
- 1移动H3_2S光猫进入管理员账号_h3-2s超级密码
- 2【信道编码】LDPC-BP信道编码【含Matlab源码 2340期】_ldpc编码是信道编码的代码
- 3《大话数据结构》-程杰自学数据结构感悟_程杰大话数据结构
- 4刚刚,谷歌宣布TPU全面开放,AI芯片及云市场再迎变局
- 5Word Embeddings 原理与代码实战案例讲解
- 6寿星万年历---java算法实现_寿星万年历算法
- 7Java程序设计——实现求几何图形的周长面积_java用接口编写程序长方形和圆形都属子几何图形,都有周长和面积,并且它们都有
- 8如何在Spring Boot应用中加载和使用TensorFlow模型
- 9Java面试题以及答案--SpringMVC框架_java mvc面试
- 10Python 操作excel
Llama 3.1:系列模型原理讲解论文(章节6-9)_llama3.1论文下载
赞
踩
6 推论
我们研究了两种主要技术来提高 Llama 3 405B 模型的推理效率:(1) 管道并行和 (2) FP8 量化。我们已公开发布了 FP8 量化的实现。
下载全文PDF(7.4万字):https://www.aisharenet.com/llama-3yigeduoa/
6.1 管道并行 (Pipeline Parallelism)
当使用 BF16 表示模型参数时,Llama 3 405B 模型无法装入单个配备 8 个 Nvidia H100 GPU 的机器的 GPU 内存。为了解决这个问题,我们使用了 BF16 精度,将模型推理并行化到两台机器上的 16 个 GPU 上。在每台机器内,高带宽的 NVLink 使得能够使用张量并行 (Shoeybi et al.,2019)。然而,跨节点连接具有较低的带宽和更高的延迟,因此我们使用管道并行 (Huang et al.,2019)。
在使用管道并行的训练过程中,气泡是一个主要的效率问题(参见第 3.3 节)。但是,它们在推理过程中并不是一个问题,因为推理不涉及需要管道冲刷的反向传递。因此,我们使用微批量化来提高管道并行推理的吞吐量。
我们评估了在 4,096 个输入标记和 256 个输出标记的推理工作负载中使用两个微批量的效果,这两个微批量分别用于推理的关键值缓存预填充阶段和解码阶段。我们发现微批量化可以提高相同本地批量大小的推理吞吐量;参见图 24。这些改进来自微批量化在两个阶段都能够并发执行微批量。由于微批量化导致额外的同步点,也会增加延迟,但总体而言,微批量化仍然会导致更好的吞吐量-延迟权衡。

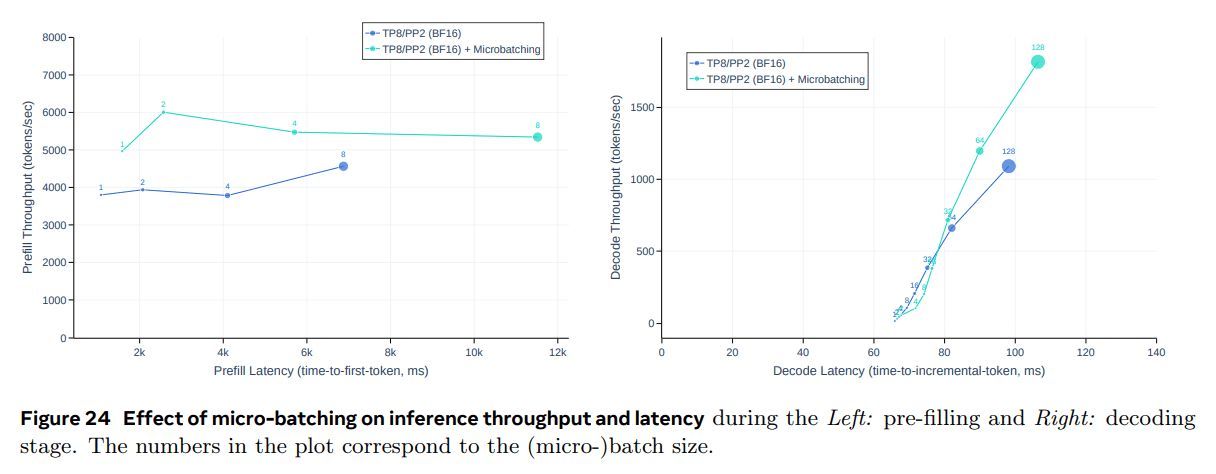
6.2 FP8 量化
我们利用 H100 GPU 本身的 FP8 支持进行低精度推理实验。为了实现低精度推理,我们将模型内部的大多数矩阵乘法应用了 FP8 量化。具体来说,我们将模型中前馈网络层的绝大多数参数和激活值进行了量化,这些层占推理计算时间的约 50%。我们没有对模型的自注意力层中的参数进行量化。我们利用动态缩放因子来提高精度 (Xiao 等人,2024b),并优化我们的 CUDA 内核15 以减少计算比例的开销。
我们发现 Llama 3 405B 的质量对某些类型的量化很敏感,并做了一些额外的改动以提高模型输出质量:
- 与 Zhang 等人 (2021) 相似,我们没有对第一个和最后一个 Transformer 层进行量化。
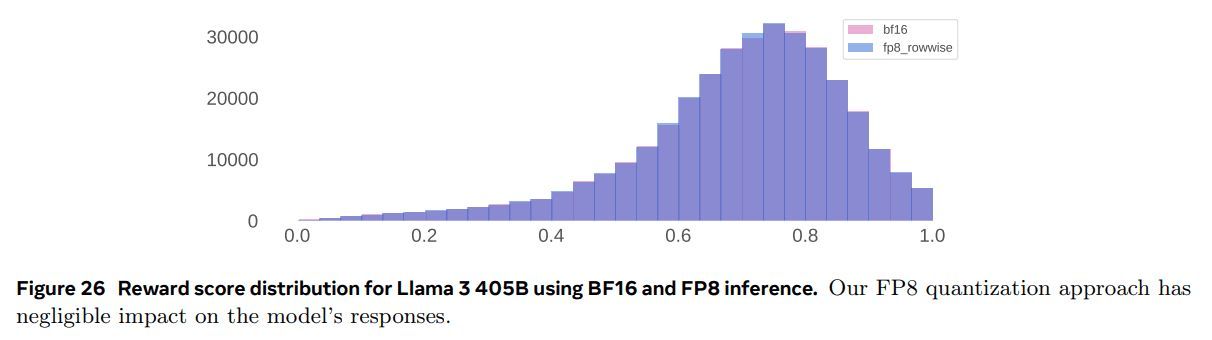
- 高排列度标记(例如日期)可能导致较大的激活值。反过来,这会导致 FP8 中较高的动态缩放因子,并产生不可忽视数量的浮点下溢,从而导致解码错误。图 26 显示了使用 BF16 和 FP8 推理的 Llama 3 405B 的奖励得分分布。我们的 FP8 量化方法对模型的响应几乎没有影响。
为了解决这个问题,我们将动态缩放因子上限设置为 1200。
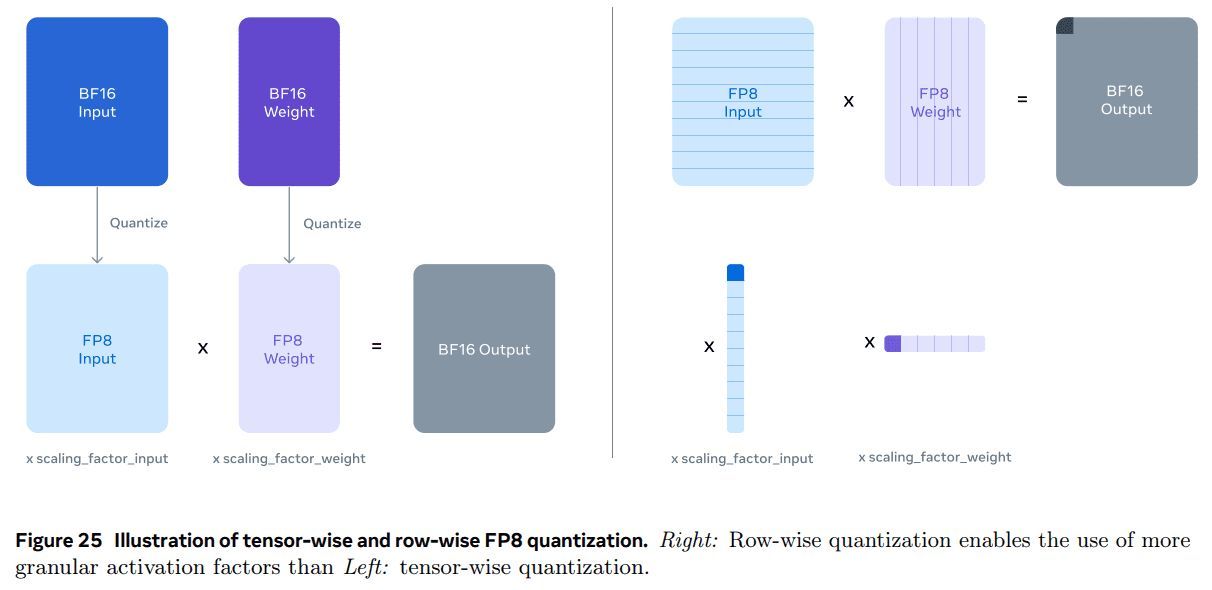
- 我们使用逐行量化,为参数和激活矩阵计算跨行的缩放因子(见图 25)。我们发现这比张量级量化方法效果更好。
量化错误的影响。标准基准的评估通常表明,即使没有这些缓解措施,FP8 推理的性能也与 BF16 推理相当。但是,我们发现这样的基准不能充分反映 FP8 量化的影响。当缩放因子没有被上限限制时,模型偶尔会产生损坏的响应,即使基准性能很强。
与其依靠基准来测量由于量化导致的分布变化,不如分析使用 BF16 和 FP8 生成的 100,000 个响应的奖励模型得分的分布。图 26 显示了我们量化方法得到的奖励分布。结果表明,我们的 FP8 量化方法对模型的响应影响非常有限。
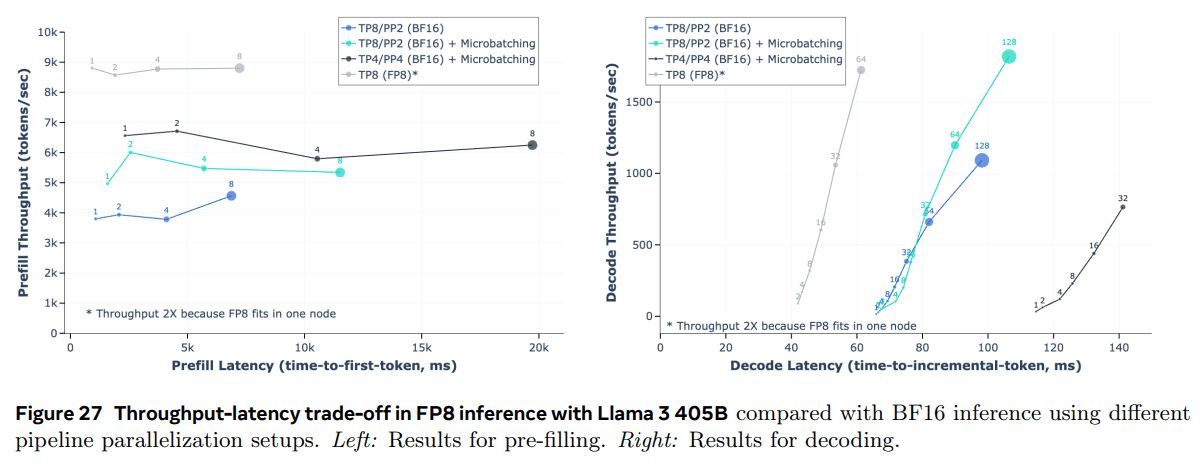
效率实验评估。图 27 描述了使用 Llama 3 405B 在预填充和解码阶段执行 FP8 推理的吞吐量-延迟权衡关系,使用 4,096 个输入标记和 256 个输出标记。该图将 FP8 推理的效率与第 6.1 节中描述的两台机器 BF16 推理方法进行了比较。结果表明,使用 FP8 推理可以使预填充阶段的吞吐量提高高达 50%,并且在解码期间大幅提高了吞吐量-延迟权衡关系。
7 视觉实验
我们进行了一系列实验,通过一种组合方法将视觉识别能力整合到 Llama 3 中。该方法主要分为两个阶段:
第一个阶段: 我们将预训练的图像编码器 (Xu et al., 2023) 与预训练的语言模型结合起来,并在大量的图像文本对上引入和训练一组交叉注意力层 (Alayrac et al., 2022)。这导致了如图 28 所示的模型。
第二个阶段: 我们引入了时间聚合层和额外的视频交叉注意力层,这些层作用于大量视频文本对上,以学习模型识别和处理来自视频的时间信息。
组合式方法构建基础模型有几个优势:
(1) 它允许我们并行开发视觉和语言建模功能;
(2) 它避免了联合预训练视觉和语言数据带来的复杂性,这些复杂性源于视觉数据的标记化、不同模式的背景困惑度的差异以及模式之间的竞争;
(3) 它保证了引入视觉识别能力不会影响模型在仅文本任务上的性能;
(4) 交叉注意力架构确保我们不需要将全分辨率图像传递给不断增大的 LLM 主干 (特别是在每个 Transformer 层中的前馈网络),从而提高推理效率。
请注意,我们的多模态模型仍在开发中,尚未准备好发布。
在第 7.6 和 7.7 节中介绍实验结果之前,我们将描述用于训练视觉识别能力的数据、视觉组件的模型架构、我们如何扩展这些组件的训练以及我们的预训练和后训练配方。
7.1 数据
我们分别描述了图像和视频数据。
7.1.1 图像数据
我们的图像编码器和适配器在图像-文本对上进行训练。我们通过一个复杂的的数据处理管道构建这个数据集,该管道包括四个主要阶段:
(1) 质量过滤 (2) 感知去重 (3) 重采样 (4) 光学字符识别 。我们还应用了一系列的安全措施。
- 质量过滤: 我们实施质量过滤器,通过诸如(Radford 等人,2021)产生的低对齐分数等启发式方法去除非英语标题和低质量标题。具体来说,我们将低于特定 CLIP 分数的所有图像-文本对都删除。
