
- 1AI基本概念和应用_ai应用基础
- 24 个实用示例帮助你掌握 JavaScript 中Proxy功能_proxy(array)
- 3微软商店错误代码: 0x80131500解决方案
- 4Socket编程详解
- 5WPS 手动去除广告_ksomisc启动项
- 6微软登录界面加载不出_微软为何把Office365改名为Microsoft365? Part 1
- 7阿里云服务器迁移数据到新账号简单教程_阿里云转移服务器到新账号
- 8pytorch神经网络学习笔记03----几种网络的维度计算_神经网络维度计算
- 9【毕业设计选题】基于深度学习的柑橘果实目标检测系统 YOLO python 卷积神经网络 人工智能_柑橘内部品质检测毕业设计
- 10百面嵌入式专栏(面试题)内存管理相关面试题1.0
人工智能趋势与深度学习算法_人工智能的图论算法
赞
踩
人工智能趋势与深度学习算法
内容也和前面的机器学习简要概览和论文写作概述一样,是关于网上一个免费小课(来自点头AI)的整理。
1 前沿技术
1.1 Transformer模型:
由Google的Ashish Vaswani等人和多伦多大学的Aidan N.Gomez于2017年首次提出,是一种基于自注意力机制(在Transformer模型中起基础作用,可减少对外部信息的依赖,更擅长捕捉数据或特征的内部关系,优化模型训练结果)的深度学习模型.
该模型主要由编码器和解码器构成,模型本身并行度较高,在精度和性能上均要优于传统的循环神经网络(RNN)和卷积神经网络(CNN)。
Transformer模型在简单语言问答和语言建模任务上有着较好表现。
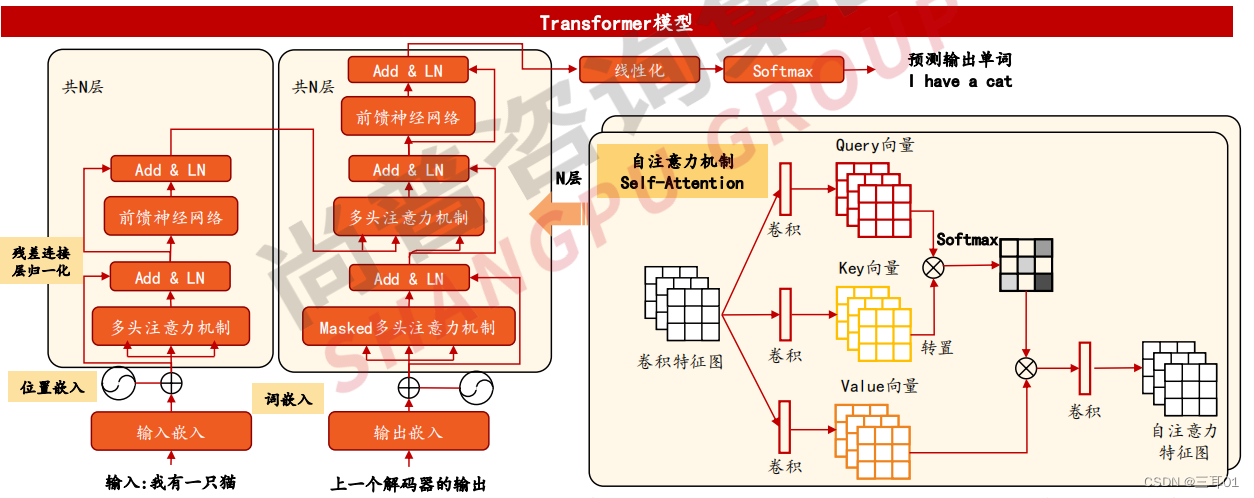
1.2 BERT模型:基于Transformer Encoder构建的预测模型
由Google于2018年提出,是基于Transformer Encoder构建的一种模型。
模型基本思想:给定上下文来预测下一个词。
BERT模型架构是由多接口组成的Transformer编码器层,即全连接神经网络增加自注意力机制。对于序列中的每个输入标记,每个接口计算键、 值和查询向量,相关向量用于创建加权表示,合并同一层中所有接口输出并通过全连接层运行。每个层使用跳跃连接进行包装,之后将层归一化处理。
