
- 1zookeeper Client Session 0x0 for server null
- 2SQL查询的一些内嵌函数_内嵌表值函数的查询格式
- 3头歌大数据作业七:Spart_spark graphx—构建图及相关操作 第1关:graphx-构建图及相关基本操作
- 4python入门之文件的读写_python 文件读写模式
- 5FPGA相关应用_余小游
- 6终于看懂别人的代码了!总结Java 8之Lambda表达式的写法套路
- 7『PLSQL』在oracle表中怎样创建自增长字段?_plsql给表里一个字段插入数据,使该字段自增、
- 8解决git clone报错: Failed to connect to github.com port 443 after 21068 ms: Couldn’t connect to server_git clone couldn't connect to server
- 9iOS-判断输入的网址是http还是https,判断网址是否可用_ios判断域名是否可用
- 10地址标准化服务AI深度学习模型推理优化实践_地址解析ai模式训练
中文性能全面超越GPT-4!阿里发布通义千问2.5,登顶中文最强大模型_阿里gpt通义千问
赞
踩
在人工智能领域,阿里云的通义千问大模型以其卓越的性能和开源策略,正逐渐成为中文语境下的强大工具。以下是对阿里云通义千问大模型的深度解析,以及其在开源社区中的重要地位和实际应用的综述。
阿里云放大招,成为最强中文大模型!
阿里云通义千问(Qwen)大模型自发布以来,便以其出色的性能和不断的迭代升级,赢得了业界的广泛关注。在闭源和开源领域,通义千问均展现出了令人满意的成果。特别值得一提的是,通义千问2.5模型在中文场景下的表现已经超越了GPT-4 Turbo,是目前最强的中文大模型。

性能提升与模型迭代
通义千问2.5模型在理解能力、逻辑推理、指令遵循和代码能力方面相较于前序版本通义千问2.1分别提升了9%、16%、19%、10%。在权威大模型评测基准平台OpenCompass上,通义千问2.5的得分追平了GPT-4 Turbo,这标志着国产大模型首次在该基准上取得如此出色的成绩。
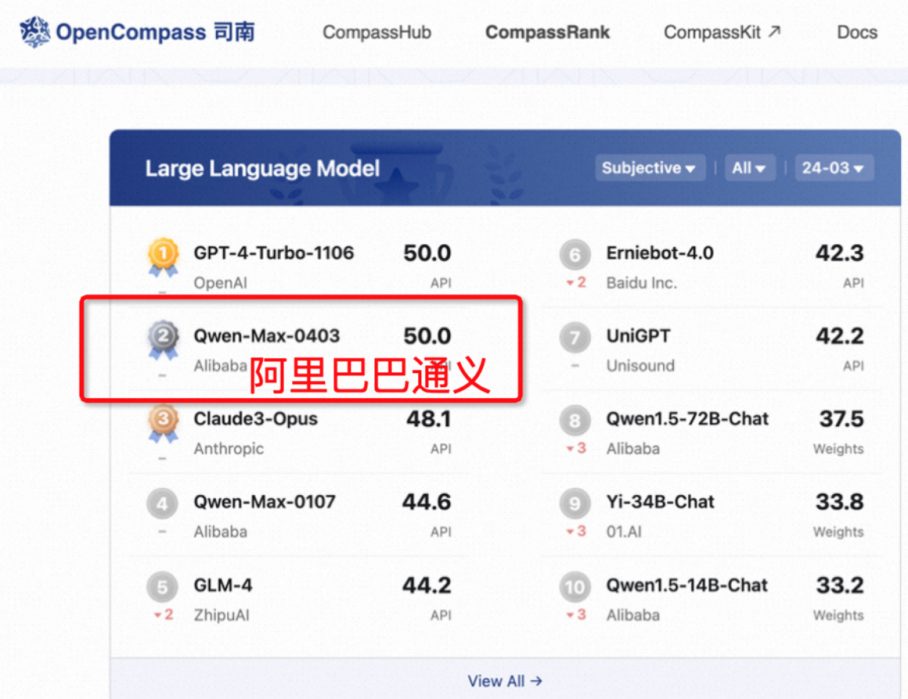
外国网友惊呼:通义千问开源真香!
