
- 1elasticsearch——字段截取_elasticsearch截取字符串
- 2linux内核那些事之mmap_region流程梳理
- 3Stable Diffusion-安装(整合版)_stablediffusion整合包
- 4模拟速度控制器的基本结构_模拟控制器的基本构成
- 5k8s网络插件-flannel
- 6图片优化:延迟加载的实现原理及源码解析_shopify 延迟图片加载代码
- 7HarmonyOS应用开发者基础认证试题_harmonyos应用开发者基础认证题库
- 8联想服务器网卡型号怎么看,如何通过设备硬件ID判断无线网卡的品牌及型号
- 9部署 Express 应用_express部署
- 10Ubuntu18.04显卡检查和驱动安装_tegra pcie x8 endpoint
CCF智能无人车比赛(国内绿洲科学实验云平台)心路历程+AWS Deepracer智能无人车比赛经验(附优秀代码re:lnvent 2018赛道)_绿洲无人车
赞
踩
PS: 本人2022年从学校组队参加CCF全国智能无人车大赛(re:lnvent 2018赛道),一开始是跟着学校用的绿洲科学实验云平台进行模型的训练,但是学校提供的免费训练时间一开始只有6h,小组成员都是从零开始,时间不知不觉就用完了,而训练出的小车模型却不是很理想,成绩在1min以外(因为一切都是未知的,每一次尝试都需要花费有限的训练时间,才能从其中得到经验以更进一步)。