
- 1测试时报错 RuntimeError: CUDA out of memory._训练了两个epoch后cuda out of memory
- 2基于SPRINGBOOT搜房网设计与实现_基于spring boot的在线选房网站设计与实现
- 3nodejs中unzip时js报错ENOENT not found in或者Invalid package_node.js uncaught error: invalid package
- 4Android系统启动系列5 SystemServer进程下_android systemserver
- 5Android Gradle 开发与应用 (六) : 创建buildSrc插件和使用命令行创建Gradle插件
- 6在 M1/M2 Mac 上,让 Windows 11 免费“跑”起来!_mac m2 win11arm usb
- 7事务注解放到类上面 下面私有方法有效吗_Spring声明式事务,你用对了吗
- 8Mac安装鸿蒙系统,搭建MAC系统下的Wi-Fi loT Hi3861鸿蒙开发环境
- 9身份证批量识别 免费 身份证OCR识别 如何用python实现身份证识别_python使用tesseract ocr识别身份证
- 10python现在排第几名_2019 编程语言排行榜:C 排名衰退,python即将问鼎
论文学习——HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis_hifigan
赞
踩
引言
- 这篇文章,是《CONDITIONAL SOUND GENERATION USING NEURAL DISCRETE TIME-FREQUENCY REPRESENTATION LEARNING》主要应用到的三个技术之一,我正在复现这篇文章,然后需要了解HiFi-GAN技术,续哦一就翻译了这篇文章。
- 这篇文章是2020年的,近三年的文章,是Conference on Neural Information Processing Systems (NeurIPS 2020),这个会议也是人工智能领域的顶会,还是有价值的,所以更需要翻译了。
论文翻译
Abstract摘要
- 近几年声音合成领域很多研究已经采用生成对抗网络(GANs)去产生声音原始的波形图。虽然对抗生成模型提高了采样的效率和内存的使用率,但是采样的质量并没有自回归生成模型或者基于流的生成模型效果好。本文,我们提出了一个新的HiFi-GAN,这个模型能够同时实现高效率和高保真的声音合成效果。因为声音信号是由不同周期的正弦波组成的,我们通过试验发现,对于声音的周期特征进行建模,能够有效提高声音的采样质量。对于单个说话人的数据集做实验发现,我们提出的方法使用V100GPU上,生成22.05KHz高保真音频比实时167.9倍。作者进一步展示了HiFi-GAN对未见过的说话者的梅尔频谱图反演和端到端语音合成的通用性。最后,我们对剪裁出了一个小样本,能够在CPU上运行,生成样本是实时样本的13.4倍,并且质量和自回归模型的质量相当。
问题
-
实时生成声音的含义
- 声音的生成速度和声音播放的速度相同。
- 论文中说的比实时的快,意思是如果正常生成一秒种的声音需要一秒种,但是我们的模型只需要0.001秒就能生成1秒中的声音。
-
梅尔频谱图的含义
- 具体含义:从梅尔频谱图恢复到原始音频信号的过程。
- 梅尔频谱图的含义:梅尔频谱图是音频的一种表示,描述了音频信号在不同频率上的能量分布,这些频率是模拟人耳听觉感知的刻度
- 应用:语音合成领域是将文本转成梅尔频谱图,然后在从梅尔频谱图转成音频信号,这个比较困难,因为他需要从梅尔频谱图这种粗糙的音频表示恢复成更加细致的音频表示。
-
端到端的语音合成
- 含义:直接从文本到语音的转换方法,不需要中间的手动特征工程或者复杂的处理步骤
- 传统的语音合成:在传统的语音合成系统中,通常需要多个步骤来从文本生成语音,包括文本分析、音素转换、声调预测、语音合成等。这些步骤通常需要大量的手动特征工程和领域知识。
-
未见说话者的梅尔频谱图反转