通义千问的实战效果同样令人印象深刻。无论是在处理文档、音视频理解还是智能编码方面,通义千问均展现出了其强大的能力。
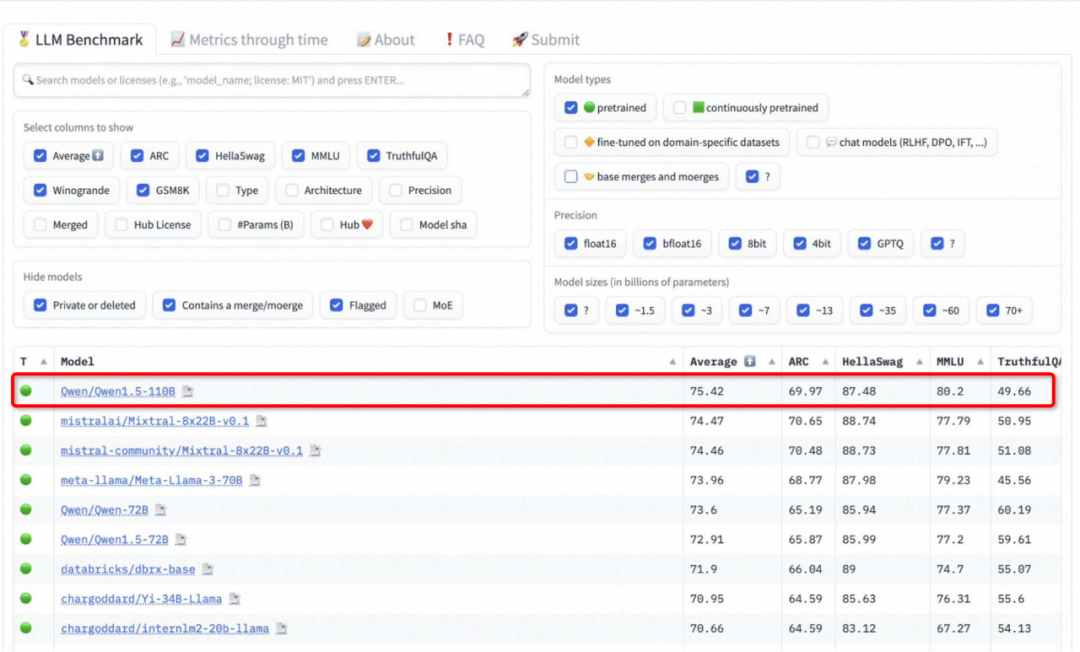
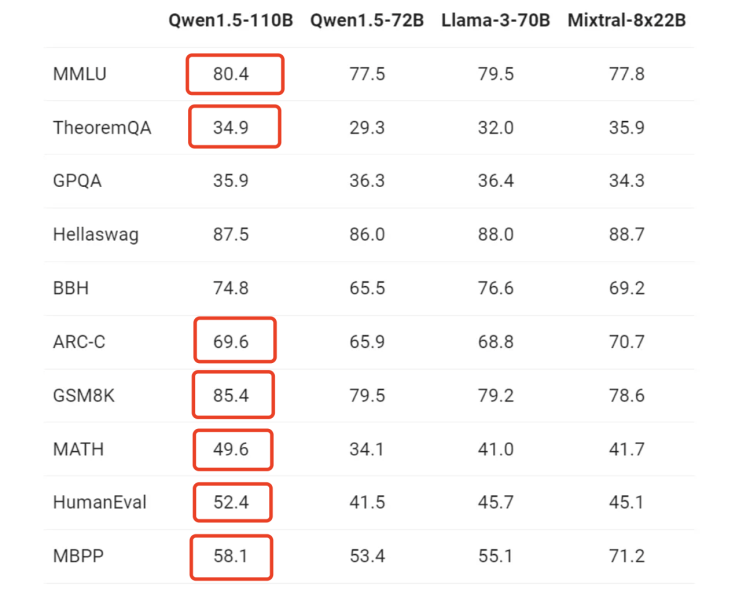
在近期的 HuggingFace 开源大型语言模型排行榜 Open LLM Leaderboard 中,我们发现,Qwen1.5-110B 已经跃居首位,其性能甚至超过了 Llama-3-70B,足以证明证明通义开源大模型在业界的最强竞争力。
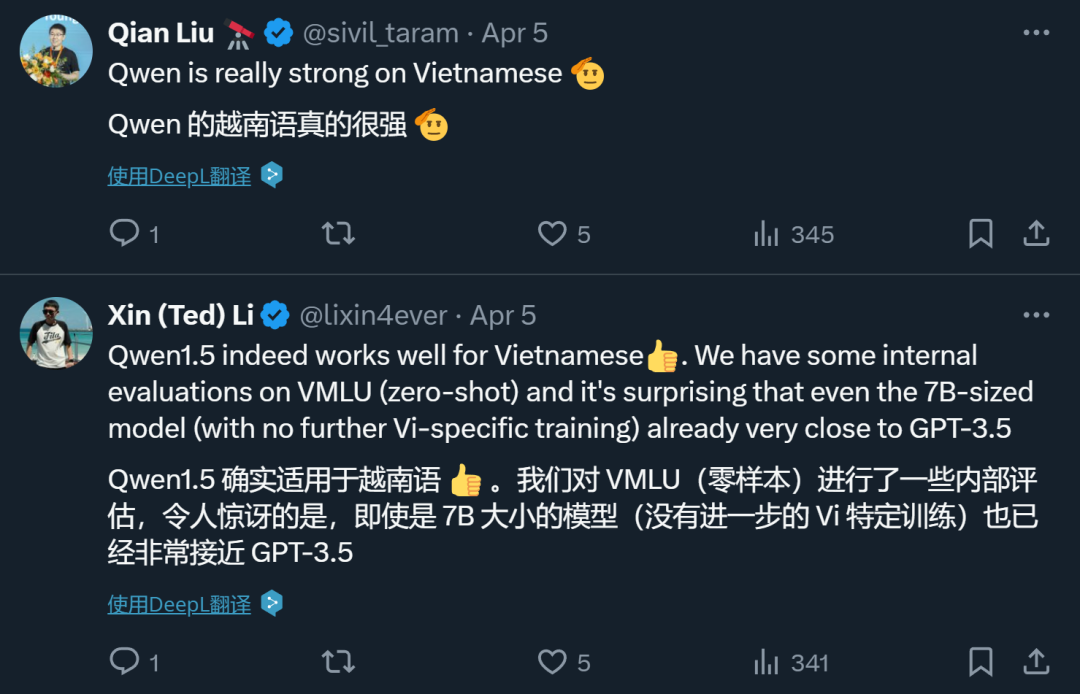
作为国产大模型代表,通义千问也收获了诸多国外网友的好评。比如这位越南网友表示:在我们的VMLU(零样本)内部评估中,通义千问7B模型的能力,已经非常接近GPT-3.5。
开源越来越落后?不!
阿里云通义千问的开源策略,使其成为了开发者和企业真正用得上的大模型。开源不仅促进了技术的共享和创新,还为整个产业乃至每个企业的创新性开发带来了至关重要的影响。
开源布局与社区支持
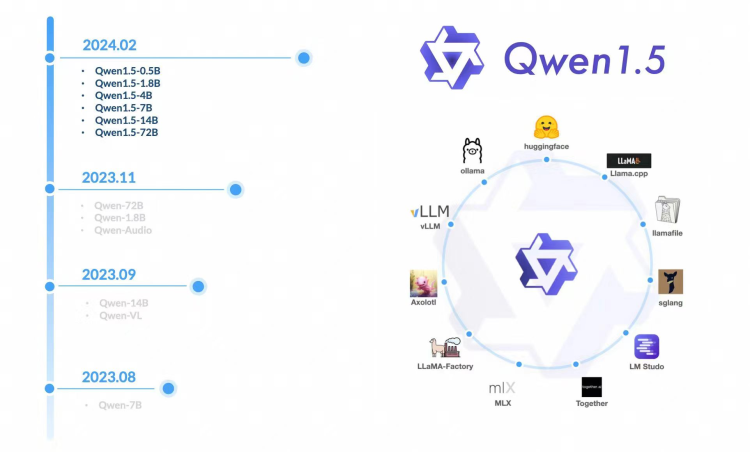