在这种较为不理想的情况下,我开始在网络上寻求经验,却意外的发现国内网站上的相关经验十分有限,搜寻起来十分困难,在连续几个晚上的信息检索和向主办方指导人员交流后,发现智能无人车的训练起源于国外的AWS平台,并且在AWS平台上每个新账号都可以有10h的免费训练时间,而创建账号只需要有一个信用卡(可绑定多个不同账号!!)和一个邮箱地址,也就是说,有一个信用卡和多个邮箱,就可以拥有数倍10h的训练时间,并且相互之间还可以进行模型的继承与转移,这无疑是一个更好的选择!!
- 无人车:绿洲云平台 VS亚马逊AWS平台
绿洲云平台是国内的无人车训练平台,知识内容和操作流程等与AWS平台相差无几,可以理解为汉化版的AWS Deepracer平台
区别:1(训练过程).AWS可以实时监控训练曲线并即时暂停,而绿洲云只有等结束才能看到训练曲线结果
2.(收费情况)AWS主要收费包括 1.训练(分析) 3.5$/h 2.存储模型(费用很少,自己用一个月大概1毛左右) 0.023$/GB,采用分别计算收费的方式。 绿洲云平台则是将所有费用整合起来,只有在训练上收费,费用为35/h,分析存储等不额外收费
3.(模型的转移)AWS的账号上,可以实现通过其中的S3桶的方式。 绿洲云平台上暂不支持模型转移
2. 无人车训练基础(经验)
一个模型的创建包括三个部分1.奖励函数 2.动作空间 3.超参数。 相关部分的基本概念在官方网站有更详细的讲解在这里就不赘述了,主要分享一下个人在训练模型中最常用到的几点。
