
- 1服务器上更新了js、html、css文件,访问时不是最新的文件_服务器响应的不是最新的资源
- 2知识点总结:Java核心技术(卷1)_java核心技术卷1
- 3【二进制部署k8s-1.29.4】一、安装前软件准备及系统初始化
- 4Monkey测试结果分析_monkey 结果分析
- 5Java和Android笔试题_安卓语法 笔试题
- 6京东h5st加密参数分析与批量商品价格爬取(文末含纯算法)_京东 h5st
- 7swagger2 knife4j 集成配置_swagger2 配置 kneif4j
- 8MySQL系列之索引
- 9利用栈和队模拟一个停车场(数据结构报告)_以栈模拟停车场,以队列模拟车场外的便道,按照从终端读入的输入数据序列进行模拟管
- 10sql操作数据_sql创建一个操作表action
AI新纪元:OpenAI GPT-4o模型发布,开启智能交互革命!_糟糕!连接到 gpt-4o 时出现问题。 external: 503, message='servi
赞
踩
前言
2024年5月13日,OpenAI向全球发布了其ChatGPT旗舰版本的升级模型——GPT-4o(Generative Pre-trained Transformer 4 Omni)。这个多语言、多模态的GPT大型语言模型被誉为比前代GPT-4快两倍,而价格却只有其一半。在OpenAI的直播演示中,米拉·穆拉蒂宣布,该模型将对所有用户免费开放。

发布会上,OpenAI详细介绍了GPT-4o在移动端与人类交互的先进程度,并特别强调了其在多模态场景下的应用。
一、 总体概述
GPT-4o是朝着更加自然的人机交互迈出的一步——它接受文本、音频、图像和视频的任意组合作为输入,并生成文本、音频和图像的任意组合输出。它可以在短短 232 毫秒内响应音频输入,平均为 320 毫秒,这与人类在对话中的响应时间相似。它在英语和代码文本上的表现与 GPT-4 Turbo 相当,在非英语语言文本上的表现有显著改善,同时在 API 上也更快、便宜 50%。与现有模型相比,GPT-4o 在视觉和音频理解方面尤其出色。
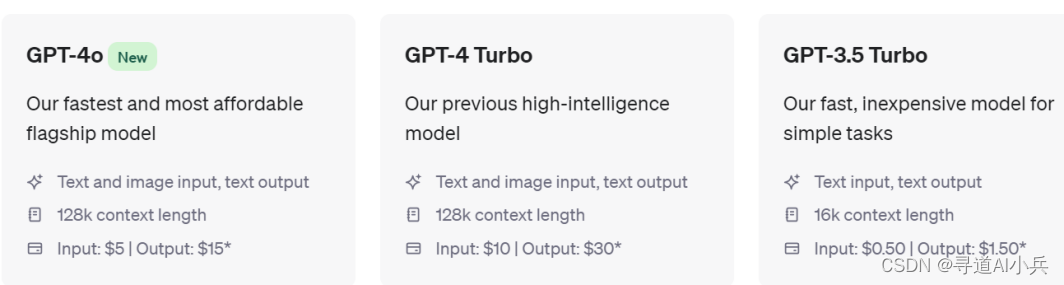
在GPT-4o推出之前,用户可以使用语音模式与 ChatGPT 交谈,平均延迟为 2.8 秒(GPT-3.5)和 5.4 秒(GPT-4)。为了实现这一点,语音模式是一个由三个独立模型组成的管道:一个简单的模型将音频转录为文本,GPT-3.5 或 GPT-4 接收文本并输出文本,第三个简单模型将该文本转换回音频。这个过程意味着主要的智能来源 GPT-4 会丢失大量信息——它无法直接观察语调、多个说话者或背景噪音,也无法输出笑声、歌声或表达情感。
二、能力探索
GPT-4o作为一个先进的多模态AI,提供了丰富的功能,从文章、图片、音频到视频等各个层面拓宽了我们与机器互动的方式。
1、文字生成图片
通过输入一段文字描述,GPT-4o能够将其转化为相应的图像。这项能力使得用户可以通过简单的文本描述来创造和获得视觉上的表达,从而在设计、创作以及教育等场景中发挥重要作用。例如,设计师可以利用这个功能快速生成初步的设计概念草图,教师可以借助它帮助学生更好地理解抽象的概念,或者在没有专业设计软件的情况下,普通用户也可以创建出自己心中的图像。

