
- 1CVPR2023:BiFormer阅读笔记
- 2【网络安全 --- xss-labs靶场通关(11-20关)】详细的xss-labs靶场通关思路及技巧讲解,让你对xss漏洞的理解更深刻_xss-labs全关详解
- 3聊聊 Kafka:编译 Kafka 源码并搭建源码环境,2024年最新关于小程序的毕业设计_打开卡夫卡环境代码
- 4SELinux深度解析:安全增强型Linux的探索与应用(上)
- 5色彩滤波阵列(Color Filter Array)
- 6Java | Leetcode Java题解之第132题分割回文串II
- 7【讯为Linux驱动开发】5.并发与竞争
- 8新书速览|Django 5 Web应用开发实战_django5 企业级web应用开发实战
- 9Ollama| 搭建本地大模型,最简单的方法!效果直逼GPT_ollama搭建
- 10python进行KNN算法分析实战(鸢尾花数据集)_python鸢尾花数据集分析
机器学习算法——k-近邻算法_k近邻算法
赞
踩
前言
K近邻算法是一种简单而有效的算法,它不需要对数据进行显式的训练,因此适用于小规模数据集和非线性问题。是学习和理解机器学习基础知识的重要算法之一,也可以作为其他机器学习算法的基准进行比较和评估。
一、k-近邻算法
1、介绍
k-近邻算法(k-Nearest Neighbour algorithm),又称为KNN算法。KNN的工作原理:给定一个已知标签类别的训练数据集,输入没有标签的新数据后,在训练数据集中找到与新数据最邻近的k个实例,如果这k个实例的多数属于某个类别,那么新数据就属于这个类别。
可以简单理解为:由那些离X最近的k个点来投票决定X归为哪一类。
下面我们通过一个简单的小例子来了解一下k-近邻算法:
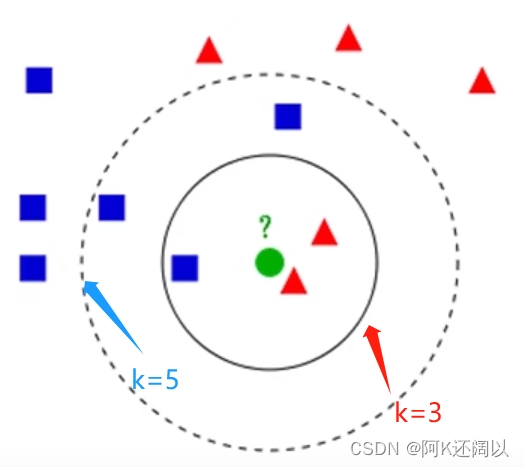
图1-1
图1-1是一个很基础的knn算法模型。有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的国所标示的数据则是待分类的数据。
问题:图中的绿色的圆属于哪一类?
如果K=3,绿色圆点的最近的3个邻居是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
如果K=5,绿色国点的最近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类。
2、距离公式
在实现k-近邻算法中,我们经常要算出未知类别与样本中其它已知类别的距离,将它们进行排序,然后根据k的取值来判断未知样本的类别。
距离公式有很多个,本篇博客着重使用欧式距离公式。
欧式距离公式(Euclidean Distance)
(1)、二维平面:
假设二维平面有两个点:
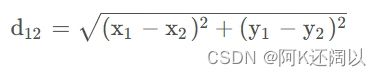
(2)、三维平面:
假设三维平面有两个店:
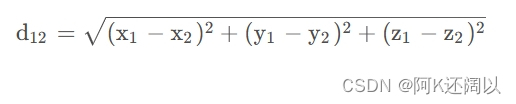
(3)、n维平面:
n维空间有两个点:
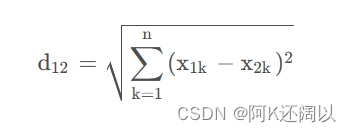
接下来通过一个小例子来使用距离公式解决问题:
| 电影名称 | 打斗镜头 | 接吻镜头 | 电影类型 |
|---|---|---|---|
| 泰坦尼克号 | 1 | 101 | 爱情片 |
| 后来的我们 | 5 | 89 | 爱情片 |
| 前任3 | 12 | 97 | 爱情片 |
| 战狼 | 112 | 9 | 动作片 |
| 战狼2 | 108 | 5 | 动作片 |
| 唐人街探案 | 115 | 8 | 动作片 |
| ? | 24 | 67 | ? |
我们将表中已有数据作为样本数据,打斗镜头和接吻镜头作为数据特征。我们用图像的方式显示出来:
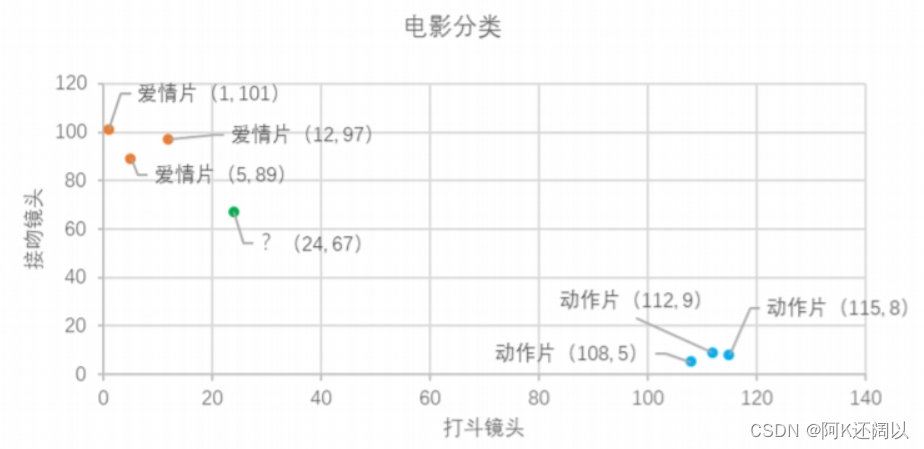
图1-2
现在我们计算未知电影与样本集中其它电影的距离,计算结果位于下面表格:
| 电影名称 | 与未知电影的距离 |
|---|---|
| 泰坦尼克号 | 20.5 |
| 后来的我们 | 18.7 |
| 前任3 | 19.8 |
| 战狼 | 115.3 |
| 战狼2 | 117.4 |
| 唐人街探案 | 118.9 |
现在我们得到了样本集中所有电影与位置电影的距离,按照距离递增排序,可以找到k个距离最近的电影。