①奖励函数,这是整个小车快慢的一个重要来源(但记住一定要搭配相应且合理的动作空间与训练时长),基本上看的是python代码的逻辑结构和策略调整,无编程基础的人也可以根据模板调整出合适的奖励函数。其中可以加入自己对于单一赛道(适用于单一赛道)的策略调整,也可以选择编译一个适应度更高(适用于许多赛道)的模型,当然也可以导入数学函数,
使得模型能更快拟合(达到速度和完成度的极限)
②动作空间,默认是离散型,每个赛道确实有不同的最佳离散型数值,但是较为单一且有限制(追求极限速度的可以尝试用log的可视化分析分析每个赛道的不同点的极限速度或角度,如这位大佬文章中所示)。本人常用的是连续型空间,采用的方法:在确定奖励函数的情况下,初始模型先设一个较小的最大速度+最小速度,然后逐步迭代,逐步增大最大和最小速度,以达到模型的极限
③超参数,本人还未尝试更改各个超参数的数值,但是其中最常用且感觉影响直观的就是batch size ,默认为32,这个参数的数值越大,模型在相同时间内训练就会迭代更多次,建议在初始模型训练时调大数值(如512)以更快达到极限,而在后面微调时则可以调小以降低改变量。
3 . 分析模型
在模型训练后提供的三条曲线图中,其中对于进一步训练最重要的判断依据为红线(分析or评估线),满值为100,若曲线图最后红线为100,此时的模型进行该赛道的分析结果全为100%完成度,所以红线与最终完成度直接挂钩。一般80以上的模型,其分析也会有2-3个以上的100%完成度(当分析5圈的情况下),这样的模型基本可保证0出界,若是有1-2次出界,也可以通过重复提交刷到0出界。
4 .小tips
