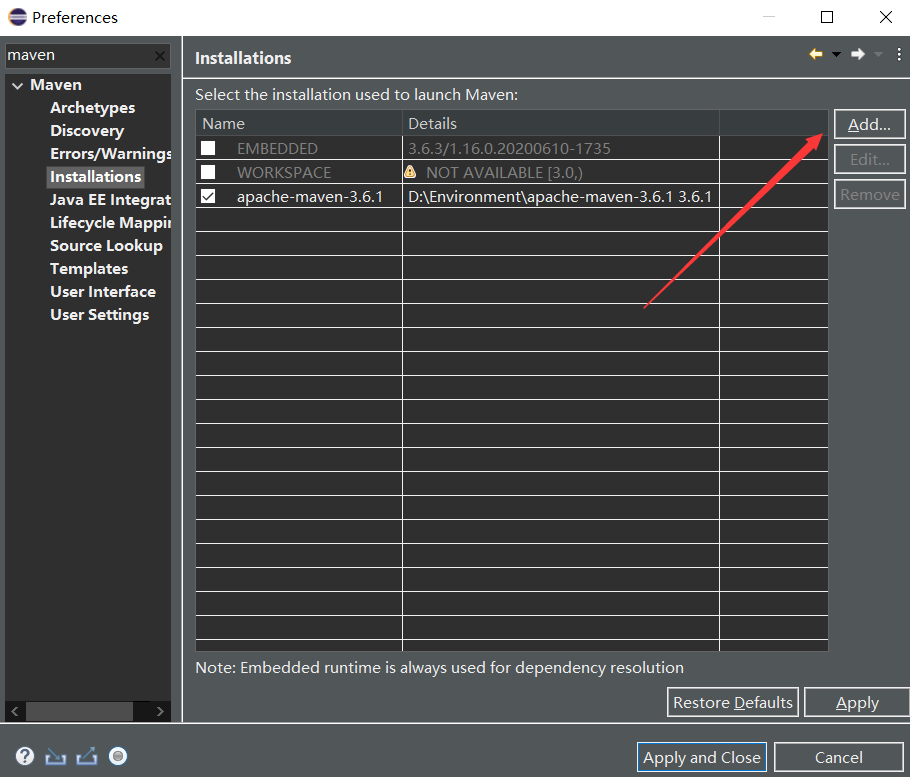
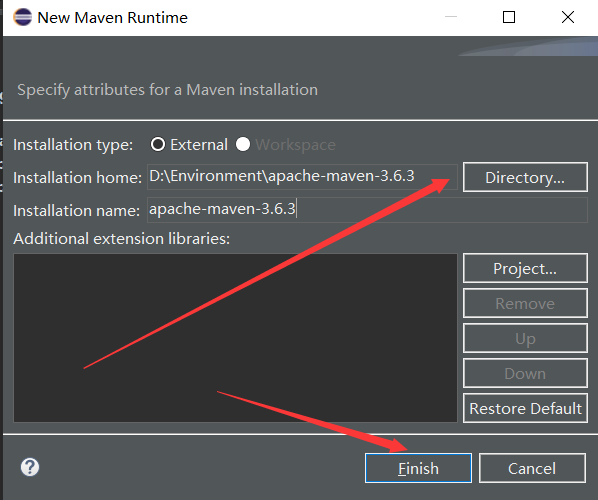
2.Maven构建Hadoop项目
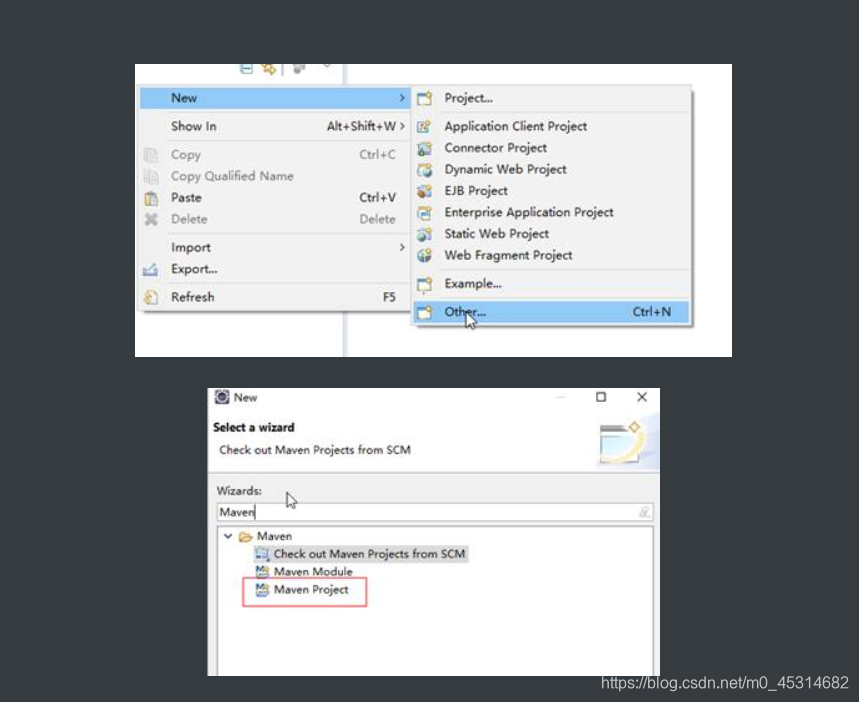
2.1创建项目
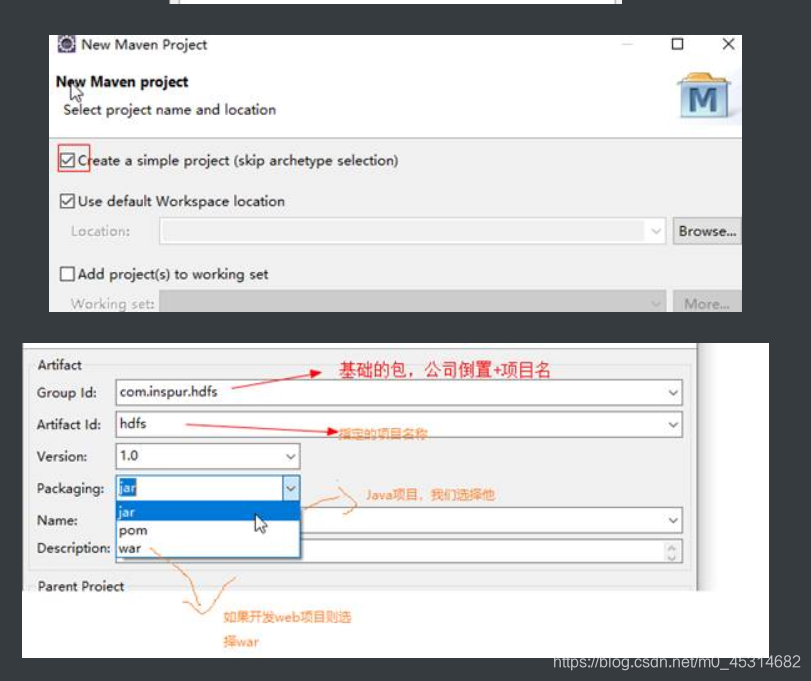

2.2添加Hadoop的依赖
<!-- 我们虽然配置了中央仓库是阿里云的仓库,
但是我们安装的hadoop版本是cdh 阿里云仓库中没有cdh的包,所以先添加cdh的依赖仓库 -->
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<!--添加hadoop-client依赖 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0-cdh5.16.2</version>
</dependency>
</dependencies>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
3.HDFS文件系统操作涉及的类
3.1Configruration
读取或设置配置的
3.2FileSystem
文件系统对象,帮助我们获取操作的文件系统的对象
3.3IOUtils工具类
输入输出(读写)工具类
4.JavaAPI操作HDFS
4.1.获取FileSystem对象
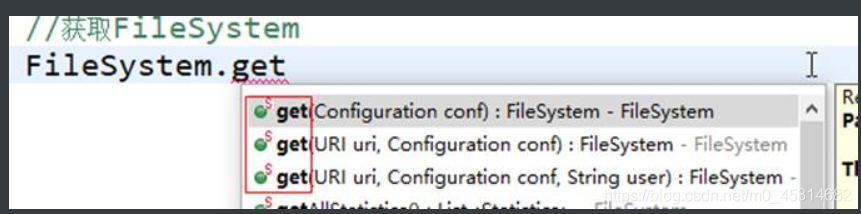
get(conf) :获取本地的文件系统
