
- 1国内访问ChatGPT, 并且支持回答图片!_chatf.free2gpt.xyz
- 2Spark入门(一篇就够了)
- 3ps -ef|grep命令_psefgrep命令看进程
- 4算法导论_15.3 动态规划基础_最优解的值和最优解的区别
- 5NodeJS使用淘宝 NPM 镜像/NPM使用国内源_nodejs 国内源
- 6大模型时代,自动驾驶落地还需几步?
- 7计算机毕业设计django基于python平面地图监控(源码+系统+mysql数据库+Lw文档)_python 平面图 源码
- 8在K-Means算法中使用肘部法寻找最佳聚类数_肘部法确定最佳聚类中心
- 9iOS 使用Image I/O 实现超大图片降采样
- 10pxe无盘服务器教程,[教程]Synology+PXE挂载iSCSI网络无盘启动Win7(08.04更新)
python 爬取贝壳网小区名称_Python爬虫实战:爬取贝壳网二手房40000条数据
赞
踩
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理
以下文章来源于啤酒就辣条 ,作者啤酒就辣条
一、网页分析
爬取贝壳网石家庄二手房信息,先打开链接
https://sjz.ke.com/ershoufang/。
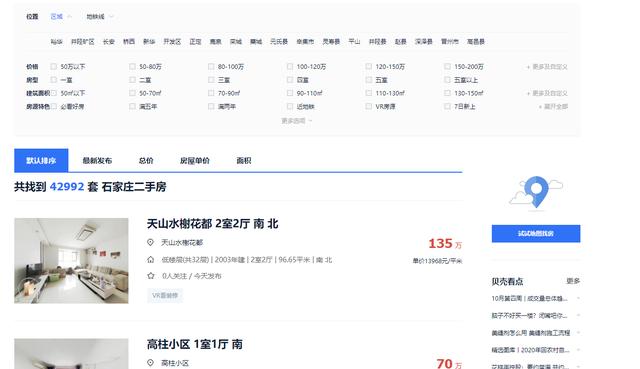
不添加筛选条件,发现总共有42817套房子。我们点击第二页,再查看链接变成了https://sjz.ke.com/ershoufang/pg2/。所以,可发现/pg{i},i就是页码。

所以最多可爬取3000套房产信息,距离上面给出的4万多差的还很远,于是尝试把pg{i}的那个i人为改变一下,点击回车请求一下。
返回房产信息数据都一样。都是第100页的信息,于是乎,得出结论。通过贝壳网web端,查看某一条件下的房产信息,最多可以查看3000套。

所以呢,我们增加一些条件,比如,满五唯一,2室的。请求之~
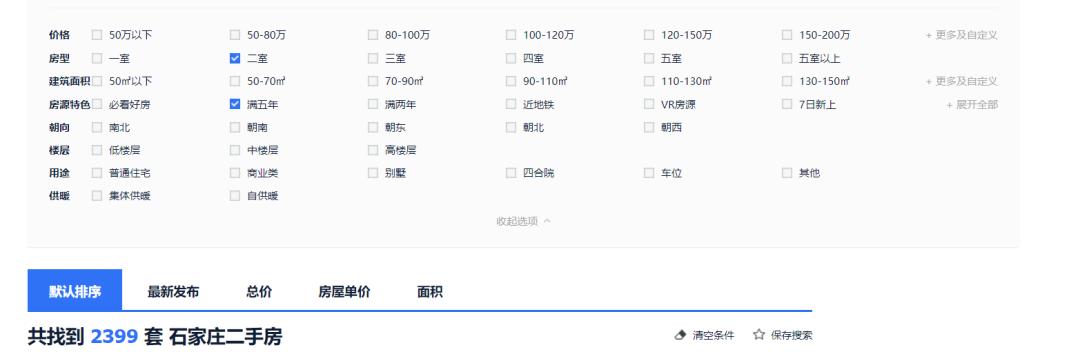
发现链接变成了https://sjz.ke.com/ershoufang/pg2mw1l2/。mw1l2这个玩意应该筛选条件。看到只有2399套,欧克,咱们就爬它了。
二、撸起袖子写代码
麻雀虽小五脏俱全,本爬虫设计三个部分,爬取,解析,储存。
爬取
爬取利用requests库,比python内置库urllib要好用很多。
importrequestsdefget_a_page(url):
result=requests.get(url)print(result.text)if __name__ == '__main__':for i in range(1, 101):
get_a_page(f'https://sjz.ke.com/ershoufang/pg{i}mw1l2/')
for循环打印返回数据,发现没问题。其实i循环到81就好了,毕竟咱们知道了,只有不到2400套嘛。
解析
解析使用pyquery ,这个库使用起来类似于Jquery。完整API,https://pythonhosted.org/pyquery/api.html。还有一个解析库`bs4,下次再尝试。
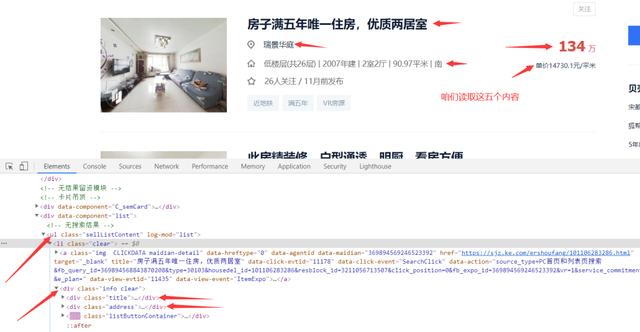
在这里插入图片描述
发现读取如图所示ul里面一个div就可以拿到我们想要的数据。
importrequestsfrom pyquery importPyQuery as pqimportjsondefget_a_page(url):
result=requests.get(url)
doc=pq(result.text)
ul= doc('.sellListContent')
divs= ul.children('.clear .info.clear').items()for div indivs:
count+= 1title= div.children('.title a').text()
place= div.children('.address .flood .positionInfo a').text()
msg= div.children('.address .houseInfo').text()
price= div.children('.address .priceInfo .totalPrice span').text()
per_meter= div.children('.address .priceInfo .unitPrice').attr('data-price')
