
- 1Android Gradle 引用本地 AAR 的几种方式
- 2车道线检测1. lanenet代码精读(记录)_lanenet ncnn
- 3git篇:仓库fork后怎么同步_gitlabfork后如何同步原仓库代码
- 4Kafka的使用(Windows中)_windows启动kafka
- 5SSM学习39:AOP通知类型:环绕通知
- 6【深度学习】OCR中的Shrink反向扩展
- 7基于opencv的人脸检测(图片、视频、摄像头)_opencv人脸检测
- 8SSM实现Excel的导入导出功能_ssm中如何把服务器的excel文件以输出流方式返回到前端
- 9ubuntu1804 安装 jdk10.0 tomcat 9.0 mysql 8.0_ubuntu1804 apt安装jdk
- 10Linux中Nginx的HTTP和HTTPS常用配置以及proxy_pass详解
GPT系列的总结以及GPT4
赞
踩
GPT系列是OpenAI的一系列预训练文章,GPT的全称是Generative Pre-Trained Transformer,顾名思义,GPT的目的就是通过Transformer为基础模型,使用预训练技术得到通用的文本模型。目前已经公布论文的有文本预训练GPT-1,GPT-2,GPT-3,以及图像预训练iGPT。 最近非常火的ChatGPT和今年年初公布的[1]是一对姐妹模型,是在GPT-4之前发布的预热模型,有时候也被叫做GPT3.5。ChatGPT和InstructGPT在模型结构,训练方式上都完全一致,即都使用了指示学习(Instruction Learning)和人工反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)来指导模型的训练,它们不同的仅仅是采集数据的方式上有所差异。
2023年3月27日,OpenAI 宣布发布其最新的大型语言模型 GPT-4。该模型是一个大型多模态模型(large multimodal model ),可以接受图像和文本输入并生成文本输出。GPT-4 标志着人工智能领域的一个重要里程碑,尤其是在自然语言处理领域。
历代GPT的发布时间,参数量以及训练量
| 模型 | 发布时间 | 层数 | 头数 | 词向量长度 | 参数量 | 预训练数据量 |
|---|---|---|---|---|---|---|