- 含义:模型能够处理并反转那些在训练阶段没有见过的说话者的梅尔频谱图,从而生成对应的音频信号
- 困难:模型能够从未见过的说话者的梅尔频谱图恢复出音频信号
总结
- 常见的基于对抗生成模型用于音频生成的采样率和内存利用率都比较好,但是质量不咋地。我们提出的HiFi-Gan能够完美弥补这些问题,速度快,并且质量高。主要是对于声音的周期信息进行建模,才会带来对应的效果提升。
Introduction介绍
- 声音是人类交互中使用频率最高并且最自然的交流介质。随着技术的不断发展,声音已经是人工智能助手的主要交流介质,常见的有亚马逊的Alexa,除此之外,还广泛应用于汽车、智能家具和其他别的一些领域。相应的,随着人类和机器交流的需求增加,人们开始积极研究能够合成人类语言的语音合成技术。
- 语音合成技术也随着神经网络的发展而快速进步。大部分的神经网络语言合成系统都是分为两步:
- 1、根据文本,预测一个低分辨率的中间表示形式,比如说梅尔频谱图或者语言特征
- 2、将中间特征合成每秒24,000个采样点的波形图和高达16位的高保真度的原始波形。
- 我们的文章专注于设计一个第二阶段的模型,能够从梅尔频谱中合成高保真的波形图。
- 第二阶段的模型有很多,主要有一下几种
- 基于回归模型
- WaveNet:是自回归卷级神经网络,该方法生成声音质量超过传统的方法,但是因为是自回归,一次前向操作只能生成一个采样点,如果要生成采样率很高的声音很慢
- Flow-based generative model:基于流模型的声音生成模型,就是专门为了解决上述生成缓慢的问题。 这些模型将噪声序列(通常是从一个简单的分布中采样得到的)转换成复杂的音频波形。这个转换过程是并行的,也就是说,模型可以同时处理序列中的所有样本,而不是像自回归模型那样一次只处理一个样本。但是生成的质量赶不上自回归模型生成的声音
- Parallel WaveNet ,WaveGlow
- 基于对抗生成网络
- 2014年Goodfellow提出的,目前最主要的深度生成模型
- MelGAN:提出了一种多尺度架构,用于在多个原始波形尺度上操作的鉴别器。通过复杂的架构考虑,MelGAN 生成器足够紧凑,可以在 CPU 上实现实时合成。
- 提出了多分辨率STFT损失函数来改进和稳定GAN训练,比IAF模型ClariNet获得了更好的参数效率和更少的训练时间(Pin et al., 2018)。
- GAN-TTS (Bínkowski et al., 2019) 不是梅尔谱图,而是通过在不同窗口大小上运行的多个鉴别器成功地从语言特征生成高质量的原始音频波形。与 Parallel WaveNet 相比,该模型也显示出更少的 FLOP。
- 尽管具有优势,但 GAN 模型和基于 AR 或基于流的模型之间的样本质量仍然存在差距。
- 基于回归模型
- 本文的思路
- 我们提出的HiFi-GAN无论是计算效率还是采样率都比自回归模型和基于流的模型要好。因为语音信号是由不同周期的正弦信号构成,对周期信号进行建模对于生成实际的语音信号而言,十分重要。**因此,我们提出针对一个有多个鉴别器构成的大鉴别器,每一个小鉴别器固定获取某一周期的原始波形。**这个模型是我们模型合成真实声音的基础。因为我们为鉴别器提取出声音的不同部分,我们还设计了一个模块,该模块放置多个残差块,每个块并行观察不同长度的特征,并将其应用于生成器。
- 比起最近发布的最好的一些模型比如说,WaveNet,WaveGlow,HiFi-GAN能够获得更高的MOS评分。我们的模型能够在GPUV100上面合成3.7KHz的高质量人声。我们提出的模型,对于第一次接触的声音进行梅尔频谱图的反转,运行效果不错。最后,HiFi-GAN 的微小足迹版本只需要 0.92M 参数,同时优于最佳公开可用的模型和 HiFi-GAN 最快的版本在 CPU 上比实时快 13.44 倍,在单个 V100 GPU 上比实时快 1,186 倍,质量与自回归生成的声音相当。
- 实验结果展示网站,具体的demo链接
- 项目具体代码,代码链接
问题
- 鉴别器discriminator是什么?如何实现针对不同周期信号的检测?
