
热门标签
热门文章
- 1配电站房AI智能对指示灯开关状态识别技术解析---豌豆云_变电站 指示灯 图像识别 分类
- 2github生成密钥_github怎么生成密匙
- 3git 删除分支
- 4网页信息采集-网页数据采集方法_网页采集
- 5word转换为pdf后图片失真的解决办法_word保存pdf图片失真
- 6AI绘画软件:创作新时代的艺术革命
- 7AI论文速读 | 大语言模型作为城市居民——利用LLM智能体框架生成人类移动轨迹_基于大语言模型的语义轨迹移动序列生成
- 8kafka集群之kraft模式部署_windows环境搭建kafka的kraft集群
- 97大AI绘画“ 炸裂”应用趋势,离谱的创新力,又有多少人要失业了!
- 10飞凌嵌入式受邀参加矿鸿OSV生态策略大会,共创矿山智能化新时代
当前位置: article > 正文
sqoop导入数据_sqoop数据导入
作者:盐析白兔 | 2024-06-09 09:16:24
赞
踩
sqoop数据导入
1. Sqoop简介
Sqoop:是一款开源的工具,其实就是 SQL to Hadoop,主要用于在Hadoop(Hive) 与传统的数据库(MySQL,postgresql...)之间进行数据的传递,实现关系型数据库与HDFS数据的转换。
sqoop原先是Hadoop的一个组件。
sqoop1与sqoop2是两个版本,推荐使用一版本,因为2版本仅仅是测试,不投入生产环境中。
- 1
- 2
- 3
- 4
- 5
2. Sqoop原理
将导入或者导出命令翻译成MapReduce程序来实现。
在翻译出来的MapReduce中,主要是对inputformat 以及 outputformat 进行定制。
- 1
- 2
- 3
3. Sqoop的简单实用案例
3.1 导入数据
在 sqoop中,导入是指:从非大数据集群(RDBMS) 向大数据集群(HDFS,HIVE,HBASE)中传输数据
与参数位置没有关系
使用关键字 import
- 1
- 2
- 3
- 4
- 5
3.1.1 RDBMS 到 HDFS
3.1.1.1 Mysql准备数据
(1)开启MySQL服务,登录mysql,在mysql准备数据,
sudo systemctl start mysqld
- 1
- 2

(2)创建数据库company
create database company;
show databases;
- 1
- 2
- 3

(3)创建数据表staff
use company ; //使用数据库company
create table company.staff(id int(4) primary key not null auto_increment,name varchar(255),sex varchar(255)); //创建表staff
show tables; //查看company数据库中的全部表
- 1
- 2
- 3
- 4
- 5
- 6


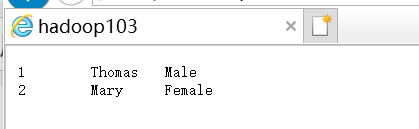
(4) 向数据表是staff插入数据
insert into staff(name,sex) values('Thomas','Male');
insert into staff(name,sex) values('Mary','Female');
SELECT *FROM staff; //查看数据表staff
- 1
- 2
- 3
- 4
- 5

3.1.1.2 全部导入HDFS
先测试JDBC连接是否成功
------------------------
bin/sqoop list-databases --connect jdbc:mysql://hadoop102:3306/ --username root --password xxxxx
- 1
- 2
- 3
(1)执行import命令
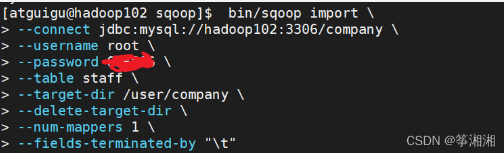
bin/sqoop import \
> --connect jdbc:mysql://hadoop102:3306/company \
> --username root \
> --password xxxxxx \
> --table staff \
> --target-dir /user/company \
> --delete-target-dir \
> --num-mappers 1 \
> --fields-terminated-by "\t"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
遇到错误:NameNode处于safeMode安全模式
- 1