| GPT-1 | 2018 年 6 月 | 12 | 12 | 768 | 1.17 亿 | 约 5GB |
| GPT-2 | 2019 年 2 月 | 48 | - | 1600 | 15 亿 | 40GB |
| GPT-3 | 2020 年 5 月 | 96 | 96 | 12888 | 1,750 亿 | 45TB |
| InstructGPT | 2022 年 3 月 | - | - | - | 13亿 | - |
GPT之前
从 2017 年谷歌的 Transformer开始,当前的自然语言 AI 革命只有在 transformer 模型的发明后才有可能。在此之前,文本生成是通过其他深度学习模型进行的,例如递归神经网络 (RNN) 和长短期 记忆神经网络 (LSTM)。 这些在输出单个单词或短语方面表现良好,但无法生成逼真的较长内容。
2018 GPT-1

2018 年,OpenAI 发表了一篇论文(Improving Language Understanding by Generative Pre-Training),内容是使用他们的 GPT-1 语言模型进行自然语言理解。 该模型是概念验证,并未公开发布。
GPT 训练方法
以【单字接龙】的方式训练模型,训练的主要目的不是记忆而是学习,学习提问和回答的通用的规律。
学到效果就是即使是从没有记忆过的提问,也可以从所学的规律中生成用户所要的回答

聊到GPT1,就不得不提到2019年谷歌团队提出得BERT了。BERT 的变换器方法是一项重大突破,因为它不是一种监督学习技术。 也就是说,它不需要昂贵的注释数据集来训练它。 BERT 被谷歌用于解释自然语言搜索(interpreting natural language searches),但是,它不能从提示中生成文本(generate text from a prompt)。
BERT 于GPT1从模型的角度上对比:
- GPT是单向模型,无法利用上下文信息,只能利用上文;而BERT是双向模型。
- GPT是基于自回归模型,可以应用在NLU和NLG两大任务,而原生的BERT采用的基于自编码模型,只能完成NLU任务,无法直接应用在文本生成上面。
- 同等参数规模下,BERT的效果要好于GPT。
NLP有2个核心的任务:分别是【自然语言理解—NLU】和【自然语言生成—NLG】。
BERT, GPT 和ELMo模型结构之间比较

