
- 1[WebSocket]之上层协议STOMP_stompclient.connect
- 2iphone/ipad 连接smb服务器,实现局域网内文件共享_ipad smb
- 3嵌入式软件开发工程师就业发展前景怎么样?
- 4openwrt 处理间歇性无法上网(DNS故障)问题_openwrt 间歇性断网
- 5vue3+element plus使用修改element的主题色问题_element-plus用了node-sass
- 6Epic版JustCause4(正当防卫4)0xc000007b错误解决方法_epic 0xc000007b
- 7变废为宝,用旧电脑自己DIY组建 NAS 服务器
- 8windows下内网穿透之frp使用_frp在2003系统上可以运行吗
- 9Centos7下搭建dhcp服务_centos7 yum dcphd
- 10PIDNet: A Real-time Semantic Segmentation Network Inspired by PID Controllers翻译
白话机器学习-Encoder-Decoder框架
赞
踩
一 背景
大抵是去年底吧,收到了几个公众号读者的信息,希望能写几篇介绍下Attention以及Transformer相关的算法的文章,当时的我也是满口答应了,但是确实最后耽误到了现在也没有写。
前一阵打算写这方面的文章,不过发现一个问题,就是如果要介绍Transformer,则必须先介绍Self Attention,亦必须介绍下Attention,以及Encoder-Decoder框架,以及GRU、LSTM、RNN和CNN,所以开始漫长的写作之旅。
截止目前,已经完成几篇文章的输出
- 《白话机器学习-卷积神经网络CNN》
- 《白话机器学习-循环神经网络RNN》
