
- 1druid数据源检测数据库连接有效性testOnBorrow、testOnReturn、testWhileIdle属性原理分析_druid testwhileidle机制
- 2分布式数据一致性思考-B端系统一致性
- 3龙年伊始,2024北京国际老年产业博览会,助企开拓养老市场
- 4数据库--教务管理系统(数据库部分--Java-jdbc连接)_教务管理系统数据库
- 5简单的vue抽屉效果
- 6Unity 获取当前动画播放的帧_unity获取当前动画播放到第几帧
- 7MSF中kiwi模块的使用_msfgik
- 8Android C 语言读取系统属性___system_property_get
- 9Maven上传jar到私仓_maven批量上传jar到私仓
- 10Spring Boot 中使用 Spring MVC基础
sds和c字符串比较_SDS虚拟化架构的简要比较
赞
踩
sds和c字符串比较
寻找合适的存储平台:GlusterFS vs. Ceph vs. Virtuozzo Storage (The search for a suitable storage platform: GlusterFS vs. Ceph vs. Virtuozzo Storage)
This article outlines the key features and differences of such software-defined storage (SDS) solutions as GlusterFS, Ceph, and Virtuozzo Storage. Its goal is to help you find a suitable storage platform.
本文概述了GlusterFS,Ceph和Virtuozzo Storage这样的软件定义存储(SDS)解决方案的主要功能和区别。 其目标是帮助您找到合适的存储平台。
糊状 (Gluster)
Let’s start with GlusterFS that is often used as storage for virtual environments in open-source-based hyper-converged products with SDS. It is also offered by Red Hat alongside Ceph.
让我们从GlusterFS开始,它通常在带有SDS的基于开源的超融合产品中用作虚拟环境的存储。 Red Hat还与Ceph一起提供了它。
GlusterFS employs a stack of translators, services that handle file distribution and other tasks. It also uses services like Brick that handle disks and Volume that handle pools of bricks. Next, the DHT (distributed hash table) service distributes files into groups based on hashes.
GlusterFS使用了一堆转换器,处理文件分发和其他任务的服务。 它还使用诸如处理磁盘的Brick和处理磁盘池的Volume之类的服务。 接下来,DHT(分布式哈希表)服务基于哈希将文件分布到组中。
Note: We’ll skip the sharding service due to issues related to it, which are described in linked articles.
注意:由于相关的问题,我们将跳过分片服务,这在链接的文章中有介绍。
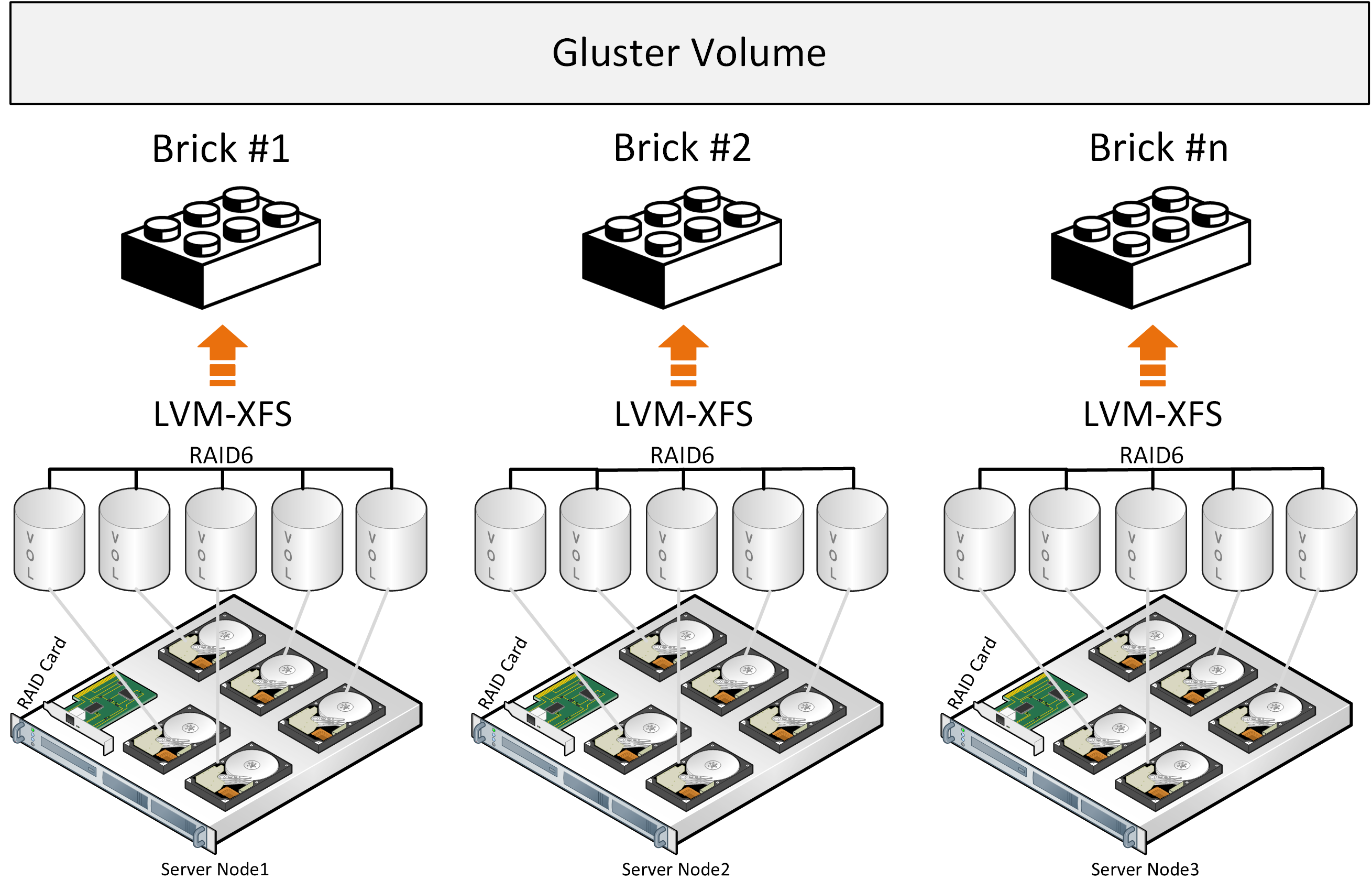