①同一个模型在提交到相同比赛赛道时,每一次提交的成绩都会上下波动,其中完成度较高(出界少或者无出界)波动较小,在比赛的过程中可以通过重复提交的方式来尽量刷新掉出界,以此提高成绩(例,若分析结果中只有一次100%,在提交模型的过程中就可通过重复多次提交的方式令其三次都100%-快速且不出界)
5 实战案例分析(re:lnvent 2018赛道)
模型1:最终成绩29s(赛制为三圈的计时赛,出界一次罚时3s)。
训练时间共2h,单圈(100%)最快为9.8s左右
第一次训练如下,时长为1h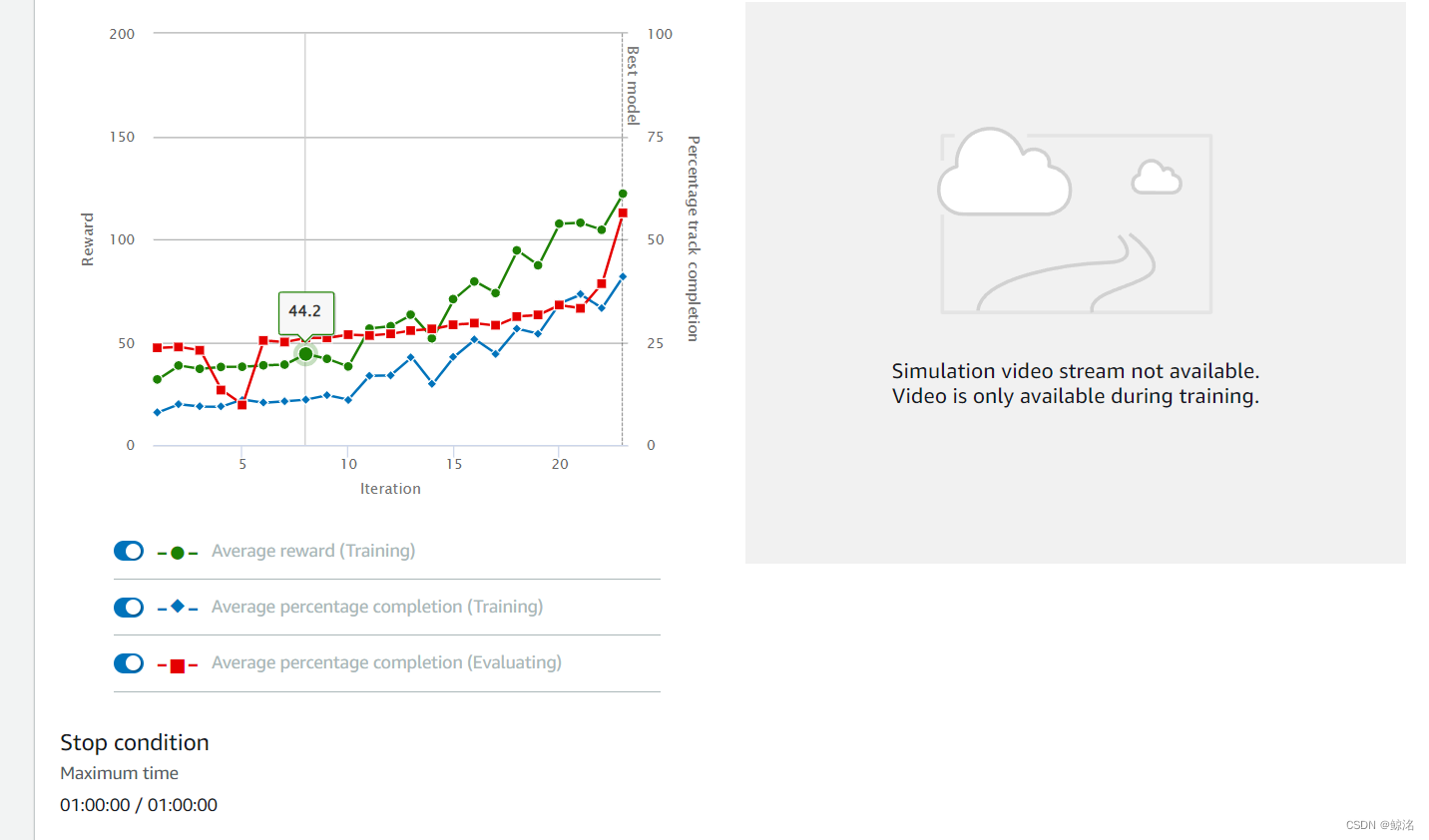
当然,第一次训练出来的模型连一次完整的赛道都跑不完,不过这只是初始模型,在最后的红线评估有一个大的跃迁就是件好事,可以接着往下训练
下面是第二次训练(第一次的克隆,参数不变),时长为1h
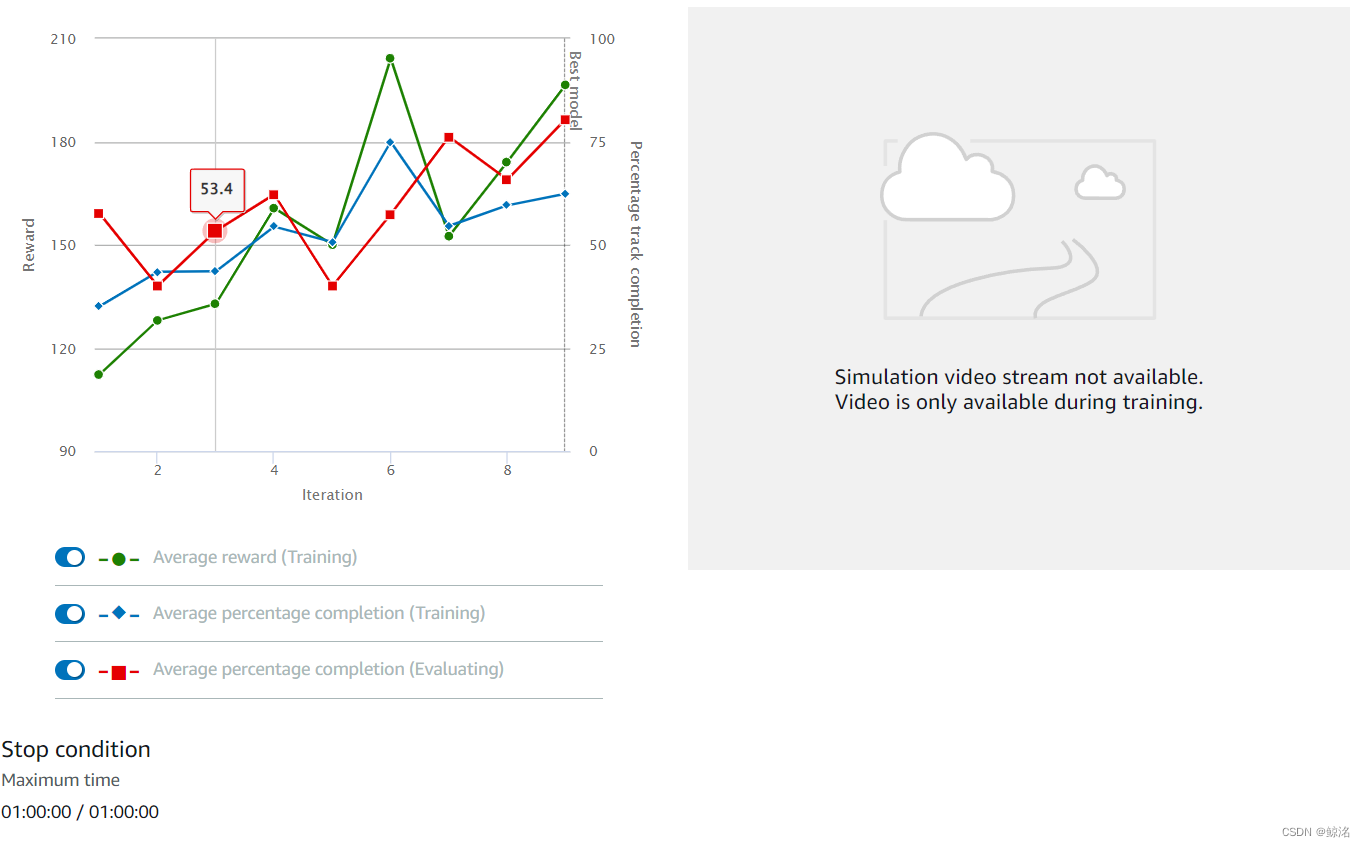
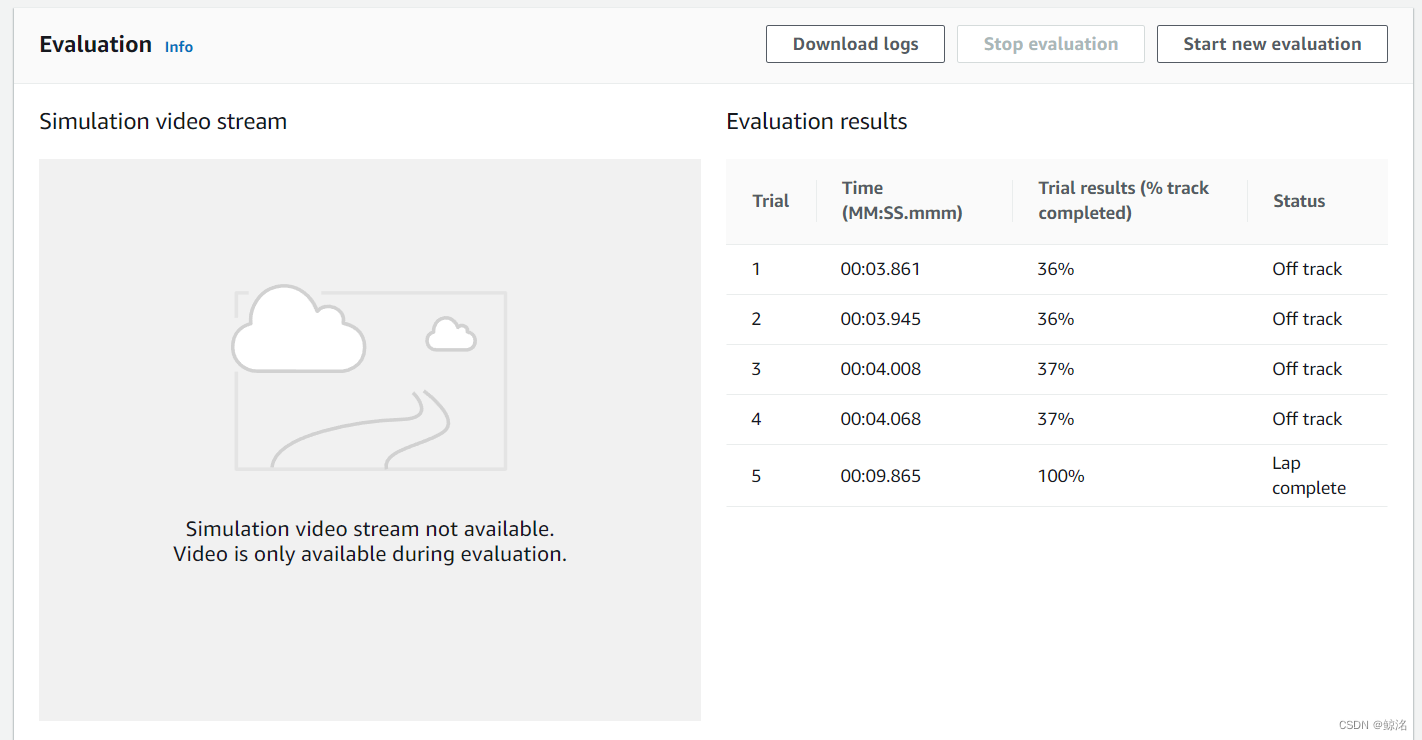
此时出现了100%完成率的情况,而且为9.865s,根据我之前说的重复提交方法,就可以在赛道里面提交出三次都不出界的成绩,预估为9.8×3,大约能达到29s
如下所示,用该模型进行提交

下面这个是同样的模型提交到了AWS四月线上公开赛的成绩,为前5%,共1728人,排名66,因为在前10%,晋级了5月的专业赛,还得到一份车手套装奖励
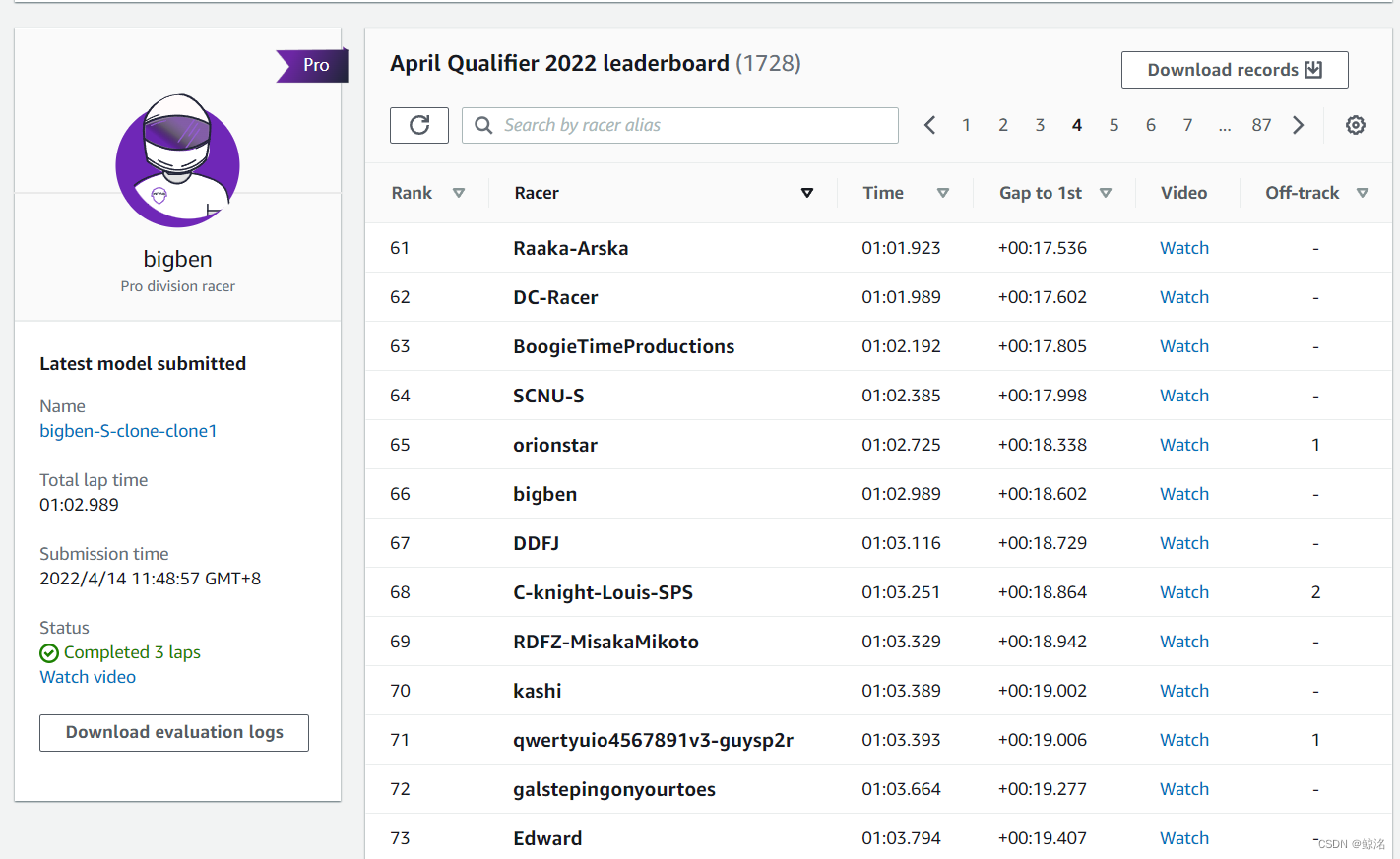
