
热门标签
热门文章
- 12024年03月Python五级真题+答案解析(中国电子学会 )
- 2warning: LF will be replaced by CRLF the next time Git touches it warning_warning: in the working copy of 'windows.php', lf
- 3jenkins+springboot+github(或码云)实现自动部署_jadmins 码云
- 4大模型PEFT之LoRA_peftmodel在1卡加载一个base在0卡加载多个lora
- 5学人工智能,这10本书,精读一本就够!_人工智能入门自学书籍
- 6Python学习笔记 - Python语言概述和开发环境_假设有一段英文,text = "if the implementation is hard to e
- 7芋道源码 yudao-cloud 、Boot 文档,开发指南 看全部,去除弹窗[芋道快速开发平台 Boot + Cloud] 。可接二次开发
- 8Springboot 的几种配置文件形式_java springboot指定配置文件多种方式
- 9【大语言模型LLM】-如何使用大语言模型提高工作效率?_利用大预言模型的例子
- 10人工智能该如何学习?详细的AI学习路线与资料推荐_ai 如何学习
当前位置: article > 正文
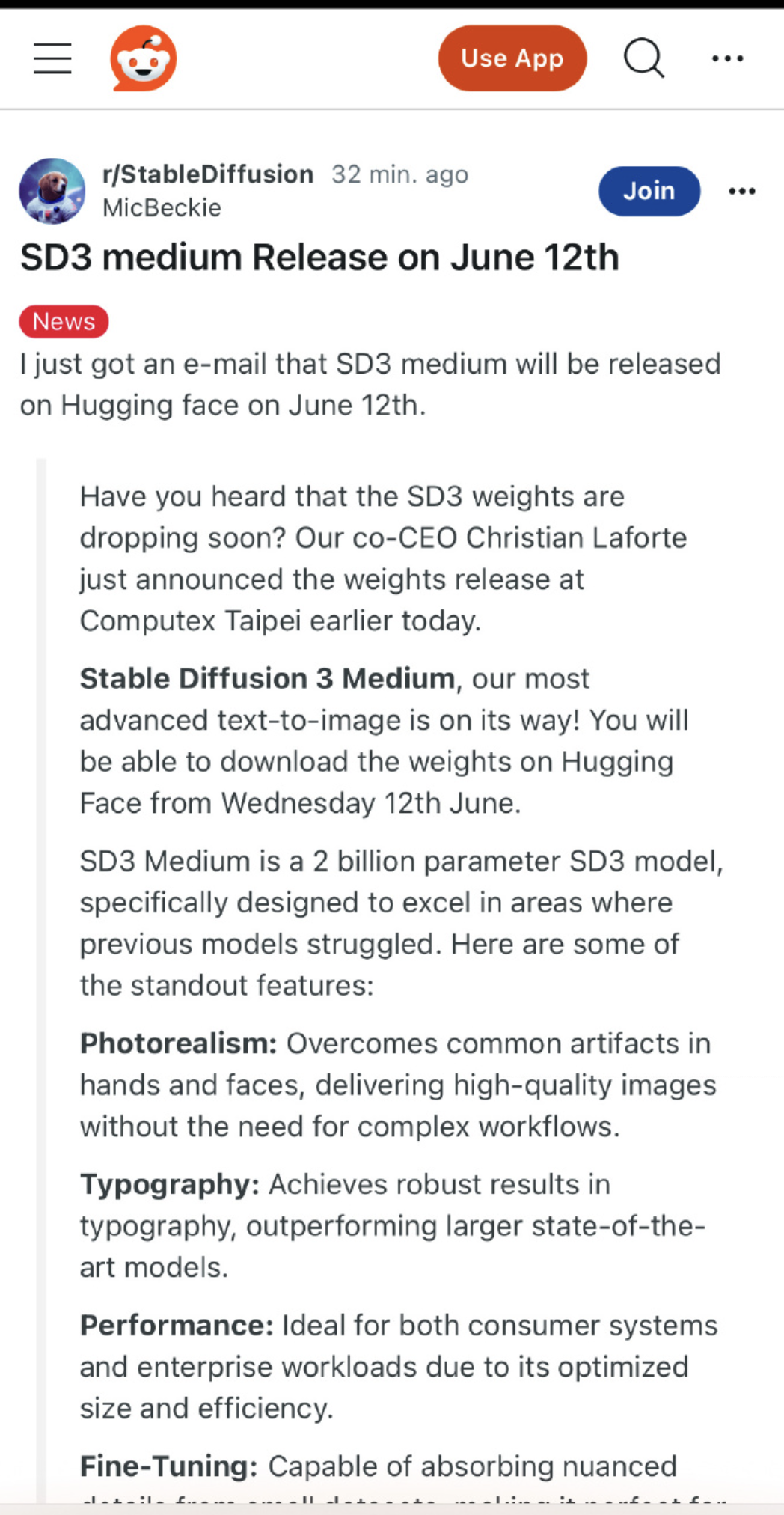
重磅消息! Stable Diffusion 3将于6月12日开源 2B 版本的模型,文中附候补注册链接。
作者:盐析白兔 | 2024-08-15 10:10:45
赞
踩
重磅消息! Stable Diffusion 3将于6月12日开源 2B 版本的模型,文中附候补注册链接。

在OpenAI发布Sora后,Stability AI也发布了其最新的模型Stabled Diffusion3, 之前的文章中已经和大家介绍过,感兴趣的小伙伴可以点击以下链接阅读。Sora是音视频方向,Stabled Diffusion3是图像生成方向,那么两者没有必然的联系,此外二者的核心部分都是采用了Difusion Transformer的方式。
从Stability AI 在 X 上发布的消息以及已经有一部分人收到了 Stability AI 的邮件证实了 6 月 12 号将会开源 2B 版本的模型-Stable Diffusion 3 Medium。

相关链接
候补注册地址:https://stability.ai/stablediffusion3
SD3的更新特点
-
采用Diffusion Transformer(DiT)架构:Stable Diffusion 3.0采用了与Sora相同的DiT架构,这种架构设计使得系统的扩展性更强,能够处理多种类型的输入数据。
-
支持生成视频、3D内容:Stable Diffusion 3.0发布时,将包含一套完整的工具,支持生成视频、3D以及更多类型的内容创作。
-
模型参数量的增加:从之前的800M参数升级到8亿参数量,这意味着新的模型能够为用户提供更多扩展性选择,同时生成的图片效果更加惊人。
-
图像质量的提升:Stable Diffusion 3.0在图像质量和色彩饱和度、图像构图、分辨率、类型、质感、对比度等方面大幅度增强。
效果展示



声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/983109
推荐阅读
相关标签

