
热门标签
热门文章
- 1Git 常用命令汇总大全_git send-email --annotate
- 2分享74个Python管理系统源代码总有一个是你想要的_python管理系统代码
- 3API工具--Apifox和Postman对比(区别)
- 4测试(绿盟)_绿盟dlp测试记录表
- 5linux安装docker
- 6深入理解Seata的四种解决方案_seata 解决什么问题
- 7哈希表、哈希桶数据结构以及刨析HashMap源码中哈希桶的使用_hash bucket
- 8韩国与日本历年GDP总量和人均GDP的对比(1953-2020年)_1960年朝鲜gdp总量
- 9活动报名|揭秘Bengio团队最新评测工作:视觉字幕恢复VCR,现有大模型能否过关?...
- 10云原生敏捷基础设施学习笔记
当前位置: article > 正文
GPT-3: Language Models are Few-Shot Learners
作者:盐析白兔 | 2024-07-24 02:10:01
赞
踩
gpt-3: language models are few-shot learners
GPT-3
数据集
- CommonCrawl:文章通过高质量参考语料库对CommonCrawl数据集进行了过滤,并通过模糊去重对文档进行去重,且增加了高质量参考语料库以增加文本的多样性。
- WebText:文章采用了类似GPT-2中的WebText文档收集清洗方法获得了更大范围的网页数据。
- Books Corpora:此外文章增加了两个来自网络的书籍语料库。
- Wiki:增加了英语百科语料库。
方法
-
模型架构基本延续GPT-2的基于Transformer的网络架构。相比于GPT-2做了如下改变:
- GPT-3采用了96层的多头transformer,头的个数为 96;
- 词向量的长度是12888
- 上下文划窗的窗口大小提升至 2048个token
- 在此基础上增加了Sparse-Transformer,即每次计算注意力的时候并不计算当前词与句子中所有词的注意力,而是通过Sparse Matrix仅仅计算当前词与句子中其它部分单词的注意力
-
In-context Learning
- 关键思想是从类比中学习,首先,ICL 需要一些示例来形成一个演示上下文。这些示例通常是用自然语言模板编写的。然后 ICL 将查询的问题(即你需要预测标签的 input)和一个上下文演示(一些相关的 cases)连接在一起,形成带有提示的输入,并将其输入到语言模型中进行预测。 值得注意的是,与需要使用反向梯度更新模型参数的训练阶段的监督学习不同,ICL 不需要参数更新,并直接对预先训练好的语言模型进行预测。
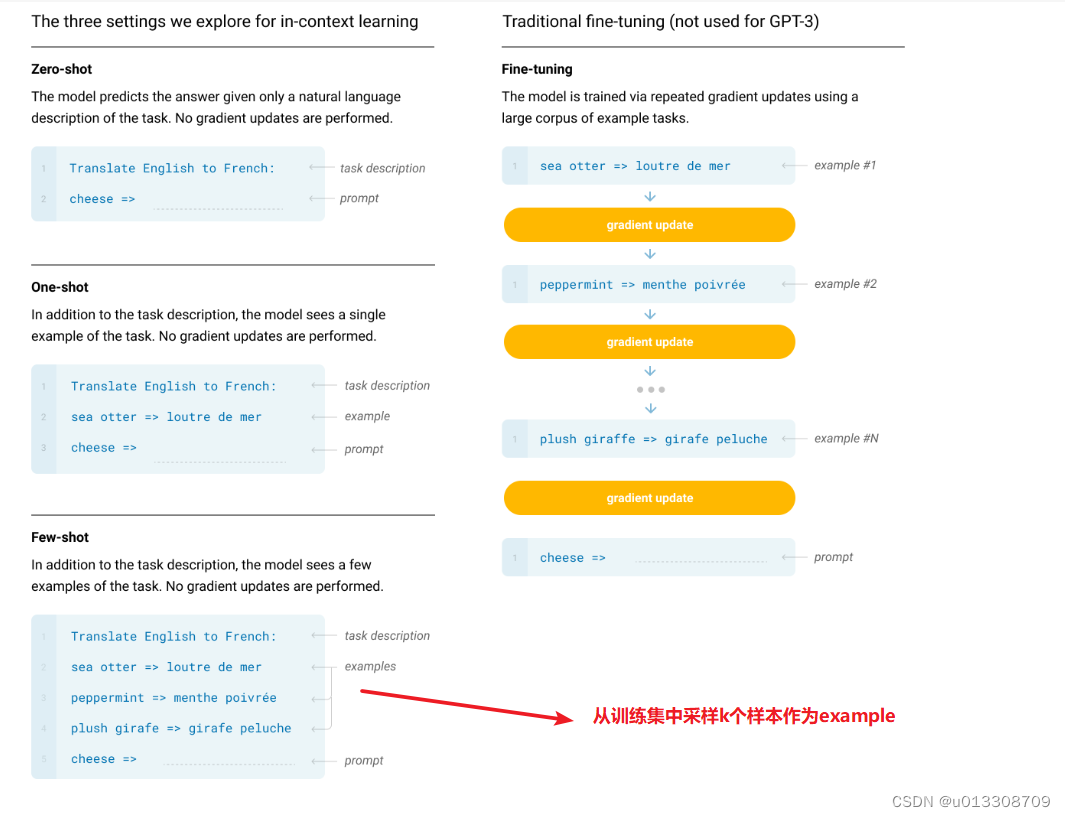
- 关键思想是从类比中学习,首先,ICL 需要一些示例来形成一个演示上下文。这些示例通常是用自然语言模板编写的。然后 ICL 将查询的问题(即你需要预测标签的 input)和一个上下文演示(一些相关的 cases)连接在一起,形成带有提示的输入,并将其输入到语言模型中进行预测。 值得注意的是,与需要使用反向梯度更新模型参数的训练阶段的监督学习不同,ICL 不需要参数更新,并直接对预先训练好的语言模型进行预测。
引用
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop】
推荐阅读
相关标签