通义千问系列模型的开源节奏紧凑,自去年8月以来,沿着“多模态、全尺寸”开源的路线,已经推出了多款不同参数规格的开源模型,覆盖了从5亿到1100亿参数的全范围,为开发者和企业提供了丰富的选择。在Hugging Face等开源社区,通义千问系列模型的累计下载量已超过700万,成为了社区中的热门选择。

实际效果与客户合作
目前,通义大模型已经通过阿里云服务超9万企业,模型下载量高达700万,已经在天文观测、教育、医疗等多个领域实现落地应用。比如,中国科学院国家天文台基于通义千问开源模型开发的“星语3.0”大模型,标志着中国大模型首次应用于天文观测领域。
开源模型的社会影响
相比使用闭源大模型的,开源大模型的可玩性更高,生态更大,使用开源大模型私有化部署性价比更高,对于要求数据安全、保密性的企业,选择开源大模型也是最优解,这样可以保证自己的数据安全性。
结语
阿里云通义千问大模型的发展历程,是国产AI技术厚积薄发的典型代表。其在中文语境下的卓越性能,以及坚定的开源策略,不仅推动了技术的进步,也为开发者和企业带来了实实在在的价值。随着通义千问2.5的发布,我们有理由相信,国产大模型将在未来的AI领域扮演更加重要的角色。