- 《白话机器学习-长短期记忆网络LSTM》
- 《白话机器学习-循环神经网络概述从RNN到LSTM再到GRU》
那么接下来,需要把Encoder-Decoder框架、Attention机制、Self Attention以及Transformer一一介绍了。
本文主要介绍Encoder-Decoder框架。
二 Encoder Decoder和Seq2Seq模型的关系
提起Encoder-Decoder,就不得不提Seq2Seq,两者本质上其实是同样的东西,基本可以画等号,这两个概念基本是前后脚提出来的。如果真要说它们的区别,那么主要可以总结成以下两个方面:
- Seq2Seq是抽象的理论,满足输入序列生成输出序列的模式,都可以归类为Seq2Seq模型。
- Encoder Decoder是具象的实现,强调实现,比如使用RNN、LSTM、GRU等进行实现的过程。
所以,后续的文章中,都是仅仅介绍Encoder-Decoder。
相对于传统的规整的网络布局,Encoder Decoder模型显得比较随性,不受约束,可能也正式这种自由,使得该模型在实际中发回来巨大的作用。模型结构突破了传统的固定大小输入问题的框架,将经典深度神经网络模型运用于在翻译、文本自动摘要、智能问答等情景中,并且在实际应用中有着不俗的表现。
那么我们简单总结下Encoder Decoder模型的特点,看看它到底有什么不同之处。
- Encoder将可变长度的输入序列编码成一个固定长度的向量;
- Decoder将固定长度的向量解码成一个可变长度的输出序列;
- Encoder-Decoder阶段的编码与解码的方式可以是CNN、RNN、LSTM、GRU等;
三 Encoder-Decoder结构