1.3 自监督学习(Self-supervised Learning)
旨在对于无标签数据,通过设计辅助任务来挖掘数据自身的表征特性作为监督信息,来提升模型的特征提取能力,是一种将无监督问题转化为有监督问题的方法。

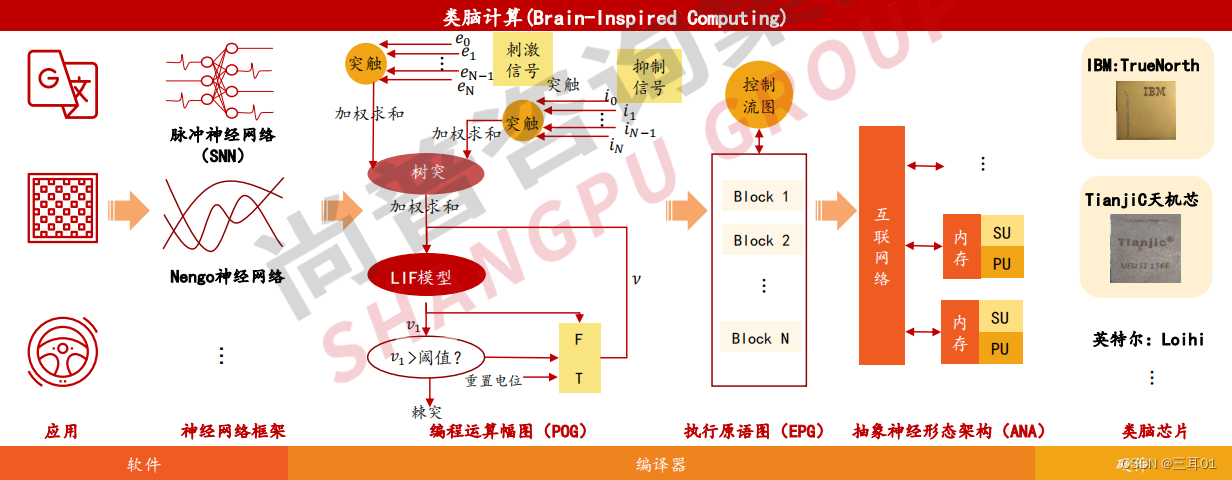
1.4 类脑计算(Brain-Inspired Computing)
又称神经形态计算,是借鉴生物神经系统信息处理模式和结构的计算理论、体系结构、芯片设计以及应用模型与算法的总称。类脑计算可模拟人类大脑信息处理方式,以极低的功耗对信息进行异步、并行、高速和分布式处理,并具备自主感知、识别和学习等多种能力,是实现通用人工智能的途径之一。
模拟大脑结构和信息加工过程,提高机器认知能力、降低运行功耗。
1.5 AI大模型(Foundation Models)
是指经过大规模数据训练且在经微调后即可适应广泛下游任务的模型。随着参数规模不断扩大,AI大模型在语言、视觉、推理、人机交互等领域涌现出新能力。
包含了万亿量级参数的预训练模型,显著降低模型训练成本。

2 产业融合
2.1 人工智能与元宇宙
人工智能作为元宇宙时代的核心生产要素,加速元宇宙商业化落地。
元宇宙(Metaverse):本质上是对现实世界的虚拟化、数字化过程,其主要包括基础设施、人机交互、空间计算等七层架构,其中计算机视觉、AI芯片和嵌入式AI等人工智能技术及基础设施共同助力元宇宙加速落地。元宇宙涵盖芯片、云计算、技术平台、通信、智能设备、内容服务等庞大生态系统。
2.2 人工智能与生命科学
AlphaFold驱动人工智能在生命科学领域实现突破。
AlphaFold是由谷歌旗下DeepMind团队基于深度学习算法的蛋白质结构预测的人工智能系统,其被视作人工智能深入到生物领域的一大突破。目前AlphaFold已对98.5%的人类蛋白质结构做出预测,此外还对于大肠杆菌、果蝇、斑马鱼、小鼠等研究时常用生物的蛋白质结构进行预测。
2.3 人工智能与新冠疫情
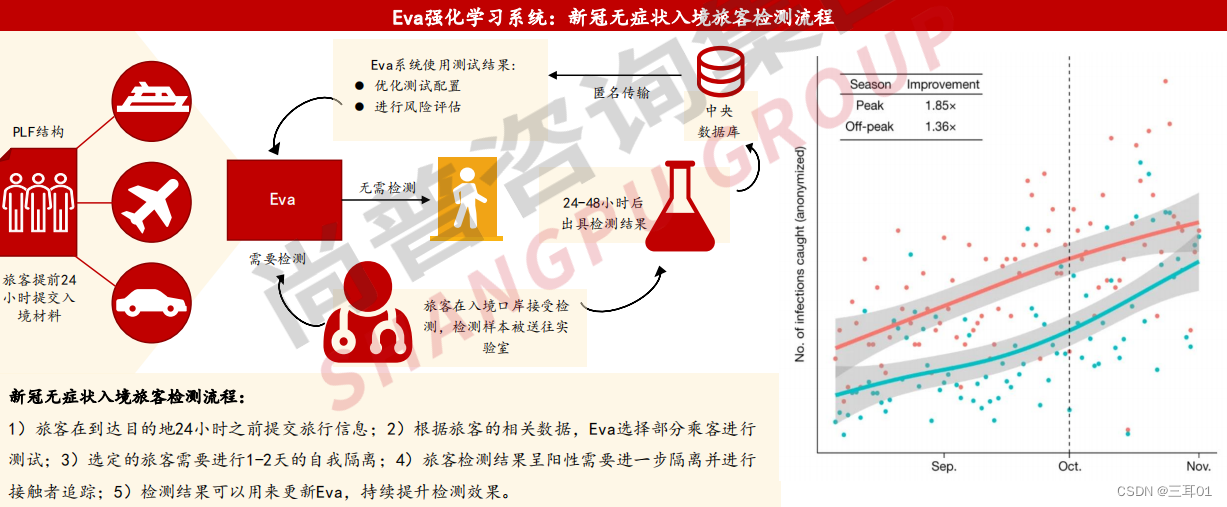
Eva强化学习系统提升入境旅客新冠病毒检测效能。
