
- 1java中String类详解(java.lang.String)
- 2计算机安全中心无法启动,win10无法启动安全中心服务的解决方法
- 3专利转化运用行动方案解读-于春堂|中国智库·国家(中国)智库
- 4activity中Variable和VariableLocal在taskService和runtimeService中的设置和获取_taskservice.getvariables
- 5微信小程序使用蓝牙连接硬件_startbluetoothdevicesdiscovery
- 6循环神经网络:GRU_gru神经网络谁发明的
- 7C++ 链表有环问题解决_链表有环怎么处理
- 8pnpm配置(重启!重启!重启!)_pnpm环境变量设置
- 92020年十大IC设计企业_ic设计企业排名
- 10IOS 使用itms-services协议,服务端安装应用
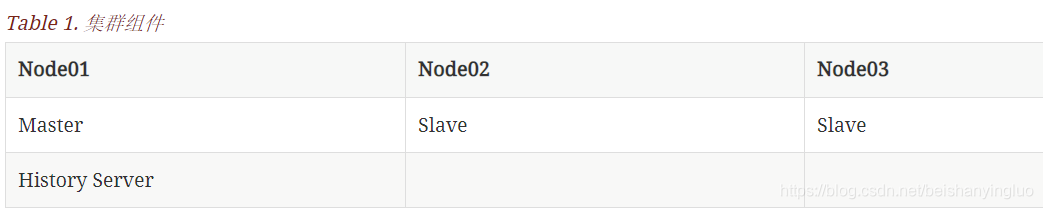
Spark 集群搭建(完整)_spark3.3.4集群环境搭建
赞
踩
1. Spark 集群结构
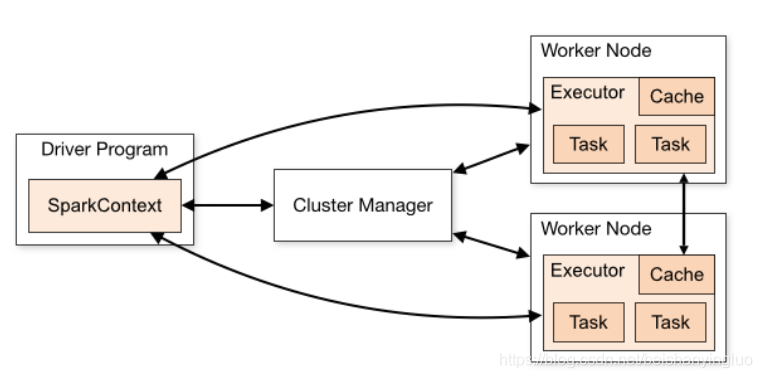
名词解释
Driver
- 该进程调用 Spark 程序的 main 方法, 并且启动 SparkContext。
Cluster Manager
- 该进程负责和外部集群工具打交道, 申请或释放集群资源。
Worker
- 该进程是一个守护进程, 负责启动和管理 Executor。
Executor
- 该进程是一个JVM虚拟机, 负责运行 Spark Task。
运行一个 Spark 程序大致经历如下几个步骤:
-
启动 Drive, 创建 SparkContext;
-
Client 提交程序给 Drive, Drive 向 Cluster Manager 申请集群资源;
-
资源申请完毕, 在 Worker 中启动 Executor;
-
Driver 将程序转化为 Tasks, 分发给 Executor 执行。
问题一: Spark 程序可以运行在什么地方?
-
集群: 一组协同工作的计算机, 通常表现的好像是一台计算机一样, 所运行的任务由软件来控制和调度;
-
集群管理工具: 调度任务到集群的软件;
-
常见的集群管理工具: Hadoop Yarn, Apache Mesos, Kubernetes。
Spark 可以将任务运行在两种模式下:
-
单机, 使用线程模拟并行来运行程序;
-
集群, 使用集群管理器来和不同类型的集群交互, 将任务运行在集群中。
Spark 可以使用的集群管理工具有:
-
Spark Standalone
-
Hadoop Yarn
-
Apache Mesos
-
Kubernetes
问题二: Driver 和 Worker 什么时候被启动?
