
- 1graphpad做饼图_要想饼图更出彩,还得试试这款数据分析工具
- 2Android开发——回调(Callback)_android callback
- 3Win11家庭版,鸿蒙DevEco 模拟器启动失败,成功解决了_鸿蒙app 模拟器启动
- 4(zhuan) Recurrent Neural Network
- 5经典进程同步问题--生产者消费者问题_假定在生产者和消费者之间有一个公用缓冲池,具有n个缓冲区。生产者进程和消费
- 6Prism研究(for WPF & Silverlight)【转载】
- 7Altium designer中,如何在字母上面加上横线_ad18怎么在字母上加横线
- 8Pikachu漏洞靶场系列之SQL注入_皮卡丘靶场报错注入
- 9adb kill -server 提示adb.exe: unknown command kill解决办法
- 10Python+PyQt5+Mysql(二)通过QSqlQueryModel实现QTableView分页显示,表头排序等功能_pyqt5写一个分页表格界面
论文阅读笔记 | AAAI-2022 | 提高文本生成任务的语义覆盖率_基于e2e数据集的表格到文本生成任务
赞
踩
原文标题:Search and Learn: Improving Semantic Coverage for Data-to-Text Generation
原文链接:https://arxiv.org/pdf/2112.02770v1.pdf
目录
2、Search-Based Text Generation.
2、Search to Improve Semantic Coverage
3、Second-Stage Fine-Tuning T5 with Search Results
一、Introduction
数据到文本的生成任务是指,将结构化的数据信息转化为人类可读的文本内容。传统方式是手工设定规则并归纳;现在的方法是用序列对序列的循环神经网络,但是它需要大量的并行训练数据,不仅浪费时间还难以应用。
于是有人用复制机制微调预训练语言模型,能够有效减少所需样本量,但是语义覆盖率低,一些重要的数据信息有时会被遗漏,没有显示在文本内容中。
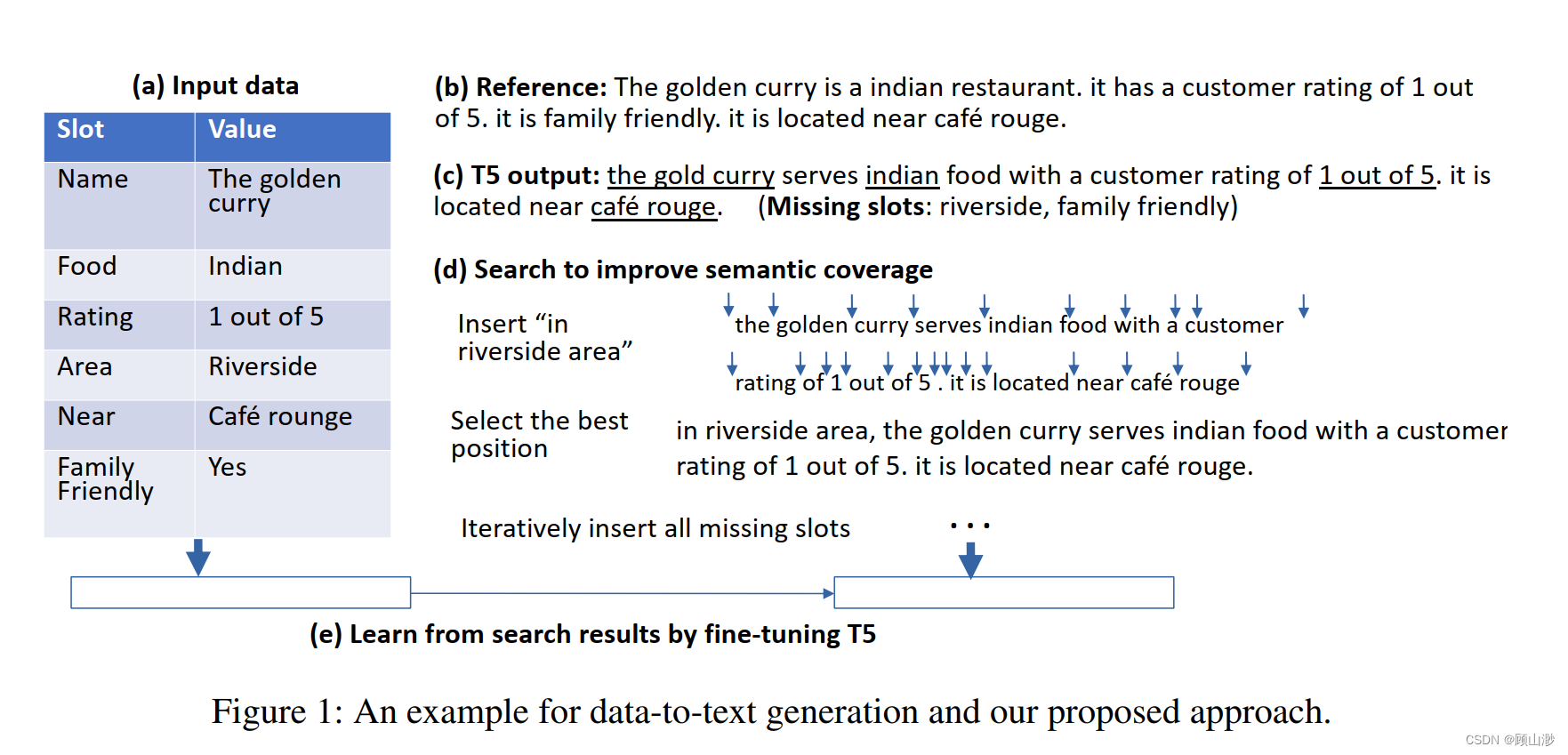
本文使用S&L(搜索和学习)方法,同样微调预训练T5语言模型,然后将遗漏的信息插入到生成的文本内容中。具体是指:尝试所有可插入的位置,然后选出最合适的那一个。
二、Related Work
1、Data-to-Text Generation.