Eva是用于检测入境旅客新冠病毒的强化学习系统,其由美国南加州大学、美国宾夕法尼亚学、AgentRisk以及希腊相关专家合作开发。
2020年,Eva系统被部署到希腊所有入境口岸(机场、港口、车站等),用于识别限制新冠无症状旅客入境。
2.4 人工智能与半导体
AI与EDA紧密融合,促使芯片PPA结果更加稳定。
为使PPA优化结果更佳,同时为应对芯片安全性需求提升、设计规模攀升及工艺节点微缩等趋势,EDA厂商开始利用AI技术解决半导体芯片设计问题。在EDA中,数据快速提取模型、布局和布线、电路仿真模型、 PPA优化决策等环节均有AI技术参与。
2.5 人工智能与碳中和
人工智能在预测、监测、优化三大环节赋能碳中和。
当前,碳中和已获得全球超过40个国家和地区承诺,其中大部分国家宣布将于2050年左右实现碳中和目标。从整体来看,人工智能将从预测、监测、优化三大环节助力碳中和,如预测未来碳排放量、实时监测碳足迹、优化工作流程等。
3 神经网络与卷积神经网络
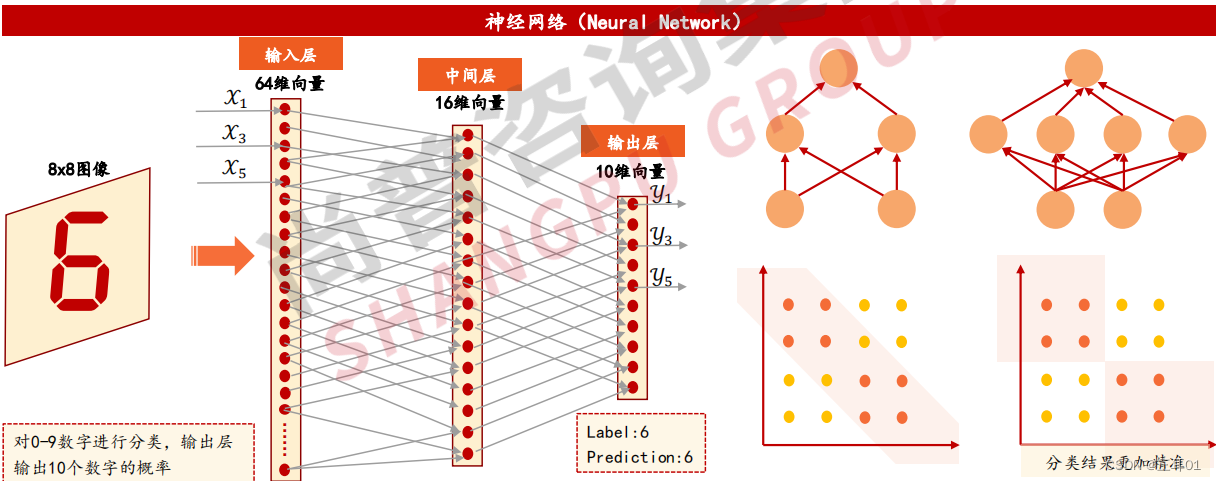
神经网络:具有适应性简单单元组成的广泛并行互联网络。
由数千甚至数百万个紧密互连的简单处理节点组成,其主要包括输入层(输入数据)、中间层/隐藏层(学习复杂决策边界)和输出层(输出结果)。
神经网络可以用于回归,但主要应用于分类问题。如下图所示:输入层表示输入图像(64维向量),中间层使用Sigmoid等非线性函数对于输入层数据进行计算,输出层使用非线性函数对于中间层数据进行计算。
神经网络通过采取设置中间层的方式,利用单一算法学习各种决策边界,调节中间层数量以及层的深度,神经网络可学习更复杂的边界特征,而得出更加准确的结果。
卷积神经网络(Convolutional Neural Network,CNN):以图像识别为核心的深度学习算法。
由数千甚至数百万个紧密互连的简单处理节点组成,其主要包括输入层、卷积层、池化层、全连接层和输出层,适合处理图片、视频等类型数据。