- 去重: 去除大规模训练数据集的重复数据可以提高模型性能,因为它减少了用于冗余数据的训练计算(Esser 等人,2024;Lee 等人,2021;Abbas 等人,2023),并减少了模型记忆化风险(Carlini 等人,2023;Somepalli 等人,2023)。因此,我们出于效率和隐私原因对训练数据进行去重。为此,我们使用最新的 SSCD 复制检测模型(Pizzi 等人,2022)的内部版本来大规模地对图像进行去重。对于所有图像,我们首先使用 SSCD 模型计算一个 512 维的表示。然后,我们使用这些嵌入针对数据集中的所有图像执行最近邻 (NN) 搜索,使用余弦相似性度量。我们将高于特定相似度阈值的示例定义为重复项。我们使用连通分量算法对这些重复项进行分组,并仅保留每个连通分量的单个图像-文本对。我们通过以下方式提高去重管道的效率:(1) 使用 k 均值聚类预先对数据进行聚类 (2) 对 NN 搜索和聚类使用 FAISS(Johnson 等人,2019)。
- 重采样: 我们确保图像-文本对的多样性,类似于 Xu 等人(2023);Mahajan 等人(2018);Mikolov 等人(2013)。首先,我们通过解析高质量的文本源构建一个 n 元语法词汇表。接下来,我们计算数据集中每个词汇表 n 元语法的频率。然后,我们以如下方式对数据进行重采样:如果标题中的任何 n 元语法在词汇表中出现的次数少于 T 次,我们就保留相应的图像-文本对。否则,我们独立地对标题中的每个 n 元语法 n i 以概率 T / f i 进行抽样,其中 f i 表示 n 元语法 n i 的频率;如果任何 n 元语法都被抽取到了,我们就保留图像-文本对。这种重采样有助于提高低频类别和细粒度识别任务的性能。
- 光学字符识别: 我们通过提取图像中的文字并将其与标题串联起来,进一步改进了我们的图像文本数据。使用专有光学字符识别 (OCR) 管道提取书写文本。我们观察到将 OCR 数据添加到训练数据中可以极大地提高需要 OCR 功能的任务的性能,例如文档理解。
为了提高模型在文档理解任务上的性能,我们将文档页面渲染为图像,并将图像与其各自的文本配对。文档文本是直接从源获取的,或者通过文档解析管道获取的。
安全: 我们主要致力于确保图像识别预训练数据集不包含不安全内容,例如性虐待材料 (CSAM) (Thiel, 2023)。我们使用感知哈希方法,如 PhotoDNA (Farid, 2021),以及内部专有分类器,扫描所有训练图像以查找 CSAM。我们还使用专有的媒体风险检索管道来识别和删除我们认为是 NSFW 的图像文本对,例如因为它们包含性或暴力内容。我们相信最小化训练数据集中的此类材料的流行度可以提高最终模型的安全性和帮助性,而不会影响其有用性。最后,我们对训练集中的所有图像执行面部模糊处理。我们测试了该模型针对人类生成的引用附加图像的提示。
退火数据: 我们通过使用 n-gram 对图像标题对进行重采样,创建了一个包含约 3.5 亿个示例的退火数据集。由于 n-gram 重采样有利于更丰富的文本描述,因此它选择了一个更高质量的数据子集。我们还用来自五个额外来源的约 1.5 亿个示例增强了结果数据:
-
- 视觉定位: 我们将文本中的名词短语与图像中的边界框或蒙板关联起来。定位信息(边界框和蒙板)以两种方式在图像文本对中指定:(1) 我们在图像上覆盖框或蒙板,并在文本中使用标记作为参考,类似于标记集 (Yang et al., 2023a)。(2) 我们直接将归一化 (x min, y min, x max, y max) 坐标插入文本,并用特殊标记将其分隔开。
- 截图解析: 我们从 HTML 代码中渲染截图,并让模型预测生成特定截图元素的代码,类似于 Lee 等人 (2023)。感兴趣的元素通过边界框在截图中指示。
- 问答对: 我们包括问答对,使我们能够使用太大而无法用于模型微调的大量问答数据。
- 合成标题: 我们包括带有由早期模型版本生成的合成标题的图像。与原始标题相比,我们发现合成标题提供了比原始标题更全面的图像描述。
- 合成结构化图像。 我们还包含了各种领域(例如图表、表格、流程图、数学公式和文本数据)的合成生成图像。这些图像都附带相应的结构化表示,例如对应的 Markdown 或 LaTeX 符号。 除了提高模型在这些领域的识别能力外,我们发现这些数据对于通过文本模型生成用于微调的问答对也很有用。
图 28 本文研究的将多模态能力添加到 Llama 3 的组合方法示意图。 这种方法导致一个多模态模型,经过五个阶段训练:语言模型预训练、多模态编码器预训练、视觉适配器训练、模型微调和语音适配器训练。
7.1.2 视频数据
为了进行视频预训练,我们使用了大型的视频-文本对数据集。我们的数据集通过多阶段过程进行整理。 我们使用基于规则的启发式方法筛选和清理相关的文本,例如确保最小长度并修复大写字母。然后,我们运行语言识别模型以过滤掉非英语文本。
我们运行OCR检测模型以过滤掉过度叠加文本的视频。为了确保视频-文本对之间的合理对齐,我们使用CLIP(Radford等,2021)风格的图像-文本和视频-文本对比模型。 我们首先使用视频中的单帧计算图像-文本相似度,并过滤掉相似度低的对,然后后续过滤掉视频-文本对齐较差的对。我们的某些数据包含静态或低运动视频;我们使用基于运动评分的过滤(Girdhar等,2023)来过滤这些数据。我们没有对视频的视觉质量进行任何过滤,例如美学评分或分辨率过滤。
我们的数据集包含平均持续时间为 21 秒的中值持续时间为 16 秒的视频,超过99% 的视频都在一分钟以内。空间分辨率在 320p 和 4K 视频之间变化很大,其中超过 70% 的视频的短边大于 720 像素。视频具有不同的纵横比,几乎所有视频的纵横比都在 1:2 和 2:1 之间,中值为 1:1。
7.2 模型架构
我们的视觉识别模型由三个主要组件组成: (1) 图像编码器,(2) 图像适配器,以及 (3) 视频适配器。
图像编码器:
我们的图像编码器是一个标准的视觉 Transformer(ViT;Dosovitskiy 等人 (2020)),它被训练用来对齐图像和文本 (Xu 等人, 2023)。 我们使用 ViT-H/14 版本的图像编码器,它拥有 6.3 亿个参数,在 25 亿张图像-文本对上训练了五个 epoch。 图像编码器的输入图像分辨率为 224 × 224;图像被拆分为 16 × 16 个大小相等的小块(即 14×14 像素的块大小)。正如之前 ViP-Llava (Cai 等人, 2024) 等工作所表明的那样,我们发现通过对比文本对齐目标训练的图像编码器无法保留精细的定位信息。为了缓解这个问题,我们采用了多层特征提取方法,除了最后一层特征外,还提供了第 4、8、16、24 和 31 层的特征。