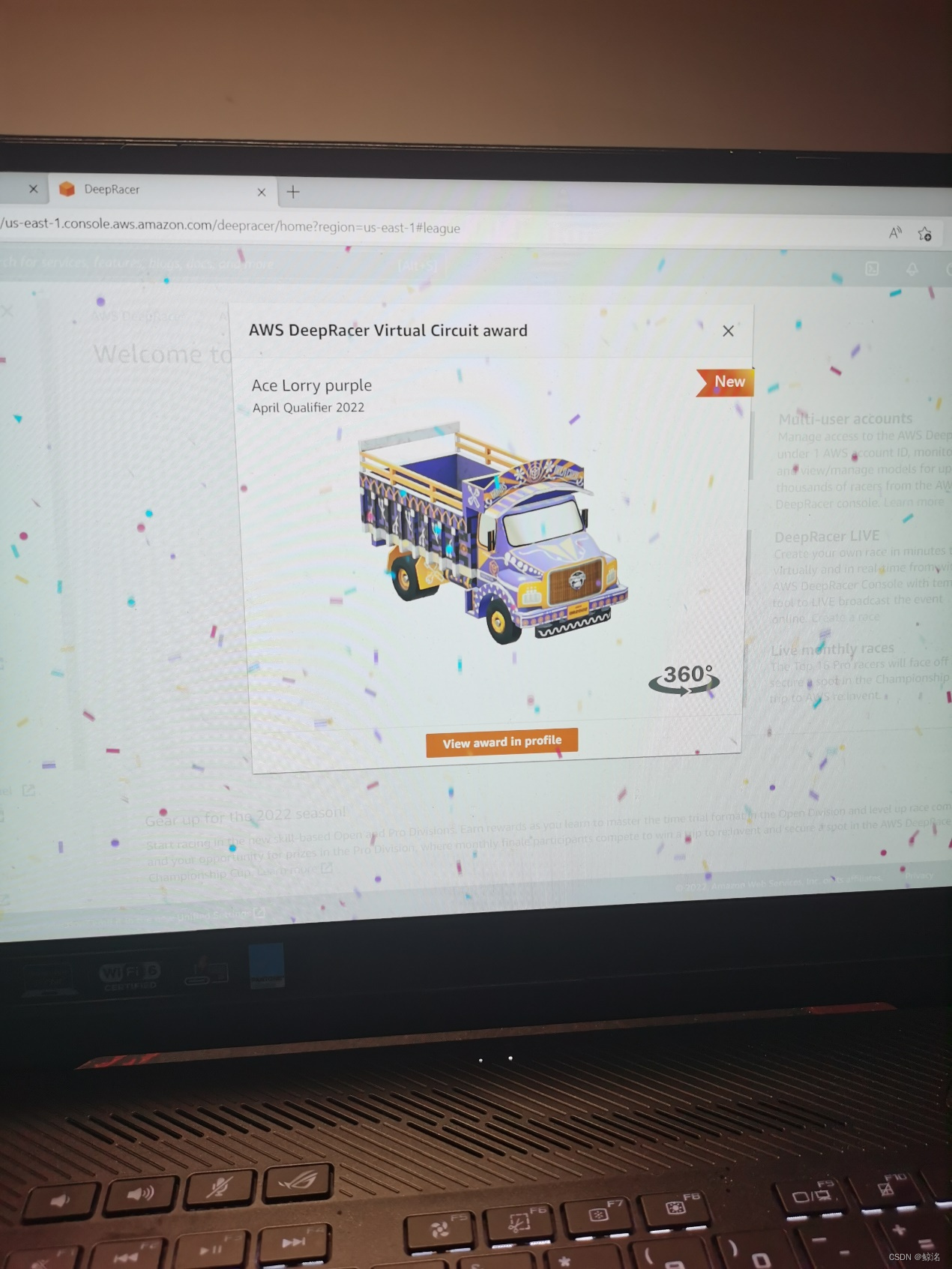
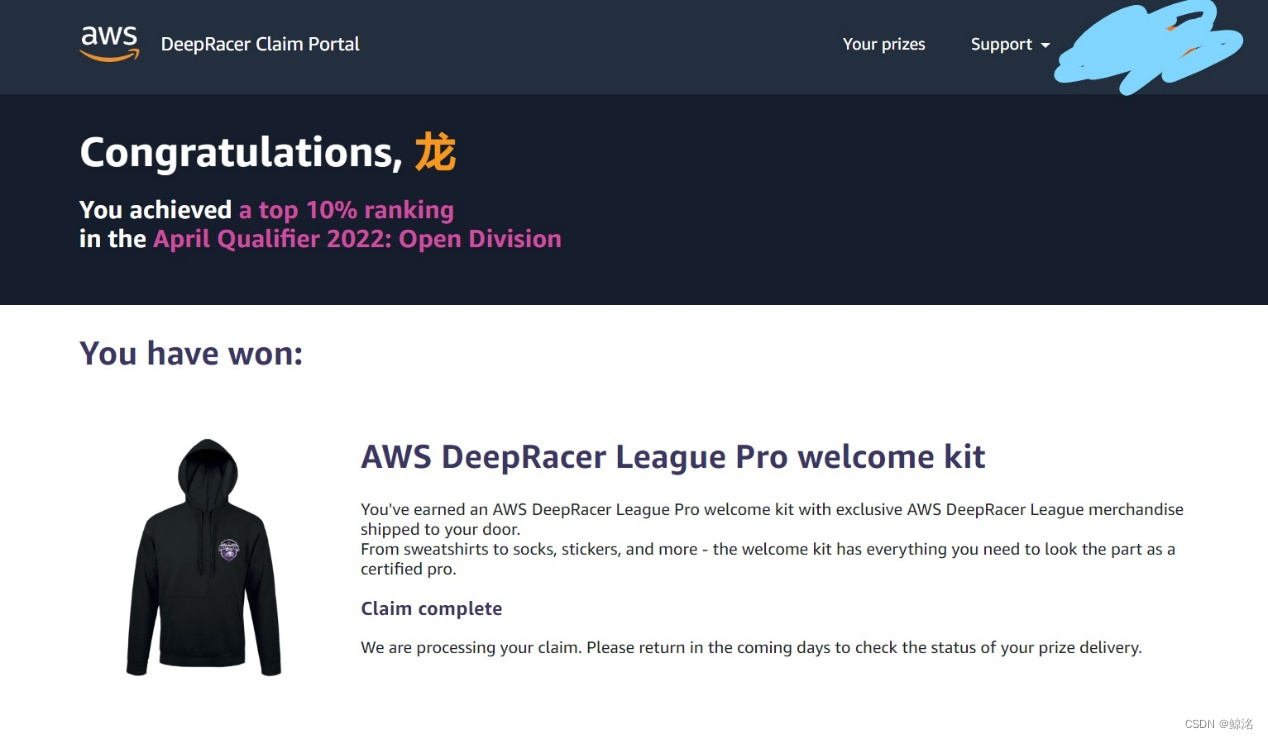
其中值得注意的是,我提交的模型如上,训练的是2018赛道

而这次的AWS四月赛采用的是另一个赛道,如下图

这样的差别可以说明,上面我训练出来的模型通用性较强,即使在不同赛道也能有较好成绩。下面是该模型的奖励函数代码,在这里分享给大家
- def reward_function(params):
- track_width = params['track_width']
- distance_from_center = params['distance_from_center']
- all_wheels_on_track = params['all_wheels_on_track']
- speed = params['speed']
- closest_waypoints = params["closest_waypoints"]
- SPEED_THRESHOLD = 2.0
-
- # Calculate 3 markers that are at varying distances away from the center line
- marker_1 = 0.1 * track_width
- marker_2 = 0.25 * track_width
- marker_3 = 0.5 * track_width
-