- 多个參差模块如何实现并行提取特征?
HiFi-GAN
Overview总览
- HiFi-GAN是由一个生成器和两个鉴别器构成,分别是多尺度鉴别器和多周期鉴别器。生成器和鉴别器都是通过对抗学习进行训练的,为了提高训练的稳定性和模型的性能,还需要两个额外的损失函数。
Generator生成器
- 生成器是全卷级神经网络,使用梅尔频谱图作为输入,并且通过反卷级对其进行上采样,直到输出序列的长度和原始波形图的时间分辨率相匹配。每一个反卷积模块后面都有一个多感知区域融合模块。图片一具体描述了生成器的架构,噪声并没有作为额外的输入放到生成器。
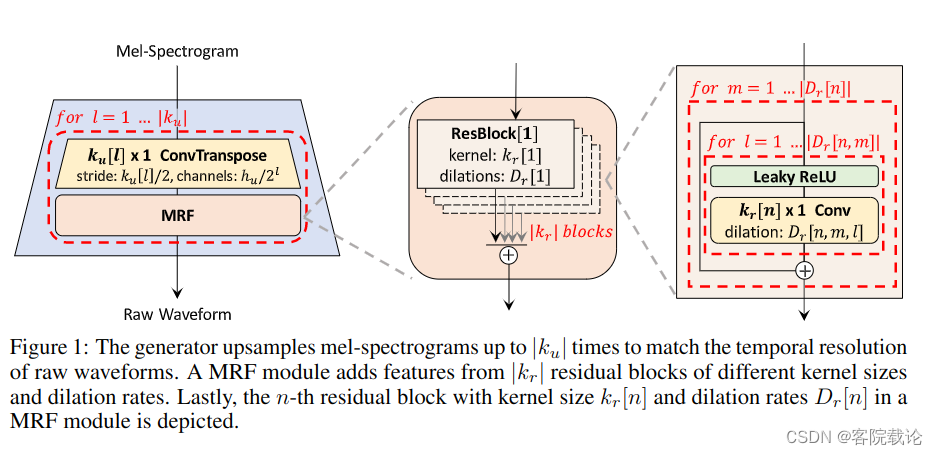
- 图片一:生成器对梅尔频谱图进行上采样Ku次,直到结果和原始波形图的时间频率相一致。一个MRF模块是由多个大小不同的卷积核和膨胀率的残差模块构成,最右边的图片是描述了Kn个残差卷积模块,kernel大小是Kr[n]和膨胀率Dr[n]
Multi-Receptive Field Fusion多感知域融合
- 我们为生成器设计了多感知域融合模块(Multi-Receptive field Fusion) ,它能够并行观察不同长度的模式特征。 具体来说,MRF模块是返回多个參差模块输出的累加和。每一个残差模块都有不同的卷积核大小和膨胀系数,这主要是为了形成不同的感受野模式。MRF模块的架构和残差模块的架构具体在图一可见。我们在生成器中留了一些可调参数。我们留了一些可调参数,可以调整MRF模块的隐藏维度的 h u h_u hu,反转卷积核大小 k u k_u ku,卷积核大小 k r k_r kr以及膨胀系数 D r D_r Dr去实现你的需求。你的需求需要自己在效率和采样质量之间进行权衡。
问题
- 膨胀卷积是什么
-
含义:又称为空洞卷积,在卷积核中间插入0,然后扩大卷积核,进而扩大感受野。具体可以看下面的图,最左边的是正常的卷积,中间是膨胀率为2的卷积,最右边的是膨胀率为3的卷积

-
优点:较之于普通的卷积,使用膨胀卷积,他的感受野更大,获取的信息更多
-

Discriminator鉴定器
- 识别长域依赖(long-term dependencies)是构建出真是语音的关键。比如说,音素的持续时间就超过了100毫秒,对照在波形图中,就是连续大学2200个采样点。以前是通过增加生成器和鉴别器的感受野实现的。我们关注另外一个关键问题,目前还没有被解决。因为声音是有多个不同周期的正弦信号构成的,所以,需要识别出音频数据中潜在的周期模式。