此外,我们在交叉注意力层的预训练之前进一步插入了 8 个门控自注意力层(总共 40 个 Transformer 块),以学习特定于对齐的特征。因此,图像编码器最终拥有 8.5 亿个参数和额外的层。 通过多层特征,图像编码器为生成的 16 × 16 = 256 个小块中的每一个产生一个 7680 维度的表示。在后续训练阶段中,我们不会冻结图像编码器的参数,因为我们发现这可以提高性能,特别是在文本识别等领域。
图像适配器:
我们在图像编码器产生的视觉标记表示和语言模型产生的标记表示之间引入交叉注意力层 (Alayrac 等人, 2022)。交叉注意力层应用于核心语言模型中的每个第四个自注意力层之后。 与语言模型本身一样,交叉注意力层使用广义查询注意力 (GQA) 来提高效率。
交叉注意力层为模型引入了大量可训练参数:对于 Llama 3 405B,交叉注意力层的参数约为 1000 亿。 我们对图像适配器进行了两个阶段的预训练: (1) 初始预训练和 (2) 退火: * 初始预训练: 我们在上述约 60 亿张图像-文本对的数据集上预训练我们的图像适配器。为了提高计算效率,我们将所有图像的大小调整为最多适合四个 336 × 336 像素的图块,其中我们安排图块以支持不同的宽高比,例如 672 × 672、672 × 336 和 1344 × 336。 * 退火: 我们继续使用上述退火数据集中的约 5 亿张图像来训练图像适配器。在退火过程中,我们增加每个图块的图像分辨率以提高对需要更高分辨率图像的任务的性能,例如信息图表理解。
视频适配器:
我们的模型最多可以接受 64 帧的输入(均匀采样自完整视频),每个帧都被图像编码器处理。我们通过两个组件对视频中的时间结构进行建模: (i) 编码的视频帧通过一个时间聚合器合并成一个,该聚合器将 32 个连续的帧合并为一个;(ii) 在每个第四个图像交叉注意力层之前添加额外的视频交叉注意力层。时间聚合器被实现为感知器重采样器 (Jaegle 等人, 2021;Alayrac 等人, 2022)。 我们使用每视频 16 帧(聚合成 1 帧)进行预训练,但在监督微调期间将输入帧数增加到 64。 视频聚合器和交叉注意力层在 Llama 3 7B 和 70B 中分别有 0.6 亿和 4.6 亿个参数。
7.3 模型规模
在将视觉识别组件添加到 Llama 3 后,模型包含自注意力层、交叉注意力层和一个 ViT 图像编码器。我们发现在训练较小(80 亿和 700 亿参数)模型的适配器时,数据并行和张量并行是最有效的组合。在这些规模下,模型或流水线并行不会提高效率,因为收集模型参数将主导计算。然而,在训练 4050 亿参数模型的适配器时,我们确实使用了流水线并行(除了数据和张量并行)。在这个规模上进行训练带来了三个新的挑战,除了第 3.3 节中概述的挑战之外:模型异质性、数据异质性和数值不稳定性。
模型异质性。模型计算是异质的,因为某些标记比其他标记执行更多的计算。特别是,图像标记通过图像编码器和交叉注意力层进行处理,而文本标记仅通过语言骨干网络进行处理。这种异质性会导致流水线并行调度中的瓶颈。我们通过确保每个流水线阶段包含五个层来解决这个问题:即语言骨干网络中的四个自注意力层和一个交叉注意力层。(回想一下,我们在每四个自注意力层后引入了一个交叉注意力层。)此外,我们将图像编码器复制到所有流水线阶段。由于我们训练的是配对的图像文本数据,这使我们能够在计算的图像和文本部分之间进行负载平衡。
数据异质性。数据是异质的,因为平均而言,图像比关联文本具有更多标记:一张图像有 2308 个标记,而关联文本平均只有 192 个标记。因此,交叉注意力层的计算需要更长的时间和更多的内存,而不是自注意力层的计算。我们通过在图像编码器中引入序列并行来解决这个问题,这样每个 GPU 处理的标记数量大致相同。由于平均文本尺寸相对较小,我们还使用了更大的微批量大小(8 而不是 1)。
数值不稳定性。在将图像编码器添加到模型后,我们发现使用 bf16 进行梯度累积会导致数值不稳定。最可能的解释是图像标记通过所有交叉注意力层引入到语言骨干网络中。这意味着图像标记表示中的数值偏差对整体计算的影响过大,因为错误被复合起来。我们通过使用 FP32 执行梯度累积来解决这个问题。
7.4 预训练
图像预训练: 我们从预训练的文本模型和视觉编码器权重开始初始化。视觉编码器被解冻,而文本模型权重保持冻结,如上所述。首先,我们使用 60 亿个图像-文本对训练模型,每个图像都被调整大小以适合四个 336 × 336 像素的图块。我们使用 16,384 的全局批量大小和余弦学习率计划,初始学习率为 10 × 10 -4,权重衰减为 0.01。初始学习率是基于小规模实验确定的。然而,这些发现并不能很好地推广到非常长的训练计划中,并且在损失值停滞时,我们会在训练过程中多次降低学习率。在基本预训练之后,我们将图像分辨率进一步提高,并在退火数据集上继续训练相同的权重。优化器通过热身重新初始化到学习率 2 × 10 -5,再次遵循余弦计划。
视频预训练: 对于视频预训练,我们从上述图像预训练和退火权重开始。我们将添加视频聚合器和交叉注意力层,如架构中所述,并随机初始化它们。我们冻结模型中的所有参数,除了特定于视频的参数(聚合器和视频交叉注意力),并在视频预训练数据上训练它们。我们使用与图像退火阶段相同的训练超参数,学习率略有不同。我们从完整的视频中均匀采样 16 帧,并使用四个大小为 448 × 448 像素的块来表示每一帧。我们在视频聚合器中使用 16 的聚合因子,从而得到一个有效的帧,文本标记将交叉关注该帧。我们使用 4,096 的全局批量大小、190 个标记的序列长度以及 10 -4 的学习率进行训练。
7.5 训练后处理
在这一章节中,我们将详细描述视觉适配器的后续训练步骤。
在预训练之后,我们将模型微调到高度精选的多模态对话数据上,以启用聊天功能。
此外,我们还实现了直接偏好优化 (DPO) 以提高人工评估性能,并采用了拒绝采样来改善多模态推理能力。
最后,我们添加了一个质量调整阶段,在这个阶段我们将继续在非常小的高质量对话数据集上微调模型,这进一步提高了人工评估结果,同时保留了基准测试的性能。
以下将提供每个步骤的详细信息。
7.5.1 监督微调数据
我们在下面分别描述用于图像和视频功能的监督微调 (SFT) 数据。
图像: 我们使用不同数据集的混合进行监督微调。
- 学术数据集:我们使用模板或通过大语言模型 (LLM) 重写,将高度过滤的现有学术数据集转换为问答对。LLM 重写的目的是用不同的指令来扩充数据,并提高答案的语言质量。
- 人工标注:我们通过人工标注员为各种任务(开放式问答、字幕、实际用例等)和领域(例如,自然图像和结构化图像)收集多模态对话数据。标注员将收到图像并被要求编写对话。
为了确保多样性,我们将大规模数据集进行聚类,并在不同的聚类中均匀地采样图像。此外,我们还通过使用 k 近邻扩展种子来获取一些特定领域的附加图像。标注员还将获得现有模型的中间检查点,以促进模型在循环中的样式标注,以便可以使用模型生成作为标注员提供额外人类编辑的起点。这是一个迭代过程,其中模型检查点将定期更新为性能更好的版本,这些版本是在最新数据上训练的。这增加了人工标注的量和效率,同时也提高了质量。
