
- 1【大模型系列】图文对齐(CLIP/TinyCLIP/GLIP)_微软 glip
- 2Python XML解析
- 3短语,直接短语,素短语与最左素短语(语法树求法)
- 4【LeetCode】动态规划 刷题训练(五)
- 5Maven settings.xml配置指定本地仓库_maven settings配置本地仓库
- 6python列表 sort和sorted的区别_python sorto
- 7Swift 周报 第四十五期_本期是 swift 编辑组整理周报的第四十五期,每个模块已初步成型。各位读者如果有好
- 8Gitlab介绍及使用_gitlab-rails关闭插件
- 9华为云RDS全量备份恢复到自建数据库(数据库qp文件恢复)_华为云rds 全量下载 如何本地还原
- 10机器学习-密度聚类算法(DBSCAN)_数据密度算法
R语言学习丨数据重塑、拆分与组合基础知识,merge、melt、cast函数介绍_r语言cast函数
赞
踩
今天学习R语言中数据重塑相关基础知识,主要有merge、melt、cast函数用法示例。公众号:生信分析笔记
合并数据框
merge()函数能够以一列为参考合并两个不同数据框,相当于数学中的布尔运算“交集、并集、反补集”,没有的元素定为NA,语法格式如下:
merge(x, y, #数据框
by = intersect(names(x), names(y)), #制定匹配列名称
by.x = by, by.y = by, #指定两个数据框中匹配列名称,默认情况下使用两个数据框中相同列名称。
all = FALSE, #默认取交集,若TRUE则为并集
all.x = all, #取x的全集和交集
all.y = all, #取y的全集和交集
sort = TRUE, #排序,默认打开
suffixes = c(".x",".y"), #后缀,当合并后的x,y矩阵有相同的列名时,使用后缀表明出处,默认后缀为.x, .y
no.dups = TRUE, #是否将上一个参数扩展到更多情况下,以避免出现重复的列名
incomparables = NULL, …)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
by.x和by.y是用来告诉merge函数取出x(第一个数据框)的by.x列和y(第二个数据框)的by.y列中具有相同取值的行进行合并,其他的丢掉,另外如果指定了其中一个,那么另一个就必须同时指定,不然就报错。
老规矩,接下来演示:
> #合并两个不同内容的数据框,交并补三种方式。
> df1 <- data.frame(id = c(1:4),name = c("jack","jeson","lucky","poler"))
> df2 <- data.frame(id = c(2,4,6),home = c("zhong","han","mei"))
- 1
- 2
- 3
上面咱已经建立了俩数据框,df1有4个ID,每个id对应4个名字,共4行。
> # 生成两个数据框,行数不一样,但有重叠区域
> df3 <- merge(x = df1,y = df2,by = "id")
> #以id列为准进行合并,两个数据框中只有序号2、4同时存在,默认取交集。
> print(df3)
id name home
1 2 jeson zhong
2 4 poler han
- 1
- 2
- 3
- 4
- 5
- 6
- 7
通过id为准来合并两个数据框,其中df1中id的2和4在df2中也存在,属于两者共同交集,因此输出的只有这俩。
> df4 <- merge(x=df1,y=df2,by="id",all=TRUE)
> #输出两个数据框的并集
> print(df4)
id name home
1 1 jack <NA>
2 2 jeson zhong
3 3 lucky <NA>
4 4 poler han
5 6 <NA> mei
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