get(uri,conf):获取通过uri指定的的文件系统,当本地的用户和服务器HDFS的用户名相同是则不用指定user
get(uri,conf,user):获取通过uri指定的文件系统,并且操作这个文件系统的时候是使用我们指定user用户,如果本地的用户和服务器HDFS的用户名不同时,则user指定的是服务器HDFS的用户。
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import com.inspur.hdfs.util.FileSystemUtil;
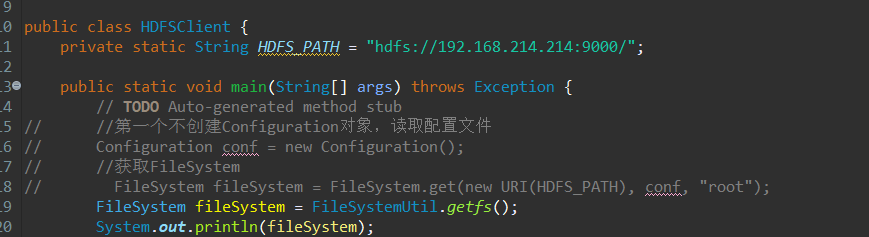
public class HDFSClient {
private static String HDFS_PATH = "hdfs://192.168.214.214:9000/";
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
// //第一个不创建Configuration对象,读取配置文件
// Configuration conf = new Configuration();
// //获取FileSystem
// FileSystem fileSystem = FileSystem.get(new URI(HDFS_PATH), conf, "root");
FileSystem fileSystem = FileSystemUtil.getfs();