dict={'title': title,'place': place,'msg': msg,'price': price,'per_meter': per_meter
}print(str(count) + ':' + json.dumps(dict, ensure_ascii=False))
代码如上,pyquery 的children方法是查找子标签,find方法是找子孙标签,此处我们只需要找下一代就好。然后通过text找到标签所包含的文本。attr是获取属性内容的,因为那个per_meter从属性中获取比较简单,标签中的内容还包含了“元/平米”。
储存
本次我们直接储存到csv中,一种类似于excel的文件格式。利用的是pandas库。
完整代码如下:
importrequestsfrom pyquery importPyQuery as pqimportjsonimportpandas as pd
columns= ['title', 'msg', 'price', 'per_meter']#爬取某网页
defget_a_page(url):
result=requests.get(url)
doc=pq(result.text)
ul= doc('.sellListContent')
divs= ul.children('.clear .info.clear').items()
count=0
titles=[]
places=[]
msgs=[]
prices=[]
per_meters=[]for div indivs:
count+= 1title= div.children('.title a').text()
place= div.children('.address .flood .positionInfo a').text()
msg= div.children('.address .houseInfo').text()
price= div.children('.address .priceInfo .totalPrice span').text()
per_meter= div.children('.address .priceInfo .unitPrice').attr('data-price')
dict={'title': title,'place': place,'msg': msg,'price': price,'per_meter': per_meter
}
titles.append(title)
places.append(place)
msgs.append(msg)
prices.append(price)
per_meters.append(per_meter)print(str(count) + ':' + json.dumps(dict, ensure_ascii=False))
datas={'title': titles,'place': places,'msg': msgs,'price': prices,'per_meter': per_meters
}
df= pd.DataFrame(data=datas, columns=columns)
df.to_csv('sjz.csv', mode='a', index=False, header=False)if __name__ == '__main__':for i in range(1, 101):
get_a_page(f'https://sjz.ke.com/ershoufang/pg{i}mw1l2/')
多进程
由于get_a_page函数要运行100次,有点小慢,所以利用多进程加快速度,这部分代码,请直接copy。
将主函数改成如下所示
from multiprocessing.pool importPoolif __name__ == '__main__':
pool= Pool(5)
group= ([f'https://sjz.ke.com/ershoufang/pg{x}mw1l2/'for x in range(1, 101)])
pool.map(get_a_page,group)
pool.close()
pool.join()
三、结束
查看下效果:
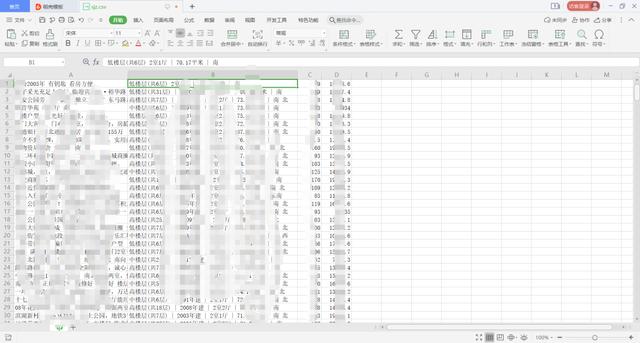
效果还可以。有人会说,为什么不把msg信息拆分一下,分别储存楼层、几室几厅、建筑年代等等多好。刚开始,我是那么做的,结果发现这个msg数据那几项不是必填项,有的建筑年代、楼层什么的房主不填写,索性就整个拿过来了。