- # Give higher reward if the car is closer to center line and vice versa
- if distance_from_center <= marker_1:
- reward = 2.0
- elif distance_from_center <= marker_2:
- reward = 0.5
- elif distance_from_center <= marker_3:
- reward = 0.1
- else: reward = 1e-3 # likely crashed/ close to off track
-
- if not all_wheels_on_track:
- # Penalize if the car goes off track
- reward = 1e-3
- elif speed < SPEED_THRESHOLD:
- # Penalize if the car goes too slow
- reward = reward + 0.1
- else:
- # High reward if the car stays on track and goes fast
- reward = reward + 1.5
-
- if closest_waypoints[0] >= 0 and closest_waypoints[1] <= 16 or closest_waypoints[0] >= 111 and closest_waypoints[1] <= 117:
- speed = 3.0
- if all_wheels_on_track and (0.5 * track_width - distance_from_center) >= 0.05:
- reward = 2.0
- elif closest_waypoints[0] >= 87 and closest_waypoints[1] <= 103:
- speed = 2.6
- if all_wheels_on_track and (0.5 * track_width - distance_from_center) >= 0.05:
- reward = 2.0
- return float(reward)

模型2. 最终成绩为27.162s,赛制赛道同上,这次的模型采用了不同的训练策略和奖励函数(来自于大佬@Rambo.Fan的指导和分享),因为这次模型大部分来自这位前辈的指导,不是自己独立做出,所以在这里就不透露奖励函数的代码,但是这次模型的稳定性到了一个新的高度!!
训练时长为大约6h,经过多次模型迭代
首先是初始模型的效果如下图
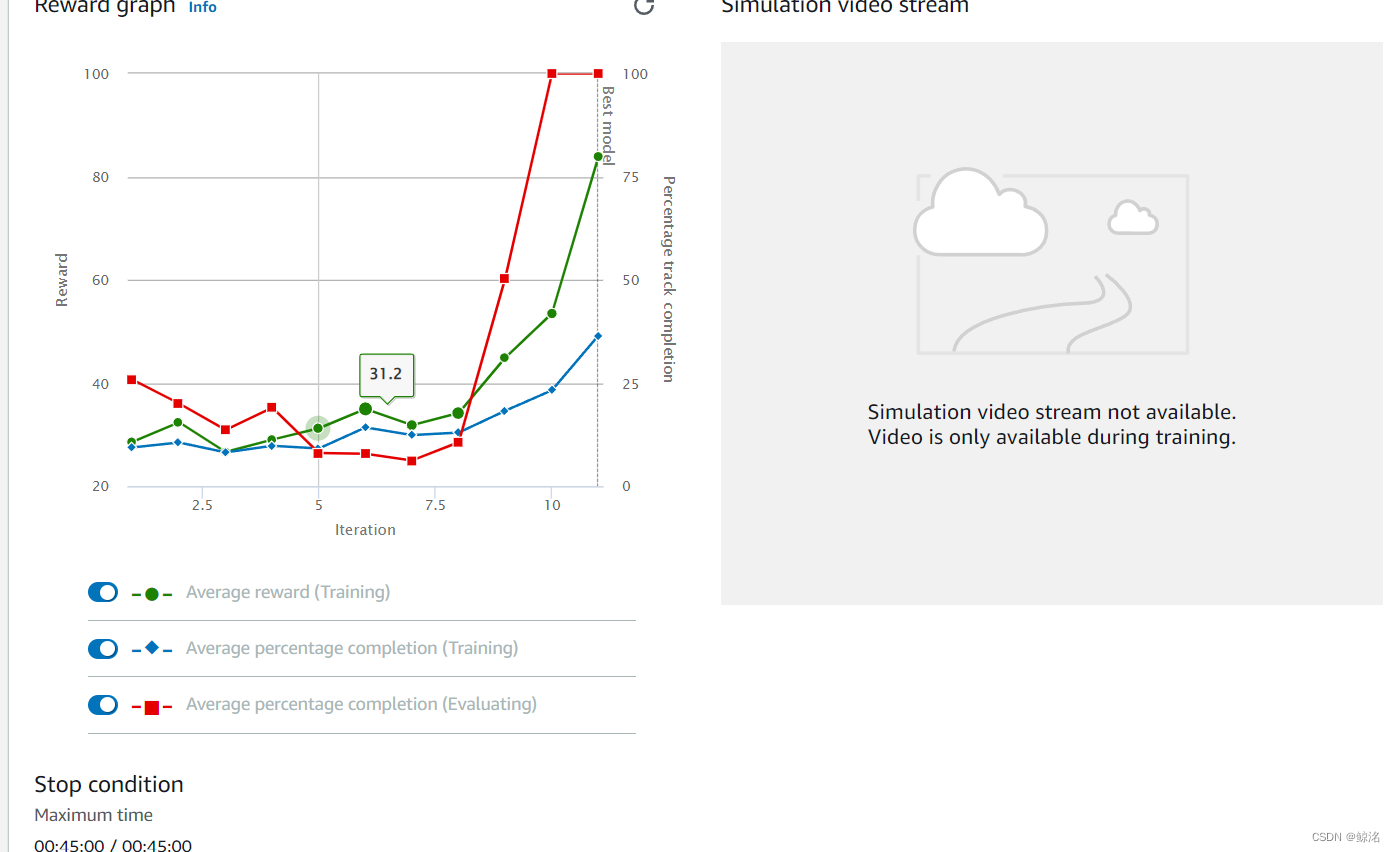
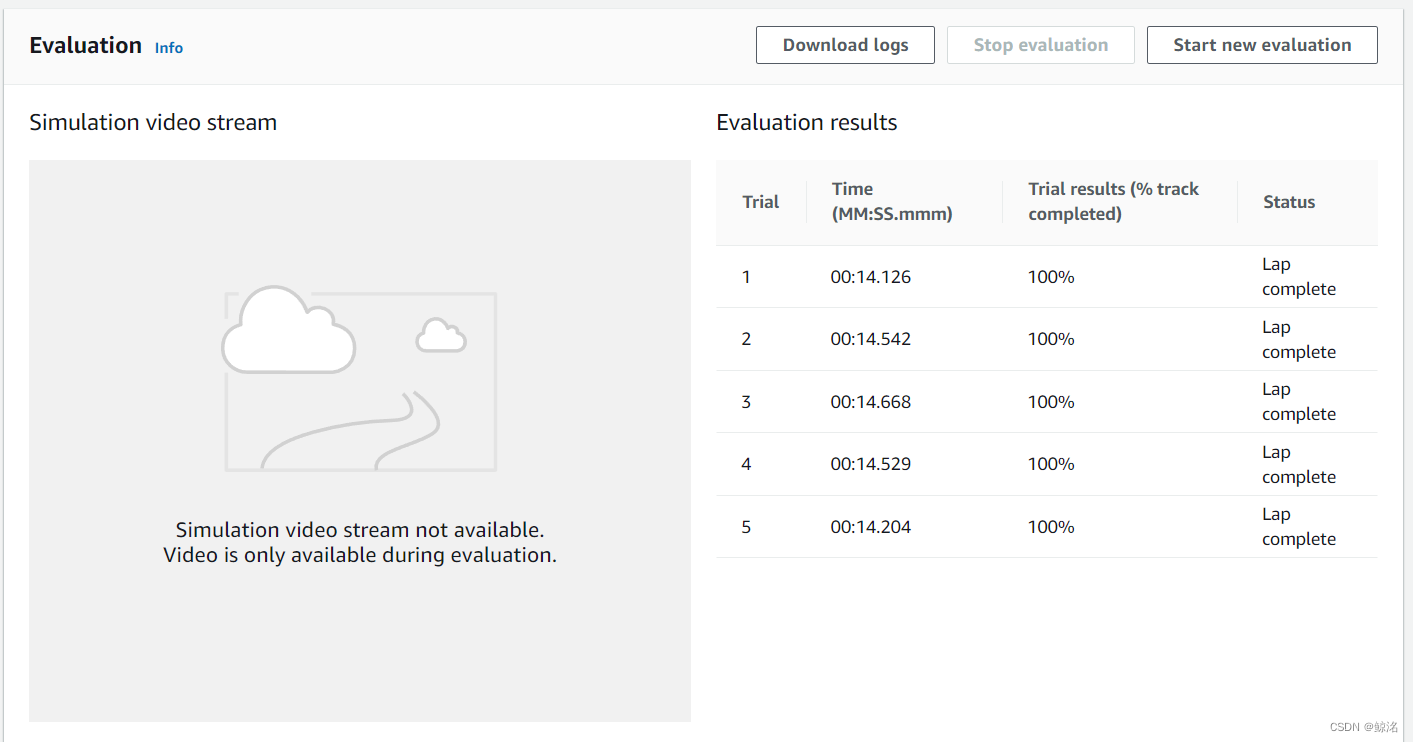
其中为了快速达到完成度的100%,所以将速度范围设置得较小,为了保持红线一直在100,以达到快速拟合。