When a file is written onto GlusterFS storage, it is placed on a brick in one piece and copied to another brick on another server. The next file will be placed on two or more other bricks. This works well if the files are of about the same size and the volume consists of a single group of bricks. Otherwise the following issues may arise:
将文件写入GlusterFS存储器时,它会一块放在一块砖上,然后复制到另一台服务器上的另一块砖上。 下一个文件将放置在两个或多个其他块上。 如果文件大小相同且卷由一组砖块组成,则效果很好。 否则可能会出现以下问题:
- Storage space in groups is not utilized evenly, depending on file size. If a group does not have enough space, an attempt to write a file will result in an error. The file will not be written or placed in another group. 根据文件大小,组中的存储空间使用不均匀。 如果组没有足够的空间,则尝试写入文件将导致错误。 该文件将不会被写入或放置在另一个组中。
- When a file is being written, only its group’s I/O is used, resources assigned to other groups are idle. It is impossible to utilize entire volume’s I/O to write a single file. 写入文件时,仅使用其组的I / O,分配给其他组的资源处于空闲状态。 无法利用整个卷的I / O写入单个文件。
- The overall concept looks less efficient due to data not being split into blocks that are easier to balance and distribute evenly. 整体概念看起来效率较低,这是因为数据没有分成更易于平衡和均匀分布的块。
The architecture overview also shows that GlusterFS works as file storage on top of a classic hardware RAID. It also uses such open-source components as FUSE, which has limited performance. There are attempts to shard files into blocks, but they come at the cost of performance as well. This could be somewhat mitigated by means of a metadata service but GlusterFS does not have one. Higher performance is achievable by applying the Distributed Replicated configurations to six and more nodes to set up 3 reliable replicas and provide optimal load balancing.