比如说我们假定k=3,则最近的电影分别为:泰坦尼克号、后来的我们、前任3。因此未知电影属于爱情片。因此k的取值在k-近邻算法中是非常重要的,它间接影响到了未知样本类别的判断,所以我们对于k的取值一定要谨慎。
3、k-近邻算法的一般流程
流程:
(1)、收集数据:可以使用任何方法
(2)、准备数据:距离计算所需要的数值
(3)、分析数据:可以使用任何方法
(4)、训练算法:此步骤不适用于k-近邻算法
(5)、测试算法:计算错误率
(6)、使用算法:首先需要输入样本数据和结构化的输出结果,然后运行k-近邻算法判定输入的数据分别属于哪个分类,最后应用对计算出的分类执行后续的处理。
二、k-近邻算法案例——医用判断良性恶性肿瘤
接下来我们通过一个简单案例来深入学习k-近邻算法
问题背景
医学上判断肿瘤需要通过radius (半径), texture(纹理), perimeter(周长), area(面积), smoothness(光滑度), symmetry(对称性), compactness(紧凑度), fractal_dimension(分形维度)等数据来判断肿瘤是否为恶性,现在有一组数据,请用knn方法来进行分析肿瘤的良性恶性(良性肿瘤用“B”,恶性肿瘤用“M”表示)
数据展示
| id | diagnosis_result | radius | texture | perimeter | area | smoothness | compactness | symmetry | fractal_dimension |
| 1 | M | 23 | 12 | 151 | 954 | 0.143 | 0.278 | 0.242 | 0.079 |
| 2 | B | 9 | 13 | 133 | 1326 | 0.143 | 0.079 | 0.181 | 0.057 |
| 3 | M | 21 | 27 | 130 | 1203 | 0.125 | 0.16 | 0.207 | 0.06 |
| 4 | M | 14 | 16 | 78 | 386 | 0.07 | 0.284 | 0.26 | 0.097 |
数据处理
- # 读取csv文件,将每行数据存储为一个字典,并将所有字典存储到列表中
- with open('Prostate_Cancer.csv') as file:
- reader = csv.DictReader(file)
- datas = [row for row in reader]
-
- # 对数据进行随机排序
- random.shuffle(datas)
-
- # 选取1/3的数据作为测试集,其余作为训练集
- n = len(datas)//3
- test_set = datas[0:n]
- train_set = datas[n:]
计算距离
- # 返回两个数据点之间的欧几里得距离
- def distance(d1,d2):
- res = 0
- for key in ("radius","texture","perimeter","area",
- "smoothness","compactness","symmetry","fractal_dimension"):
- res += (float(d1[key])-float(d2[key])) ** 2
- return res ** 0.5
knn分类器实现
- # 设定k值
- k = 4
-
- # KNN分类器
- def knn(data):
- # 计算测试数据和每个训练数据之间的距离,并将结果存储到一个列表中
- res = [
- {"result":train["diagnosis_result"],"distance":distance(data,train)}
- for train in train_set
- ]
-
- # 将结果按照距离从小到大排序
- res = sorted(res, key=lambda item:item['distance'])
- # 取前K个距离最近的数据
- res2 = res[0:k]
- # 加权平均,将离测试数据更近的数据点所属类别的贡献权重更高
- result = {'B':0,'M':0}
- # 计算所有数据点到测试数据的距离之和
- sum_dist = 0
- for r1 in res2:
- sum_dist += r1['distance']
-
- # 逐个分类累加贡献权重(结果为'B'或'M')
- for r2 in res2:
- result[r2["result"]] += 1-r2["distance"]/sum_dist
-