2、3D 物体合成
基于一段文字描述,GPT-4o有能力生成一个具有三维效果的Logo。这一功能为品牌营销、产品设计等领域带来了革新。想象一下,品牌经理只需提供品牌的关键字或理念,即可在短时间内得到一个立体的、富有创意的Logo设计。这不仅极大地降低了设计成本,也加速了品牌推广和形象塑造的过程。

3、音频提炼总结
GPT-4o可以接收一段音频文件,并解析其内容,最终为用户提供一份精炼的摘要或总结。这对于处理长时段的演讲、讲座或会议录音尤其有用。记者、研究人员或任何需要从大量音频资料中提取关键信息的个体都能从这个功能中受益。此外,这项技术还可以应用到智能助手中,帮助用户管理日常生活中的语音信息。

输出:

4、视频讲座总结
GPT-4o还具备对视频内容的分析和总结能力。当用户上传一段视频讲座后,GPT-4o能够观看并理解视频内容,然后输出一份简洁的总结。这无疑会改变教育和自学的方式,因为学习者现在可以通过这个工具迅速获取讲座的核心要点而无需花费大量时间观看整个视频。同时,这也为内容创作者提供了一种有效的工具来整理和分发他们的作品中的关键信息。

总结输出

三、 模型评估
按照传统基准测试,GPT-4o 在文本、推理和编码智能方面实现了 GPT-4 Turbo 级别的性能,同时在多语言、音频和视觉功能上创下了新的高水准。
1、文本评估
在文本处理方面,GPT-4o在0-shot CoT(Chain of Thought) MMLU(常识问题)上创下了 88.7% 的新高分。所有这些评估都是通过新的简单评估库收集的。此外,在传统的 5-shot no-CoT MMLU测试中,GPT-4o 创下了 87.2% 的新高分。