架构概述还显示,GlusterFS在经典硬件RAID之上充当文件存储。 它还使用性能有限的开源组件(例如FUSE)。 有尝试将文件分片为块,但是它们也以性能为代价。 通过元数据服务可以稍微缓解这种情况,但是GlusterFS没有。 通过将分布式复制配置应用于六个及更多节点以设置3个可靠副本并提供最佳负载平衡,可以实现更高的性能。

The figure above shows distribution of load while two files are being written. The first file is copied onto three servers grouped into Volume 0. The second file is copied onto Volume 1, which also comprises three servers. Each server has a single disk.
上图显示了写入两个文件时的负载分布。 第一个文件复制到分组为Volume 0的三个服务器上。第二个文件复制到也包含三个服务器的Volume 1中。 每个服务器只有一个磁盘。
The general conclusion is that you can use GlusterFS if you understand its performance and fault tolerance limits that will hinder certain hyper-converged setups where resources are spent on compute workloads as well.
总体结论是,如果您了解GlusterFS的性能和容错性限制,这些限制也会阻碍某些超融合设置,而在这些超融合设置中,资源也会花费在计算工作负载上,那么您可以使用GlusterFS。
More details on performance that you can achieve with GlusterFS, even if with limited fault tolerance, are provided at.
即使在有限的容错范围内,也提供了有关使用GlusterFS可以实现的性能的更多详细信息。
头孢 (Ceph)
Now let’s take a look at Ceph. According to research published on the Internet, Ceph works best on dedicated servers as it may require all of the available hardware resources under load.
现在让我们看一下Ceph。 根据Internet上发布的研究,Ceph在专用服务器上效果最好,因为它可能需要负载才能使用所有可用的硬件资源。
The architecture of Ceph is more intricate than that of GlusterFS. In particular, Ceph stores data as blocks, which looks more efficient, and it also does employ metadata services. The overall stack of components is rather complicated, however, and not very flexible when it comes to using Ceph with virtualization. Due to complexity and lack of flexibility, the component hierarchy can be prone to losses and latencies under certain loads and in hardware failure events.
Ceph的体系结构比GlusterFS更复杂。 特别是,Ceph将数据存储为块,看起来效率更高,并且它确实使用了元数据服务。 但是,组件的整体堆栈相当复杂,而在将Ceph与虚拟化一起使用时,灵活性并不高。 由于复杂性和缺乏灵活性,在某些负载下以及硬件故障事件中,组件层次结构可能易于丢失和等待时间。
At the heart of Ceph is the Controlled Replication Under Scalable Hashing (CRUSH) algorithm that handles distribution of data on storage. The next key part is a placement group (PG) that groups objects to reduce resource consumption, increase performance and scalability, and make CRUSH more efficient. Addressing each object directly, without grouping them into PGs, would be quite resource-intensive. Finally, each disk is managed by its OSD service.
Ceph的核心是可伸缩哈希下的受控复制(CRUSH)算法,该算法处理存储中的数据分配。 下一个关键部分是放置组(PG),该组将对象分组以减少资源消耗,提高性能和可伸缩性并提高CRUSH的效率。 直接寻址每个对象而不将它们分组到PG中将非常耗费资源。 最后,每个磁盘都由其OSD服务管理。

Overall diagram
整体图

PG and hashing function diagram
PG和哈希函数图
On the logical tier, a cluster can comprise one or more pools of data of different types and configurations. Pools are divided into PGs. PGs store objects that clients access. On the physical tier, each PG is assigned one primary disk and multiple replica disks, as per pool replication factor. Logically, each object is stored in a PG, while physically it’s kept on that PG’s disks, which can be located on different servers or even in different datacenters.