System.out.println(fileSystem);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
4.2列出文件的状态信息()
方法:FileSystem.listFiles(Path,boolean)
查看指定的目录下有哪些文件
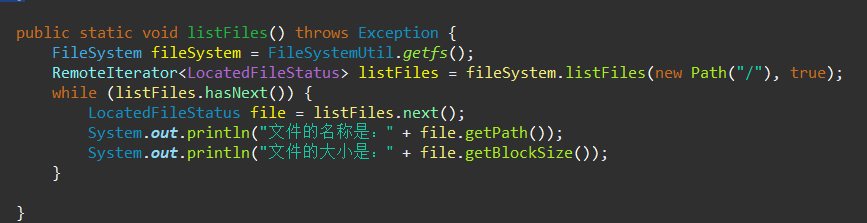
public static void listFiles() throws Exception {
FileSystem fileSystem = FileSystemUtil.getfs();
RemoteIterator<LocatedFileStatus> listFiles = fileSystem.listFiles(new Path("/"), true);
while (listFiles.hasNext()) {
LocatedFileStatus file = listFiles.next();
System.out.println("文件的名称是:" + file.getPath());
System.out.println("文件的大小是:" + file.getBlockSize());
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
记得在主方法里调用 listFiles()
4.3.列出文件或目录的状态信息
方法:FileSystem. listStatus(Path s)
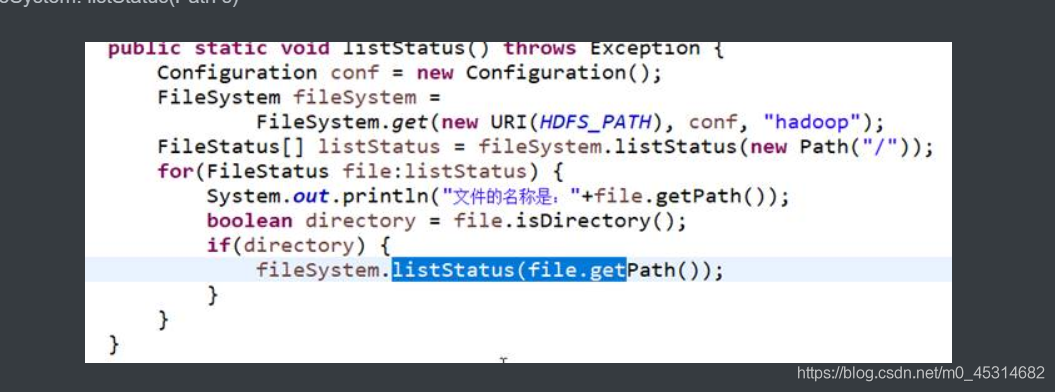
4.4封装FileSystem工具类