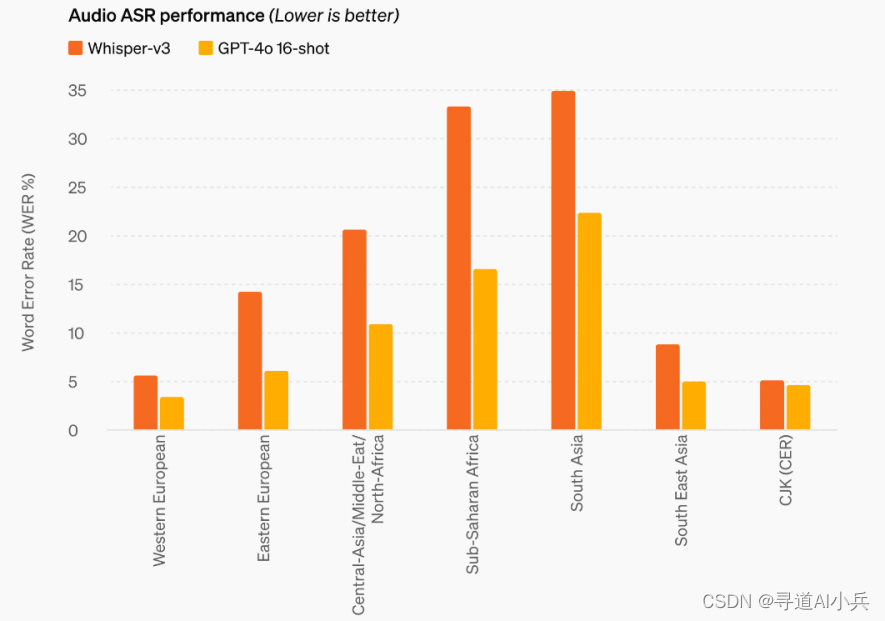
2、音频ASR评估
在音频处理方面,GPT-4o在自动语音识别(ASR)性能上实现了大幅提升,特别是在资源匮乏的语言中,其表现尤为突出。
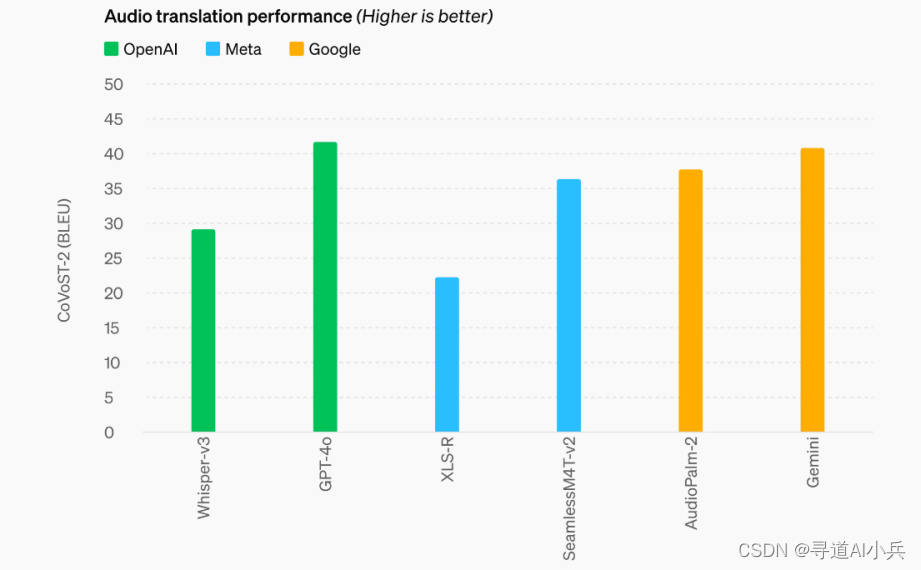
3、音频翻译性能
在音频翻译性能方面,GPT-4o 在语音翻译方面树立了新的领先水平,并在 MLS 基准上超越了 Whisper-v3。
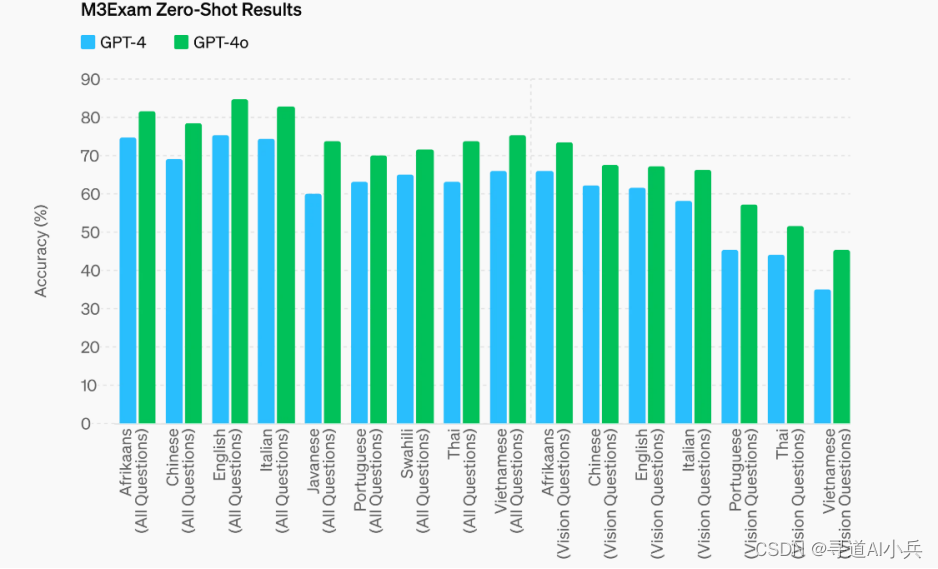
4、M3Exam零样本结果