1980年,日本科学家福岛邦彦提出一个包含卷积层、池化层的神经网络结构。在此基础上,Yann Lecun将BP算法应用到该神经网络结构的训练上,形成当代卷积神经网络的雏形;1988年,Wei Zhang提出第一个二维卷积神经网络:平移不变人工神经网络(SIANN),并将其应用于检测医学影像;1998年Yann LeCun及其合作者构建了更加完备的卷积神经网络LeNet-5并在手写数字的识别问题中取得成功。
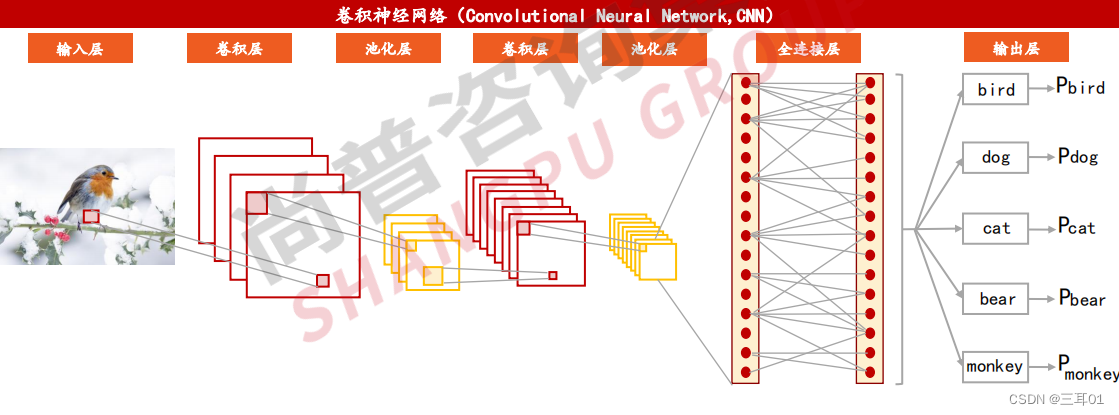
卷积层:图片输入转化成RGB对应的数字,然后通过卷积核做卷积,目的是提取输入中的主要特征,卷积层中使用同一卷积核对每个输入样本进行卷积操作;
池化层:作用在于减小卷积层产生的特征图尺寸(压缩特征映射图尺寸有助于降低后续网络处理的负载);
全连接层:计算激活值然后通过激活函数计算各单元输出值(激活函数包括Sigmoid、tanh、ReLU等);
输出层:使用似然函数计算各类别似然概率。
4 循环神经网络与图神经网络
循环神经网络(Recurrent Neural Network,RNN):用于处理序列数据的神经网络。
是一类以序列数据(指相互依赖的数据流,比如时间序列数据、信息性的字符串、对话等)为输入,在序列的演进方向进行递归且所有节点(循环单元)按链式连接的神经网络。目前,语言建模和文本生成、机器翻译、语音识别、生成图像描述、视频标记是RNN应用最多的领域。
图神经网络(Graph Neural Networks,GNN):用于处理图结构数据的神经网络。
将图数据和神经网络进行结合,在图数据上面进行端对端的计算,具备端对端学习、擅长推理、可解释性强的特点。
图神经网络发展出多个分支,主要包括图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络等。
图神经网络的训练框架如下:首先,每个节点获取其相邻节点的所有特征信息,将聚合函数(如求和或取平均)应用于这些信息。 聚合函数的选择必须不受节点顺序和排列的影响。之后,将前一步得到的向量传入一个神经网络层(通常是乘以某个矩阵),然后使用非线性激活函数(如ReLU)来获得新的向量表示。
目前,图神经网络在许多领域的实际应用中都展现出强大的表达能力和预测能力,如物理仿真、科学研究、生物医药、金融风控等。
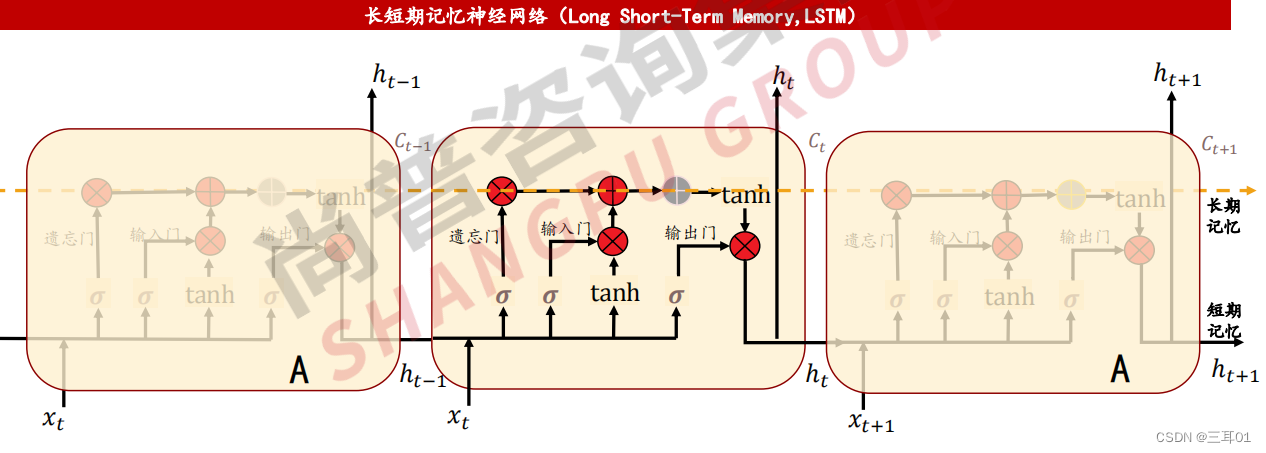
