
- 1探秘便携式软件无线电:PortaPack-HackRF
- 2机器学习入门(11)——聚类(Clustering)_聚类中心
- 3c++入门学习⑨——STL(万字总结,超级超级详细版)看完这一篇就够了!!!
- 4使用变更数据捕获方法通过提取-转换-加载过程实时更新数据仓库_数据捕捉提取转换加载
- 5聊聊Nodejs中的核心模块:stream流模块(看看如何使用)_nodejs stream
- 6图神经网络(二十七)GeniePath: Graph Neural Networks with Adaptive Receptive Paths_graph neural networks with adaptive readouts
- 7Android Studio 中创建Flutter Project及环境配置(Mac环境)_mac android studio 创建flutter 工程 不能选择运行平台
- 8Scrapy入门、当当网商品爬取实战_dangdang.promotion.get
- 9python中的哈希_Python中hash的问题
- 10Python + requests实现接口自动化框架!_python requests 接口自动化_requests.reques接口自动化
【Spark SQL】4、Spark SQL的安装及简单使用_spark sql 安装
赞
踩
Spark
MapReduce的局限性:
- 代码繁琐
- 只能够支持map和reduce方法
- 执行效率低下
- 不适合迭代多次,交互式、流式的处理
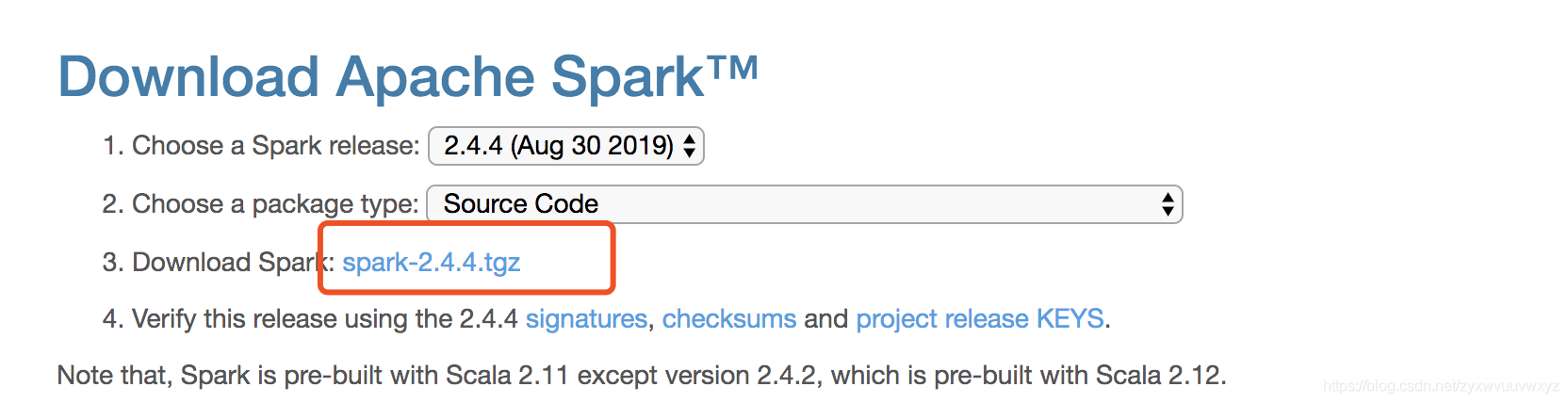
选择package type为Source Code,随后下载spark-2.4.4.tgz
为了与学习一致,这里选择spark-2.1.0,故需要maven3.3.9及以上版本,java7及以上版本
注意:这里之所以选择手动编译源码的方式,是想跟前文中使用到的hadoop、hive等环境配套,如果不需要使用hadoop相关技术,可忽略下面的编译,可直接选择一个tgz包下载即可
提供了两种编译源码的方式
build/mvn
spark自带的一个maven,可以用来编译
make-distribution.sh的方式
要创建类似于Spark下载页面所分发的Spark发行版,并将其布局为可运行,请在项目根目录中使用./dev/make-distribution.sh
如果想在编译spark时,启动hive、yarn等配置,可选参数-P指定;可以指定要通过Hadoop编译的版本。
启用哪些配置 可以参看make-distribution.sh中profiles指定的。如
cd ~/app/spark-2.1.0
./dev/make-distribution.sh --name 2.6.0-cdh5.7.0 --tgz -Pyarn -Phadoop-2.6 -Phive -Phive-thriftserver -Dhadoop.version=2.6.0-cdh5.7.0