M3Exam 基准既是多语言评估,也是视觉评估,由来自其他国家标准化测试的多项选择题组成,有时包括图形和图表。GPT-4o 在所有语言的这个基准上都比 GPT-4 更强。(也就是说在多语言和视觉评估方面,在所有语言的测试中均表现优异)
5、视觉理解评估
GPT-4o 在视觉感知基准上实现了最先进的性能。所有视觉评估都是 0 次测试,其中 MMMU、MathVista 和 ChartQA 作为 0 次测试 CoT。(这意味着GPT-4o在无样本学习的情况下依然能够保持高水平的视觉理解和推理能力)
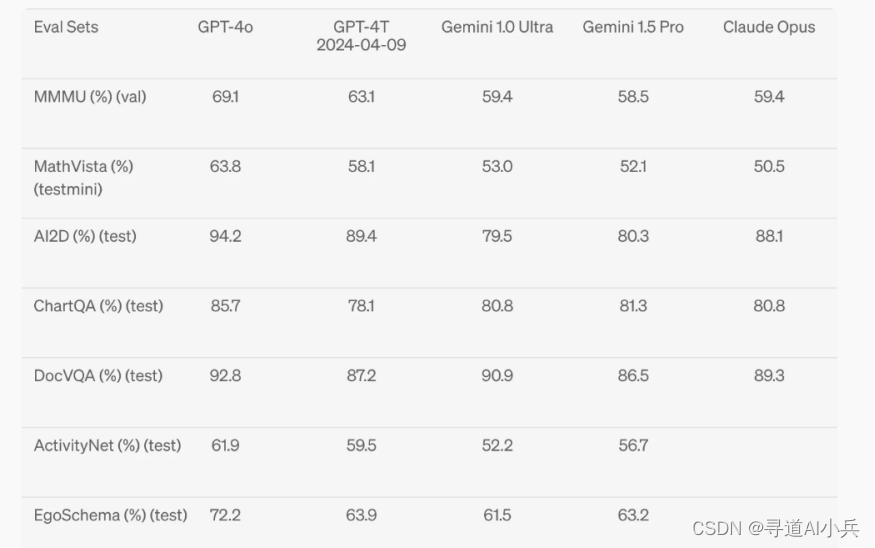
四、 OpenAI API使用