5 长短期记忆神经网络(Long Short-Term Memory,LSTM)
长短期记忆神经网络:在RNN中加入门控机制,解决梯度消失问题。
LSTM是一种特殊的循环神经网络(RNN)。传统RNN在训练中,随着训练时间的加长和层数的增多,很容易出现梯度爆炸或梯度消失问题,导致无法处理长序列数据,LSTM可有效解决传统RNN“长期依赖”问题。
LSTM由状态单元、输入门(决定当前时刻网络的输入数据有多少需要保存到单元状态)、遗忘门(决定上一时刻的单元状态有多少需要保留到当前时刻)、输出门(控制当前单元状态有多少需要输出到当前输出值)组成,以此令长期记忆与短期记忆相结合,达到序列学习的目的。
LSTM应用领域主要包括文本生成、机器翻译、语音识别、生成图像描述和视频标记等。
6 自编码器(Autoencoder,AE)
自编码器:通过期望输出等同于输入样本的过程,实现对输入样本抽象特征学习。
典型深度无监督学习模型包括自编码器、受限波尔兹曼机与生成对抗网络。
自编码器:包括编码器和解码器两部分,其中编码器将高维输入样本映射到低维抽象表示,实现样本压缩与降维;解码器将抽象表示转换为期望输出,实现输入样本的复现。自码器的输入与期望输出均为无标签样本,隐藏层输出则作为样本的抽象特征表示。
自编码器仅通过最小化输入样本与重构样本之间的误差来获取输入样本的抽象特征表示,无法保证自编码器提取到样本的本质特征。为避免上述问题,需要对自编码器添加约束或修改网络结构,进而产生稀疏自编码器、去噪自编码器、收缩自编码器等改进算法。
自编码器凭借其优异的特征提取能力,主要应用于目标识别、文本分类、图像重建等诸多领域。
7 生成对抗网络(Generative Adversarial Network,GAN)
生成对抗网络:通过使用对抗训练机制对两个神经网络进行训练,避免反复应用马尔可夫链学习机制带来的配分函数计算,明显提高应用效率。
生成对抗网络包含一组相互对抗模型—判别器和生成器,判别器目的是正确区分真实数据和生成数据,使得判别准确率最大化,生成器是尽可能逼近真实数据的潜在分布。
生成器类似于造假钞的人,其制造出以假乱真的假钞,判别器类似于警察,尽可能鉴别出假钞,最终造假钞的人和警察双方在博弈中不断提升各自能力。