在逻辑层上,集群可以包含一个或多个不同类型和配置的数据池。 池分为PG。 PG存储客户端访问的对象。 在物理层上,根据池复制因子,为每个PG分配了一个主磁盘和多个副本磁盘。 从逻辑上讲,每个对象都存储在PG中,而从物理上讲,它保存在该PG的磁盘上,这些磁盘可以位于不同的服务器上,甚至可以位于不同的数据中心中。
In this architecture, PGs look necessary to provide flexibility to Ceph, but they also seem to reduce its performance. For example, when writing data, Ceph has to place it in a PG logically and across PG’s disks physically. The hash function works when both searching and inserting objects but the side effect is that rehashing (for example, when adding or removing disks) is very resource-intensive and limited. Another issue with the hash is that it does not allow relocating the data once it has been placed. So if a disk is under a high load, Ceph cannot write data onto another disk instead. Because of this, Ceph consumes a lot of memory when PGs are self-healing or when the storage capacity is increased.
在这种体系结构中,PG看起来很有必要为Ceph提供灵活性,但它们似乎也会降低其性能。 例如,在写入数据时,Ceph必须将其逻辑上放置在PG中,物理上放置在PG的磁盘上。 散列函数在搜索和插入对象时均有效,但副作用是重新散列(例如,在添加或删除磁盘时)非常耗费资源并且受到限制。 散列的另一个问题是,一旦放置了数据,便不允许重新定位数据。 因此,如果磁盘负载较高,则Ceph无法将数据写入另一磁盘。 因此,当PG进行自我修复或增加存储容量时,Ceph会占用大量内存。
The general conclusion is that Ceph work well (albeit slowly) when it does not come to scalability, emergencies or updates. With good hardware, you can improve its performance by means of caching and cache tiering. Overall, Ceph seems to be a better choice for production than GlusterFS.
总体结论是,在涉及可伸缩性,紧急情况或更新时,Ceph可以很好地运行(尽管运行缓慢)。 有了良好的硬件,您可以通过缓存和缓存分层来提高其性能。 总体而言,与GlusterFS相比,Ceph似乎是更好的生产选择。
储存空间 (Vstorage)
Now let’s turn to Virtuozzo Storage that has an even more interesting architecture. It can share a server with a hypervisor (KVM/QEMU) and can be installed rather easily on a lot of hardware. The caveat is that the entire solution needs to be configured right to achieve good performance.
现在,我们来看一下具有更有趣架构的Virtuozzo Storage。 它可以与管理程序(KVM / QEMU)共享服务器,并且可以很容易地安装在许多硬件上。 需要注意的是,整个解决方案需要正确配置才能获得良好的性能。
Virtuozzo Storage utilizes just a few services organized in a compact hierarchy: the client service mounted via a custom FUSE implementation, a metadata service (MDS), and a chunk service (CS) that equals to a single disk on the physical tier. In terms of performance, the fastest fault tolerant setup is two replicas, although with caching and journals on SSD disks, you can also achieve good performance with erasure coding (EC) or RAID6 on a hybrid or, better yet, an all-flash configuration. The downside of EC is that changing even a single chunk (block of data) means that checksums need to be recalculated. To avoid losing resources on this, Ceph, for example, uses delayed writes with EC.
Virtuozzo Storage仅利用按紧凑层次结构组织的一些服务:通过自定义FUSE实现安装的客户端服务,元数据服务(MDS)和相当于物理层上单个磁盘的块服务(CS)。 在性能方面,最快的容错设置是两个副本,尽管在SSD磁盘上具有缓存和日志,您也可以在混合或更好的全闪存配置中使用擦除编码(EC)或RAID6获得良好的性能。 。 EC的缺点是,即使更改单个块(数据块),也意味着需要重新计算校验和。 为了避免在此方面浪费资源,例如,Ceph使用EC延迟写入。
This may result in performance issues in case of certain requests, e.g., to read all the blocks. In turn, Virtuozzo Storage writes changed chunks using the log-structured file system approach that minimizes performance expenses on checksum calculations. An online calculator provided by Virtuozzo helps you estimate performance with and without EC and plan your configuration accordingly.
