
- 1aws rds监控慢sql_如何使用Web控制台和AWS CLI停止AWS RDS SQL Server
- 2(附源码)spring boot物联网智能管理平台 毕业设计 211120_springboot 物联网相关技术有那些
- 3python常用字符串拼接方法_python字符串连接输出字符串
- 4多个comfyui之间如何共享模型,节省存储空间_comfyui共用模型
- 5AI、AGI、AIGC与AIGC、NLP、LLM,ChatGPT区分
- 6MySql中的CAST_mysql cast
- 7yolo v5 onnxruntime与opencv cv2加载部署推理、实时摄像头检测_onnxruntime yolo 多路摄像头识别
- 8git 的注册与常用的方式_agit网站注册
- 9AIGC从入门到入坑01(初学者适用版)_aigc百问百答适合新手入门
- 10我的软件测试面试经历,7轮高强度面试顺利入职_软件测试怎么面试高级别
《读论文系列 GPT》Improving Language Understandingby Generative Pre-Training(使用通用的预训练来提升语言的理解力)_阅读论文的gpt
赞
踩
摘要
自然语言理解包括各种各样的任务,如文本蕴涵、问题回答、语义相似性评估和文档分类。我们在没有标号的语言模型上进行预训练,在有标号的子任务上训练一个微调模型。 与以前的方法相反,我们在微调期间利用任务感知输入转换来实现有效的传输,同时需要对模型体系结构进行最小的更改。我们在自然语言理解的广泛基准上证明了我们的方法的有效性。+结果
1 介绍
使用无标号文本遇到的困难:
1 不清楚哪种类型的优化目标在学习对迁移有用的文本表示时最有效
2 怎么把文本学到的表示传到下游子任务上
半监督:学习一种普遍的表征,首先,我们在未标记数据上使用语言建模目标来学习神经网络模型的初始参数。随后,我们使用相应的监督目标将这些参数调整到目标任务中。
使用Transformer,在传输过程中,我们利用源自遍历式方法[52]的特定于任务的输入调整,将结构化文本输入处理为单个连续的令牌序列
可用于自然语言推理、问题回答、语义相似性和文本分类+结果
2 相关工作
自然语言的半监督学习:最早的方法是使用未标记的数据来计算词级或短语级统计,然后将其用作监督模型中的特征。最近的方法研究了从未标记数据中学习和利用超过单词级别的语义。
无监督预训练:使用语言建模目标预训练神经网络,然后在监督下对目标任务进行微调。
辅助训练目标:添加辅助无监督训练目标是半监督学习的另一种形式。
3 框架
第一阶段是在大量文本语料库上学习高容量语言模型。
接下来是一个微调阶段,我们将模型调整为具有标记数据的判别任务。
3.1 无监督的预训练
![]()
每个词表示成ui,那么整个文本就表示成u1-un;语言模型就是要预测第i个词出现的概率,GPT就是用一个语言模型来最大化似然函数。把ui前面的k个词,给定一个模型,预测这k个词下一个词的概率。从i=0开始一直到最后,相加得到目标函数。k是超参数(窗口大小),输入序列的长度。

语言模型θ是transformer的解码器。该模型在输入上下文令牌上应用多头自注意力操作,然后在位置前馈层上生成目标令牌的输出分布。
假设要预测u整个词的概率,把u前面的词拿出来记成U,加上投影和位置信息的编码作为transformer的输入,迭代n次每次都是将上一次的输出作为transformer下一次的输入;最后将transformer得到的最后一次的输出做一个投影,再经过一个softmax之后得u的概率。
3.2 有监督的微调
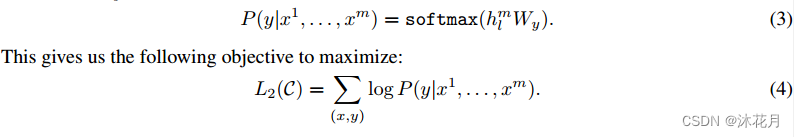
给x1-xm,去预测y。把整个序列放进之前训练好的GPT模型里面,拿到transormer快的最后一层的输出hm,再乘以一个输出层,通过softmax,得到概率。
把x1-xn输入进去后,计算真实的标号在上面的概率,对其做最大化。
![]()
把之前的语言模型放进来,效果很好
其中L1:给你序列,预测序列的下一个词;
L2:给你完整的序列,预测对应的标号。
3.3 特定任务的输入转化
把nlp里面很不同的子任务表示成统一的形式,也就是表示成序列和对应的标号。
将所有结构化输入转换为标记序列,由我们的预训练模型处理,然后是线性+softmax层。

分类:给一段文本,判断对应的标号。前面放一个初始的词源,后面放一个抽取的词源,做成一个序列,放进预训练好的transformer解码器中,在经过线性层得到概率。
蕴含:给一段话,再给一个假设,看这段话有没有蕴含假设。三分类问题。
相似:判断两段文字是否相似。相似对称。分别进入模型后得到输出,再相加,经过线性层得到是否相似。
多选:问一个问题,给几个答案,选出正确答案。如果有n个答案那么久有n个序列,输出得到答案是正确答案的置信度。
4 实验



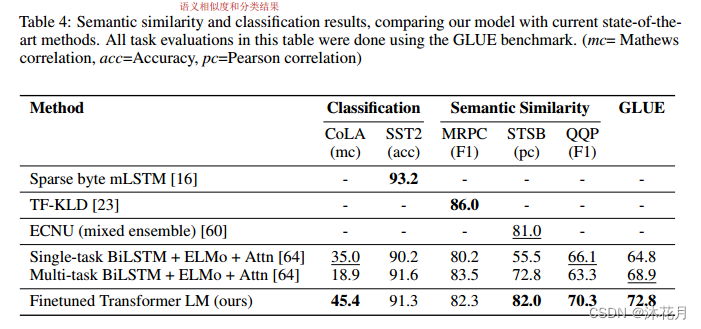
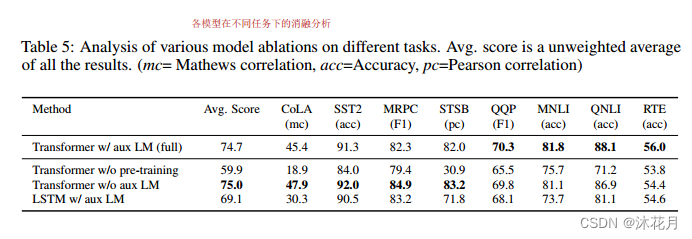
6 分析
7 结论
我们引入了一个框架,通过生成式预训练和判别微调,使用单一任务不可知论模型实现强自然语言理解。成功地转移到解决判别性任务,如问题回答、语义相似性评估、蕴意确定和文本分类。