Transformer中Encode Self-attention的某层某个attention head的图

2019 GPT-2

次年,OpenAI 发表了另一篇关于他们最新模型 GPT-2 的论文(Language Models are Unsupervised Multitask Learners)。
GPT-2模型在具有数百万网页的WebText 的新数据集上训练的。模型参数是15亿。此模型证明了在无监督的学习也是可以学习到zero-shot任务的下游任务。并且在8个测试语言建模数据集中的7个上取得了好的的结果,但模型仍然在WebText数据集上表现出欠拟合。
2020 GPT-3
2020 年,OpenAI 发表了另一篇关于他们的 GPT-3 模型的论文(Language Models are Few-Shot Learners)。GPT-3 拥有 1750 亿个参数。 该模型的参数是 GPT-2 的 100 倍,并且在更大的文本数据集上进行训练,从而获得更好的模型性能。GPT-3展示了扩大语言模型极大地提高了与任务无关的、多样本(few-shot)的性能,有时甚至可以与先前最先进的微调方法竞争。GPT-3在大多数语言任务中,不需要大型监督数据集来学习,只需要在推理的过程中提供少量的示例。在许多 NLP 数据集上实现了强大的性能,包括翻译、问答和完形填空任务,以及一些需要即时推理或领域适应的任务,例如解读单词,在 句子,或执行 3 位数算术。在所有的这些任务里,GPT-3没有任何梯度更新或微调,只给模型提供任务本身和多个示例(few-shot)。
论文中提到了Meta-learning,下图中Inner loop和outer loop一起就是元学习。In-context learning实在序列的推理中学习的。
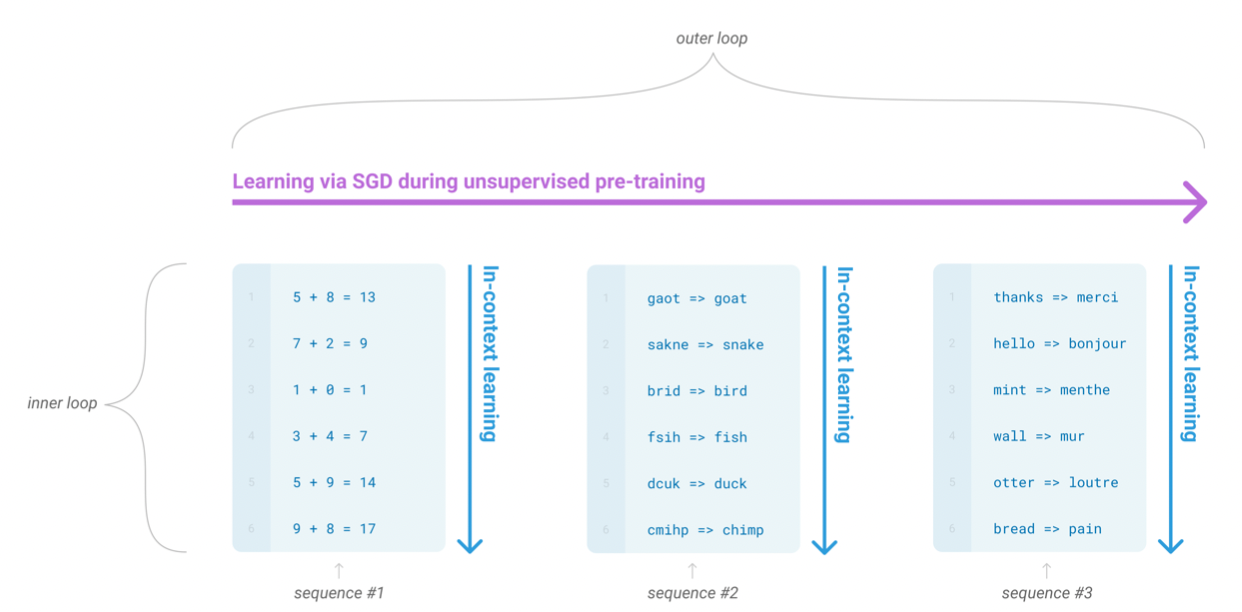
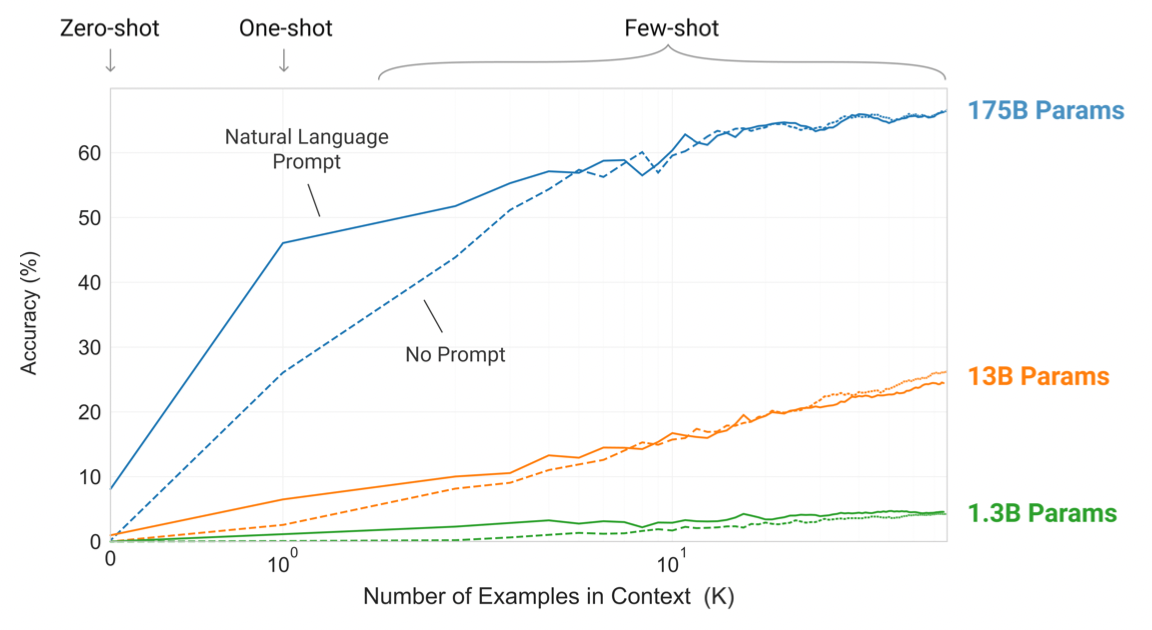
论文中也提到了多个示例效果比一个示例效果好,一个示例比没有示例要好。一般示例提供的越多越好。
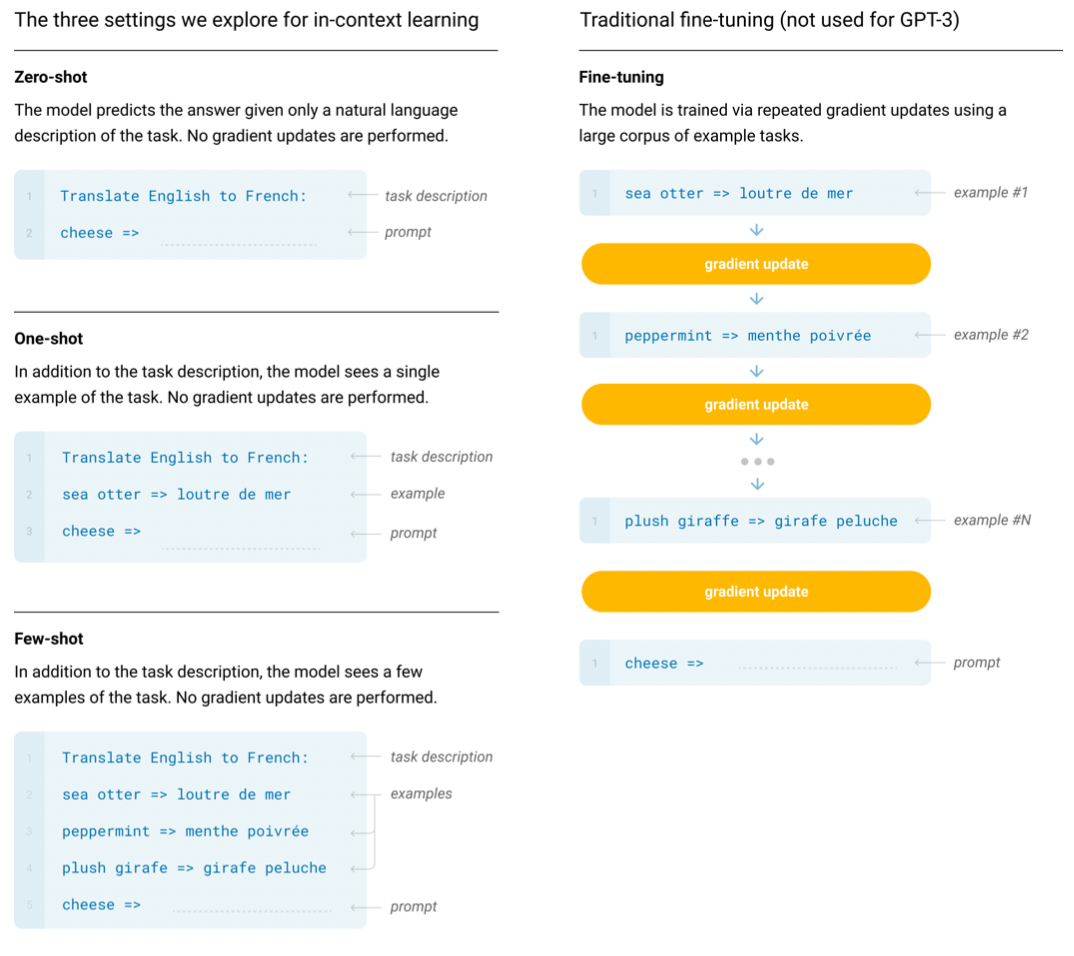
下图是zero-shot, one-shot,few-shot与传统的Fine-tuning的比较。Fine-tuning是需要训练的,模型要修改参数的。但是In-context learning不需要梯度更新,模型在推理的过程中学习示例中蕴含的逻辑。