1、文本聊天
要通过 OpenAI API 使用其中一个模型,只需要向 Chat Completions API 发送包含输入和 API 密钥的请求,并接收包含模型输出的响应即可。聊天模型将消息列表作为输入,并返回模型生成的消息作为输出。
聊天 API 调用示例如下:
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
2、图像解析
图像主要通过两种方式提供给模型:通过传递图像链接或直接在请求中传递 base64 编码的图像。图像可以在用户、系统和助手消息中传递。目前不支持在第一个系统消息中使用图像。
from openai import OpenAI client = OpenAI() response = client.chat.completions.create( model="gpt-4o", messages=[ { "role": "user", "content": [ {"type": "text", "text": "What’s in this image?"}, { "type": "image_url", "image_url": { "url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg", }, }, ], } ], max_tokens=300, ) print(response.choices[0])

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
3、上传 Base 64 编码图像
如果您本地有一张或一组图像,则可以将其以 Base 64 编码格式传递给模型,以下是实际操作示例:
import base64 import requests # OpenAI API Key api_key = "YOUR_OPENAI_API_KEY" # Function to encode the image def encode_image(image_path): with open(image_path, "rb") as image_file: return base64.b64encode(image_file.read()).decode('utf-8') # Path to your image image_path = "path_to_your_image.jpg" # Getting the base64 string base64_image = encode_image(image_path) headers = { "Content-Type": "application/json", "Authorization": f"Bearer {api_key}" } payload = { "model": "gpt-4o", "messages": [ { "role": "user", "content": [ { "type": "text", "text": "What’s in this image?" }, { "type": "image_url", "image_url": { "url": f"data:image/jpeg;base64,{base64_image}" } } ] } ], "max_tokens": 300 } response = requests.post("https://api.openai.com/v1/chat/completions", headers=headers, json=payload) print(response.json())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
4、多幅图像输入
聊天完成 API 能够接收和处理多幅图像输入,既可以采用 base64 编码格式,也可以采用图像 URL 格式。模型将处理每幅图像,并使用所有图像的信息来回答问题。
from openai import OpenAI client = OpenAI() response = client.chat.completions.create( model="gpt-4o", messages=[ { "role": "user", "content": [ { "type": "text", "text": "What are in these images? Is there any difference between them?", }, { "type": "image_url", "image_url": { "url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg", }, }, { "type": "image_url", "image_url": { "url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg", }, }, ], } ], max_tokens=300, ) print(response.choices[0])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
五、未来展望
随着GPT-4o技术的持续进化和深化应用,未来的技术发展和应用前景将更加广阔。下面是对GPT-4o未来发展的一些展望:
1、智能自动化与人类协作的新篇章
预计在未来,GPT-4o将在智能自动化领域扮演更加关键的角色,不仅仅是提高工作效率,而且能够与人类建立更加紧密的协作关系。在设计、工程、软件开发等领域,GPT-4o将以其卓越的处理速度和精确度,完成那些重复性高、耗时长的任务,使人类工作者得以将注意力集中在更具创造性和战略性的工作上。通过这种深度协作,我们可能会看到创新速度的显著加快和总体生产效率的提升。
2、为每个用户打造的深度个性化体验
展望未来,GPT-4o将更加注重为每个用户提供深度个性化的服务体验。这包括但不限于根据用户的显示偏好、行为习惯以及明确需求提供定制化的内容和服务。例如,在学习平台上,GPT-4o可以根据用户的学习进度和认知能力,动态调整课程内容和难度,实现真正的个性化学习。同样,在消费者服务领域,企业可以利用GPT-4o进行精细的市场细分,为不同的客户群体提供量身定制的解决方案和产品推荐。
3、跨学科的创新应用成为常态
随着GPT-4o的能力不断扩展,预计将有更多跨学科的应用案例出现。GPT-4o将在诸如环境科学、生物技术、医疗健康等领域发挥重要作用,解决传统方法难以解决的问题。例如,在环境科学领域,GPT-4o可以分析大量环境监测数据,识别污染源和趋势,帮助制定更有效的环境保护政策。在医疗健康领域,GPT-4o可以通过分析患者的历史健康数据和全球医疗研究成果,为医生提供精准的治疗建议。
4、全球知识共享与打破语言障碍
借助于GPT-4o强大的多语言处理能力,未来的互联网将变得更加无国界,信息流动更加自由。GPT-4o将能够实时翻译和传播各种语言的内容,不仅促进全球范围内的知识和文化共享,还能加深各国之间的理解和合作。这将为解决全球性问题,如气候变化、公共卫生等提供更加坚实的信息支持和合作基础。
5、伦理与责任的全面强化
随着GPT-4o能力的不断增强,对其应用的伦理审视和社会责任也将成为重点。预计将出现更加完善的法律法规和伦理指导原则,确保技术的发展不会侵犯个人隐私、数据安全及公平性。同时,开发者和企业也需要承担起相应的社会责任,确保AI技术的应用不仅遵循技术的进步,更符合人类社会的整体利益和可持续发展的需求。
总结
OpenAI的GPT-4o模型,凭借速度快两倍、价格便宜一半的优势,迅速成为科技领域的焦点。免费开放的决策推动了AI技术的普及和应用。GPT-4o在多模态交互方面的惊人能力,为各领域带来了革命性影响,极大地拓宽了人机互动的边界。从文本到音频,再到视频,GPT-4o展示了其在多个基准测试中的卓越性能和智能推理能力。通过OpenAI API,用户可轻松调用GPT-4o的强大功能,享受便捷高效的服务。总之,GPT-4o的发布不仅标志着人工智能领域的一大进步,也为社交网络等领域带来了新的革命。随着GPT-4o的持续发展,我们将迈向智能化程度更高、人机交互更自然的时代。

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