## 这里指定了编译成功后的名称,hadoop的版本号 以及启用哪些profile
- 1
- 2
- 3
编译前准备(我选用的版本):
- Scala-2.11.8
- jdk 1.8.0_221
- maven 3.3.9
- spark-2.1.0
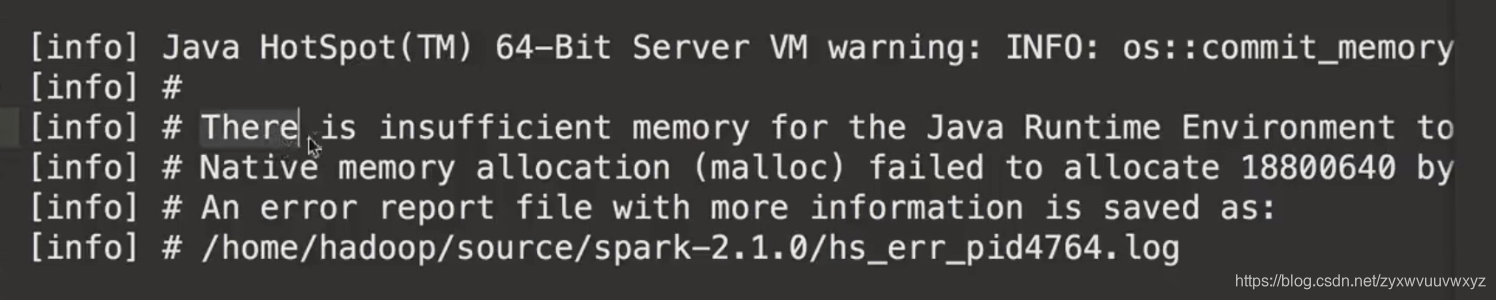
您需要通过设置MAVEN_OPTS将Maven配置为比通常使用更多的内存:
export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=512m"
- 1
ReservedCodeCacheSize设置是可选的,但推荐使用。)如果不将这些参数添加到MAVEN_OPTS,您可能会看到如下错误和警告:
[INFO] Compiling 203 Scala sources and 9 Java sources to /Users/me/Development/spark/core/target/scala-2.12/classes... [ERROR] Java heap space -> [Help 1]
- 1
- 2
编译命令(spark-2.1.0目录下):
# 指定scala版本
./dev/change-scala-version.sh 2.11
./dev/make-distribution.sh --name 2.6.0-cdh5.7.0 --tgz -Pyarn -Phadoop-2.6 -Phive -Phive-thriftserver -Dhadoop.version=2.6.0-cdh5.7.0
- 1
- 2
- 3
- 4
常见问题与解决
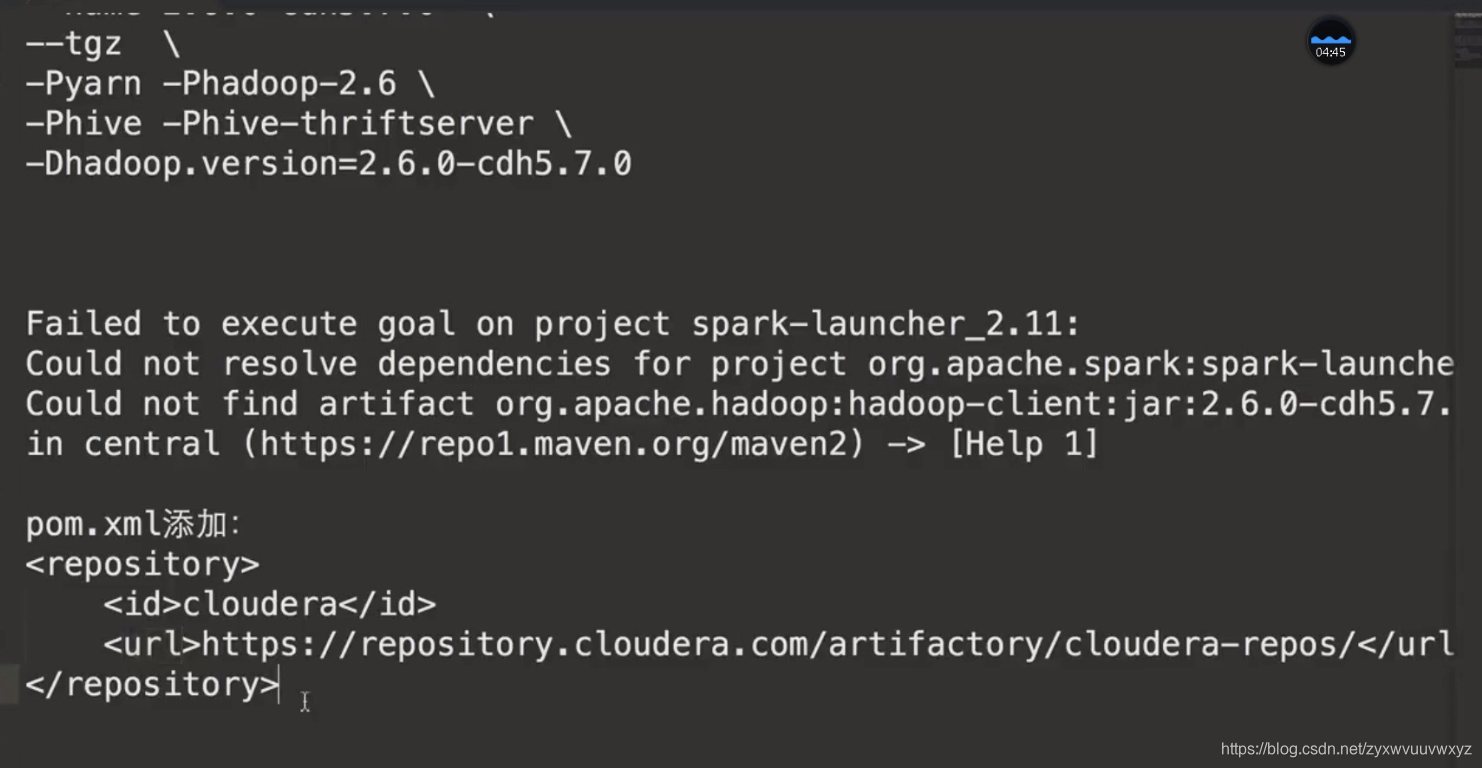
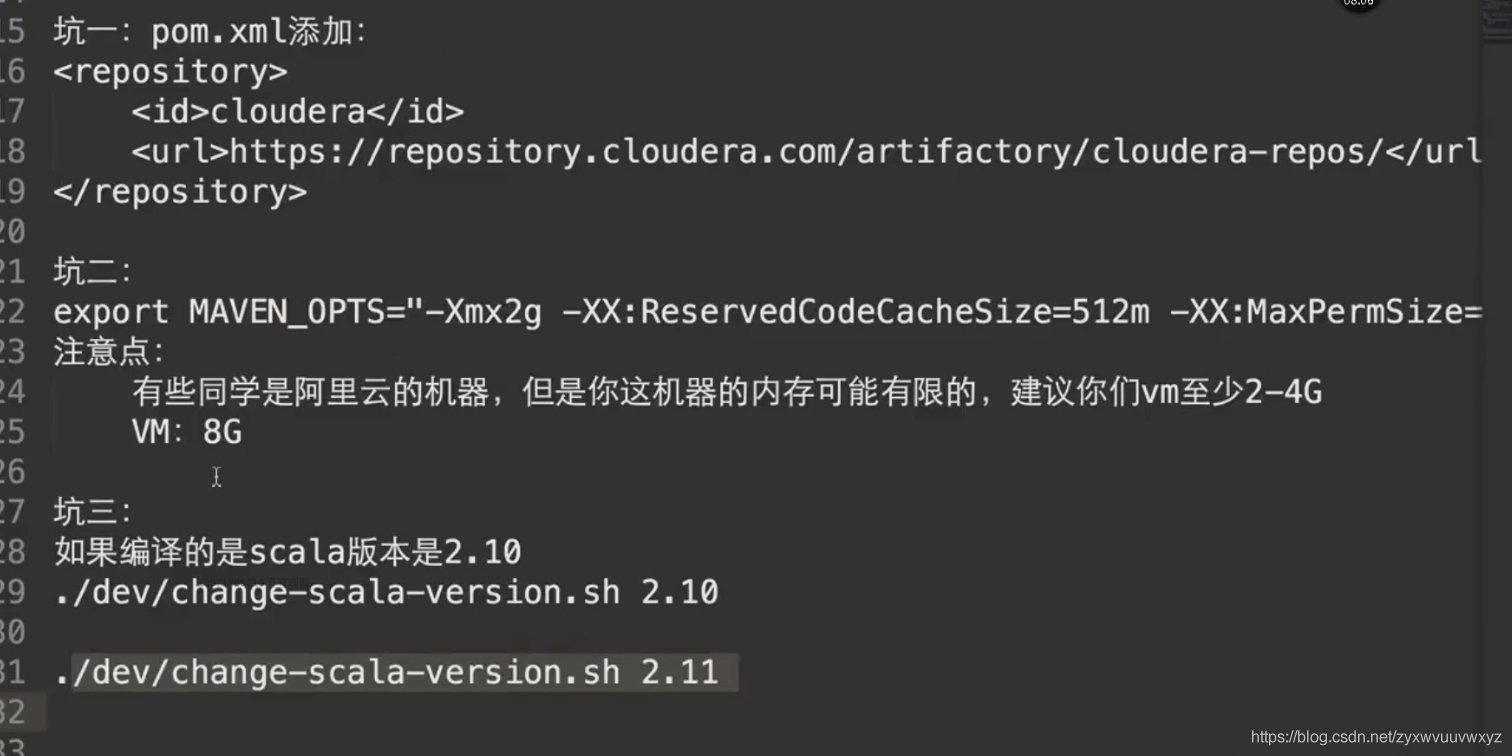

如果在编译过程中,看到的异常信息不是太明显、看不太懂,编译命令后 -X就能看到更详细的编译信息,如下
net.alchim31.maven:scala-maven-plugins:3.2.2:compile failed报错点击这里
引入依赖:
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
- 1
- 2
- 3
- 4
编译了很多次,出现很多次问题,但尤以net.alchim31.maven:scala-maven-plugins:3.2.2:compile failed错误最多,可参看上面的链接来处理。总之环境、版本就是上面陈述的,并未有其他的操作,编译错了就多编几次
Spark简单实用
-
local模式 直接把编译包解压开
验证是否搭建成功
spark-shell --master local[2] 其中2表示2个线程
-
Standalone模式
Spark Standalone模式的架构和Hadoop HDFS/YARN很类似的
1 master + n worker