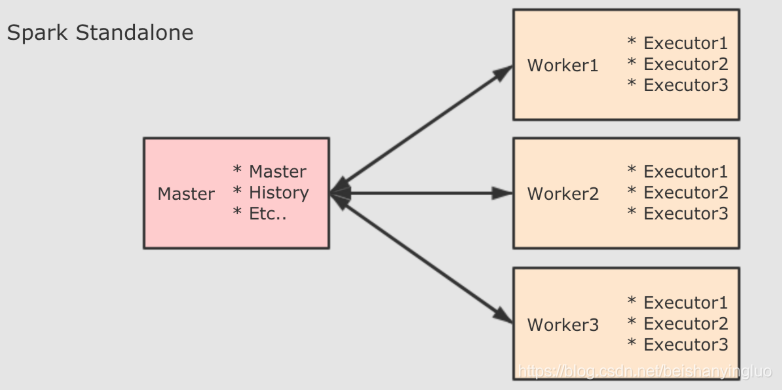
-
Standalone 集群中, 分为两个角色: Master 和 Slave, 而 Slave 就是 Worker, 所以在 Standalone 集群中, 启动之初就会创建固定数量的 Worker。
-
Driver 的启动分为两种模式: Client 和 Cluster. 在 Client 模式下, Driver 运行在 Client 端, 在 Client 启动的时候被启动. 在 Cluster 模式下, Driver 运行在某个 Worker 中, 随着应用的提交而启动。
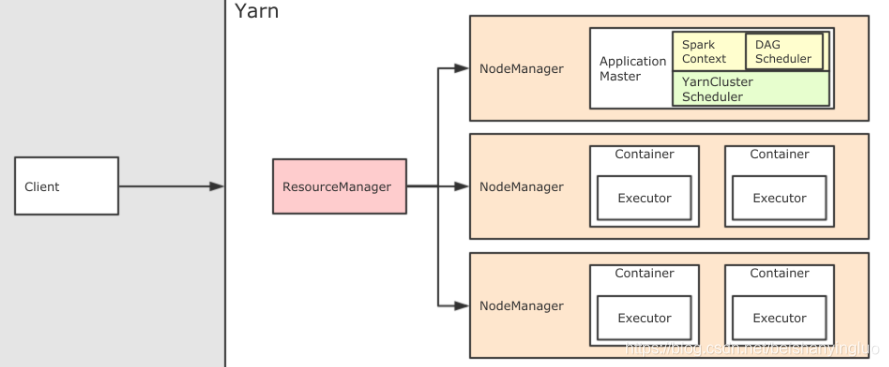
-
在 Yarn 集群模式下, 也依然分为 Client 模式和 Cluster 模式, 较新的版本中已经逐渐在废弃 Client 模式了, 所以上图所示为 Cluster 模式。
-
如果要在 Yarn 中运行 Spark 程序, 首先会和 RM 交互, 开启 ApplicationMaster, 其中运行了 Driver, Driver创建基础环境后, 会由 RM 提供对应的容器, 运行 Executor, Executor会反向向 Driver 反向注册自己, 并申请 Tasks 执行。
-
在后续的 Spark 任务调度部分, 会更详细介绍。
总结
-
Master 负责总控, 调度, 管理和协调 Worker, 保留资源状况等;
-
Slave 对应 Worker 节点, 用于启动 Executor 执行 Tasks, 定期向 Master汇报;
-
Driver 运行在 Client 或者 Slave(Worker) 中, 默认运行在 Slave(Worker) 中。
2. Spark 集群搭建
2.1 下载和解压
注意: 此步骤假设大家的 Hadoop 集群已经能够无碍的运行, 并且 Linux 的防火墙和 SELinux 已经关闭, 时钟也已经同步, 如果还没有, 请参考 Hadoop 集群搭建部分, 完成以上三件事。
1. 下载
# 下载 Spark
cd /export/softwares
wget https://archive.apache.org/dist/spark/spark-2.2.0/spark-2.2.0-bin-hadoop2.7.tgz
- 1
- 2
- 3
2. 解压并拷贝到export/servers
# 解压 Spark 安装包
tar xzvf spark-2.2.0-bin-hadoop2.7.tgz
# 移动 Spark 安装包
mv spark-2.2.0-bin-hadoop2.7 /export/servers/spark
- 1
- 2
- 3
- 4
- 5
3.修改配置文件spark-env.sh, 以指定运行参数
进入配置目录, 并复制一份新的配置文件, 以供在此基础之上进行修改
cd /export/servers/spark/conf
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
- 1
- 2
- 3
将以下内容复制进配置文件末尾
# 指定 Java Home
export JAVA_HOME=/export/servers/jdk1.8.0_221
# 指定 Spark Master 地址
export SPARK_MASTER_HOST=node01
export SPARK_MASTER_PORT=7077
- 1
- 2
- 3
- 4
- 5
- 6
2.2 配置