GPT-3.5系列
GPT-3.5系列是一系列在2021第4季度之前根据混合文本和代码进行训练的模型。以下型号属于GPT-3.5系列:
- code-davinci-002是一个基本模型,非常适合纯代码完成任务
- text-davinci-002是一个基于code-davinci-002的InstructGPT模型
- text-davinci-003是对text-davici-002的改进
- gpt-3.5-turbo-0301是text-davinci-003的改进,针对聊天进行了优化
GPT-3.5-turbo*和ChatGPT的模型的关系

InstructGPT models
以 3 种不同方式训练的 InstructGPT 模型变体
SFT 和 PPO(Proximal Policy Optimization.)模型的训练与 InstructGPT 论文中的模型类似。 FeedME(“feedback made easy”的缩写)模型是通过所有的模型中提取最佳完成度来训练的。 模型通常在训练时使用最佳可用数据集,因此使用相同训练方法的不同引擎可能会在不同数据上进行训练。
ChatGPT 是 InstructGPT 的同级模型,它经过训练可以按照提示中的说明进行操作并提供详细的响应。 我们使用与 InstructGPT 相同的方法,使用人类反馈强化学习 (RLHF) 训练该模型,但数据收集设置略有不同。 ChatGPT 是从 GPT-3.5 系列中的一个模型微调而来的。
OpenAI 官网
We’ve trained a model called ChatGPT which interacts in a conversational way. The dialogue format makes it possible for ChatGPT to answer followup questions, admit its mistakes, challenge incorrect premises, and reject inappropriate requests. ChatGPT is a sibling model to InstructGPT, which is trained to follow an instruction in a prompt and provide a detailed response.