vi spark-env.sh ## 添加 SPARK_MASTER_HOST=hadoop001 SPARK_WORKER_CORES=2 SPARK_WORKER_MEMORY=2g SPARK_WORKER_INSTANCE=1- 1
- 2
- 3
- 4
- 5
- 6
在./sbin下执行./satrt-all.sh即启动集群。
问题一:localhost:JAVA_HOME not set 导致worker启动失败
解决方式:在spark-env.sh中添加JAVA_HOME=/home/hadoop/app/jdk1.8.0_221。重新启动即可
启动Application:
./spark-shell --master spark://hadoop001:7077
Spark SQL
Spark1.x中Spark SQL的入口点:SQLContext
val sc:SparkContext val sqlContext=new org.apache.spark.sql.SQLContext(sc) //创建相应的Context val sparkConf=new SparkConf() //在测试或者生产中,AppName和Master我们是通过脚本进行指定 sparkConf.setAppName("SQLContextApp").setMaster("local[2]") val sc=new SparkContext(sparkConf) val sqlContext=new SQLContext(sc) //2)相关的处理:json val people=sqlContext.read.format("json").load(path) people.printSchema() people.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
spark-submit脚本负责使用Spark及其依赖项设置类路径,并可以支持不同的集群管理器和部署Spark支持的模式
./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
–class 应用程序的入口点(例如:org.apache.spark.examples.SparkPi)
–master 集群的master url(例如:spark://localhost:7077)
–deploy-mode 是将驱动程序部署在工作节点(群集)上还是作为外部客户端(客户端)本地部署(默认:客户端)有两个值:cluster/client
–conf 键=值格式的任意Spark配置属性。对于包含空格的值,将“ key = value”用引号引起来(
application-arguments:传递给主类主方法的参数(如果有)
./bin/spark-submit \
--name SparkSQLApp \
--class com.wojiushiwo.App \
--master local[2] \
/home/hadoop/lib/spark-1.0.jar \
/home/hadoop/app/data/people.json