1. 修改配置文件 slaves, 以指定从节点为止, 从在使用 sbin/start-all.sh 启动集群的时候, 可以一键启动整个集群所有的 Worker
进入配置目录, 并复制一份新的配置文件, 以供在此基础之上进行修改
cd /export/servers/spark/conf
cp slaves.template slaves
vi slaves
- 1
- 2
- 3
配置所有从节点的地址
node02
node03
- 1
- 2
2.配置 HistoryServer
a.默认情况下, Spark 程序运行完毕后, 就无法再查看运行记录的 Web UI 了, 通过 HistoryServer 可以提供一个服务, 通过读取日志文件, 使得我们可以在程序运行结束后, 依然能够查看运行过程
b.复制 spark-defaults.conf, 以供修改
cd /export/servers/spark/conf
cp spark-defaults.conf.template spark-defaults.conf
vi spark-defaults.conf
- 1
- 2
- 3
c.将以下内容复制到spark-defaults.conf末尾处, 通过这段配置, 可以指定 Spark 将日志输入到 HDFS 中
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node01:8020/spark_log
spark.eventLog.compress true
- 1
- 2
- 3
d.将以下内容复制到spark-env.sh的末尾, 配置 HistoryServer 启动参数, 使得 HistoryServer 在启动的时候读取 HDFS 中写入的 Spark 日志
# 指定 Spark History 运行参数
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://node01:8020/spark_log"
- 1
- 2
e.为 Spark 创建 HDFS 中的日志目录
hdfs dfs -mkdir -p /spark_log
- 1
可能会出现错误:
[root@node01 hadoop-2.7.5]# hdfs dfs -mkdir -p /spark_log
mkdir: Cannot create directory /spark_log. Name node is in safe mode.
- 1
- 2
这是因为安全模式,不允许添加,关闭安全模式即可,操作如下,在hadoop目录下执行:
[root@node01 hadoop-2.7.5]# hadoop dfsadmin -safemode leave
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
Safe mode is OFF
- 1
- 2
- 3
- 4
- 5
2.3 分发和运行
1. 将 Spark 安装包分发给集群中其它机器
cd /export/servers
scp -r spark root@node02:$PWD
scp -r spark root@node03:$PWD
- 1
- 2
- 3
2.启动 Spark Master 和 Slaves, 以及 HistoryServer
cd /export/servers/spark
sbin/start-all.sh
sbin/start-history-server.sh
- 1
- 2
- 3
3. Spark 集群高可用搭建
如何使用 Zookeeper 帮助 Spark Standalone 高可用?