- 合成数据:我们探索了通过使用图像的文本表示和文本输入 LLM 生成合成多模态数据的不同方法。基本思路是利用文本输入 LLM 的推理能力在文本域中生成问答对,并用其对应的图像替换文本表示以产生合成的多模态数据。示例包括将来自问答数据集的文本呈现为图像或将表格数据呈现为合成表格和图表图像。此外,我们还使用现有图像的字幕和 OCR 提取来生成与图像相关的一般对话或问答数据。
视频: 与图像适配器类似,我们将预先存在注释的学术数据集用于转换,将其转换为适当的文本指令和目标响应。目标将转换为开放式回答或多项选择题,视情况而定。我们请人工标注员为视频添加问题和相应的答案。我们要求标注员关注那些不能基于单个帧来回答的问题,以引导标注员朝着需要时间理解的问题方向前进。
7.5.2 监督微调方案
我们分别介绍了图像和视频能力的受监督微调(SFT)方案:
图像: 我们从预训练的图像适配器初始化模型,但将预训练语言模型的权重替换为指令调优语言模型的权重。为了保持仅文本性能,语言模型权重保持冻结,即我们只会更新视觉编码器和图像适配器权重。
我们的微调方法类似于 Wortsman 等人(2022)。首先,我们使用多个数据随机子集、学习率和重量衰减值进行超参数扫描。接下来,我们根据模型性能对它们进行排名。最后,我们将前 K 个模型的权重取平均以获得最终模型。K 的值通过评估平均模型并选择性能最高实例来确定。我们观察到,与通过网格搜索找到的最佳单个模型相比,平均模型始终产生更好的结果。此外,这种策略减少了对超参数的敏感性。
视频: 对于视频 SFT,我们使用预训练权重初始化视频聚合器和交叉注意力层。模型的其余参数(图像权重和 LLM)则从相应的模型中初始化,并按照它们的微调阶段进行。类似于视频预训练,然后只对视频 SFT 数据上的视频参数进行微调。在此阶段,我们将视频长度增加到 64 帧,并使用 32 的聚合因子获得两个有效帧。 aynı zamanda,块的分辨率也相应提高,以与对应的图像超参数保持一致。
7.5.3 偏好数据
为了奖励建模和直接偏好优化,我们构建了多模态成对偏好数据集。
- 人工标注: 人工标注的偏好数据包含两个不同模型输出的比较,标记为“选择”和“拒绝”,并使用 7 级评分。用于生成响应的模型是每周从一池最佳近期模型中随机采样的,每个模型都有不同的特征。除了偏好标签外,我们还要求标注员提供可选的人工编辑以更正“选择”响应中的不准确性,因为视觉任务对不准确性的容忍度较低。请注意,人工编辑是一个可选步骤,因为实践中存在数量和质量之间的权衡。
- 合成数据: 通过使用仅文本的 LLM 编辑并故意在监督微调数据集引入错误也可以生成合成偏好对。我们取对话数据作为输入,并使用 LLM 引入微妙但有意义的错误(例如,更改对象、更改属性、添加计算错误等)。这些编辑后的响应被用作负面“拒绝”样本,并与“选择”的原始监督微调数据配对。
- 拒绝采样: 此外,为了创建更多策略性负样本,我们利用拒绝采样的迭代过程来收集额外的偏好数据。我们在接下来的部分中将更详细地讨论拒绝采样的使用方式。总而言之,拒绝采样用于从模型中迭代地采样高质量的生成结果。因此,作为副产品,所有未被选中的生成结果都可用作负面拒绝样本,并用作额外的偏好数据对。
7.5.4 奖励模型
我们训练了一个视觉奖励模型 (RM),它基于视觉 SFT 模型和语言 RM。视觉编码器和交叉注意力层从视觉 SFT 模型初始化,并在训练期间解冻,而自注意力层则从语言 RM 初始化并保持冻结。我们观察到,冻结语言 RM 部分通常会导致更好的精度,尤其是在需要 RM 根据其知识或语言质量进行判断的任务中。我们采用与语言 RM 相同的训练目标,但添加了一个加权正则化项来对批量平均的奖励 logits 平方进行处理,以防止奖励分数漂移。
第 7.5.3 节中的人类偏好注释用于训练视觉 RM。我们遵循与语言偏好数据(第 4.2.1 节)相同的做法,创建两到三个具有清晰排名的对(编辑版本 > 选择版本 > 拒绝版本)。此外,我们还通过扰动与图像信息相关的词语或短语(例如数字或视觉文本)来合成增强负面回复。这鼓励视觉 RM 基于实际的图像内容进行判断。
7.5.5 直接偏好优化
与语言模型(第 4.1.4 节)类似,我们使用直接偏好优化 (DPO;Rafailov 等人 (2023)) 进一步训练视觉适配器,并使用第 7.5.3 节中描述的偏好数据。为了对抗后训练过程中分布偏移,我们只保留最近几批人类偏好注释,而丢弃那些与策略差距较大的批次(例如,如果更改了基本预训练模型)。我们发现,与其始终冻结参考模型,不如每 k 步以指数移动平均 (EMA) 的方式更新它,有助于模型从数据中学习更多,从而在人类评估中获得更好的性能。总体而言,我们观察到视觉 DPO 模型在人类评估中始终优于其 SFT 起始点,并且在每次微调迭代中都表现出色。
7.5.6 拒绝采样
现有的大多数问答对仅包含最终答案,而缺乏推理任务泛化良好的模型所需的思维链解释。我们使用拒绝采样来为这些示例生成缺少的解释,从而提高模型的推理能力。
给定一个问答对,我们通过使用不同的系统提示或温度对微调后的模型进行采样来生成多个答案。接下来,我们将生成的答案与真实答案通过启发式方法或LLM裁判进行比较。最后,我们将正确的答案添加到微调数据中重新训练模型。我们发现每道题保留多个正确答案是有用的。
为了确保只将高质量的示例添加到训练中,我们实施了以下两个安全措施:
- 我们发现,一些示例包含错误的解释,尽管最终答案是正确的。我们注意到这种模式在只有很小一部分生成的答案正确的题目中更常见。因此,我们将正确答案概率低于特定阈值的题目的答案丢弃。
- 评审员由于语言或风格的差异而偏爱某些答案。我们使用奖励模型来选择 K 个最高质量的答案并将其添加到训练中。
7.5.7 质量调优
我们精心策划了一个规模虽小但高度精选的精细调优(SFT)数据集,所有样本都经过人工或我们最佳模型的重写和验证,以满足最高标准。 我们用这些数据训练DPO模型,以提高响应质量,并将此过程称为质量调优(QT)。我们发现,当QT数据集涵盖广泛的任务并且应用适当的提前停止时,QT可以显着提高人类评估结果,而不会影响基准测试验证的一般性性能。在此阶段,我们仅根据基准测试选择检查点,以确保能力保持或改进。
7.6 图像识别结果
我们评估了 Llama 3 图像理解能力在一系列任务上的表现,这些任务涵盖了自然图像理解、文本理解、图表理解和多模态推理:
- MMMU (Yue 等人,2024a) 是一个具有挑战性的多模态推理数据集,模型需要理解图像并解决跨越 30 个不同学科的大学水平问题。这包括多项选择题和开放式问题。我们将模型在包含 900 张图像的验证集上进行评估,与其他工作一致。
- VQAv2 (Antol 等人,2015) 测试了模型结合图像理解、语言理解和常识知识来回答关于自然图像的一般性问题的能力。
- AI2 Diagram (Kembhavi 等人,2016) 评估了模型解析科学图表并回答有关图表问题的能力。我们使用与 Gemini 和 x.ai 相同的评估协议,并使用透明边界框报告分数。
- ChartQA (Masry 等人,2022) 是一个具有挑战性的图表理解基准测试。这要求模型在视觉上理解不同类型的图表并回答有关这些图表逻辑问题。
