
热门标签
热门文章
- 1git : 无法将“git”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。请检查名称的拼写,如果包括路径,请确保路径正确, 然后再试一次。
- 2史上最详细的Python安装教程,小白建议收藏!_安装python教程
- 3云计算与企业IT成本治理
- 4如何在mac中安装Visual Studio Code并搭建dart,Flutter环境_苹果电脑下载visual studio code
- 5Linux | 调试器GDB的详细教程【纯命令行调试】_linux gdb 调试教程
- 6vscode 配置 python3开发环境_vscode python
- 7【Java】【JDK】使用JDK自带的mail API实现邮件发送_java 邮件接口
- 8FastChat启动与部署通义千问大模型_fastchat封装千问模型
- 9专项技能训练五《云计算网络技术与应用》实训9 使用openVPN建立小型企业内网VPN环境
- 10深度学习与多模态数据融合:实践指南
当前位置: article > 正文
Hive笔记-6
作者:盐析白兔 | 2024-06-30 11:00:47
赞
踩
Hive笔记-6
6.2.8 聚合函数
1) 语法
-
count(*),表示统计所有行数,包含null值;
-
count(某列),表示该列一共有多少行,不包含null值;
-
max(),求最大值,不包含null,除非所有值都是null;
-
min(),求最小值,不包含null,除非所有值都是null;
-
sum(),求和,不包含null。
-
avg(),求平均值,不包含null。
2) 案例实操
(1) 求总行数 (count)
hive (default)> select count(*) cnt from emp;hive sql执行过程:


count不仅可以传一个 * 还可以传一个(字段)

null 值是不统计在内

null 值是不会被统计在内的
(2) 求工资的最大值 (max)
hive (default)> select max(sal) max_sal from emp;hive sql执行过程:

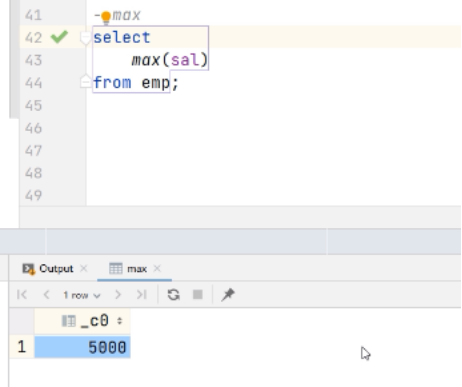
(3) 求工资的最小值 (min)
hive (default)> select min(sal) min_sal from emp;hive sql执行过程:

(4) 求工资的总和 (sum)
hive (default)> select sum(sal) sum_sal from emp; hive sql执行过程:


(5) 求工资的平均值 (avg)
hive (default)> select avg(sal) avg_sal from emp;hive sql执行过程:


6.3 分组
6.3.1 Group By 语句
Group By语句通常会和聚合函数一起使用,按照一个或者多个列队结果进行分组,然后对每个组执行聚合操作。
1) 案例实操:
把job分组后查看
select count(*) from emp group by job
结果:

看起来有点不太对劲,再改一下:
在count(*)前面加个job

现在看的清楚多了
注意:

注意: 当你 group by job 的时候,
那你只能select 后面跟 job 不能是其他的字段
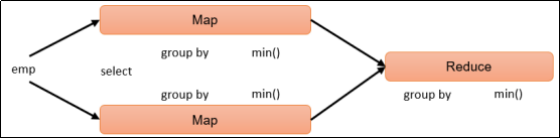
(1) 计算emp表每个部门的平均工资
- hive (default)>
- select
- t.deptno,
- avg(t.sal) avg_sal
- from emp t
- group by t.deptno;
hive sql执行过程:

(2)计算emp每个部门中每个岗位的最高薪水。
- hive (default)>
- select
- t.deptno,
- t.job,
- max(t.sal) max_sal
- from emp t
- group by t.deptno, t.job;
hive sql执行过程:
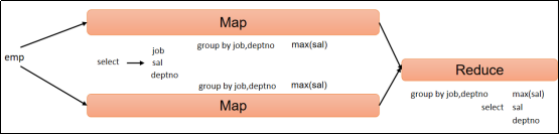
6.3.2 Having 语句
1) having 与 where 不同点
(1) where 后面不能写分组聚合函数,而having后面可以使用分组聚合函数
(2) having 只用于 group by 分组统计语句
2) 案例实操
找这张表里人数大于等于2的:

输入代码:

得到输出结果:

但是当我不想要嵌套子查询时:

可见where字句行不通
因为where是用来过滤一行一行的数据
而已经group by 分组过了,where不能过滤组
于是我们只能用having来过滤一组一组的数据
那我们就用having:

(1) 求每个部门的平均薪水大于2000的部门
1.求每个部门的平均工资
- hive (default)>
- select
- deptno,
- avg(sal)
- from emp
- group by deptno;
hive sql执行过程:

2.求每个部门的平均薪水大于2000的部门
- hive (default)>
- select
- deptno,
- avg(sal) avg_sal
- from emp
- group by deptno
- having avg_sal > 2000;
hive sql执行过程:

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/772455
推荐阅读
相关标签