下面我们来剖析下Encoder-Decoder的网络结构,由于本文重点是讲解Encoder-Decoder框架,所以编解码都使用RNN为例,对CNN、LSTM、GRU感兴趣的同学请参考本公众号的《白话机器学习》系列文章,里面有详细的推导和理解。
那么一种可能的网络结构如下(对于RNN不熟悉的同学,请查看公众号前面发的文字《白话机器学习-长短期记忆网络LSTM),下面我们结合视图对于Encoder-Decoder的网路结构进行分析:
- Encoder阶段使用的编码为RNN;
- 向量C是Encoder编码阶段的最终隐藏层的状态 c t c_t ct,或是多个隐藏层状态 c t c_t ct的加权总和,作为Decoder解码阶段的初始状态;
- W是Encoder的最终输出(最后一个隐藏层的输出 h t h_t ht,作为Decoder的解码阶段初始输入。
- Decoder阶段使用的解码为LSTM,通过输出的
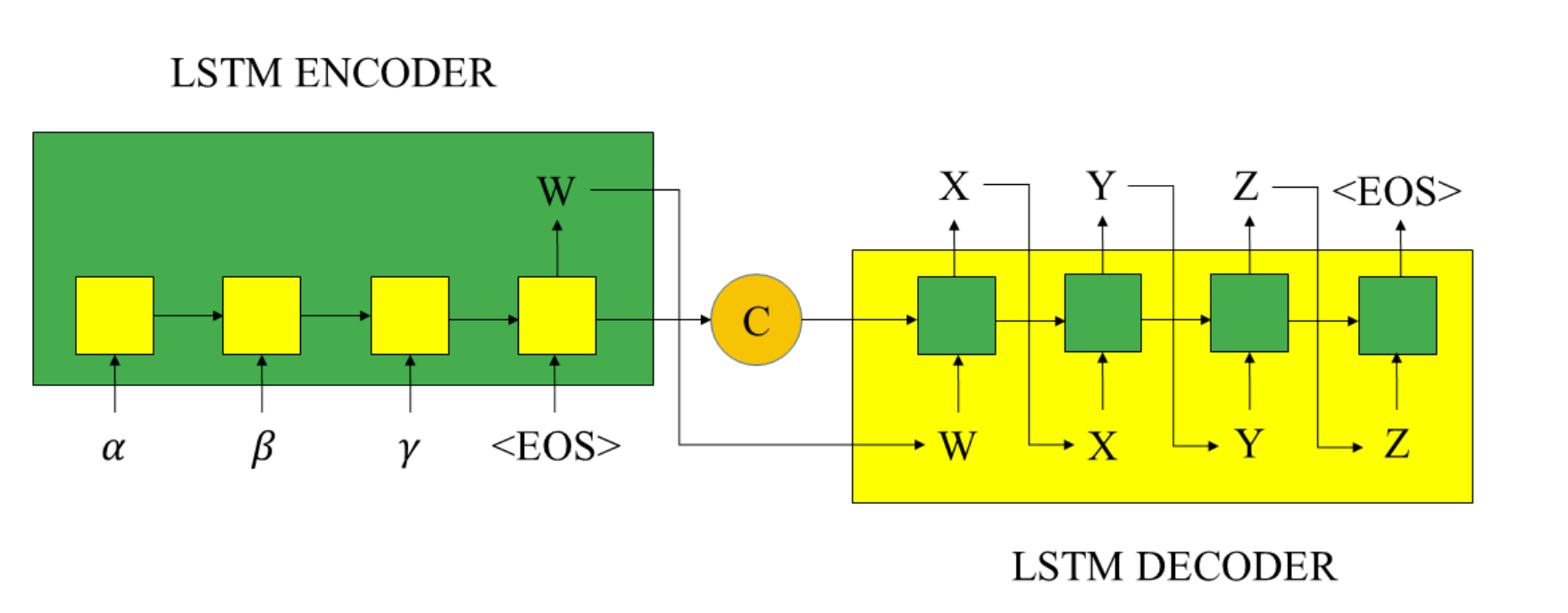
- Encoder部分
Encoder负责将输入序列压缩成指定长度的向量,这个向量就可以看成是这个序列的语义,这个过程称为编码。
如下图,获取语义向量最简单的方式就是直接将最后一个输出的隐状态作为语义向量c。也可以对最后一个隐含状态做一个变换得到语义向量,还可以将输入序列的所有隐含状态做一个变换得到语义变量。
下图c代表生成的语义向量,q函数代表相应的变换(线性变换等)
四 Encoder与Decoder流程
1 Encoder
得到各个隐藏层的输出然后汇总,生成固定长度语义向量

2 Decoder
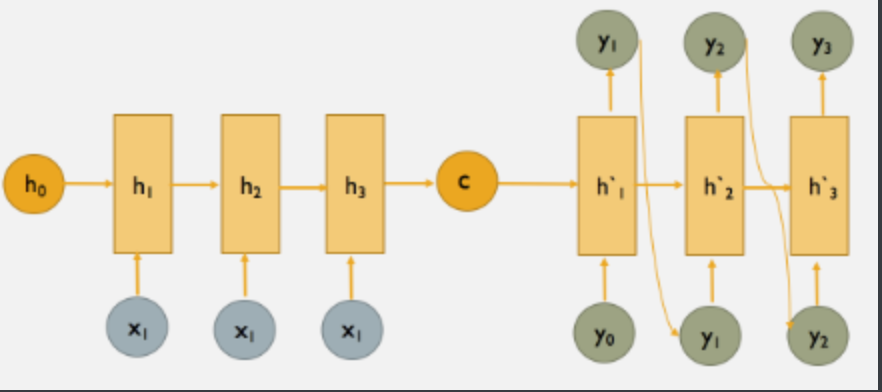
Decoder部分就是根据Encoder部分输出的语义向量c来做解码工作。以翻译为例,就是生成相应的译文。
注意生成的序列是不定长的。而且上一时刻的输出通常要作为下一时刻的输入,如下图所示,预测y2时y1要作为输入。