- TextVQA (Singh 等人,2019) 是一个流行的基准数据集,需要模型阅读和推理图像中的文本以回答有关它们的疑问。这测试了模型对自然图像中 OCR 理解能力。
- DocVQA (Mathew 等人,2020) 是一个专注于文档分析和识别的基准数据集。它包含各种文档的图像,评估了模型执行 OCR 理解并推理文档内容以回答有关它们的问题的能力。
表 29 展示了我们实验的结果。表中的结果表明,附加到 Llama 3 上的视觉模块在不同模型容量的各种图像识别基准测试中都具有竞争力。使用 resulting Llama 3-V 405B 模型,我们在所有基准测试上均优于 GPT-4V,但略逊于 Gemini 1.5 Pro 和 Claude 3.5 Sonnet。Llama 3 405B 在文档理解任务上表现尤为出色。
7.7 视频识别结果
我们对 Llama 3 的视频适配器在三个基准测试上进行了评估:
- PerceptionTest (Lin et al., 2023):该基准测试模型对短视频片段进行理解和预测的能力。它包含了各种类型的问题,例如识别物体、动作、场景等。我们根据官方提供的代码和评估指标(准确率)报告结果。
- TVQA (Lei et al., 2018):该基准评估模型的复合推理能力,需要进行空间时间定位、识别视觉概念以及与字幕对话联合推理。由于该数据集来源于流行的电视节目,因此它还测试了模型利用这些电视节目的外部知识来回答问题的能力。它包含超过 1.5 万个验证 QA 对,每个对应的视频片段平均长度为 76 秒。它采用多项选择格式,每个问题有五个选项,我们根据先前工作(OpenAI, 2023b)在验证集上报告性能。
- ActivityNet-QA (Yu et al., 2019):该基准评估模型对长视频片段进行理解以了解动作、空间关系、时间关系、计数等的能力。它包含 800 个视频中的 8,000 个测试 QA 对,每个视频平均长度为 3 分钟。对于评估,我们遵循先前工作(Google, 2023;Lin et al., 2023;Maaz et al., 2024)的协议,其中模型生成短的单词或短语回答,并且使用 GPT-3.5 API 将其与真实答案进行比较以评估输出的正确性。我们报告 API 计算出的平均准确率。
推理过程
在执行推理时,我们从完整的视频片段中均匀采样帧并将其与简短的文本提示一起传递给模型。由于大多数基准都涉及回答多项选择题,因此我们使用以下提示:
- 从以下选项中选择正确的答案:{问题}。只用正确选项字母回答,不要写其他任何东西。
对于需要生成简短答案(例如 ActivityNet-QA 和 NExT-QA)的基准,我们使用以下提示:
- 使用一个单词或短语回答问题:{问题}。
对于 NExT-QA,由于评估指标(WUPS)对长度和使用的特定单词很敏感,因此我们还提示模型要具体化并回复最突出的答案,例如在被问及位置问题时指定“客厅”而不是简单地回答“房子”。对于包含字幕(即 TVQA)的基准,我们在推理过程中将片段对应的字幕包含在提示中。
结果
表 30 展示了 Llama 3 8B 和 70B 模型的性能。我们将其与两个 Gemini 模型和两个 GPT-4 模型的性能进行了比较。请注意,所有结果都是零样本的结果,因为我们在训练或微调数据中没有包含这些基准的任何部分。我们发现,我们的 Llama 3 模型在后处理期间训练小型视频适配器非常有竞争力,并且在某些情况下甚至比其他可能从预训练开始就利用原生多模态处理的模型更好。Llama 3 在视频识别方面表现特别出色,因为我们仅评估了 8B 和 70B 参数模型。Llama 3 在 PerceptionTest 上取得了最佳成绩,这表明该模型具有很强的进行复杂时间推理的能力。在像 ActivityNet-QA 这样的长片段活动理解任务中,即使 Llama 3 只处理高达 64 帧,它也能获得强劲的结果(对于 3 分钟的视频,模型每 3 秒只处理一帧)。
8 语音实验
我们进行了实验,研究将语音功能整合到 Llama 3 中的组合方法,类似于我们用于视觉识别的方案。在输入端,添加了编码器和适配器来处理语音信号。我们利用系统提示(以文本形式)来使 Llama 3 支持不同的语音理解模式。如果没有提供系统提示,该模型将充当通用语音对话模型,能够有效地以与仅文本版本 Llama 3 一致的方式响应用户语音。引入对话历史作为提示前缀可以改善多轮对话体验。我们还尝试了使用系统提示来实现 Llama 3 的自动语音识别(ASR)和自动语音翻译(AST)。Llama 3 的语音界面支持高达 34 种语言。18 它还允许文本和语音交替输入,使模型能够解决高级音频理解任务。
我们还尝试了一种语音生成方法,其中我们实现了流式文本到语音(TTS)系统,该系统在语言模型解码过程中动态生成语音波形。我们基于专有的 TTS 系统设计了 Llama 3 的语音生成器,并且没有针对语音生成微调语言模型。相反,我们通过在推理时利用 Llama 3 词嵌入来专注于改进语音合成的延迟、准确性和自然度。语音界面如图 28 和 29 所示。
8.1 数据
8.1.1 语音理解
训练数据可以分为两类。预训练数据包括大量的未标记语音,用于以自我监督的方式初始化语音编码器。有监督的微调数据包括语音识别、语音翻译和口语对话数据;这些数据用于在与大型语言模型集成时解锁特定的能力。
预训练数据: 为了预训练语音编码器,我们整理了一个包含约1500万小时语音记录的数据集,涵盖多种语言。 我们使用语音活动检测 (VAD) 模型过滤音频数据,并选择 VAD 阈值高于 0.7 的音频样本进行预训练。 在语音预训练数据中,我们还重点确保不存在个人身份信息 (PII)。 我们使用 Presidio Analyzer 来识别此类 PII。
语音识别和翻译数据: 我们的 ASR 训练数据包含 23 万小时的手写转录语音记录,涵盖 34 种语言。 我们的 AST 训练数据包含 90,000 小时的双向翻译:从 33 种语言到英语以及从英语到 33 种语言。这些数据包含监督和使用 NLLB 工具包 (NLLB Team 等人,2022) 生成的合成数据。 使用合成 AST 数据可以提高低资源语言的模型质量。 我们数据中的语音片段最大长度为 60 秒。
口语对话数据: 为了微调用于口语对话的语音适配器,我们通过询问语言模型对这些提示的转录做出回应来合成语音提示的回复 (Fathullah 等人,2024)。 我们使用 ASR 数据集的子集(包含 60,000 小时的语音)以这种方式生成合成数据。
此外,我们还通过在用于微调 Llama 3 的数据子集上运行 Voicebox TTS 系统 (Le 等人,2024) 生成了 25,000 小时的合成数据。 我们使用了几种启发式方法来选择与语音分布相匹配的微调数据的子集。这些启发式方法包括关注相对较短且结构简单的提示,并且不包含非文本符号。
8.1.2 语音生成
