
Hive的分区与分桶操作_分桶实验
赞
踩
Hive分区与分桶
1. 前置准备
查看数据文件
stocks.csv文件以逗号“,”分隔,依次记录股票代码、股票交易日期、股票开盘价、股票最高价、股票最低价、股票收盘价、股票交易量和股票成交价。

进入hive客户端
设置Hive本地执行模式,注意如果通过网络执行,可省略此步,数据量不大时,本地可加快执行速度。
SET mapreduce.framework.name=local;
- 1
1.1 实验环境
1)Oracle Linux 7.4
2)Java1.8.0_144
3)Hadoop2.7.4
4)Hive2.3.3
1.2 实验流程
1)建立表stocks,做为原始股票数据表
2)建立分区表p_stocks,将原始表中数据按分区抽取进来,每个分区在HDFS上建立一个文件夹,每个文件夹下存储该分区的数据文件
3)建立分桶表b_stocks,将原始表中的数据按分桶抽取进来,每个分桶在HDFS上所属表下生成一个文件,文件中存储分桶的数据
2. 分区分桶
建立表stocks,做为原始股票数据表

加载数据
LOAD DATA LOCAL INPATH '/root/experiment/datas/hive/stocks.csv' OVERWRITE INTO TABLE stocks;
- 1
查询表
SELECT * FROM stocks;
- 1

2.1 表分区
**建立按symbal分区表p_stocks **
CREATE EXTERNAL TABLE p_stocks(
sno STRING,
symbol STRING,
month STRING,
price_open FLOAT,
price_high FLOAT,
price_low FLOAT,
price_close FLOAT,
volume INT,
price_adj_close FLOAT)
PARTITIONED BY (p_symbol STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
将表stocks中数据按symbol字段分区存储至表p_stocks中
FROM stocks
INSERT INTO TABLE p_stocks PARTITION(p_symbol='APPL') SELECT * WHERE symbol='APPL'
INSERT INTO TABLE p_stocks PARTITION(p_symbol='AAME') SELECT * WHERE symbol='AAME'
INSERT INTO TABLE p_stocks PARTITION(p_symbol='IBM') SELECT * WHERE symbol='IBM'
INSERT INTO TABLE p_stocks PARTITION(p_symbol='ACFN') SELECT * WHERE symbol='ACFN'
INSERT INTO TABLE p_stocks PARTITION(p_symbol='ACAT') SELECT * WHERE symbol='ACAT';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
在Web页面查看HDFS数据物理存储情况,共分为5个文件夹分别记录symbol的5个分区,每个分区下生成一个文件存储了插入的数据。

通过HQL查询表p_stocks中APPL分区的内容
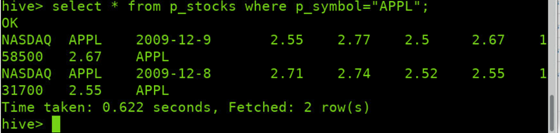
2.2 表分桶
依据
stocks.csv内容,将下面命令输入hive>后,建立分桶表b_stocks
CREATE EXTERNAL TABLE b_stocks(
sno STRING,
symbol STRING,
month STRING,
price_open FLOAT,
price_high FLOAT,
price_low FLOAT,
price_close FLOAT,
volume INT,
price_adj_close FLOAT)
CLUSTERED BY (symbol) INTO 3 BUCKETS
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
设置分桶,设置Reducer的数量与分桶的数量一致
-- 如果不使用set hive.enforce.bucketing=true这项属性,需要显式地声明SET mapreduce.job.reduces=3;来设置Reducer的数量。此外,还需要在SELECT语句后面加上CLUSTERBY来实现INSERT查询。
SET hive.enforce.bucketing=true;
SET mapreduce.job.reduces=3;
- 1
- 2
- 3
- 4
将原始表stocks中的数据按分桶设定格式插入至分桶表b_stocks中
INSERT INTO TABLE b_stocks
SELECT * FROM stocks CLUSTER BY symbol;
- 1
- 2
- 3

查看分桶表b_stocks在HDFS上物理数据存储的格式

以第1个分桶为例,通过HQL语句查看分桶表b_stocks中分桶1的数据
SELECT * FROM b_stocks tablesample(BUCKET 1 out of 3 ON symbol);
- 1
在没有经过分桶的表
stocks中,通过tablesample方法,取出随机分成3桶中的第2桶数据。
SELECT * FROM stocks tablesample(BUCKET 2 out of 3 ON rand());
- 1

3. 流程总结
分桶操作需要根据某一列具体数据来进行哈希取模操作,故指定的分桶列必须基于表中的某一列(字段)。分桶改变了数据的存储方式,它会把哈希取模相同或者在某一区间的数据行放在同一个桶文件中。
桶为表加上了额外的结构,Hive 在处理查询时能利用这个结构,提高了执行效率。
文章仅做记录,涉及侵权内容请联系删除