添加了all=TRUE,表示全部合并,取并集,没有元素用NA,共6条结果。
> df5 <- merge(x=df1,y=df2,by="id",all.x=TRUE)
> #输出(df1的全部)和(df1与df2的交集)
> print(df5)
id name home
1 1 jack <NA>
2 2 jeson zhong
3 3 lucky <NA>
4 4 poler han
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
all.x表示左边数据框的全部数据都保留,下面同理输出右边数据框的全部。
> df6 <- merge(x=df1,y=df2,by="id",all.y=TRUE)
> #输出(df2的全部)和(df1与df2的交集)
> print(df6)
id name home
1 2 jeson zhong
2 4 poler han
3 6 <NA> mei
- 1
- 2
- 3
- 4
- 5
- 6
- 7
为了更好的理解,用下图来说明,all参数控制合并时布尔运算逻辑。

数据整合拆分
R 语言使用 melt() 和 cast() 函数来对数据进行整合和拆分,该功能需要借助R包来完成,首先安装R包并载入:
install.packages("MASS", repos = "https://mirrors.ustc.edu.cn/CRAN/")
install.packages("reshape2", repos = "https://mirrors.ustc.edu.cn/CRAN/")
install.packages("reshape", repos = "https://mirrors.ustc.edu.cn/CRAN/")
library(MASS)
library(reshape2)
library(reshape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
melt和dcast函数都是来自于reshape2程序包的函数,melt的作用为将宽数据转化为长数据,而dcast的作用为将长数据转化为宽数据,二者互为“逆函数”。如下图:
melt()函数
英语中melt的意思是融化,咱们可以理解为将很多数据融化成具有一定规则的数据,方便后续分析。
数据分析时,采用的数据通常是宽数据,在进行图形绘制时,常常需要将多列放置在一列中,例如需要在同一张图中绘制出三个结局的时间序列,那么就需要将原来的三个结局变量转化为一个三分类变量的列,然后将这个三分类变量映射为点图的颜色或形状等图形属性,这样就实现了绘图的需求。
一般样本数据都有很多个不同的属性和值,列表会有好多列很宽,melt函数能够将列表由宽变窄,值被按顺序排成一列了。函数的语法格式:
melt(data, ..., #数据集
na.rm = FALSE, #是否删除数据中的NA
value.name = "value") #变量名称
- 1
- 2
- 3
接下来进行实例演示,创建一个数据框,数据有两列为标识,另外两列为值,用于后续操作。
> id<- c(1, 1, 2, 2)
> lei <- c(1, 2, 1, 2)
> x1 <- c(5, 3, 6, 2)
> x2 <- c(6, 5, 1, 4)
> data_1 <- data.frame(id,lei,x1,x2)
> print(data_1)
id lei x1 x2
1 1 1 5 6
2 1 2 3 5
3 2 1 6 1
4 2 2 2 4
> out_1 <- melt(data_1,id = c("id","lei"))
> print(out_1)
id lei variable value
1 1 1 x1 5
2 1 2 x1 3
3 2 1 x1 6
4 2 2 x1 2
5 1 1 x2 6
6 1 2 x2 5
7 2 1 x2 1
8 2 2 x2 4