训练方法

- 第一步:收集范例数据,并以有监督方法训练。 贴标签者提供了输入提示分布(prompt distribution)上所需行为的范例。 然后,使用有监督学习在该数据集上微调预训练的 GPT-3 模型。
- 第二步:收集对比数据,训练奖励模型(Reward model)。 收集了多个模型输出之间比较的数据集,贴标记者给同一个输入不同模型输出根据喜欢程度打分,组成一个对比数据集。 然后用这个数据集训练奖励模型。
- 第三步:使用 PPO 针对奖励模型优化策略。 使用 RM奖励模型的输出作为标量奖励。 使用 PPO 算法微调监督策略以优化此奖励。
步骤2和步骤3可以不断迭代; 收集当前最佳策略的更多比较数据,用于训练新的 RM,然后训练新的策略。 在实践中,大部分比较数据来自监管的学习,也有一些来自PPO学习。
ChatGPT
总结:
- ChatGPT的实质功能是单字接龙
- 长文由单字接龙的自回归所生的
- 通过提前训练才能让它生成人们想要的问答
- 训练方式是让它按照问答范例来做单字接龙
- 这样训练是为了让它学会【能举一反三的规律】
- 缺点是可能混淆记忆,无法直接查看和更新所学,且高度依赖学习材料
ChatGPT 的三个训练阶段
- “开卷有益”阶段:让ChatGPT对【海量互联网文本】做单字接龙,以扩充模型的词汇量,语言知识,世界的信息与知识。使ChatGPT从“哑巴鹦鹉”变成“脑容量超级大的懂王鹦鹉”。
- “模版规范”阶段:让ChatGPT对【优质对话范例】做单字接龙,以规范回答的对话模式和对话内容。使ChatGPT变成“懂规矩的博学鹦鹉”。
- “创意引导”阶段:让ChatGPT根据【人类对它生成答案的好坏评分】来调节模型,以引导它生成人类认可的创意回答。使ChatGPT变成“既懂规矩又会试探的博学鹦鹉”。
利用优质对话范例再次利用单字接龙训练它。从而矫正不规范的回答。
为什么一开始不直接用优质的对话范例训练模型呢? 一方面优质的对话数量有限,另一方语言多样性不足,无法学习广泛的语言规律。也无法涉猎到各个领域。还有一方面,优质对话范例都是需要人工专门标注,成本过高。
在超大规模中,GPT3展现了“理解”指令,理解例子和思维链。
GPT-4 有什么新功能?
2023年3月27日,OpenAI 宣布发布其最新的大型语言模型 GPT-4。该模型是一个大型多模态模型(large multimodal model ),可以接受图像和文本输入并生成文本输出。GPT-4 是为了更好的遵循用户意图,更好的理解用户的问题,同时使其更真实并产生更少的冒犯性或危险输出。论文地址是这里。
1.性能改进