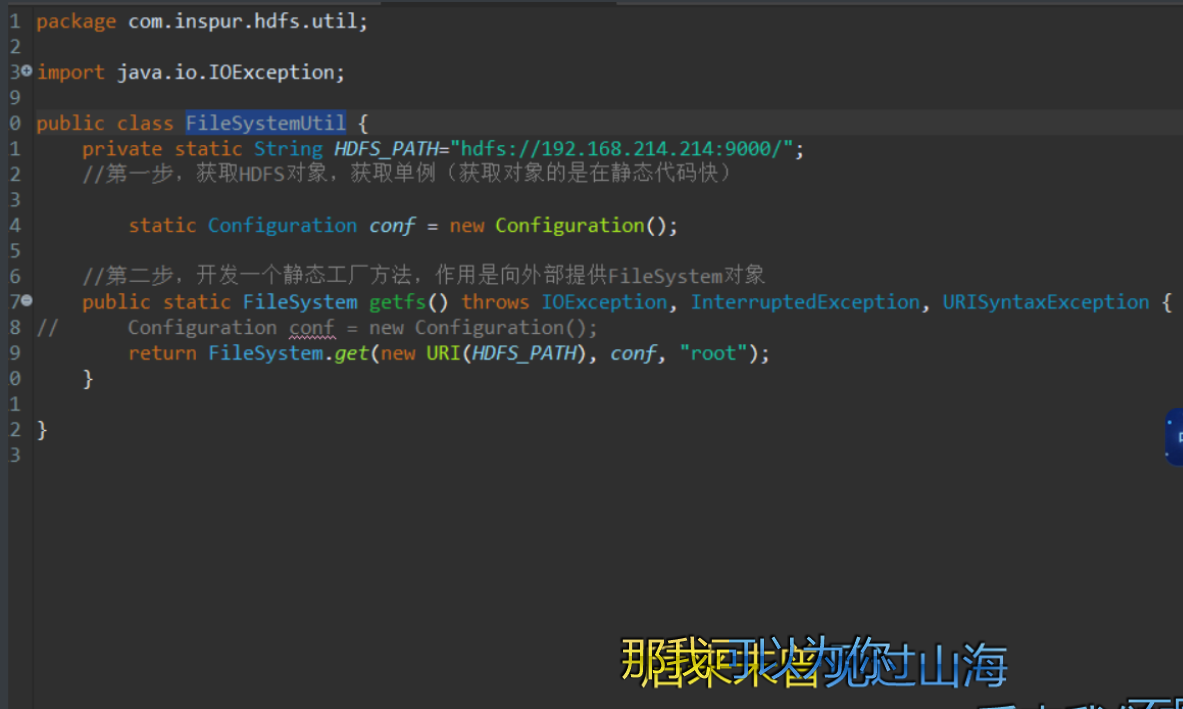
package com.inspur.hdfs.util;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
public class FileSystemUtil {
private static String HDFS_PATH="hdfs://192.168.214.214:9000/";
//第一步,获取HDFS对象,获取单例(获取对象的是在静态代码快)
static Configuration conf = new Configuration();
//第二步,开发一个静态工厂方法,作用是向外部提供FileSystem对象
public static FileSystem getfs() throws IOException, InterruptedException, URISyntaxException {
// Configuration conf = new Configuration();
return FileSystem.get(new URI(HDFS_PATH), conf, "root");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
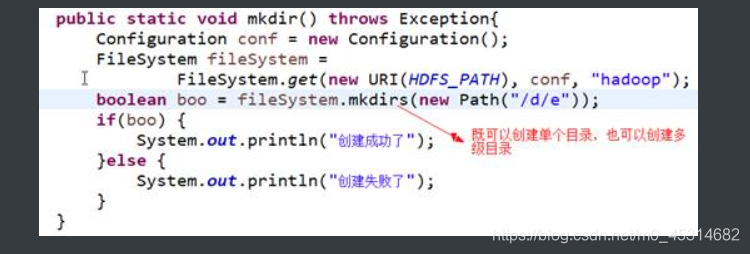
4.5.创建目录
方法:FileSystem.mkdirs(path)
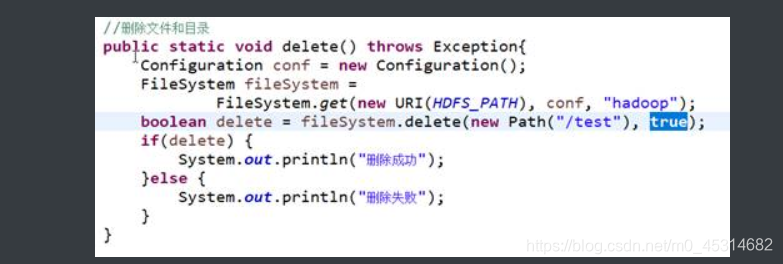
4.6.删除文件或目录