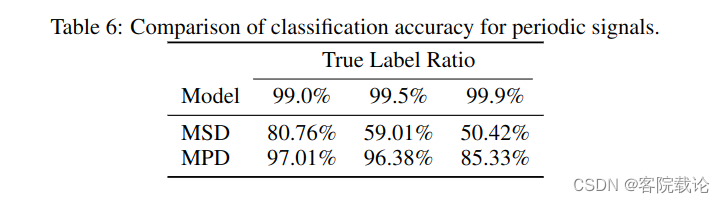
- 为此,我们提出了多周期鉴别器,这个鉴别器是有多个子鉴别器构成,每一个子鉴别器都专门识别输入音频信号的某一部分的周期信号。除此之外,为了获取连续模式和长领域依赖,我们使用了多尺度鉴别其,这个2019年的MelGAN中提出来过的,主要是在不同尺度下连续测试音频的采样点。我们也做了一些小试验,去验证MPD和MSD获取周期特征的能力,具体结果在附件1中可以看到。具体见下表,这就是一个消融试验,可以看到没了MSD和MPD,准确率都有所下降。
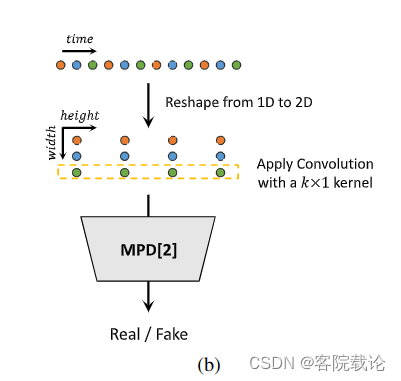
Multi-Period Discriminator多周期鉴别器
- MPD是由若干子鉴别器构成的,每一个子鉴别器只接受音频的等间距样本,这个间隔是由周期给出的。**子鉴别器主要是通过查看输入音频的不同部分,来获取彼此不同的隐式结构。**我们将周期设置为[2,3,5,7,11]来尽量减少重叠。如图二b中展示的一样,我们将一维的长度为T的原始音频数据转换为2维的数据,宽为 p p p,长为 T / p T/p T/p,然后对其使用二维卷积处理。MPD中每一个卷积层,我们将卷积核宽度设置为1,来单独处理某一個周期的样本。每一个子鉴别器是一个跨步卷积层,激活函数为 ReLU。然后,对MPD进行权重归一化,通过将输入数据转换成二维数据,而不是直接对周期信号进行采样,MPD的梯度可以传递到输入音频的所有时间步长。
MPD的问题
-
如何实现将一维的波形信号转为二维的矩阵信号?
- 是按照他设定的周期区间[2,3,5,7,11],对数据进行转换,所以周期为p,然后数据的长度就为T/p,每一行都是对应某一个周期间隔的采样信号点。
- 这里设置为这样的间隔是因为他们是质数,彼此重叠的因子比较少,所以不会出现很多重叠。
- 为什么出现重叠就不好了??可以试试看!
-
为什么二维卷积设置宽度为1,就可以不相互影响?
- 每一层都是某一个特定的周期频率,仅仅围绕着一层进行卷积,肯定不会出现重叠。
-
为什么使用二维卷积,梯度就能全时传播?