解决方法:
退出安全模式
hadoop dfsadmin -safemode leave
重新执行sqoop import 操作
- 1
- 2
- 3
- 4


提交到ResourceManager,需要等待片刻

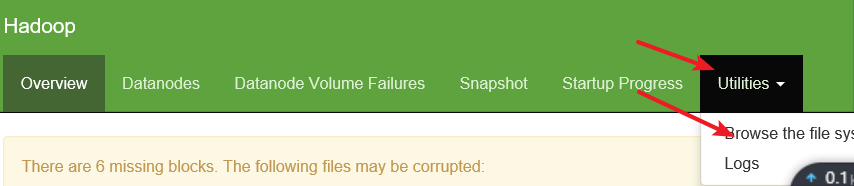
(2) Web端口查看
进入NameNode
点击Utilities ->点击Browse the file system
搜索 文件夹/user/company
点击part-m-000000
点击download
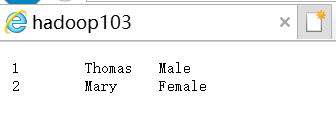
可以看到我们插入在staff中的两条数据
说明导入数据成功啦!!!!!!!!!!!!!!
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8




3.1.1.3 查询导入HDFS(用的多)
查询导入指定表中数据
select 语句,where过滤条件中必须加上$CONDITIONS
因为正常业务中,有多个map读取数据,数据是有序导入HDFS,$CONDITIONS用来传递参数,保证写入HDFS的数据顺序和Mysql中顺序一致。
- 1
- 2
- 3
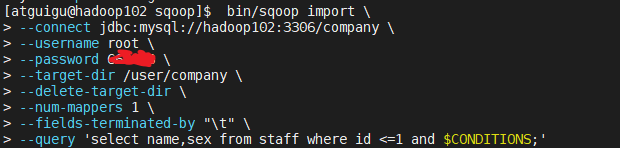
(1) 执行sqoop import命令 ----------------------------------------- //第一种 bin/sqoop import \ --connect jdbc:mysql://hadoop102:3306/company \ --username root \ --password xxxxxx \ --target-dir /user/company \ --delete-target-dir \ --num-mappers 1 \ --fields-terminated-by "\t" \ --query 'select name,sex from staff where id <=1 and $CONDITIONS;' ----------------------------------------- 第二种 bin/sqoop import \ --connect jdbc:mysql://hadoop102:3306/company \ --username root \ --password xxxxxx \ --target-dir /user/company \ --delete-target-dir \ --num-mappers 1 \ --fields-terminated-by "\t" \ --query 'select name,sex from staff where id <=1 and $CONDITIONS;' -------------------------------------------------------------------------- 两种效果一致,区别在于,如果select语句使用双引号,则必须在$CONDITIONS前面加上 斜杠转移符,防止shell识别为自己的变量,否则执行的时候依旧会报错提示需要加$CONDITIONS。

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
(2) Web端查看结果,完美!!!!!!!!!!!!
- 1

3.1.1.4 导入指定列
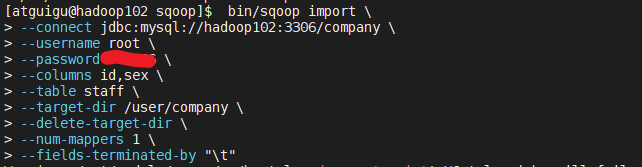
(1) 执行import 命令
bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password XXXxxxx \
--columns id,sex \
--table staff \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t"
------------------------------------------------
--columns id,sex \ 是指定id和性别这两列
上面这些都是参数,位置是可以调整的,尽量把mysql参数放在一起,HDFS参数放在一起
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
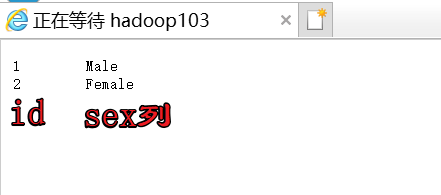
(2) Web端查看结果
- 1
3.1.1.5 Sqoop关键字筛选查询导入HDFS
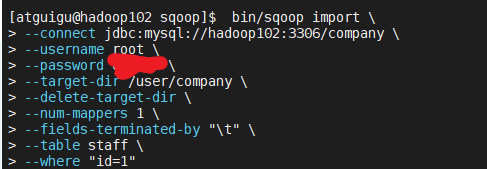
(1) 执行import命令 ---------------------------------------------------------------- bin/sqoop import \ --connect jdbc:mysql://hadoop102:3306/company \ --username root \ --password 666666 \ --target-dir /user/company \ --delete-target-dir \ --num-mappers 1 \ --fields-terminated-by "\t" \ --table staff \ --where "id=1" ---------------------------------------------- where关键字查询还可以加上--columns id,sex 指定列 bin/sqoop import \ --connect jdbc:mysql://hadoop102:3306/company \ --username root \ --password xxxxxx \ --target-dir /user/company \ --delete-target-dir \ --num-mappers 1 \ --fields-terminated-by "\t" \ --table staff \ --columns id,sex \ --where "id=1" 输出的是id为1的那条记录的id列以及性别列,没有name姓名列。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
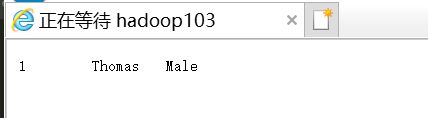
(2) Web端查看结果
- 1
3.1.2 导入数据到Hive
(1)执行import命令 ------------------------------------------- bin/sqoop import \ --connect jdbc:mysql://hadoop102:3306/company \ --username root \ --password xxxxxx \ --table staff \ --num-mappers 1 \ --hive-import \ --fields-terminated-by "\t" \ --hive-overwrite \ --hive-table staff_hive -------------------------------------------- 当前hive没有这张表staff_hive 操作分为两步 一是把数据导入到HDFS,默认的临时目录是/user/atguigu/表名(因为我的HDFS是在atguigu用户) 二是从HDFS迁移到Hive hive有自己的import
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
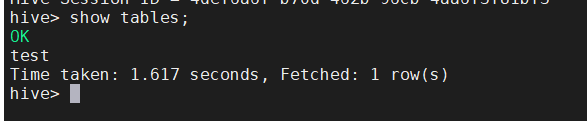
出现错误: ERROR tool.BaseSqoopTool: Error parsing arguments for import:是因为有个空格没有出现,改正就好了,重新执行
- 1