方法:FileSystem.delete(path,boolean),其中 boolean参数指定是否递归删除
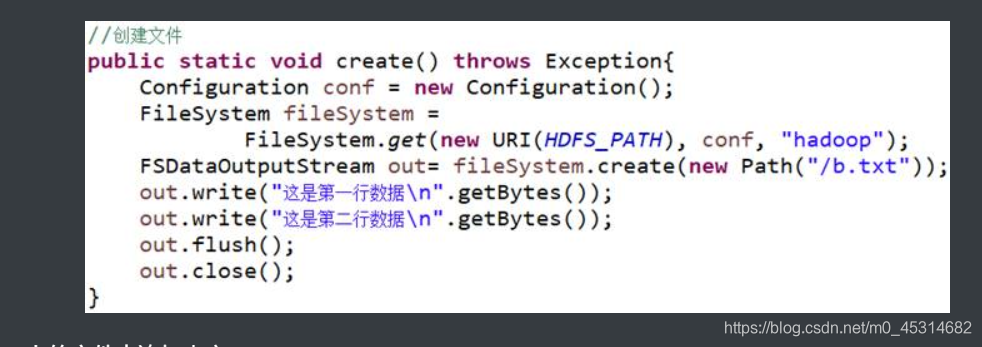
4.7.在HDFS中创建文件
方法:FileSystem.create(path)
4.8 在HDFS上的文件中追加内容
方法: FileSystem.append()

4.9.在HDFS中读取文件
方法:FileSystem.open(path)
输出HDFS的文件内容到控制台
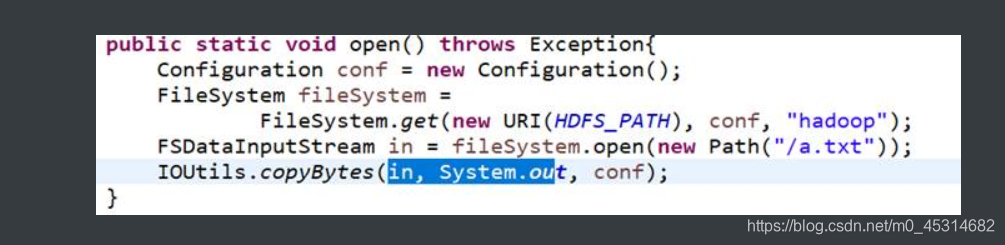
输出HDFS的文件内容到本地的文件
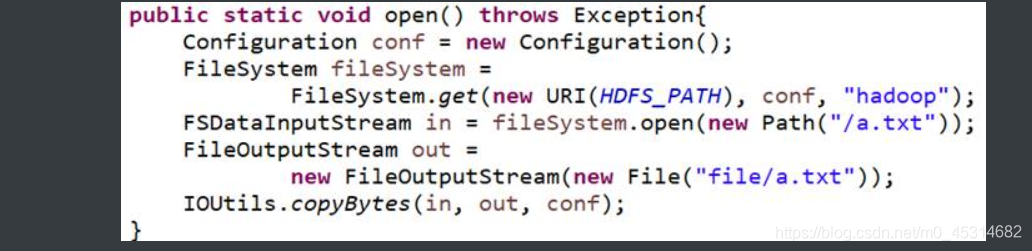
4.10.将本地文件上传HDFS
方法:FileSystem.copyFromLocalFile(src,dst)
4.11.将HDFS中文件下载到本地
方法:FileSystem.copyToLocalFile(src,dst)
4.12.重命名文件或目录
方法:FileSystem.rename(src,dst) 不能跨文件系统
5 .Configuration读取配置文件
第六章 分布式计算框架MapReduce
一、MapReduce的概述
MapReduce源于Google在2004年12月发布的一篇论文:MapReduce。
1.什么是MapReduce
Hadoop MapReduce是一个软件框架,可以轻松地编写以可靠、容错的方式在大型集群(数千个节点)上并行处理大量数据(TB数据集)的应用程序。