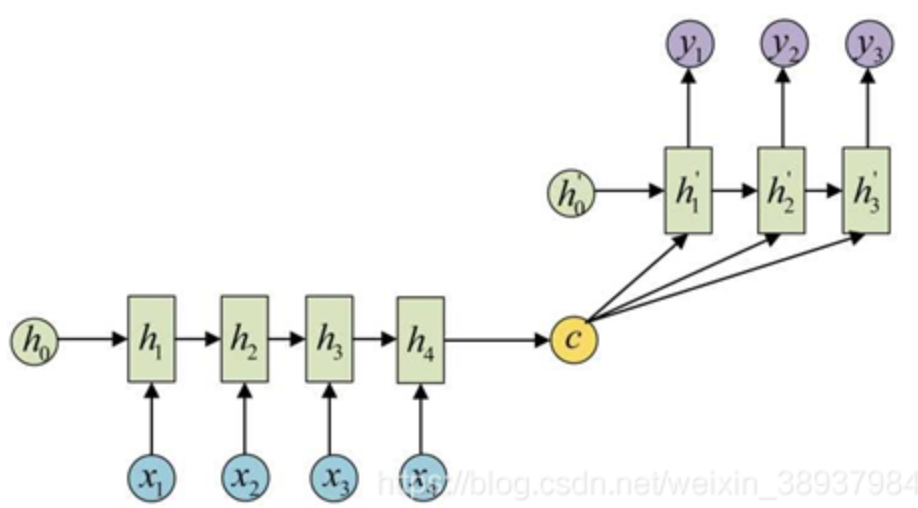
还有一种做法是将c当做每一步的输入:
五 Paper中的Encoder-Decoder解析
Cho在2014年提出了Encoder–Decoder结构,它由两个RNN组成,另外本文还提出了GRU的门结构,相比LSTM更加简洁,而且效果不输LSTM,应用较广,对GRU感兴趣的同学可以参看我上篇文章。
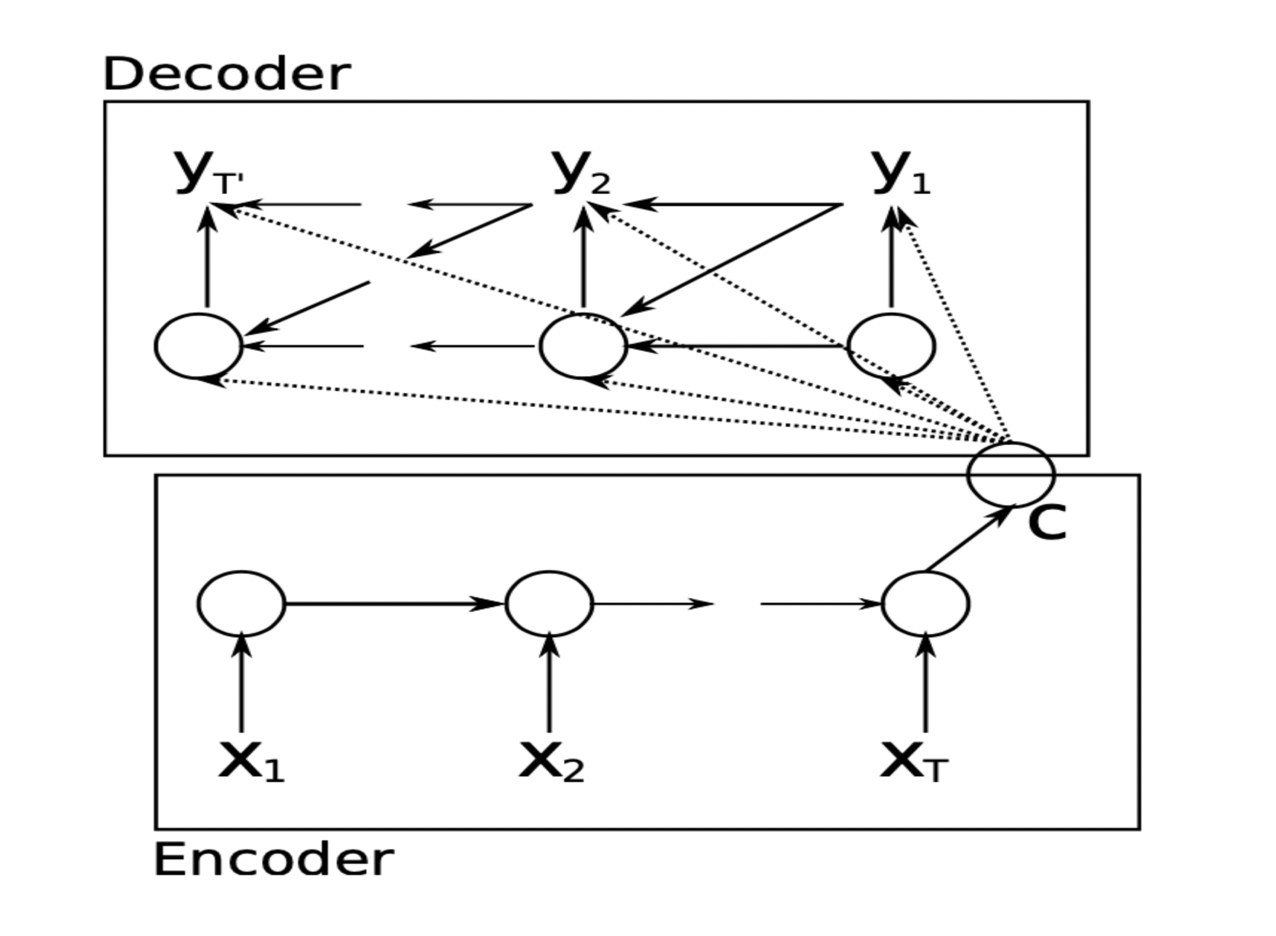
Cho提出了一种新的神经网络结构,它学习将一个可变长度的序列编码成一个固定长度的向量表示,并将一个给定的固定长度的向量表示解码回一个可变长度的序列。从概率的角度来看,这个新模型是一种学习可变长序列条件分布的一般方法。 p ( y 1 , . . . , y T ‘ ∣ ( x 1 , . . . , x T ) ) p(y_1,...,y_{T^`}|(x_1,...,x_T)) p(y1,...,yT‘∣(x1,...,xT)),需要注意的是 T ‘ 和 T T^{`}和T T‘和T是可以不一样的,即输入的长度与输出的长度可以不一致。
- Encoder阶段
Encoder阶段一个RNN,它按顺序读取输入序列x的每个符号。在读取每个符号时,RNN的隐藏状态h会发生如下变化。读取序列末尾(用序列结束符标记)后,RNN的隐藏状态是整个输入序列的汇总c。
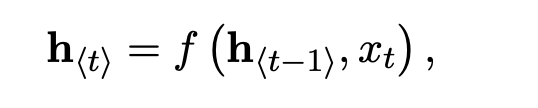
注:式中f为非线性激活函数。f可能像sigmoid函数一样简单,像长短期记忆(LSTM)单元一样复杂(Hochreiter和Schmidhuber, 1997)。
- Decoder阶段