- 在二维卷积操作中,每一个输出元素都是输入矩阵中一组元素的函数,当我们对输出元素进行反向传播时,每一个输入元素的梯度都会被计算并被积累,因此,通过这种方式,梯度可以从输出传播到所有的输入元素。
- 通过这种设计,使得鉴别器的梯度传播到输入音频的所有时间步中,提高了模型的性能,使得模型考虑的是全局信息,不是局部信息
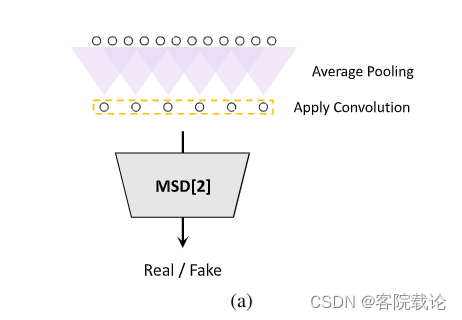
Multi-Scale Discriminator多尺度鉴别器
- 因为在多周期鉴定器中,每一个子鉴定器仅仅只能接受非链接的采样点,我们增加了多尺度鉴定器,来实现对于音频序列的连续感知。MSD的架构是借鉴了MelGAN的,这个是2019年Kumar发明的。MSD是三个子鉴定器的混合,每一个子鉴定器都是针对不同的输入尺度,分别是原始音频、2倍平均池化音频、4倍平均池化音频,具体展示请看下图。MSD中每一个子鉴定器都是跨步成组卷积层的堆栈,激活函数是Leaky ReLU.。鉴定器的尺寸会随着步长的减少和层数的增多而增多。除了第一个直接操作原始音频的子鉴定器,权重归一化被应用在每一个子鉴定器中。相反,为了稳定训练,我们还使用了频谱归一化借此稳定训练结果。
MSD的问题
-
为什么MPD是离散的采样点,MSD是连续的估计音频序列?
- MPD是检测不同周期的采样点,按照一定的空间间隔进行采样,本来就是离散的。MSD是对光滑的波形图进行整体卷积采样,是连续,是为了弥补MPD的离散的缺点。
-
原始音频,两倍平均池化的原始音频,四倍平均池化的原始音频区别在哪里?
- 平均池化的含义:下采样的常见技术,是将输入的数据划分成多个不重叠的区域,然后计算每一个区域的平均值作为输出。
- 这里而2X,4X分别是划分的颗粒度,分别是将两个连续的输入,4个连续的输入进行平均池化,然后进行输出。从原始图像,到2X,再到4X,分辨率依次降低。数据也相应的更加粗糙。
-
groudped convolution layer什么意思?
- 常规卷积:每一个输出的特征图是由所有的输入特征图通过卷积核卷积所得,如果输入有c个通道,那么每一个卷积核也有C个通道
- 分组卷积:将输入和卷积核分成多个组,每一个组的特征图只与同组的卷积核进行卷积操作。如果输入有C个通道,设定分组的数量是G,那么每一个组有C/G个通道,每一个卷积核也只有C/G个通道。
- 效果:增加网络的多样性,并且减少计算量和参数量。
2.3 总结
- 注意,MPD是作用在波形图中离散的采样点中,MSD是作用在光滑的波形图上,是连续的采样点。
- 以前的研究也有使用多鉴定器的结构,比如说《High Fidelity Speech Synthesis with Adversarial Networks》。这篇文章的多鉴定器的架构和我们的MSD和MPD有相似之处,都是多个鉴定器的混合,但是他需要将输出平均并且是有条件的鉴别器,我们提出的MSD和MPD是基于马尔克夫窗口的完全无条件鉴别器。这篇文论的RWD和我们提出的MPD对于输入数据的处理是相同的。但是我们提出的MPD是使用素数的周期集,去尽可能地区分尽可能多的周期数据,但是RWD则是设置的周期存在较多的重叠,并且没有单独处理每一个重塑过后的通道,这和我们提出来的完全不一样。RWD的变体可以执行和MPD一样的操作,但是两者在参数共享和相邻元素的跨步卷积上面的原理是不一样。
问题
-
马尔克夫窗口是什么?完全无条件鉴别器的含义?