在某些请求(例如,读取所有块)的情况下,这可能会导致性能问题。 反过来,Virtuozzo Storage使用日志结构化的文件系统方法写入更改的块,从而将校验和计算的性能开销降至最低。 Virtuozzo提供的在线计算器可帮助您评估是否使用EC的性能,并据此计划配置。
Despite the simplicity of the Virtuozzo Storage architecture, its components still need decent hardware as laid out in the requirements. So if you need a hyper-converged setup alongside a hypervisor, it is recommended to plan the server configuration beforehand.
尽管Virtuozzo存储体系结构很简单,但其组件仍需要按要求列出的体面的硬件。 因此,如果您需要在虚拟机管理程序旁边安装超融合设置,建议事先计划服务器配置。
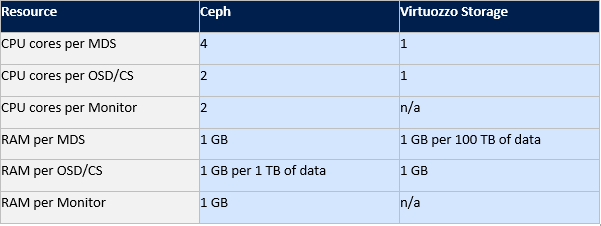
The following table compares the consumption of hardware resource by Ceph and Virtuozzo Storage:
下表比较了Ceph和Virtuozzo Storage消耗的硬件资源:
Unlike GlusterFS and Ceph that can easily be compared based on research published on the Internet, Virtuozzo Storage is not as popular, so the documentation remains the primary source of information about its features.
与GlusterFS和Ceph可以轻松地基于Internet上发布的研究进行比较相比,Virtuozzo Storage不那么受欢迎,因此文档仍然是有关其功能的主要信息来源。
For this reason, I will describe the architecture of Virtuozzo Storage in more detail, so the part dedicated to this solution will be longer.
因此,我将更详细地描述Virtuozzo Storage的体系结构,因此致力于该解决方案的部分将更长。
Let’s take a look at how writes are performed in a hybrid setup where data is stored on HDDs while caches (read/write journals) are kept on SSDs.
让我们看一下如何在混合设置中执行写入操作,在混合设置中,数据存储在HDD上,而缓存(读/写日志)则保留在SSD上。
A client, a FUSE mount point service, initiates a write to the server where the mount point is. Then MDS directs the client to a CS that manages data chunks of equal size (256 MB) on a single disk.
客户端(FUSE挂载点服务)启动对挂载点所在服务器的写入。 然后,MDS将客户端定向到CS,该CS在单个磁盘上管理大小相等(256 MB)的数据块。

The chunk is replicated, almost in parallel, to multiple servers, according to the replication factor. In a setup with the replication factor of 3 and caches (read/write journals) on SSDs, the data write is committed after the journal has been written to the SSD. At that moment, however, the data is still being flushed from the caching SSD to the HDD in parallel.
根据复制因子,该块几乎并行地复制到多个服务器。 在具有3的复制因子和SSD上的缓存(读/写日志)的设置中,在将日志写入SSD后提交数据写入。 但是,此时,数据仍在并行地从高速缓存SSD刷新到HDD。
Essentially, as soon as the data gets into a journal on the SSD, it’s immediately read and flushed to HDD. Given the replication factor of 3, the write will be committed after it’s been confirmed by the third server’s SSD drive. It may seem that dividing the sum of SSD write speeds by the number of SSDs produces the speed at which one replica is written.