对于 Spark Standalone 集群来说, 当 Worker 调度出现问题的时候, 会自动的弹性容错, 将出错的 Task 调度到其它 Worker 执行。
但是对于 Master 来说, 是会出现单点失败的, 为了避免可能出现的单点失败问题, Spark 提供了两种方式满足高可用:
-
使用 Zookeeper 实现 Masters 的主备切换
-
使用文件系统做主备切换 (不经常用)
3.1 停止 Spark 集群
cd /export/servers/spark
sbin/stop-all.sh
- 1
- 2
3.2 修改配置文件, 增加 Spark 运行时参数, 从而指定 Zookeeper 的位置
1.进入 spark-env.sh 所在目录, 打开 vi 编辑
cd /export/servers/spark/conf
vi spark-env.sh
- 1
- 2
2.编辑 spark-env.sh, 添加 Spark 启动参数, 并去掉 SPARK_MASTER_HOST 地址

具体内容如下:
# 指定 Java Home
export JAVA_HOME=/export/servers/jdk1.8.0_221
# 指定 Spark Master 地址
# export SPARK_MASTER_HOST=node01
export SPARK_MASTER_PORT=7077
# 指定 Spark History 运行参数
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://node01:8020/spark_log"
# 指定 Spark 运行时参数
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node01:2181,node02:2181,node03:2181 -Dspark.deploy.zookeeper.dir=/spark"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3.3 分发配置文件到整个集群
cd /export/servers/spark/conf
scp spark-env.sh node02:$PWD
scp spark-env.sh node03:$PWD
- 1
- 2
- 3
3.4 启动
1.在 node01 上启动整个集群
cd /export/servers/spark
sbin/start-all.sh
sbin/start-history-server.sh
- 1
- 2
- 3
2.在 node02 上单独再启动一个 Master
cd /export/servers/spark
sbin/start-master.sh
- 1
- 2
3.5 查看 node01 master 和 node02 master 的 WebUI
1.你会发现一个是 ALIVE(主), 另外一个是 STANDBY(备)
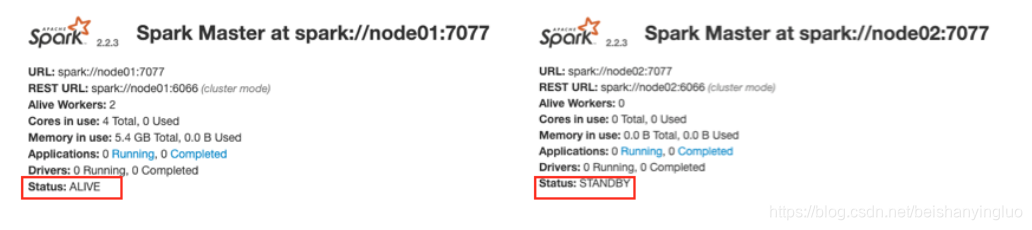
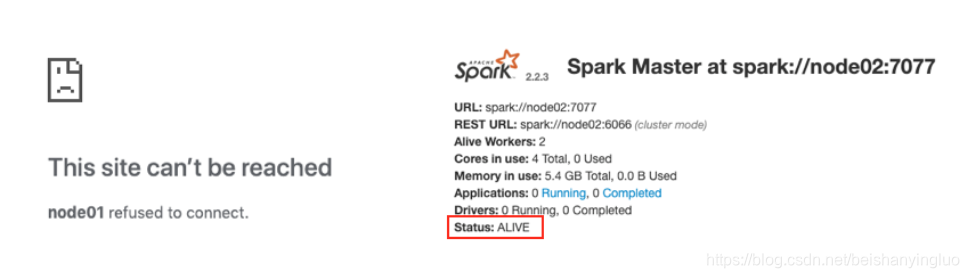
2.如果关闭一个, 则另外一个成为ALIVE, 但是这个过程可能要持续两分钟左右, 需要耐心等待
# 在 Node01 中执行如下指令
cd /export/servers/spark/
sbin/stop-master.sh
- 1
- 2
- 3
Spark HA 选举:
Spark HA 的 Leader 选举使用了一个叫做 Curator 的 Zookeeper 客户端来进行。
Zookeeper 是一个分布式强一致性的协调服务, Zookeeper 最基本的一个保证是: 如果多个节点同时创建一个 ZNode, 只有一个能够成功创建. 这个做法的本质使用的是 Zookeeper 的 ZAB 协议, 能够在分布式环境下达成一致.
4. 第一个应用的运行
4.1 进入 Spark 安装目录中
cd /export/servers/spark/
- 1
4.2 运行 Spark 示例任务
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://node01:7077,node02:7077,node03:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
/export/servers/spark/examples/jars/spark-examples_2.11-2.2.3.jar \
100
- 1
- 2
- 3
- 4
- 5
- 6
- 7
4.3 运行结果
Pi is roughly 3.141550671141551
- 1
刚才所运行的程序是 Spark 的一个示例程序, 使用 Spark 编写了一个以蒙特卡洛算法来计算圆周率的任务

计算过程
-
不断的生成随机的点, 根据点距离圆心是否超过半径来判断是否落入园内
-
通过 Spark01 cfb9a 来计算圆周率
-
不断的迭代