如您所料,GPT-4 在答案的事实正确性方面改进了 GPT-3.5 模型。 模型出现事实或推理错误的“幻觉(hallucinations)”数量较少,在 OpenAI 的内部事实性能基准测试中,GPT-4 的得分比 GPT-3.5 高 40%。
它还提高了“可操纵性(steerability)”,即根据用户请求更改其行为的能力。 例如,您可以命令它以不同的风格、语气或声音书写。 尝试以“你是一个喋喋不休的数据专家”或“你是一个简洁的数据专家”来开始提示,并让它向你解释一个数据科学概念。 您可以在此处阅读有关为 GPT 模型设计出色提示的更多信息。
进一步的改进是模型对护栏的依从性(adherence to guardrails)。 如果你要求它做一些非法或令人不快的事情,它最好拒绝这个请求。
2. 在 GPT-4 中使用视觉输入
一个主要变化是 GPT-4 可以使用图像输入(仅限研究预览;尚未向公众开放)和文本。 用户可以通过输入穿插的文本和图像来指定任何视觉或语言任务。
示例展示了 GPT-4 正确解释复杂图像的能力,例如来自学术论文的图表、模因和屏幕截图。
您可以在下面看到视觉输入的示例。


3. GPT-4 的性能基准
OpenAI 通过模拟为人类设计的考试来评估 GPT-4,例如Uniform Bar Examination和 LSAT,以及大学录取的 SAT。 结果表明,GPT-4 在各种专业和学术基准上达到了人类的水平。
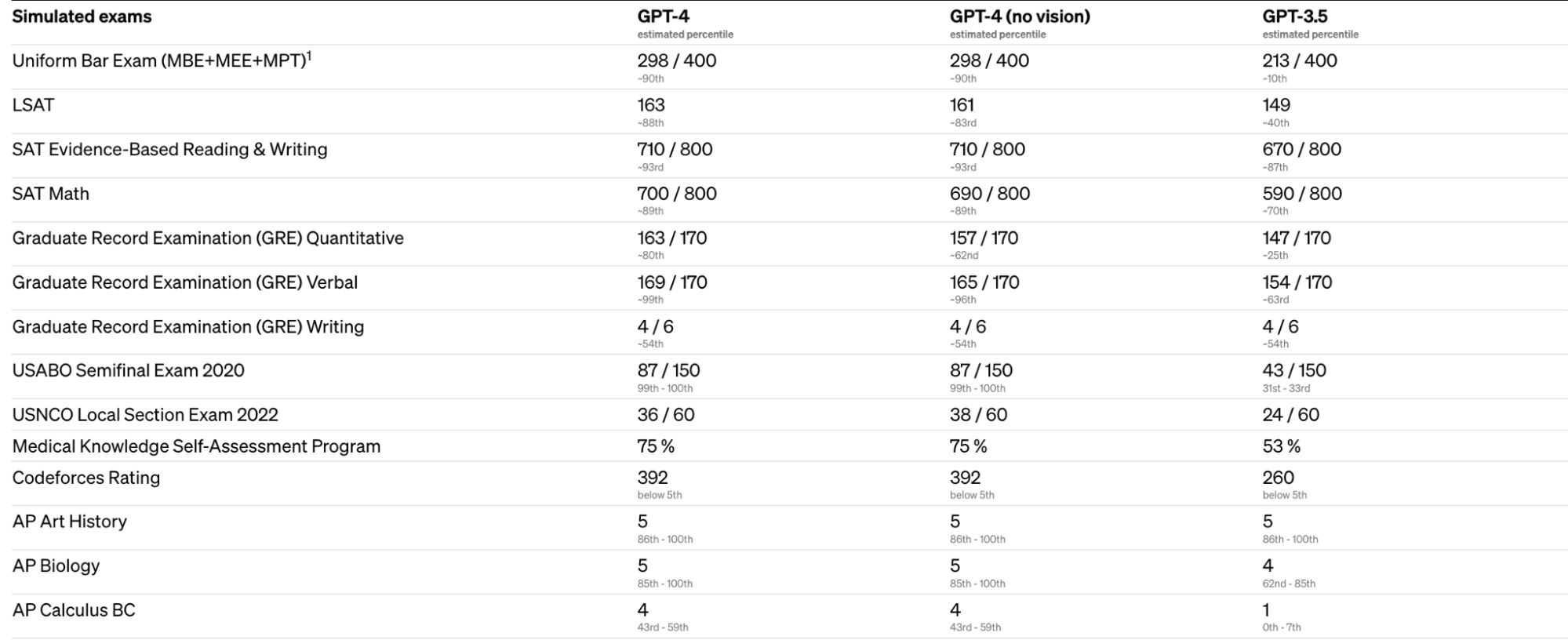
OpenAI 还在为机器学习模型设计的传统基准测试中评估了 GPT-4,它优于现有的大型语言模型和大多数最先进的模型,这些模型可能包括特定于基准的制作或额外的训练协议。 这些基准包括 57 个科目的多项选择题、围绕日常事件的常识推理、小学多项选择科学问题等等。
OpenAI 通过使用 Azure Translate 将 MMLU 基准测试(一套涵盖 57 个主题的 14,000 个多项选择题)翻译成各种语言来测试 GPT-4 在其他语言中的能力。 在测试的 26 种语言中的 24 种中,GPT-4 的英语语言性能优于 GPT-3.5 和其他大型语言模型。
总体而言,GPT-4 更加扎实的结果表明 OpenAI 在开发具有越来越先进能力的 AI 模型方面取得了重大进展。
如何访问 GPT-4
OpenAI 正在通过 ChatGPT 发布 GPT-4 的文本输入功能。 ChatGPT Plus 用户目前可以使用它。 GPT-4 API 有一个候补名单。
图像输入功能的公开可用性尚未公布。
OpenAI 拥有开源的 OpenAI Evals,这是一个用于自动评估 AI 模型性能的框架,允许任何人报告其模型中的缺陷并指导进一步改进。
问题
ChatGPT和InstructGPT异同