本质上,一旦数据进入SSD的日志中,就会立即读取并刷新到HDD。 给定复制因子3,在第三台服务器的SSD驱动器确认写入后,将提交写入。 看来,将SSD写入速度的总和除以SSD的数量可得出写入一个副本的速度。
Actually, replicas are written in parallel and since SSDs have much lower latencies than the network, the write speed essentially depends on network throughput. One can estimate the actual system IOPS by loading the entire system the right way, instead of focusing only on memory and cache. There is a dedicated test method for this that takes into account data block size, the number of threads, and other things.
实际上,副本是并行写入的,并且由于SSD的延迟比网络低得多,因此写入速度主要取决于网络吞吐量。 通过以正确的方式加载整个系统,而不是只关注内存和缓存,可以估算出实际的系统IOPS。 为此有一种专用的测试方法 ,该方法考虑了数据块大小,线程数以及其他因素。
The number of MDS per cluster is determined by the Paxos algorithm. Also, from the client’s point of view, the FUSE mount point is a storage directory mounted to all servers at once.
每个群集的MDS数量由Paxos算法确定。 同样,从客户端的角度来看,FUSE挂载点是一次挂载到所有服务器的存储目录。
Another beneficial distinction of Virtuozzo Storage from Ceph and GlusterFS is FUSE with fast path. It significantly improves IOPS and lets you go beyond just horizontal scalability. The downside is that Virtuozzo Storage requires a paid license unlike Ceph and GlusterFS.
Virtuozzo Storage与Ceph和GlusterFS的另一个有益区别是具有快速路径的FUSE。 它显着提高了IOPS,并让您超越了水平可扩展性。 不利之处在于,与Ceph和GlusterFS不同,Virtuozzo Storage需要付费许可证。
For every platform described in this article, it’s vital to properly plan and deploy the network infrastructure, providing enough bandwidth and proper aggregation. For the latter, it’s very important to choose the right hashing scheme and frame size.
对于本文描述的每个平台,至关重要的是正确规划和部署网络基础结构,提供足够的带宽和适当的聚合。 对于后者,选择正确的哈希方案和帧大小非常重要。
To sum it up, Virtuozzo Storage offers the best performance and reliability, followed by Ceph and GlusterFS. Virtuozzo Storage wins for having the optimal architecture, custom FUSE with fast path, the ability to work on flexible hardware configurations, lower resource consumption, and the possibility to share the hardware with compute/virtualization. In other words, it is a part of a hyper-converged solution. Ceph is second because its block-based architecture allows it to outperform GlusterFS, as well as work on more hardware setups and in larger-scale clusters.
综上所述,Virtuozzo Storage提供了最佳的性能和可靠性,其次是Ceph和GlusterFS。 Virtuozzo Storage凭借其最佳架构,具有快速路径的自定义FUSE,能够在灵活的硬件配置上工作,降低资源消耗以及通过计算/虚拟化共享硬件的能力而赢得了胜利。 换句话说,它是超融合解决方案的一部分。 Ceph位居第二,因为它的基于块的体系结构使其可以胜过GlusterFS,并且可以在更多的硬件设置和更大的集群中使用。
In my next article, I would like to compare vSAN, Space Direct Storage, Virtuozzo Storage, and Nutanix Storage. I would also like to review Virtuozzo Storage integration into third-party hardware data storage solutions.
在我的下一篇文章中,我想比较vSAN,空间直接存储,Virtuozzo存储和Nutanix存储。 我还想回顾一下Virtuozzo Storage与第三方硬件数据存储解决方案的集成。
If you have any comments or questions regarding the article, please let me know.
如果您对本文有任何意见或疑问,请告诉我。
The translation was helped by Artem Pavlenko, many thanks to him for this.
翻译由Artem Pavlenko帮助,非常感谢他的帮助。
sds和c字符串比较