##一般 是将上述脚本放到shell里
- 1
- 2
- 3
- 4
- 5
- 6
- 7
HiveContext的使用
要使用HiveContext,不需要现有的Hive环境,只需要hive-site.xml
<!--多引入一个依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.1.0</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
object HiveContextApp{
val sparkConf=new SparkConf()
sparkConf.setAppName("HiveContextApp").setMaster("local[2]")
val sc=new SparkContext(sparkConf)
val hiveContext=new HiveContext(sc)
//读表
hiveContext.table("emp").show()
sc.stop
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
./bin/spark-submit \
--name HiveContextApp \
--class com.wojiushiwo.App \
--master local[2] \
## 如果报驱动问题 将下面这个指定合适的驱动包
--jars /home/hadoop/software/mysql-connector-java-5.1.38.jar
/home/hadoop/lib/spark-1.0.jar
- 1
- 2
- 3
- 4
- 5
- 6
- 7
SparkSession的使用
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
- 1
- 2
- 3
- 4
- 5
Spark-shell、Spark-sql的使用
要在spark-shell中使用内嵌的spark对象查询hive表数据,需要将hive-site.xml复制到spark/conf/
cp hive-1.1.0-cdh5.7.0/conf/hive-site.xml spark-2.1.0-bin-2.6.0-cdh5.7.0/conf/
- 1
复制完成之后,启动./spark-shell,报错如下:
org.datanucleus.exceptions.NucleusException: Attempt to invoke the “BONECP” plugin to create a ConnectionPool gave an error : The specified datastore driver (“com.mysql.jdbc.Driver”) was not found in the CLASSPATH. Please check your CLASSPATH specification, and the name of the driver.
