
- 1如何实现高效数据处理?探索BI数据绑定与前端数据处理的最佳实践!
- 2windows下安装rabbitmq_windows安装rabbitmq
- 3linux xshell jdk hadoop(环境搭建) 虚拟机 安装(大数据搭建环境)
- 4nodejs、npm、webpack、vue-cli入门及使用_nodejs npm webpack vue
- 5网络网络层之(6)ICMPv4协议
- 6Kafka主从同步及leader&follower的理解_kafka的leader和follower
- 7Spring Cloud Gateway详解_spring cloud getaway作用
- 8vue和react 的简单对比_vue react
- 9git:如何做代码回滚
- 10大数据开发之kafka(完整版)_kafka详解大数据
MySQL基础学习: 第四章 使用EXPLAIN查看执行计划详解分析_explain查询执行计划
赞
踩
文章目录
一、EXPLAIN语句的作用
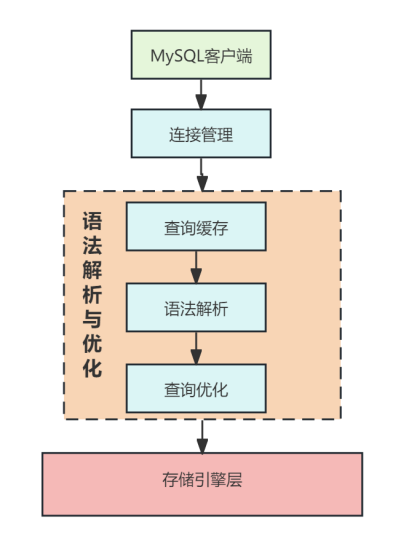
在客户端执行MySQL的操作语句,会依次经过MySQL客户端连接管理、语法解析与优化(查询缓存、语法解析、查询优化)、存储引擎层。其中查询优化器在基于成本和规则对查询语句进行优化,并且在优化后会生成一个执行计划。MySQL提供了EXPLAIN语句来查看查询语句经过查询优化器优化后的执行计划。
定义本章所使用的表结构:
CREATE TABLE `source_learn` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增主键', `data_type` enum('oracle’,'mysql') DEFAULT 'oracle' COMMENT '源类型', `name` varchar(100) NOT NULL COMMENT '源名称', PRIMARY KEY (`id`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=1DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC; CREATE TABLE `source_learn_param` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id', `source_id` bigint(20) NOT NULL COMMENT '关联源id', `key` varchar(50) NOT NULL COMMENT '参数key', `value` text NOT NULL COMMENT '参数值', `data_type` enum('oracle','mysql') DEFAULT 'oracle' COMMENT '源类型', PRIMARY KEY (`id`) USING BTREE, KEY `source_id_index` (`source_id`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC; CREATE TABLE `table_test_learn` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `source_id` bigint(20) DEFAULT NULL COMMENT '源id', PRIMARY KEY (`id`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=1DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='元数据';

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
二、EXPLAIN语句的属性含义及作用
EXPLAIN语句包含如下属性列:
| 属性名 | 说明 |
|---|---|
| id | 每个SELECT对应的唯一id |
| select_type | 每个SELECT对应的查询类型 |
| table | 表名称 |
| paritions | 分区信息 |
| type | 单表的访问方法 |
| possible_keys | 可能使用到的索引 |
| key | 实际使用的索引 |
| key_len | 实际使用到的索引长度 |
| ref | |
| rows | 预计要读取到的记录数量 |
| filtered | |
| Extra | 额外的一些信息 |
1、id
在查询语句(经过查询优化器优化后的查询语句)中可能会包含多个SELECT语句,每个select语句都会对应一个唯一的id。并且查询计划会为每个表生成一个记录,但是这些记录的id可能存在相同的情况。
(1)简单的SELECT语句
explain select id,name from source_learn where data_type = 'oracle';
- 1

(2)包含子查询的SELECT语句
EXPLAIN select * from table_test_learn as test where test.source_id in (select source_learn.id from source_learn where source_learn.data_type = 'oracle');
- 1

可以看到这个子查询语句生成的执行计划中包含两条记录,这两条的分别对应表table_test_learn和表source_learn。这个查询语句包含了两个SELECT查询语句为什么id值是相同的呢?这里的id相同表示着:通过查询优化器对查询语句的优化,将子查询语句转变成了连接查询语句。
2、select_type
在一个查询语句中可能包含多个小的查询语句,在MySQL中每个小的查询语句都包含select_type属性,通过该属性的取值,我们可以判断出这个小的查询语句在整个查询语句中扮演着一个什么样的角色。该属性的取值如下:
| 取值 | 说明 |
|---|---|
| SIMPLE | 没有UNION或查询优化器优化后不包含子查询的语句 |
| PRIMARY | 包含联合查询或查询优化器优化后包含子查询的,第一条记录的select_type的取值就是PRIMARY |
| UNION | 查询语句包含联合查询,除了第一个记录外,其余记录的select_type的取值是UNION |
| UNION RESULT | 对于UNION操作产生的临时表的select_type的取值为UNION RESULT |
| SUBQUERY | 对于非相关子查询的记录的select_type的取值为SUBQUERY |
| DEPENDENT SUBQUERY | 对于相关子查询的记录的select_type的取值为DEPENDENT SUBQUERY |
| DEPENDENT UNION | |
| DERIVED | |
| MATERIALIZED | 对于包含子查询的语句,存在需要将子查询物化后再参与连接查询,此时的select_type的取值为MATERIALIZED |
(1)SIMPLE
下面展示了内连接查询语句的执行计划,在查询语句中不包含UNION和子查询,因此两条记录的select_type的取值都是SIMPLE。
EXPLAIN select * from source_learn inner join source_learn_param on source_learn.id = source_learn_param.source_id;
- 1