语音生成数据集主要包括用于训练文本规范化(TN)模型和韵律模型(PM)的数据集。两种训练数据都通过添加 Llama 3 词嵌入作为额外的输入特征进行增强,以提供上下文信息。
文本规范化数据。我们的 TN 训练数据集包含 5.5 万个样本,涵盖了广泛的符号类别(例如,数字、日期、时间),这些类别需要非平凡的规范化。每个样本由书面形式文本和相应的规范化口语形式文本组成,并包含一个推断的手工制作的 TN 规则序列,用于执行规范化。
声韵模型数据。PM 训练数据包括从一个包含 50,000 小时的 TTS 数据集提取的语言和声韵特征,这些特征与专业配音演员在录音室环境中录制的文字稿件和音频配对。
Llama 3 嵌入。Llama 3 嵌入取自第 16 层解码器输出。我们仅使用 Llama 3 8B 模型,并提取给定文本的嵌入(即 TN 的书面输入文本或 PM 的音频转录),就像它们是由 Llama 3 模型在空用户提示下生成的。在一个样本中,每个 Llama 3 标记序列块都明确地与 TN 或 PM 本地输入序列中的相应块对齐,即 TN 特定的文本标记(由 Unicode 类别区分)或语音速率特征。这允许使用 Llama 3 标记和嵌入的流式输入训练 TN 和 PM 模块。
8.2 模型架构
8.2.1 语音理解
在输入方面,语音模块由两个连续的模块组成:语音编码器和适配器。语音模块的输出直接作为标记表示输入到语言模型中,使语音和文本标记能够直接交互。此外,我们引入了两个新的特殊标记,用于包含语音表示序列。语音模块与视觉模块(见第7节)有显著不同,后者通过交叉注意力层将多模态信息输入到语言模型中。相比之下,语音模块生成的嵌入可以无缝集成到文本标记中,使语音接口能够利用Llama 3语言模型的所有功能。
语音编码器:我们的语音编码器是一个拥有10亿参数的Conformer模型(Gulati等,2020)。模型的输入由80维的梅尔频谱图特征组成,这些特征首先通过一个步幅为4的堆叠层处理,然后通过线性投影将帧长度缩减到40毫秒。处理后的特征由一个包含24个Conformer层的编码器处理。每个Conformer层具有1536的潜在维度,包括两个维度为4096的Macron-net风格的前馈网络、一个核大小为7的卷积模块,以及一个具有24个注意力头的旋转注意力模块(Su等,2024)。
语音适配器:语音适配器包含约1亿参数。它由一个卷积层、一个旋转Transformer层和一个线性层组成。卷积层的核大小为3,步幅为2,旨在将语音帧长度减少到80毫秒。这允许模型向语言模型提供更粗粒度的特征。Transformer层的潜在维度为3072,前馈网络的维度为4096,进一步处理经过卷积下采样后的语音信息。最后,线性层将输出维度映射到与语言模型嵌入层匹配。
8.2.2 语音生成
我们在语音生成的两个关键组件中使用了Llama 3 8B的嵌入:文本标准化和韵律建模。文本标准化(TN)模块通过将书面文本上下文地转换为口语形式来确保语义正确性。韵律建模(PM)模块通过使用这些嵌入预测韵律特征来增强自然性和表现力。这两个组件协同工作,实现了准确而自然的语音生成。
**文本标准化**:作为生成语音语义正确性的决定因素,文本标准化(TN)模块进行从书面文本到相应口语形式的上下文感知转换,这些口语形式最终由下游组件进行口头化。例如,根据语义上下文,书面形式的“123”可能被读作基数(one hundred twenty three)或逐个数字拼读(one two three)。TN系统由一个流式的基于LSTM的序列标记模型组成,该模型预测用于转换输入文本的手工制作的TN规则序列(Kang等,2024)。该神经模型还通过交叉注意力接收Llama 3嵌入,以利用其中编码的上下文信息,使得最少的文本标记前瞻和流式输入/输出成为可能。
**韵律建模**:为了增强合成语音的自然性和表现力,我们集成了一个仅解码Transformer架构的韵律模型(PM)(Radford等,2021),该模型将Llama 3嵌入作为额外输入。这种集成利用了Llama 3的语言能力,使用其文本输出和中间嵌入(Devlin等,2018;Dong等,2019;Raffel等,2020;Guo等,2023)来增强韵律特征的预测,从而减少了模型所需的前瞻。PM集成了多个输入组件来生成全面的韵律预测:从上文详细介绍的文本标准化前端得出的语言特征、标记和嵌入。PM预测三个关键的韵律特征:每个音素的对数持续时间、对数基频(F0)平均值和音素持续时间内的对数功率平均值。模型由一个单向Transformer和六个注意力头组成。每个块包括交叉注意力层和具有864隐藏维度的双全连接层。PM的一个显著特征是其双重交叉注意力机制,一层专用于语言输入,另一层专用于Llama嵌入。该设置有效地管理了不同输入速率,而无需显式对齐。
8.3 训练方案
8.3.1 语音理解
语音模块的训练分两个阶段进行。第一阶段,语音预训练,利用未标记数据训练一个语音编码器,该编码器在语言和声学条件方面表现出强大的泛化能力。第二阶段,监督微调,适配器和预训练编码器与语言模型集成,并与其联合训练,而LLM保持冻结状态。这使得模型能够响应语音输入。此阶段使用对应语音理解能力的标记数据。
多语言 ASR 和 AST 建模常常导致语言混淆/干扰,从而降低性能。一种流行的缓解方法是在源端和目标端都加入语言识别(LID)信息。这可以在预先确定的方向上提高性能,但同时也可能导致泛化能力下降。例如,如果一个翻译系统期望在源端和目标端都提供 LID 信息,那么该模型不太可能在训练中未见过的方向上表现出良好的零样本性能。因此,我们的挑战在于设计一个允许一定程度 LID 信息的系统,同时保持模型足够通用,以便在未见的方向进行语音翻译。为了解决这个问题,我们设计了仅包含要输出文本(目标端)的 LID 信息的系统提示。这些提示中没有语音输入(源端)的 LID 信息,这也可能使其能够处理代码切换语音。对于 ASR,我们使用以下系统提示:用{语言}重复我的话:,其中{语言}来自 34 种语言之一(英语、法语等)。对于语音翻译,系统提示为:“将以下句子翻译成{语言}:”。这种设计已被证明能够有效地提示语言模型以期望的语言进行响应。我们在训练和推理过程中使用相同的系统提示。
我们使用自监督式 BEST-RQ 算法(Chiu 等,2022)对语音进行预训练。
编码器采用长度为 32 帧的掩码,对输入 mel 谱图的概率为 2.5%。如果语音话语超过 60 秒,我们将随机裁剪 6K 帧,对应 60 秒的语音。通过堆叠 4 个连续帧、将 320 维向量投影到 16 维空间,并在 8192 个向量的代码库内使用余弦相似度度量进行最近邻搜索,对 mel 谱图特征进行量化。为了稳定预训练,我们采用 16 个不同的代码库。投影矩阵和代码库随机初始化,在模型训练过程中不更新。多软最大损失仅用于掩码帧,以提高效率。编码器经过 50 万步训练,全局批处理大小为 2048 个语音。
监督微调。预训练语音编码器和随机初始化的适配器在监督微调阶段与 Llama 3 联合优化。语言模型在此过程中保持不变。训练数据是 ASR、AST 和对话数据的混合。Llama 3 8B 的语音模型经过 650K 次更新训练,使用全局批大小为 512 个话语和初始学习率为 10。Llama 3 70B 的语音模型经过 600K 次更新训练,使用全局批大小为 768 个话语和初始学习率为 4 × 10。