遇到这种情况,只需要将mysql驱动 放到spark-shell启动参数中,如下
./spark-shell \
--master local[2] \
--jars /home/hadoop/software/mysql-connector-java-5.1.38.jar
- 1
- 2
- 3
## Spark Session/Spark context可以直接使用
spark.sql("show databases").show()
spark.sql("select * from people").show()
+---+----+-------------------+--------------------+
| id|name| likes| addr|
+---+----+-------------------+--------------------+
| 1| zs|[game, gril, money]|Map(stuAddr -> ch...|
| 2| ls|[game, gril, money]|Map(stuAddr -> ch...|
+---+----+-------------------+--------------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
使用spark-sql
#启动
./bin/spark-sql \
--master local[2] \
--jar /home/hadoop/software/mysql-connector-java-5.1.38.jar
- 1
- 2
- 3
- 4
## 直接运行
show database;
select * from people;
1 zs ["game","gril","money"] {"stuAddr":"changsha","workAddr":"beijing"}
2 ls ["game","gril","money"] {"stuAddr":"changsha","workAddr":"beijing"}
- 1
- 2
- 3
- 4
- 5
- 6
thriftserver的使用
## 启动thriftserver服务
cd /home/hadoop/app/spark-2.1.0-bin-cdh5.7.0
./start-thriftserver.sh --master local[2] --jars /home/hadoop/software/mysql-connector-java-5.1.38.jar
- 1
- 2
- 3
前置:启动hadoop,因为数据仓库hive的数据是存储在hdfs上的。
##使用beeline去连接thriftserver
##thriftserver默认启动端口10000
##Beeline会要求您提供用户名和密码。在非安全模式下,只需在计算机上输入用户名和空白密码
beeline>!connect -u jdbc:hive2://ip:端口(这里是10000) -n 用户名(此时登录Linux的用户名)
## 如
!connect -u jdbc:hive2://localhost:10000 -n hadoop
## 连接成功去查询
jdbc:hive2://localhost:10000> select * from people;
+-----+-------+--------------------------+----------------------------------------------+--+
| id | name | likes | addr |
+-----+-------+--------------------------+----------------------------------------------+--+
| 1 | zs | ["game","gril","money"] | {"stuAddr":"changsha","workAddr":"beijing"} |
| 2 | ls | ["game","gril","money"] | {"stuAddr":"changsha","workAddr":"beijing"} |
+-----+-------+--------------------------+----------------------------------------------+--+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
如果想要改变thriftserver的端口号只需要在启动thriftserver时指定端口号
./sbin/start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=14000 \
--master local[2] \
--jars mysql-xx.jar
- 1
- 2
- 3
- 4
使用jdbc编程方式访问thriftserver服务
必须确保thriftserver服务是启动的
object JdbcThriftserverDemo { def main(args: Array[String]): Unit = { val url:String="jdbc:hive2://192.168.7.16:10000" val name:String="hadoop" Class.forName("org.apache.hive.jdbc.HiveDriver") val connection = DriverManager.getConnection(url,name,"") val preparedStatement = connection.prepareStatement("select id,name from people") val resultSet = preparedStatement.executeQuery() while(resultSet.next()){ println(resultSet.getInt("id")+","+resultSet.getString("name")) } resultSet.close() preparedStatement.close() connection.close() } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25