(2)PRIMARY、UNION、UNION RESULT
下面展示了查询语句中使用UNION关键字,其中语句最左边的是PRIMARY,其余的查询是UNION,UNION RESULT表示的是对于UNION的语句处理使用了临时表进行了去重处理。
EXPLAIN select data_type from source_learn UNION select data_type from source_learn_param;
- 1

下面展示了查询语句中使用了UNION ALL关键字执行计划详情
UNION ALL不会进行去重处理,因此没有产生临时表。
EXPLAIN select data_type from source_learn UNION ALL select data_type from source_learn_param;
- 1

(5)SUBQUERY
下面展示了查询语句在字段中使用了子查询操作,在左边的查询语句的的select_type为PRIMARY。剩下的一个查询语句查询优化器并为对其优化成连接查询的形式,并且改查询语句为非相关子查询,因此select_type为SUBQUERY。
EXPLAIN select source_learn.data_type, (select DISTINCT(source_id) from source_learn_param where source_learn_param.id = 1) as key_source_id from source_learn;
- 1

(6)DEPENDENT SUBQUERY
下面展示的是相关子查询查询计划记录的select_type的取值为DEPENDENT SUBQUERY。
- where条件后面的相关子查询语句
EXPLAIN select source_learn.data_type from source_learn where source_learn.id in (select source_id from table_test_learn) or source_learn.data_type = "oracle";
- 1

- 字段为相关子查询的语句
EXPLAIN select source_learn.data_type, (select DISTINCT(source_id) from source_learn_param where source_learn_param.data_type = source_learn.data_type) as key_source_id from source_learn;
- 1

(7)DEPENDENT UNION
在存在UNION的查询语句中如果各个子查询语句间存在依赖关系,者除了第一个记录的select_type为PRIMARY,其他的子查询语句记录中的select_type为DEPENDENT UNION
EXPLAIN select * from source_learn where id in (select source_id from source_learn_param where data_type = "oracle" UNION select id from source_learn where name='oracle_source')
- 1

(8)DERIVED
(9)MATERIALIZED
下面的查询语句展示了表table_test_learn子查询物化后参与连接查询。
EXPLAIN (select data_type from source_learn where source_learn.id in (select source_id from table_test_learn)) UNION ALL select data_type from source_learn_param;
- 1

3、table
无论我们写的SQL语句有多复杂,最终都会对单个表进行查询操作,查询计划会为每个表生成一条记录,记录中的table列就表示表的名字。
4、paritions
这个属性是有关分区表的相关查询操作,还未遇到过占不讨论,遇到了再做补充。
5、type
该属性表示查询计划对某个表的查询方式,其有如下取值:
| 取值 | 说明 |
|---|---|
| system | 当表的存储引擎为MyISAM、MEMROY并且表中仅有一条记录,那么type的取值就是system |
| const | 执行单表查询时,使用主键或者唯一二级索引与常量进行等值匹配查询时,此时type的取值就是const |
| eq_ref | 执行连接查询时,被驱动的表使用的是主键或不为null的唯一二级索引进行等值匹配查询时,被驱动表的type的取值就是eq_ref |
| ref | (1)执行单表使用普通的二级索引进行常量等匹配;(2)执行连接查询,被驱动表中的普通二级索引与驱动表的某个列进行等值匹配 |
| fulltext | |
| ref_or_null | |
| index_merge | |
| unique_subquery | |
| index_subquery | |
| range | 使用索引来进行范围查询 |
| index | 扫描所有的索引记录 |
| ALL | 表示全表扫描 |
(1)system
创建存储引擎为MyISAM的表:
create table table_test(id int) Engine=MyISAM;
- 1
执行如下EXPLAIN
explain select * from table_test;
- 1
当表中没有数据时的执行计划:

当表中插入一条记录时type的取值为system,执行计划如下:

当表中插入多条记录时type的取值为ALL,执行计划如下:

(2)const
对于单表的查询使用主键与常量进行等值匹配筛选,此时的type的取值就是const
explain select * from source_learn where id = 1;
- 1

(3)eq_ref
下面执行的查询语句,被驱动表使用的是主键进行等值匹配查询,此时被驱动表的type取值就是eq_ref。
explain select * from source_learn_param inner join source_learn on source_learn.id = source_learn_param.source_id;
- 1

(4)ref
执行单表使用普通的二级索引进行常量等匹配,此时type的取值为ref
explain select * from source_learn_param where source_id = 1;
- 1

执行连接查询,被驱动表中的普通二级索引与驱动表的某个列进行等值匹配,此时type的取值为ref
explain select * from source_learn inner join source_learn_param on source_learn_param.source_id = source_learn.id;
- 1

(5)fulltext
暂时没碰到过,碰到了在做补充说明。
(6)ref_or_null
(7)index_merge
(8)unique_subquery
(9)index_subquery
(10)range
下面的查询语句使用了普通索引来进行范围查询,type的取值为range
explain select * from source_learn_param where source_id > 3;
- 1

explain select * from source_learn_param where id > 3;
- 1

(11)index
EXPLAIN select source_learn.data_type, (select DISTINCT(source_id) from source_learn_param where source_learn_param.data_type = source_learn.data_type) as key_source_id from source_learn;
- 1

6、possible_keys
对某查询语句进行查询时可能使用到那些索引
7、key
对于某查询语句实际上使用到的索引
8、key_len
9、ref
显示了在key列记录的索引中,表查找值所用到的列或常量
10、rows
扫描出的行数,这个是个估算的值,并不是真正的结果集
11、filtered
filtered表示返回结果的行数占需读取行数的百分比,filtered列的值依赖于统计信息。


