
热门标签
热门文章
- 1推荐开源项目:grapes - 简洁强大的SSH命令分发工具
- 2微信小程序蓝牙连接(uniapp版本)_微信小程序能获取蓝牙设备信息吗
- 3java编程helloworld代码_帮我写一段java的hello world代码
- 4scrapy爬取途牛网站旅游数据
- 5Transformer的Decoder的输入输出都是什么_transformer decoder 输入输出
- 6WSL安装使用Ollama_error: listen tcp 127.0.0.1:11434: bind: address a
- 7论文分享 | “大模型个性化”论文集锦_大模型文本改写题集
- 8yolo目标检测--用yolov4训练自己的数据集
- 9JMeter使用手册
- 10501.二叉搜索树的众数
当前位置: article > 正文
爬虫使用Beautiful Soup爬取网页信息示例代码(酷dog音乐)_3、利用beautifulsoup爬取酷狗音乐top22的排名、歌名和播放时间,并保存到新建的“
作者:盐析白兔 | 2024-07-21 23:16:48
赞
踩
3、利用beautifulsoup爬取酷狗音乐top22的排名、歌名和播放时间,并保存到新建的“
爬虫代码示例
(酷狗音乐top500榜单内容的爬取)
前言
综合利用Requests,Beautiful Soup等第三方库爬取网页信息,尤其是爬虫内容的筛选,利用strip,以及split方法来进行内容的选择。
提示:以下是本篇文章正文内容,下面案例可供参考
一、实验目的?
掌握综合运用Requests,Xpath以及Beautiful Soup等第三方库爬取网页信息的方法。
二、实验过程
1.实验环境(pycharm)
import requests from bs4 import BeautifulSoup from fake_useragent import UserAgent
2.需求说明
1)爬取酷狗音乐网站中酷狗Top500榜单中的前5页信息。
2)酷狗Top500网址:http://www.kugou.com/yy/rank/home/1-8888.html
3)该处使用的url网络请求的数据。因为网页版酷狗不能手动翻页进行下一步浏览,可以通过观察第一页URL:
http://www.kugou.com/yy/rank/home/1-8888.html
将数字1换成2、3等,每页显示22首歌曲。
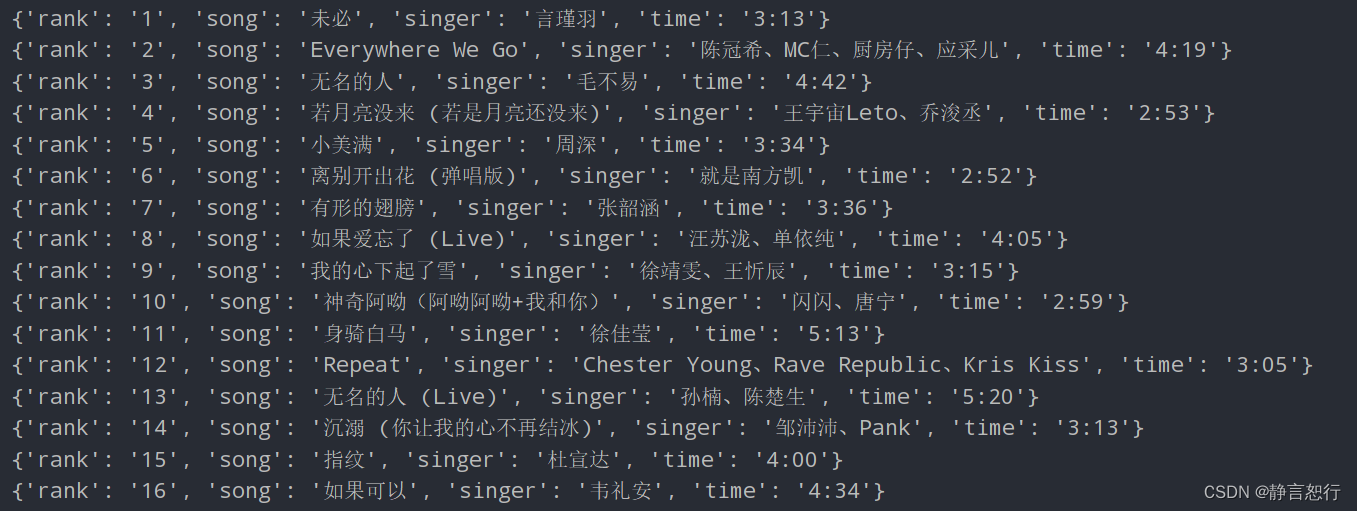
3.实验代码
- import requests
- from bs4 import BeautifulSoup
- from fake_useragent import UserAgent
-
-
- def spider_kugou():
- for i in range(1, 6):
- url = f"https://www.kugou.com/yy/rank/home/{i}-8888.html"
- ua = UserAgent()
- headers = {'User-Agent': ua.chrome}
- resp = requests.get(url, headers=headers)
- soup = BeautifulSoup(resp.text, 'lxml')
- ranks = soup.select('span.pc_temp_num')
- songs = soup.select('div.pc_temp_songlist > ul > li > a')
- times = soup.select('span.pc_temp_time')
- for rank, song, time in zip(ranks, songs, times):
- temp = song.get_text().split(' - ')
- data = {
- "rank": rank.get_text().strip(),
- "song": temp[0].strip(),
- "singer": temp[1].strip(),
- "time": time.get_text().strip()
- }
- print(data)
-
-
- if __name__ == '__main__':
- spider_kugou()

总结
记录一下split以及strip方法的使用教程
eg: 这个是未经过处理过的text字符串)
这个是未经过处理过的text字符串)
split():
str.split(str="", num=string.count(str))
- str -- 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。
- num -- 分割次数。默认为 -1, 即分隔所有。
经过split方法处理:

返回结果为:

经过strip方法处理

返回结果为:

strip():
string.strip([characters])其中,string 是要修改的文本,characters(可选)是要删除的特定字符列表。如果没有提供字符,strip 将删除任何前导或尾部空白。
爬虫的提取内容经过处理后,可以得到我们想要的结果,实战完成。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/862552
推荐阅读
相关标签