8.3.2 语音生成
为了支持实时处理,韵律模型采用了一个前瞻机制,该机制考虑了固定数量的未来音位和可变数量的未来标记。 这确保在处理传入文本时保持一致的前瞻,这对于低延迟语音合成应用程序至关重要。
训练: 我们开发了一种利用因果掩码的动态对齐策略,以促进语音合成的流式传输。该策略结合了韵律模型中的前瞻机制,用于固定数量的未来音位和可变数量的未来标记,与文本规范化过程中的分块过程相一致(第 8.1.2 节)。
对于每个音位,标记前瞻包括块大小定义的最大标记数,导致 Llama 嵌入具有可变前瞻,而音位具有固定前瞻。
Llama 3 嵌入来自 Llama 3 8B 模型,在韵律模型训练期间保持冻结。输入电话率特征包括语言和说话人/风格可控性元素。模型训练使用批量大小为 1,024 个语调的 AdamW 优化器,学习率为 9 × 10 -4,训练超过 100 万次更新,前 3,000 次更新进行学习率预热,然后遵循余弦调度。
推理: 在推理过程中,使用相同的前瞻机制和因果掩码策略,以确保训练与实时处理之间的一致性。PM 以流式方式处理传入文本,为电话率特征逐个更新输入电话,为标记率特征逐块更新输入。只有当该块的第一个电话当前时才更新新的块输入,从而在训练期间保持对齐和前瞻。
为了预测韵律目标,我们采用了一种延迟模式方法(Kharitonov 等人,2021),这增强了模型捕获和复制长程韵律依赖关系的能力。这种方法有助于合成的语音的自然度和表达力,确保低延迟和高质量输出。
8.4 语音理解结果
我们评估了 Llama 3 语音界面的语音理解能力,包括三个任务:(1) 自动语音识别 (2) 语音翻译 (3) 语音问答。我们将 Llama 3 的语音界面性能与三种最先进的语音理解模型进行了比较:Whisper(Radford 等人,2023 年)、SeamlessM4T(Barrault 等人,2023 年)和 Gemini。在所有评估中,我们使用贪婪搜索来预测 Llama 3 的标记。
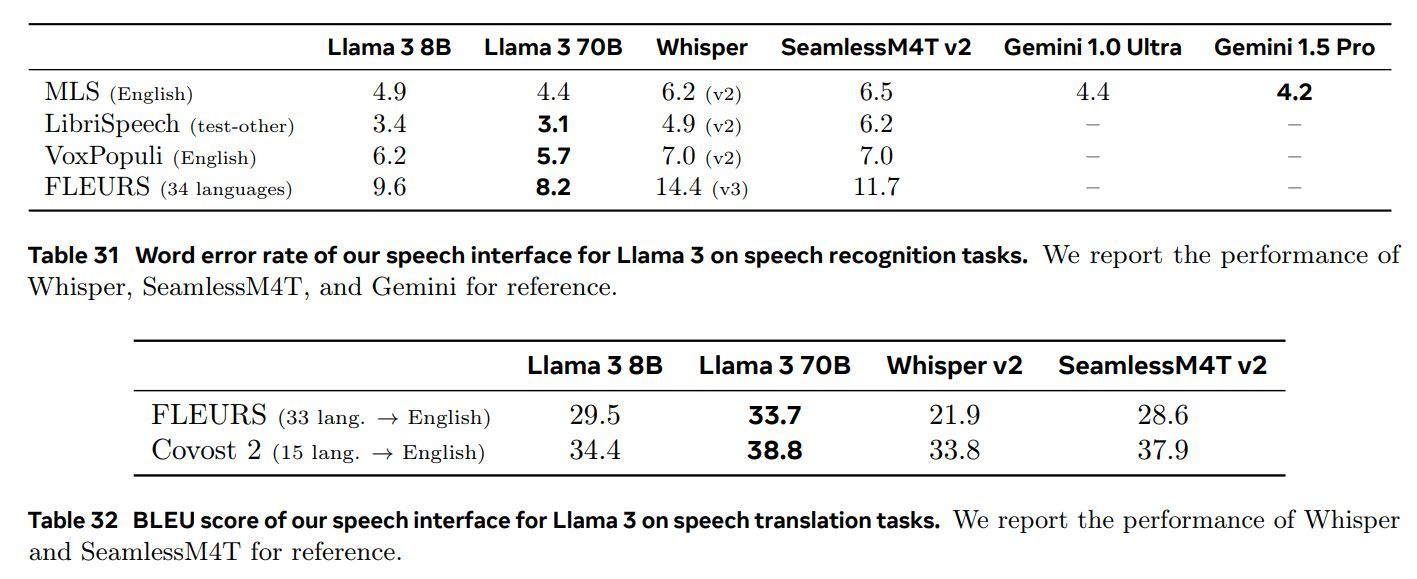
语音识别。 我们在 Multilingual LibriSpeech (MLS; Pratap 等人,2020 年)、LibriSpeech (Panayotov 等人,2015 年)、VoxPopuli (Wang 等人,2021a) 和 FLEURS 多语言数据集的子集(Conneau 等人,2023 年)上的英文数据集上评估了 ASR 性能。在评估中,使用 Whisper 文本标准化程序对解码结果进行后处理,以确保与其他模型报告的结果一致。在所有基准测试中,我们在这些基准测试的标准测试集上测量 Llama 3 语音界面的单词错误率,除了中文、日语、韩语和泰语,我们报告了字符错误率。
表 31 显示了 ASR 评估结果。它证明了 Llama 3(以及更广泛的多模态基础模型)在语音识别任务上的强劲性能:我们的模型在所有基准测试中都优于 Whisper20 和 SeamlessM4T 等专门针对语音的模型。在 MLS 英文方面,Llama 3 的表现与 Gemini 相似。
语音翻译。 我们还评估了我们的模型在语音翻译任务中的性能,其中模型被要求将非英语语音翻译成英语文本。我们在这些评估中使用 FLEURS 和 Covost 2 (Wang 等人,2021b) 数据集,并测量翻译英文的 BLEU 分数。表 32 展示了这些实验的结果。我们的模型在语音翻译方面的性能突显了多模态基础模型在语音翻译等任务中的优势。
语音问答。 Llama 3 的语音界面展示出惊人的问题回答能力。该模型可以毫不费力地理解代码切换的语音,而无需事先接触此类数据。值得注意的是,尽管该模型仅在单轮对话上进行了训练,但它能够进行扩展且连贯的多轮对话会话。图 30 展示了一些突显这些多语言和多轮能力的例子。
安全性。 我们在 MuTox (Costa-jussà 等人,2023 年) 上评估了我们语音模型的安全性能,这是一个包含 20,000 个英语和西班牙语语段以及 4,000 个其他 19 种语言语段的用于多语言基于音频的数据集,每个语段都有毒性标签。将音频作为输入传递给模型,并在清除一些特殊字符后评估输出的毒性。我们将 MuTox 分类器(Costa-jussà 等人,2023 年)应用于 Gemini 1.5 Pro 并比较结果。我们评估了当输入提示安全而输出有毒时添加毒性 (AT) 的百分比,以及当输入提示有毒而答案安全时丢失毒性 (LT) 的百分比。表 33 显示了英语的結果以及我们在所有 21 种语言上的平均结果。添加毒性百分比非常低:我们的语音模型在英语方面具有最低的添加毒性百分比,不到 1%。它去除的毒性远多于添加的毒性。
8.5 语音生成结果
在语音生成方面,我们专注于评估使用 Llama 3 向量进行文本规范化和韵律建模任务的基于标记流式输入模型的质量。评估重点在于与不将 Llama 3 向量作为额外输入的模型进行比较。
文本规范化: 为了衡量 Llama 3 向量的影响,我们尝试改变模型使用的右侧上下文量。我们使用 3 个文本规范化(TN)标记(以 Unicode 类别分隔)的右侧上下文训练了模型。这个模型与不使用 Llama 3 向量、使用 3 个标记右侧上下文或完整双向上下文的模型进行了比较。正如预期的那样,表 34 显示使用完整的右侧上下文可以提高不使用 Llama 3 向量的模型的性能。然而,包含 Llama 3 向量的模型优于所有其他模型,从而实现了无需依赖输入中的长上下文即可进行标记率输入/输出流式传输。我们比较了有或没有 Llama 3 8B 向量以及使用不同右侧上下文值的模型。
韵律建模: 为了评估我们的韵律模型(PM)与 Llama 3 8B 的性能,我们进行了两组人类评价,比较了有和没有 Llama 3 向量的模型。评分者聆听来自不同模型的样本,并表示他们的偏好。
要生成最终的语音波形,我们使用了一种基于 Transformer 的内部声学模型(Wu 等人,2021),它预测谱特征,并使用 WaveRNN 神经声码器(Kalchbrenner 等人,2018)生成最终的语音波形。
首先,我们将直接与不使用 Llama 3 向量的流式基准模型进行比较。在第二项测试中,将 Llama 3 8B PM 与不使用 Llama 3 向量的非流式基准模型进行了比较。如表 35 所示,Llama 3 8B PM 被优选了 60% 的时间(与流式基准相比),并且 63.6% 的时间被优选(与非流式基准相比),这表明感知质量有显著提高。 Llama 3 8B PM 的关键优势在于其基于标记的流式传输能力(第 8.2.2 节),它在推理过程中保持低延迟。这降低了模型的前瞻需求,使模型能够实现更具响应性和实时性的语音合成,相比于非流式基准模型。总体而言,Llama 3 8B 韵律模型始终优于基准模型,证明了其在提高合成语音的自然度和表现力方面的有效性。