- 马尔克夫性质:一个状态的下一个状态只依赖于当前的状态,与过去的状态无关
- 含义:马尔克夫窗口通常指的是一个固定大小的上下文窗口,模型只考虑这个窗口内的信息来预测下一个状态,比如说我们定义了一个大小为3的马尔克夫窗口,那么模型只会考虑当前和前两个状态,来预测下一个状态。
- 原文的含义:MPD仅仅只考虑当前的周期内,窗口下的固定信息,并不会考虑其他的信息,性质和马克洛夫的一样,并且不需要其他任何的信息作为条件。
-
跨步卷积的含义
- 含义:常规的卷积移动步长是1,输出的特征图的空间尺寸和输入特征图的空间尺寸相同。跨步卷积,卷积核在输入特征图上移动的步长大于1,设移动步长为S,输入的特征图为W*H,则输出特征图的尺寸为(W/S)×(H/S)(假设W和H都能被S整除)。
- 优点:减少运算,减少过拟合的情况
2.4 Training Loss Terms
- GAN Loss 方便起见,在这一章节,我们将MSD和MPD都描述为我们的鉴定器。对于生成器和鉴定器,训练方法是用2017年Mao等人提出的LS-GAN一样,使用最小二乘损失函数来替代交叉熵损失函数,以解决梯度消失的问题。鉴别器将实际样例分类为1,将生成器生成的样例分类为0.生成器的目标是通过改变采样的质量,来骗过鉴别器,使之将生成结果分类为1.生成器 G G G和鉴别器 D D D的GAN损失函数如下。其中 x x x表示实际的音频信号, s s s表示为输入的条件,也就是实际音频的梅尔频谱图。
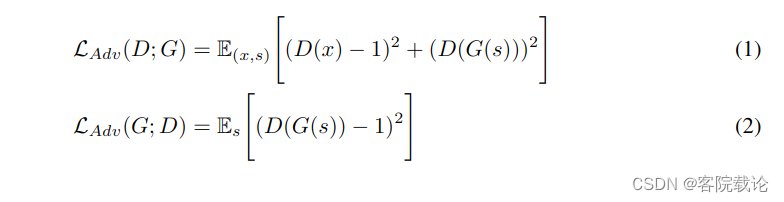
-
上述等式具体介绍如下
- 对于1式而言,是为了训练鉴定器,其需要将真实数据判定为1,生成数据判定为0
- 对于2式而言,是为了训练生成器,其生成的数据,尽量让鉴别器判定为1.
-
Mel-Spectrogram Loss 除了GAN的损失函数,我们还增加了梅尔损失函数,用来改良生成器的训练效率和生成音频的保真度。这里参考了两篇论文的思路
- 2017年的《Image-to-Image Translation with Conditional Adversarial Networks》,为了生成更加贴近于现实的结果,GNA模型增加了重建损失函数。
- 2020年的《Extremely lightweight vocoders for on-device speech synthesis.》通过联合优化多分辨率频谱图和对抗损失函数,可以有效地捕获时频分布。
- 本文使用了梅尔频谱图损失函数,因为梅尔频谱图更加符合人类的听觉系统的特性,能够提高声音的感知质量。梅尔损失函数是计算由生成器合成的声音的波形图的梅尔频谱图和实际波形图的梅尔频谱图的L1距离。具体公式如下。其中 ∅ \varnothing ∅是将波形图转换为对应的梅尔频谱图,梅尔频谱图损失函数帮助生成器根据输入条件合成更加真实的波形图,同时在早期阶段能够帮助稳定训练过程。
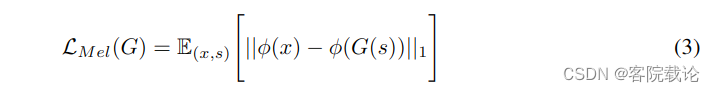
- Feature Matching Loss: 特征匹配损失函数是需要学习的相似性指标,用来衡量真实样本和生成样本在鉴别器上表现的特征差异来衡量。之前有人用过,效果不错,我们也采用,将之作为训练生成器的附加损失函数。需要提取出鉴别器的每一个中间特征,然后计算生成样例和真实样例在特征空间中的L1距离。具体定义如下。其中 T T T表示为鉴定器的层数, D i D^i Di和 N i N_i Ni分别表示第i层的特征值和特征的数量。