MapReduce的核心功能就是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上。
2.为什么引入MapReduce
海量数据的处理
集群运行的困难
业务逻辑与底层资源分配的隔离
3.MapReduce的优缺点
优点:海量数据的离线批处理
易开发、易运行
缺点:不能实时的进行计算
二、MapReduce的运行流程
1.MapReduce的执行流程
MapReduce作业通常将输入数据集分割成独立的区块,由map任务以完全并行的方式处理这些区块,框架对map的输出进行排序,然后将其输入到reduce任务中。通常作业的输入和输出都存储在文件系统中。框架负责调度任务、监视它们并重新执行失败的任务。
作业是分成了Map和Reduce两种任务,源数据和计算完成的结果通常都是保存在HDFS上的。
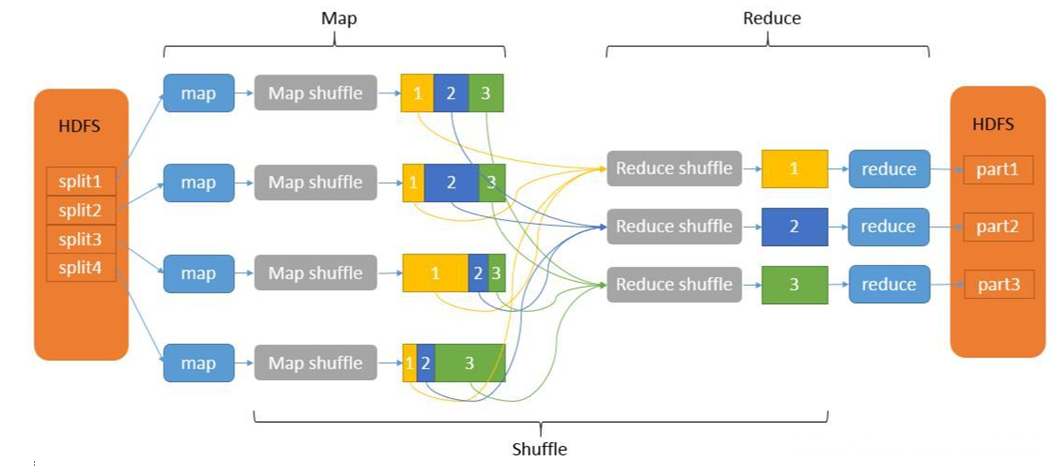
默认的分区的只有一个,每个分区中保存的数据都是相同规则
map任务的并行度由切片的数量决定
reduce任务的并行度是有分区的数量决定
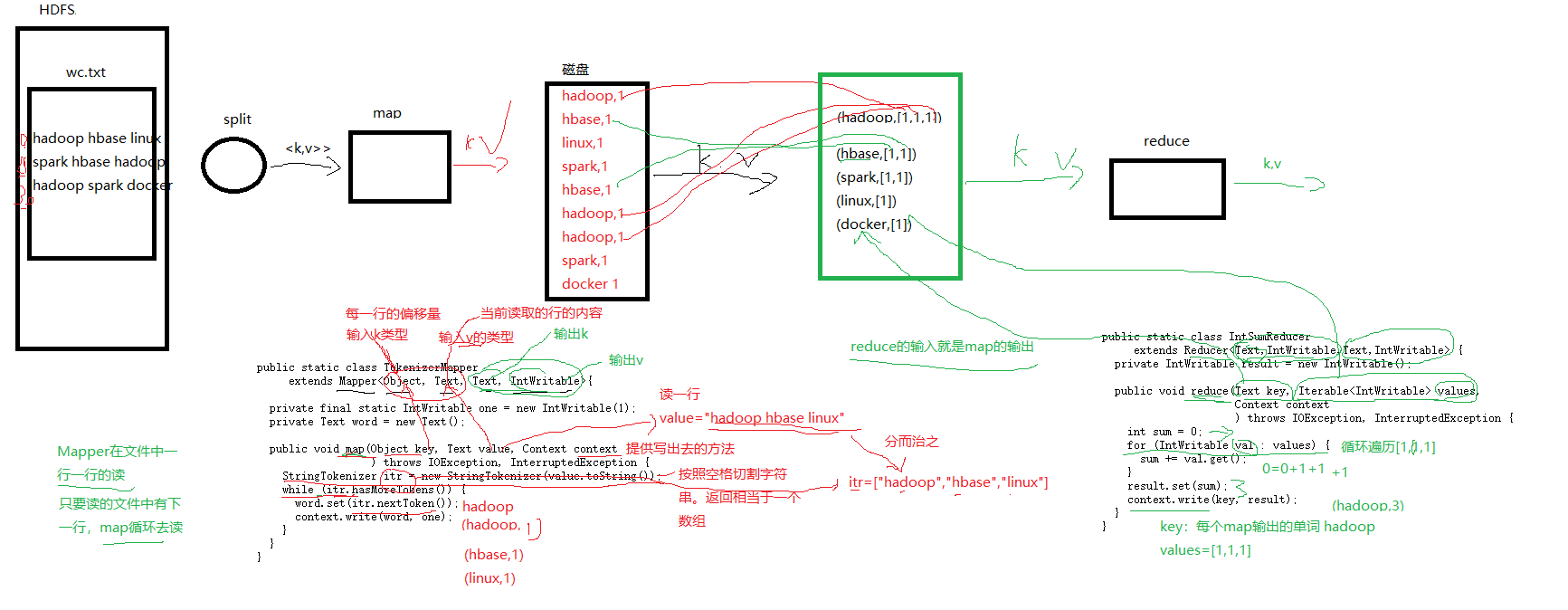
map
(1)系统将数据拆分为若干个“分片”(split)
(2)将分片数据以键-值方式传递给map进行处理
(3)map方法对数据进行业务处理(执行你的业务代码)
(4)将处理的数据写入到磁盘
reduce
(1)通过多个复制线程去拉取不同map节点输出的数据文件
(2)对这些数据文件进行排序和合并,然后传入reduce方法
(3)reduce方法对数据进行业务处理(执行你自己写的reduce的业务代码)