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
由上面的结果可以看出melt函数的作用是将原本横着排列的列堆在一个列里,每一行只留下一个值。
cast()函数
cast() 函数用于对合并对数据框进行还原,dcast() 返回数据框,语法格式如下:
dcast(
data, #待处理的数据框
formula, #重塑的数据格式,x~y
fun.aggregate = NULL, #聚合函数
subset = NULL, #对结果进行筛选
drop = TRUE, #是否保留默认值
value.var = guess_value(data) #待处理的字段
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
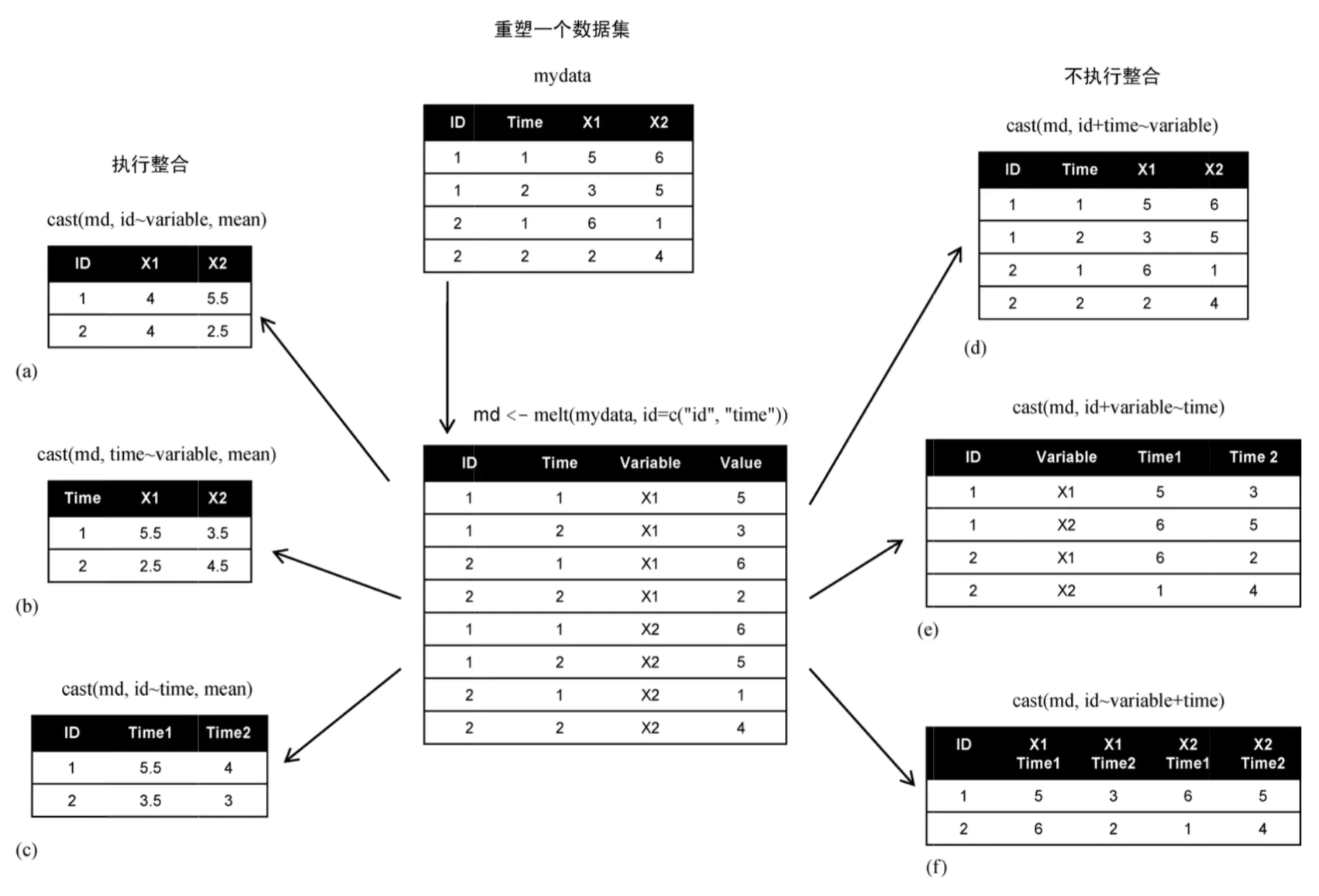
首先,创建一个数据框,并把它用melt函数整合。
> id<- c(1, 1, 2, 2)
> time <- c(1, 2, 1, 2)
> x1 <- c(5, 3, 6, 2)
> x2 <- c(6, 5, 1, 4)
> mydata <- data.frame(id, time, x1, x2)
> md <- melt(mydata, id = c("id","time"))
> print(md)
id time variable value
1 1 1 x1 5
2 1 2 x1 3
3 2 1 x1 6
4 2 2 x1 2
5 1 1 x2 6
6 1 2 x2 5
7 2 1 x2 1
8 2 2 x2 4
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
接下来,尝试用cast函数对其进行拆分。
> cast.data <- cast(md, id~variable, mean)
> print(cast.data)
id x1 x2
1 1 4 5.5
2 2 4 2.5
- 1
- 2
- 3
- 4
- 5
还可以尝试用不同的参数,以不同的方式进行拆分。~符号的前面表示列,后面表示值,用法有点类似Excel中数据透视表功能。
> time.cast <- cast(md, time~variable, mean)
#输出内容是不同time下variable的值
> print(time.cast)
time x1 x2
1 1 5.5 3.5
2 2 2.5 4.5
> id.time <- cast(md, id~time, mean)
#输出内容是不同id下time的值
> print(id.time)
id 1 2
1 1 5.5 4
2 2 3.5 3
> id.time.cast <- cast(md, id+time~variable)
#输出内容是不同id和不同time下variable的值
> print(id.time.cast)
id time x1 x2
1 1 1 5 6
2 1 2 3 5
3 2 1 6 1
4 2 2 2 4
> id.variable.time <- cast(md, id+variable~time)
# 输出内容是不同id和variable下time的值
> print(id.variable.time)
id variable 1 2
1 1 x1 5 3
2 1 x2 6 5
3 2 x1 6 2
4 2 x2 1 4
> id.variable.time2 <- cast(md, id~variable+time)
#输出内容是不同id下不同time和值
> print(id.variable.time2)
id x1_1 x1_2 x2_1 x2_2
1 1 5 3 6 5
2 2 6 2 1 4
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
参考资料:https://www.runoob.com/r
本文由mdnice多平台发布