- if result['B'] > result['M']:
- return 'B'
- else:
- return 'M'

测试集预测
- # 求正确率
- correct = 0
- for test in test_set:
- result = test['diagnosis_result']
- result2 = knn(test)
- # 如果预测结果正确,计数器加1
- if result == result2:
- correct = correct + 1;
-
- print("正确率为:" + str(correct/len(test_set)))
预测结果

图2-1
多次改变k值可以发现,k取5的时候正确率最高。
完整代码
- import csv
- import random
-
- # 读取csv文件,将每行数据存储为一个字典,并将所有字典存储到列表中
- with open('Prostate_Cancer.csv') as file:
- reader = csv.DictReader(file)
- datas = [row for row in reader]
-
- # 对数据进行随机排序
- random.shuffle(datas)
-
- # 选取1/3的数据作为测试集,其余作为训练集
- n = len(datas)//3
- test_set = datas[0:n]
- train_set = datas[n:]
-
- # 返回两个数据点之间的欧几里得距离
- def distance(d1,d2):
- res = 0
- for key in ("radius","texture","perimeter","area",
- "smoothness","compactness","symmetry","fractal_dimension"):
- res += (float(d1[key])-float(d2[key])) ** 2
- return res ** 0.5
-
- # 设定k值
- k = 5
-
- # KNN分类器
- def knn(data):
- # 计算测试数据和每个训练数据之间的距离,并将结果存储到一个列表中
- res = [
- {"result":train["diagnosis_result"],"distance":distance(data,train)}
- for train in train_set
- ]
-
- # 将结果按照距离从小到大排序
- res = sorted(res, key=lambda item:item['distance'])
- # 取前K个距离最近的数据
- res2 = res[0:k]
- # 加权平均,将离测试数据更近的数据点所属类别的贡献权重更高
- result = {'B':0,'M':0}
- # 计算所有数据点到测试数据的距离之和
- sum_dist = 0
- for r1 in res2:
- sum_dist += r1['distance']
-
- # 逐个分类累加贡献权重(结果为'B'或'M')
- for r2 in res2:
- result[r2["result"]] += 1-r2["distance"]/sum_dist
-
- if result['B'] > result['M']:
- return 'B'
- else:
- return 'M'
-
- # 求正确率
- correct = 0
- for test in test_set:
- result = test['diagnosis_result']
- result2 = knn(test)
- # 如果预测结果正确,计数器加1
- if result == result2:
- correct = correct + 1;
-
- print("正确率为:" + str(correct/len(test_set)))
三、总结
KNN算法是一种简单但有效的分类算法,尤其适用于样本数据不平衡、数据分布不规则的情况。它为初学者提供了一个很好的入门点,并且在一些小规模的问题中具有良好的效果。对于分类问题,通过投票的方式确定待分类样本所属的类别;对于回归问题,采用平均值等方法来预测待分类样本的数值。K近邻算法的优点在于简单易懂,且对于非线性、非参数化模型适用。但是它的缺点是需要大量的计算和存储空间,在处理高维度数据时效果较差,并且对于样本分布不均匀及噪声比较大的数据集容易受到干扰,因此在使用过程中需要多加注意。