(4)输入数据到文件系统(HDFS)
第一个Map任务中的第一个分区的数据: a h o
第二个map任务中的第一个分区的数据: b,l,z
reduce会将这两个分区拉取到同一个节点,对这个两个分区进行合并
a h o b l z -> a b h l o z
2.wordcount的案例解析MapReduce的编程模型
计算单词在文件中出现的个数(词频统计)
MapReduce ->(启动YARN和HDFS)
Hadoop的安装包中提供的很多的示例程序:
第一步:本地创建wc.txt文件
vim wc.txt
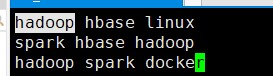
第二步:将文件上传到HDFS

第三步:运行MapReduce程序
运行mapreduce的命令:
hadoop jar 程序的jar包 jar包中驱动类 参数1(处理的文件) 参数2(输出结果的路径-目录) …

第四步:查看结果

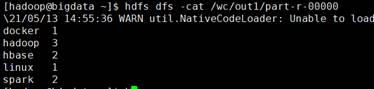
三、输入输出类
1.InputFormat
org.apache.hadoop.mapreduce.InputFormat(抽象类)
2.RecoderReader
org.apache.hadoop.mapreduce. RecoderReader
3.OutputFormat
org.apache.hadoop.mapreduce.OutputFormat
4.RecoderWriter
org.apache.hadoop.mapreduce. RecoderWriter。