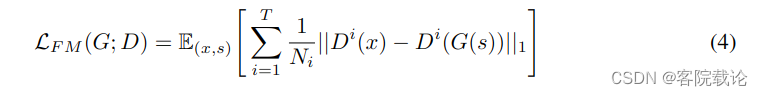
- Final Loss 最终的损失函数如下,下面分别是对生成器和鉴定器的损失函数,5式是生成器的损失函数,6是鉴定器的损失函数,其中 λ f m = 2 \lambda_{fm} = 2 λfm=2和 λ m e l = 45 \lambda_{mel} = 45 λmel=45
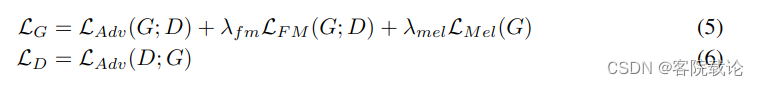
- 因为我们的鉴定器具分别是MSP和MPD构成的,所以可以分别将上述两个式子转为如下两个式子, D k D_k Dk表示在MPD和MKD中第 k k k个子鉴定器。
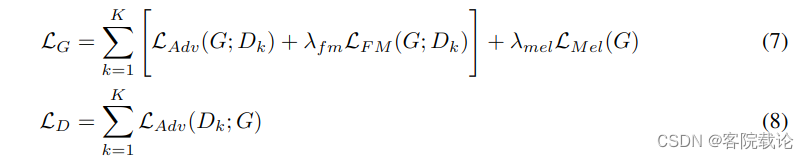
3 Experiments
- 为了和其他的模型进行公平并且可重复的比较,我们使用了大多数语音合成模型用来训练的LJSpeech数据集。这个数据集由1300个短的音频片段构成,每一个片段都是单人语音,累积起来大约有24小时。音频的格式是16位的PCM,采样率是22kHz,并且是在没有任何操作的情况下使用的。HiFi分别与WaveNet、WaveGlow以及MelGAN进行比较。我们使用的模型的权重是经过预先训练的。
- 为了评估HiFi-GAN对不可见说话人的梅尔谱图反演的通用性,我们使用了VCTK多说话人数据集(Veaux等人,2017),该数据集由109名不同口音的母语英语使用者发出的大约44,200个短音频片段组成。音频剪辑的总长度约为 44 小时。音频格式为16位PCM,采样率为44 kHz。我们将采样率降低到 22 kHz。我们随机选择了九个说话者,并从训练集中排除了所有音频片段。然后,我们用相同的数据设置训练了MoL WaveNet、WaveGlow和MelGAN;所有模型都经过训练,直到2.5M步
- 为了评估音频质量,我们通过 Amazon Mechanical Turk 众包了 5 级 MOS 测试。MOS 分数以 95% 的置信区间 (CI) 记录。评分者随机听测试样本,允许他们一次评估每个音频样本。对所有音频片段进行归一化,以防止音频体积差异对评分者的影响。第 4 节中的所有质量评估都是以这种方式进行的,并且不是来自其他论文。
- 根据最近关于神经网络效率的研究趋势,在 GPU 和 CPU 环境中测量合成速度(Kumar 等人,2019 年,Zhai 等人,2020 年,Tan 等人,2020 年)。使用的设备是单个 NVIDIA V100 GPU 和 MacBook Pro 笔记本电脑(Intel i7 CPU 2.6GHz)。此外,我们对所有模型进行了 32 位浮点操作,没有任何优化方法。
- 为了确认合成效率和样本质量之间的权衡,我们基于生成器 V 1、V 2 和 V 3 的三种变体进行了实验,同时保持相同的鉴别器配置。对于 V 1,我们设置 hu = 512,ku = [16, 16, 4, 4],kr = [3, 7, 11],Dr = [[1, 1], [3, 1], [5, 1]] × 3]。V 2 只是 V 1 的较小版本,其隐藏维度 hu = 128,但感受野完全相同。为了进一步减少层数,同时保持感受野宽,仔细选择 V 3 的内核大小和膨胀率。模型的详细配置在附录 A.1 中列出。我们使用 80 个波段梅尔谱图作为输入条件。FFT、窗口和跳数分别设置为 1024、1024 和 256。该网络使用AdamW优化器(Loshchilov and Hutter, 2017)进行训练,β1 = 0.8, β2 = 0.99,权值衰减λ = 0.01。学习率衰减在每个epoch调度一个0.999因子,初始学习率为2 × 10−4。