出现错误:
解决:
- 1
- 2
- 3


(2)进入NameNode查看atguihu中有任务在执行
当执行结束后就消失了
证明sqoop导入数据到Hive中确实是分为两步,先导入到HDFS中在迁移到Hive中。要等很久,速度比较慢
Hive中查看数据表
- 1
- 2
- 3
- 4





里面有数据导入到了HDFS
开始导入数据到hive

出现错误:
ERROR tool.ImportTool: Import failed: java.io.IOException: Hive exited with status 64
libthrift jar 包不兼容
解决办法:
将hive lib文件夹中的libthrift-0.9.2.jar 拷贝到sqoop的lib文件夹中
注意再次执行任务,需先把HDFS中已经存在的默认路径文件/user/atguigu/表名 删除
------------------------
sudo cp /opt/module/hive/lib/libthrift-0.9.3.jar /opt/module/sqoop/lib/
hadoop fs -rm -r /user/atguigu
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11



3.1.3 导入数据到HBase
(1) 执行import命令 ---------------------------------------------- bin/sqoop import \ --connect jdbc:mysql://hadoop102:3306/company \ --username root \ --password 666666 \ --table staff \ --columns "id,name,sex" \ --column-family "info" \ --hbase-create-table \ --hbase-row-key "id" \ --hbase-table "hbase_staff" \ --num-mappers 1 \ --split-by id --------------------------------------- 需要注意的是: 由于版本兼容问题,hbase无法自动创建表hbase_staff 需要我们手动在hbase中创建这个表,再执行import命令 ---------------------------- create 'hbase_staff','info'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20

(2) 进入Hbase查看表是否导入
scan 'hbase_staff'
- 1
- 2
3.1.4 死锁问题
kernel:BUG: soft lockup - CPU#1 stuck for 22s! [khugepaged:298]
- 1

查看了一些网友的经验,这是软死锁,系统会自动重启,影响还是挺大的,虽然我的进程还是完成了,不过是因为它比较小
解决办法:
echo 30 > /proc/sys/kernel/watchdog_thresh
sysctl -w kernel.watchdog_thresh=30
vi /etc/sysctl.conf
kernel.watchdog_thresh=30
- 1
- 2
- 3
- 4
- 5
- 6

程序媛叽叽歪歪
呜呜呜,导入hive出现错误,还没有解决好,解决好再补充一下啦!写博客的目的其实就是在做笔记啦,方便拿出来看看背背
后面也不用sqoop,真的太慢了,超级超级慢,等的人向敲桌子,嘿嘿,回见!
- 1
- 2
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/693451
推荐阅读
相关标签