ChatGPT和InstructGPT在模型结构,训练方式上都完全一致,即都使用了指示学习(Instruction Learning)和人工反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)来指导模型的训练,它们不同的仅仅是采集数据的方式上有所差异。所以要搞懂ChatGPT,可以先读懂InstructGPT。
ChatGPT不是搜索引擎
ChatGPT在学习的过程中,并不是把学习材料保存在模型中,也不是根据模型和搜索引擎的搭配组成的结果。而是根据训练数据训练出一个通用模型来处理所有问题。生成全新回答。因此Chatgpt也被成为生成模型。
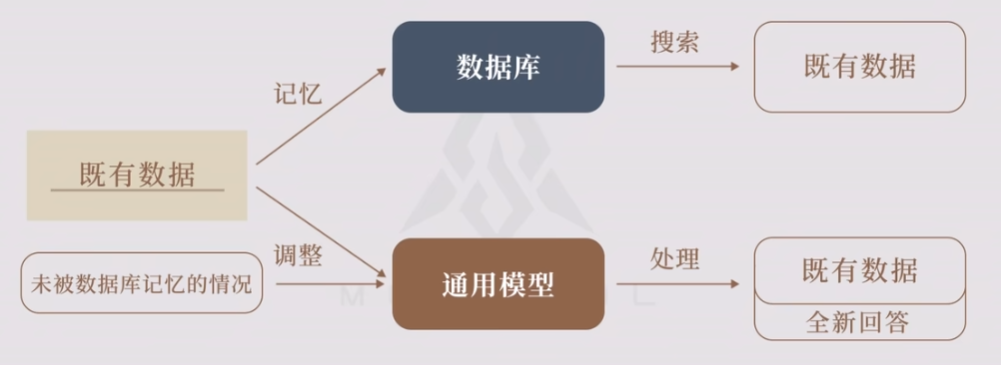
生成模型与搜索引擎对比
生成模型的长处:搜索引擎是没法给出没被数据库记忆的信息。但是生成语言模型可以生成数据即使是全新的信息。
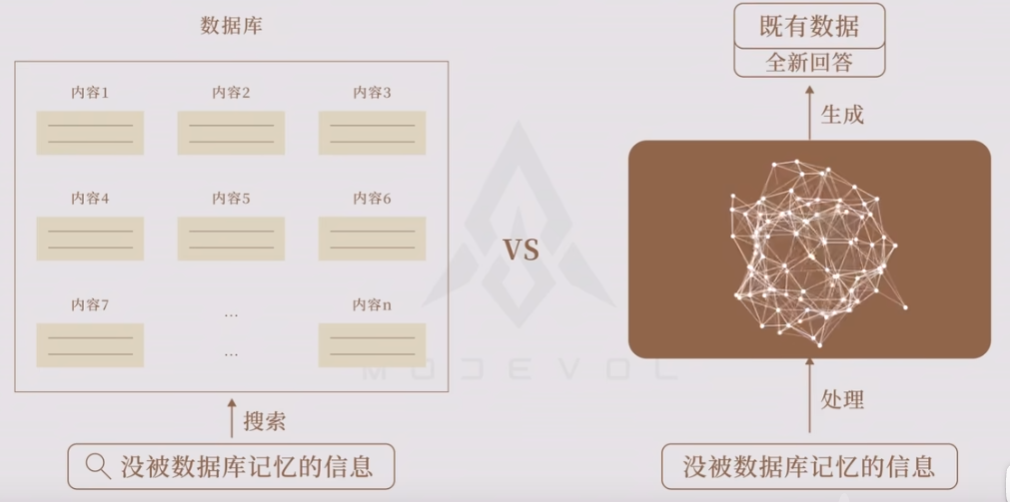
生成模型的短板
1. 能混淆记忆
生成模型的短板是可能混淆记忆但是搜索引擎不会
2. 模型所记住的内容无法直接操作
2.1. 结果缺乏解释性
2,2.更新效率低
不能通过增删改查调整模型,只能通过再次训练来调整模型,但是再次训练后,效果如何?是否是矫枉过正或引入其它问题有的通过多次提问来评估。容易顾此失彼,效率低下。
chatgpt高度依赖数据。想让Chatgpt处理未经情况,必须提供数量多,种类丰富,质量高的材料。
否则它就无法学到通用规律,所学的模型是以偏概全的。
英文缩写名词
| 缩写名词 | 全称 | 注解 |
| RLHF | Reinforcement Learning from Human Feedback | |
| GPT | Generative Pre-Trained Transformer | |
| LMs | Lanaguage Models | |
| SFT | Supervised fine-tuning on human demonstrations | |
| PPO | proximal policy optimization | Proximal Policy Optimization (PPO) is presently considered state-of-the-art in Reinforcement Learning. The algorithm, introduced by OpenAI in 2017 |
| RM | reward model |
参考资料
https://cdn.openai.com/papers/gpt-4.pdf
What is GPT-4 and Why Does it Matter? | DataCamp