问题
- PCM是什么
- PCM是脉冲编码调制,用于以数字表示音频信号的方法。16位的PCM表示音频数据中,每个样本都由16位整数表示,声音振幅是96dB
4 Results
4.1 Audio Quality and Synthesis Speed
4.2 Ablation Study
4.3 Generalization to unseen Speakers
4.4 End-to-End Speech Synthesis
5 Conclusion
-
在这篇文章中,我们引入了HiFi-GAN,它能够有效合成高质量的语音音频。最重要的是,我们提出的模型在效果比目前已经公开的模型产生的声音质量都要好,甚至和实际人的声音质量相当。我们主要是受到音频信号的是有多个不同周期的正弦信号构成的特征启发,并将之应用到神经网络中,同时通过消融实验证明了我们提出的鉴别器能够影响声音合成的质量。除此之外,我们也做了很多在声音合成领域的应用相关的试验,并且证明了,效果都很棒。
-
HiFi-GAN展示了对未见说话者的泛化能力,并能在端到端的设置中从噪声输入中合成与人类质量相当的语音音频。此外,我们的小型模型在CPU上生成样本的速度比实时快一个数量级,同时展示了与最好的公开可用的自回归对应模型相当的样本质量。这显示了向低延迟和内存占用的设备自然语音合成的进展。
-
最后,我们的实验表明,可以使用相同的判别器和学习机制训练具有各种配置的生成器,这表明可以根据目标规格灵活选择生成器配置,而无需对判别器进行耗时的超参数搜索。
-
我们将HiFi-GAN作为开源发布。我们希望我们的工作将为未来的语音合成研究提供基础。
-
简单来说,这篇论文提出了一个新的语音合成模型HiFi-GAN,它在语音合成的质量和效率上都取得了显著的进步。作者希望这个模型能为未来的语音合成研究提供基础,并期待它能在实际应用中发挥作用。
总结
-
这篇文章,是基于GAN生成对抗网络的声音生成模型,是将将梅尔频谱图转成高频率的波形图。相较于一般的的生成网络,这篇文章主要是对鉴定器进行了自己的改动,增加了MPD和MSD。还是需要结合代码进行细致地看看。
-
这个单纯算是入门,因为我想做的vq-vae进行声音生成的项目里用到了这个组件,而且是十分重要的组件之一,我就来读了这篇文章,后面还会结合代码对这篇文章在进行加深了解,现在仅仅是对论文有了了解。
-
马上就开组会了,心里有点慌,主要是因为我没和老师讲过我要做这个方向,不过原来让我做的东西,并没有任何消息,而且也被踢出去了,做了那么就,还是继续做吧。不过如果想要说服他,我还得给他一个具体的情况说明,或者文章综述。
参考
-
大部分内容到参考自chatGPT-4,并使用browserpilot插件
-
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
-
可以加群一块讨论一下关于声音生成的技术
- 群号:722462964