后面的几次迭代也仅仅是慢慢加大最大速度和最小速度,其中会一直保持红线为100,一直到了最后一个迭代,也就是该模型在速度和完成度上的一个相对极限
单圈平均为9.5s
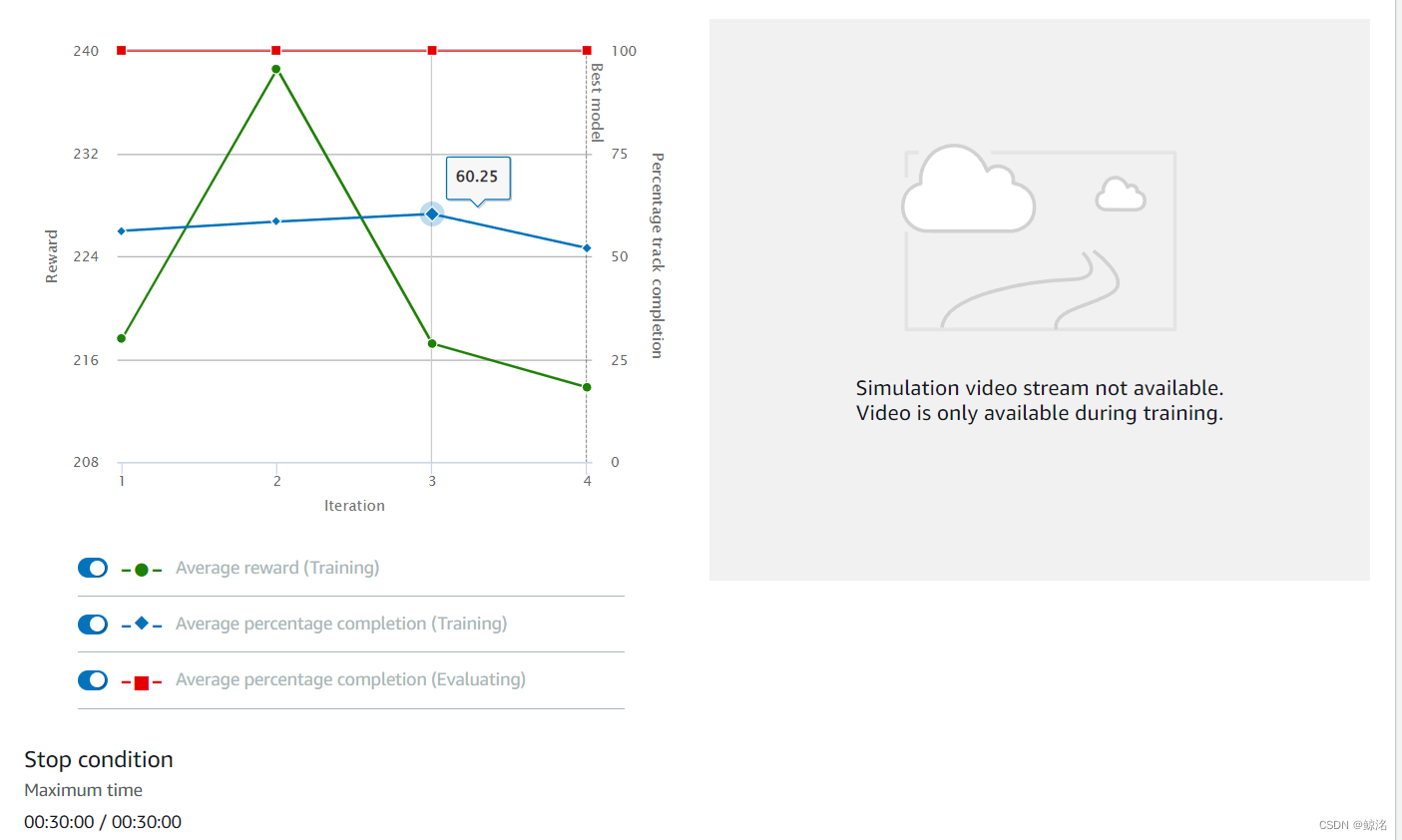
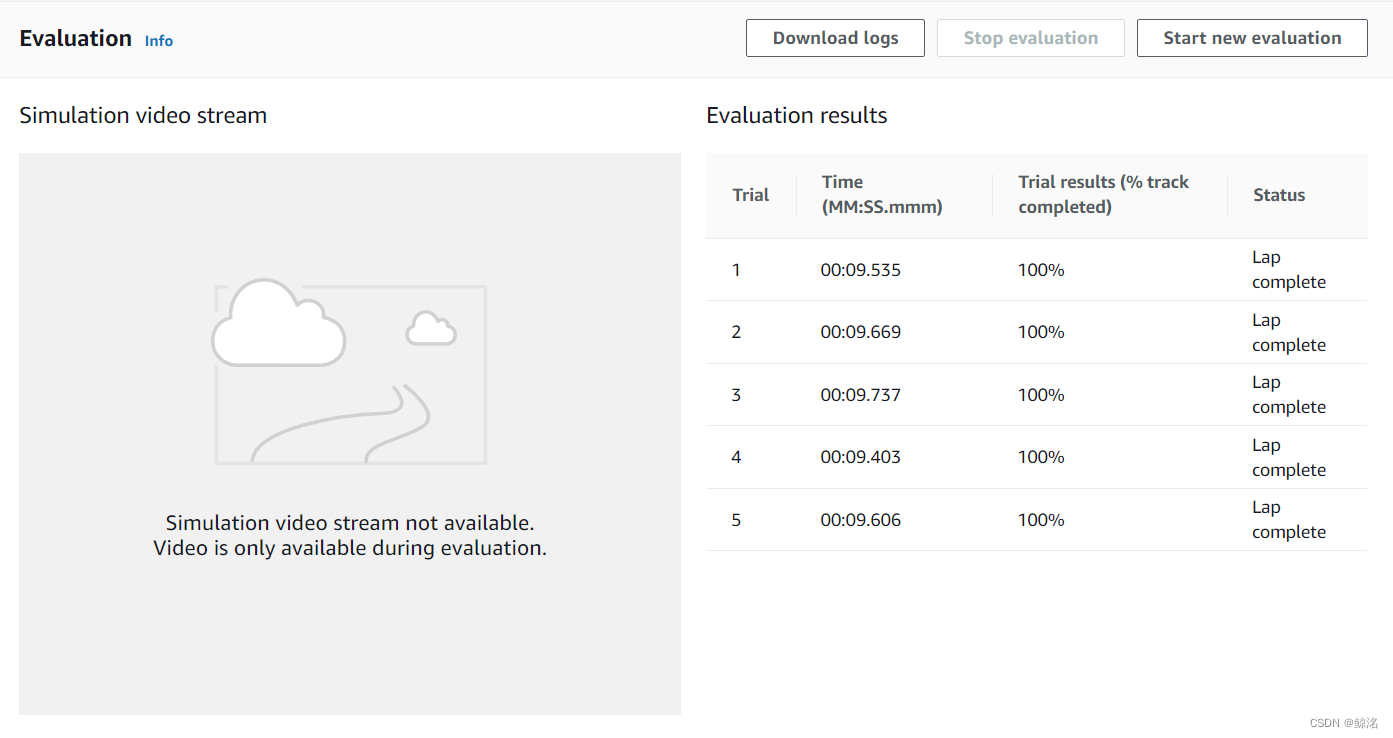
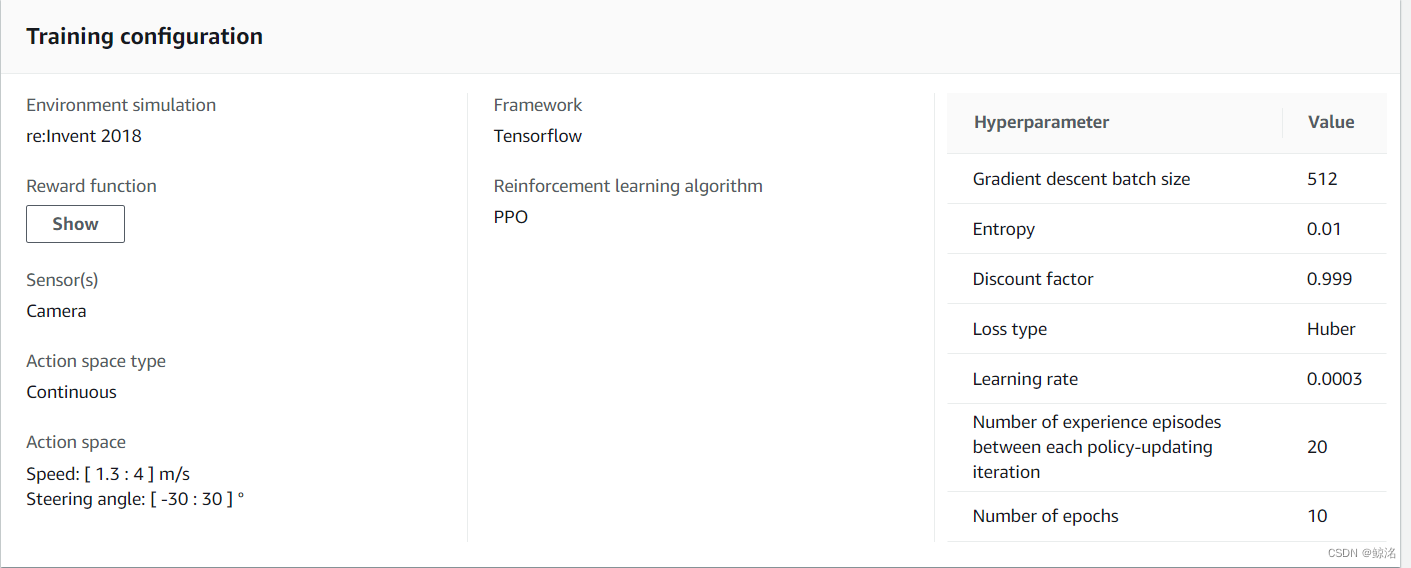
该模型的稳定性很高,因为在奖励函数中导入了数学函数,可以帮助模型快速拟合
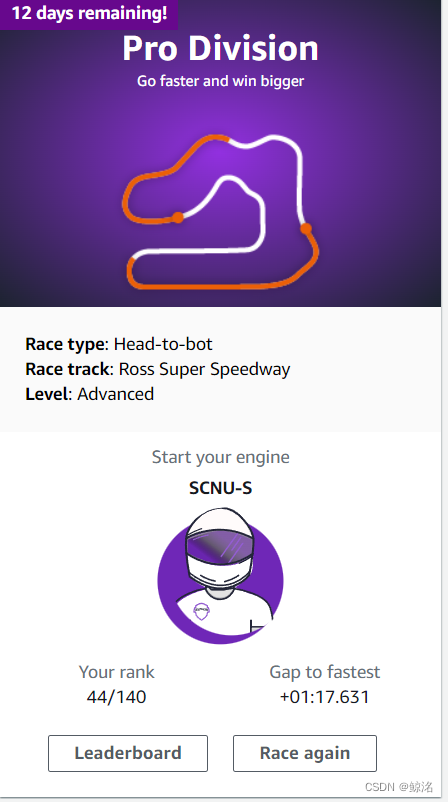
下面是在比赛中的提交成绩

跟上一个模型一样,同样参加了AWS四月公开赛,并且以前5%的成绩晋级专业赛,获得了相应奖励,下面是目前在专业赛的排名,同样是用如上在2018赛道训练模型进行的参赛,再次说明这两个模型通用性较好
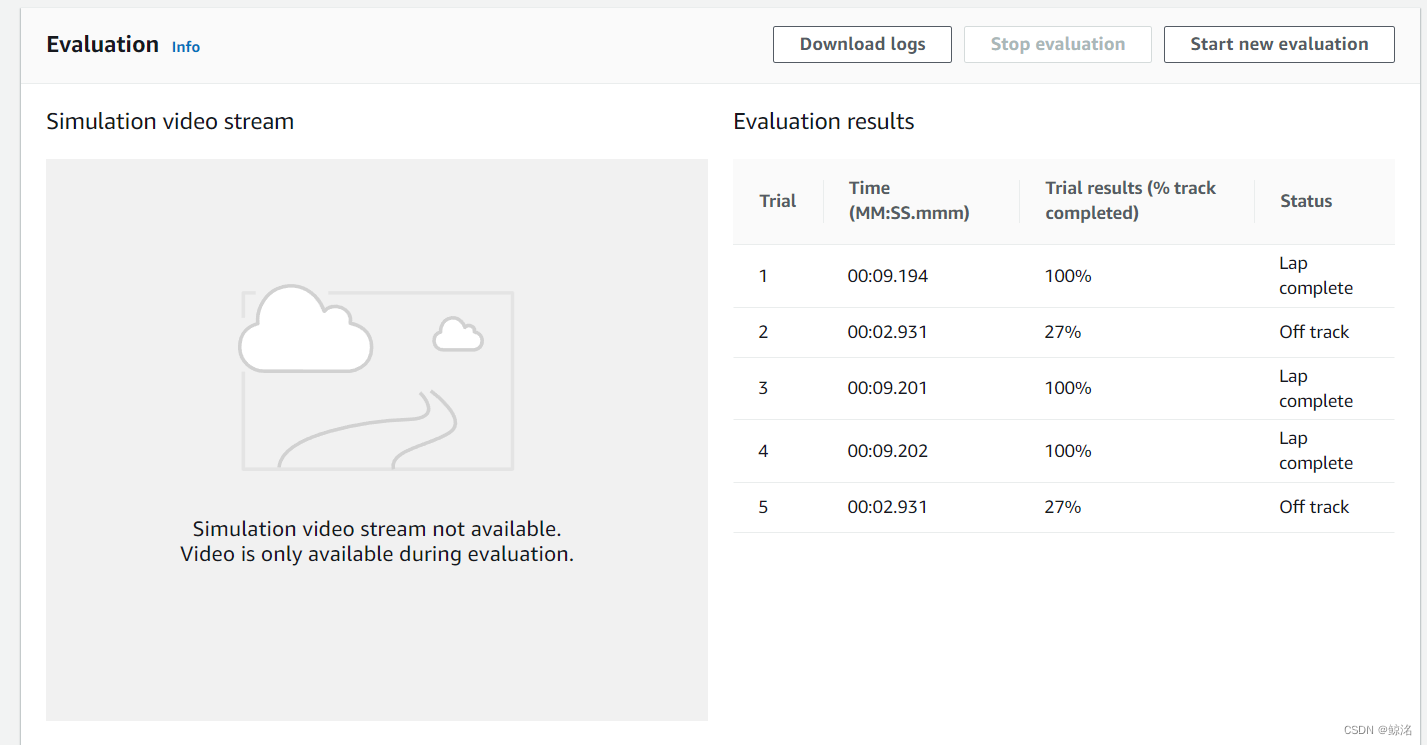
模型3 最终成绩为26.797, 赛制赛道如上,单圈平均9.2,其具体训练过程同样来自前辈@Rambo.Fan,暂不展示出来
后续还在积极尝试新的模型,如果能单圈突破到8s,就有可能成绩到24s,甚至还在其他赛道看到过成绩为22s的,估计单圈都突破7s了,真是人外有人啊,学习之路任重道远,本人还差得很多,也希望大家不要轻易放弃或者满足,争取取得更好的成绩!!!
Ps.本人现在还在进行2022年CCF全国智能无人车比赛南部赛区的线上巡回赛,5.31号出晋级结果,如果有相关问题可以私聊我,会积极与大家交流学习。