9 相关工作
Llama 3 的开发建立在对语言、图像、视频和语音基础模型的大量先前研究之上。本文范围不包括对这些工作的全面概述;我们建议读者参考 Bordes 等人 (2024);Madan 等人 (2024);Zhao 等人 (2023a) 以获取这样的概述。下面,我们将简要概述直接影响 Llama 3 开发的开创性著作。
9.1 语言
规模: Llama 3 遵循着将简单方法应用于不断增大的规模的持久趋势,这是基础模型的特征。改进是由计算能力的提高和数据质量的提升驱动的,其中405B 模型使用的预训练计算预算几乎是Llama 2 70B 的五十倍。尽管我们的最大 Llama 3 包含405B 个参数,但实际上其参数数量少于早期且性能更差的模型,例如 PALM (Chowdhery 等人,2023),这是由于对缩放定律(Kaplan 等人,2020;Hoffmann 等人,2022)有了更好的理解。其他前沿模型的大小,如 Claude 3 或 GPT 4(OpenAI,2023a),公开信息有限,但总体性能相当。
小规模模型: 小规模模型的发展与大规模模型的发展同步进行了。参数较少的模型可以显著提高推理成本并简化部署(Mehta 等人,2024;Team 等人,2024)。较小的 Llama 3 模型通过远远超过计算最优训练点来实现这一目标,有效地将训练计算权衡为推理效率。另一种途径是将较大模型蒸馏成较小模型,如 Phi(Abdin 等人,2024)。
架构: 与 Llama 2 相比,Llama 3 在架构上做了最小的修改,但其他最近的基础模型探索了其他设计。最值得注意的是,专家混合架构(Shazeer 等人,2017;Lewis 等人,2021;Fedus 等人,2022;Zhou 等人,2022)可以作为有效地提高模型容量的一种方法,例如在 Mixtral(Jiang 等人,2024)和 Arctic(Snowflake,2024)中。Llama 3 的性能优于这些模型,这表明密集架构并不是限制因素,但在训练和推理效率、以及大规模下的模型稳定性方面仍然存在许多权衡。
开源: 开源基础模型在过去一年中迅速发展,其中 Llama3-405B 现在与当前闭源的最先进水平相当。最近开发了许多模型系列,包括 Mistral(Jiang 等人,2023)、Falcon(Almazrouei 等人,2023)、MPT(Databricks,2024)、Pythia(Biderman 等人,2023)、Arctic(Snowflake,2024)、OpenELM(Mehta 等人,2024)、OLMo(Groeneveld 等人,2024)、StableLM(Bellagente 等人,2024)、OpenLLaMA(Geng 和 Liu,2023)、Qwen(Bai 等人,2023)、Gemma(Team 等人,2024)、Grok(XAI,2024)和 Phi(Abdin 等人,2024)。
后训练: Llama 3 的后训练遵循了既定的指令调整策略(Chung 等人,2022;Ouyang 等人,2022),接着是与人类反馈进行对齐(Kaufmann 等人,2023)。尽管一些研究表明轻量级对齐程序的效果出乎意料(Zhou 等人,2024),但 Llama 3 使用数百万个人类指令和偏好判断来改进预训练模型,包括拒绝采样(Bai 等人,2022)、监督微调(Sanh 等人,2022)和直接偏好优化(Rafailov 等人,2023)。为了策划这些指令和偏好示例,我们部署了更早版本的 Llama 3 来过滤(Liu 等人,2024c)、重写(Pan 等人,2024)或生成提示和响应(Liu 等人,2024b),并将这些技术通过多轮后训练应用。
9.2 多模态性
我们的 Llama 3 多模态能力实验是关于联合建模多个模态的基础模型长期研究的一部分。我们的 Llama 3 方法结合了许多论文中的想法,取得了与 Gemini 1.0 Ultra(谷歌,2023 年)和 GPT-4 Vision(OpenAI,2023b)相当的结果;请参见第 7.6 节。
视频:尽管越来越多的基础模型支持视频输入(谷歌,2023 年; OpenAI,2023b),但关于视频和语言联合建模的研究并不多。类似于 Llama 3,目前大多数研究都采用适配器方法来对齐视频和语言表示,并解开有关视频的问答和推理(Lin 等人,2023 年;Li 等人,2023a;Maaz 等人,2024 年;Zhang 等人,2023 年;Zhao 等人,2022 年)。我们发现此类方法产生的结果与最先进的结果具有竞争力;请参见第 7.7 节。
语音:我们的工作也融入了一项更大的工作,该工作结合了语言和语音建模。早期的文本和语音联合模型包括 AudioPaLM(Rubenstein 等人,2023 年)、VioLA(Wang 等人,2023b)、VoxtLM Maiti 等人(2023 年), SUTLM(Chou 等人,2023 年)和 Spirit-LM(Nguyen 等人,2024 年)。我们的工作基于 Fathullah 等人(2024 年)等先前组合语音和语言的组成方法。与大多数先前的工作不同,我们选择不针对语音任务对语言模型本身进行微调,因为这样做可能会导致非语音任务的竞争。我们发现,即使没有这样的微调,在更大的模型规模下也能取得良好的性能;请参见第 8.4 节。
10 结论
高品质基础模型的开发仍处于初期阶段。我们开发Llama 3的经验表明,这些模型未来还有很大的改进空间。在开发Llama 3模型家族的过程中,我们发现强烈的关注高质量数据、规模和简单性始终能带来最佳结果。在初步实验中,我们探索了更复杂模型架构和训练方案,但并没有发现这些方法的优势能够超过它们在模型开发中引入的额外复杂性。
开发像Llama 3这样的旗舰基础模型不仅需要克服许多深层次的技术问题,还需要做出明智的组织决策。例如,为了确保Llama 3不会意外过度拟合于常用基准测试,我们的预训练数据由一个独立的团队采购和处理,该团队被强烈激励防止将外部基准测试与预训练数据污染。另一个例子是,我们确保人类评估的可信度,只允许一小部分不参与模型开发的研究人员执行和访问这些评估。虽然这些组织决策在技术论文中很少被讨论,但我们发现它们对于Llama 3模型家族的成功开发至关重要。
我们分享了我们的开发过程细节,因为我们相信这将有助于更广泛的研究社区了解基础模型开发的关键因素,并为公众关于基础模型未来发展进行更有见地的讨论做出贡献。我们还分享了将多模态功能整合到Llama 3中的初步实验结果。虽然这些模型仍在积极开发中,尚未准备好发布,但我们希望尽早分享我们的结果可以加速该方向的研究。
鉴于本文中详细的安全分析取得的积极成果,我们将公开发布我们的Llama 3语言模型,以加速为众多社会相关用例开发人工智能系统的进程,并使研究界能够审查我们的模型并找到使这些模型更好、更安全的途径。我们相信基础模型的公开发布对于此类模型的负责任发展至关重要,并且我们希望Llama 3的发布可以鼓励整个行业拥抱开放、负责任的人工智能开发。

