
- 12023 Google 开发者大会:将大型语言模型部署到你的手机_谷歌大语言
- 2笔记:CentOS Linux release 7.6.1810安装 CUDA Toolkit_compute/cuda/repos/rhel7/x86_64/cuda-rhel7.repo
- 3unity中Input的几个方法_input.mousepresent
- 4使用 Elasticsearch 和 LlamaIndex 进行高级文本检索:句子窗口检索_liamaindex liama
- 5QT各版本源码下载_qt5.12.10源码下载
- 6软件工程填空题(50题)
- 7前端开发者:如何在没有UI设计图的情况下做出更好的前端页面_前端怎么看ui设计图
- 8YOLOv8详解代码实战,附有效果图_yolov8代码详解
- 9以太坊区块链网络部署及验证实验_以太坊私链 区块链网络实验
- 10别闹,程序员哪来的35岁危机?
caffe层解读系列-softmax_loss_ignore_label
赞
踩
Loss Function
softmax_loss的计算包含2步:
(1)计算softmax归一化概率
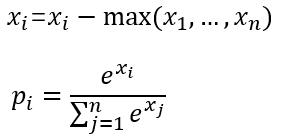
(2)计算损失
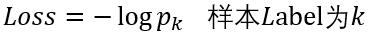
这里以batchsize=1的2分类为例:
设最后一层的输出为[1.2 0.8],减去最大值后为[0 -0.4],
然后计算归一化概率得到[0.5987 0.4013],
假如该图片的label为1,则Loss=-log0.4013=0.9130
可选参数
(1) ignore_label
int型变量,默认为空。
如果指定值,则label等于ignore_label的样本将不参与Loss计算,并且反向传播时梯度直接置0.
(2) normalize
bool型变量,即Loss会除以参与计算的样本总数;否则Loss等于直接求和
(3) normalization
enum型变量,默认为VALID,具体代表情况如下面的代码。
enum NormalizationMode {
// Divide by the number of examples in the batch times spatial dimensions.
// Outputs that receive the ignore label will NOT be ignored in computing the normalization factor.
FULL = 0;
// Divide by the total number of output locations that do not take the
// ignore_label. If ignore_label is not set, this behaves like FULL.
VALID = 1;
// Divide by the batch size.
BATCH_SIZE = 2;
//
NONE = 3;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
归一化case的判断:
(1) 如果未设置normalization,但是设置了normalize。
则有normalize==1 -> 归一化方式为VALID
normalize==0 -> 归一化方式为BATCH_SIZE
(2) 一旦设置normalization,归一化方式则由normalization决定,不再考虑normalize。
使用方法
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "fc1"
bottom: "label"
top: "loss"
top: "prob"
loss_param{
ignore_label:0
normalize: 1
normalization: FULL
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
扩展使用
(1) 如上面的使用方法中所示,softmax_loss可以有2个输出,第二个输出为归一化后的softmax概率
(2) 最常见的情况是,一个样本对应一个标量label,但softmax_loss支持更高维度的label。
当bottom[0]的输入维度为N*C*H*W时,
其中N为一个batch中的样本数量,C为channel通常等于分类数,H*W为feature_map的大小通常它们等于1.
此时我们的一个样本对应的label不再是一个标量了,而应该是一个长度为H*W的矢量,里面的数值范围为0——C-1之间的整数。
至于之后的Loss计算,则采用相同的处理。