Decoder阶段也是一个RNN,它被训练成通过预测给定隐藏状态h的下一个符号yt生成输出序列。与Encoder阶段的计算不同,在t时刻的隐藏状态h为:

同理,该时刻的条件分布概率如下

编码器-解码器的两个组成部分联合训练,以最大限度地提高条件对数似然概率
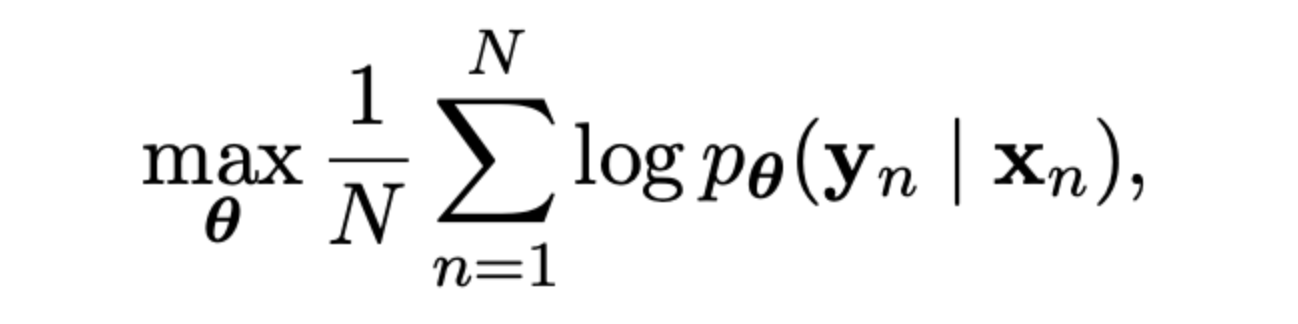
五 番外篇
个人介绍:杜宝坤,隐私计算行业从业者,从0到1带领团队构建了京东的联邦学习解决方案9N-FL,同时主导了联邦学习框架与联邦开门红业务。
框架层面:实现了电商营销领域支持超大规模的工业化联邦学习解决方案,支持超大规模样本PSI隐私对齐、安全的树模型与神经网络模型等众多模型支持。
业务层面:实现了业务侧的开门红业务落地,开创了新的业务增长点,产生了显著的业务经济效益。
个人比较喜欢学习新东西,乐于钻研技术。基于从全链路思考与决策技术规划的考量,研究的领域比较多,从工程架构、大数据到机器学习算法与算法框架均有涉及。欢迎喜欢技术的同学和我交流,邮箱:baokun06@163.com
六 公众号导读
自己撰写博客已经很长一段时间了,由于个人涉猎的技术领域比较多,所以对高并发与高性能、分布式、传统机器学习算法与框架、深度学习算法与框架、密码安全、隐私计算、联邦学习、大数据等都有涉及。主导过多个大项目包括零售的联邦学习,社区做过多次分享,另外自己坚持写原创博客,多篇文章有过万的阅读。公众号秃顶的码农大家可以按照话题进行连续阅读,里面的章节我都做过按照学习路线的排序,话题就是公众号里面下面的标红的这个,大家点击去就可以看本话题下的多篇文章了,比如下图(话题分为:一、隐私计算 二、联邦学习 三、机器学习框架 四、机器学习算法 五、高性能计算 六、广告算法 七、程序人生),知乎号同理关注专利即可。

一切有为法,如梦幻泡影,如露亦如电,应作如是观。