传统方法是使用手工设计规则并统计归纳,但是生成的文本比较呆板。后来人们使用神经网络方法,但是这些系统需要大量并行数据来训练文本生成器。
最近,有人使用复制机制微调预训练语言模型(LMs),但是由于语义覆盖率低,一些信息有时会被遗漏。本文重点解决了这个问题。
2、Search-Based Text Generation.
过去人们用各种搜索方法解决了无监督文本生成问题,基本思想是定义一个启发式目标函数(通常涉及语言流畅性、连贯性等分数),并通过面向目标的文字编辑生成文本。
与前人不同,本文是第一个用搜索和学习方法解决该问题的。我们用到了微调预训练T5语言模型,同时我们的目标是提升语义覆盖率,而不是提升语言流畅度。
三、Problem Formulation
以表格形式输入,每一行表格都是以名称-价值对的形式,记为:![]()
输出形式为![]()
小样本学习对NLG非常重要,不仅减少人类的工作量,也缓解了冷启动问题
四、Proposed Model
1、First-Stage Fine-Tuning T5
T5虽然是一个预训练语言模型,但实际上它从没受到过数据到文本的生成任务训练。
本文仅用几百条数据就完成了模型微调:用自动回归的方式估计条件概率,并用交叉熵损失进行微调。
2、Search to Improve Semantic Coverage
语义覆盖率低的问题主要是由于小样本的并行语料库不能完全支持T5学习输入输出之间的对应关系。为了解决这个问题,本文提出了一个简单有效的方法,将丢失的信息重新插入到文本中。
首先,依次检索数据信息有没有出现在文本内容中。对于没有出现的数据信息,找到文本中所有可能插入的位置,然后选出最合适的那一个。这实际上也可以被认为是一种贪婪算法。
3、Second-Stage Fine-Tuning T5 with Search Results
在解决了语义覆盖率的问题后,本文还提到了一些缺点:生成的文本不够流畅,并且在有多个候选输出时,评估效率很慢。于是对T5做了第二次微调。
给定一个输出表,用T5生成候选文本并执行搜索;搜索结果作为原语料库的扩充数据集,然后还是使用交叉熵损失进行微调。
4、Inference
两次微调使得这种S&L方法几乎达到了完美的语义覆盖率。
五、Experiments
1、E2E Dataset
这是一个众包数据集,包含五万个餐厅相关的表格-文本对。每个数据样本中输入3-8条数据信息,输出1-2句话。
由于BLEU指标与人类的判断有一定的差异,而PARENT表现得更好,所以本文主要使用PARENT指标。同时我们也对文本流畅度、语义覆盖率和错误概率做了估计
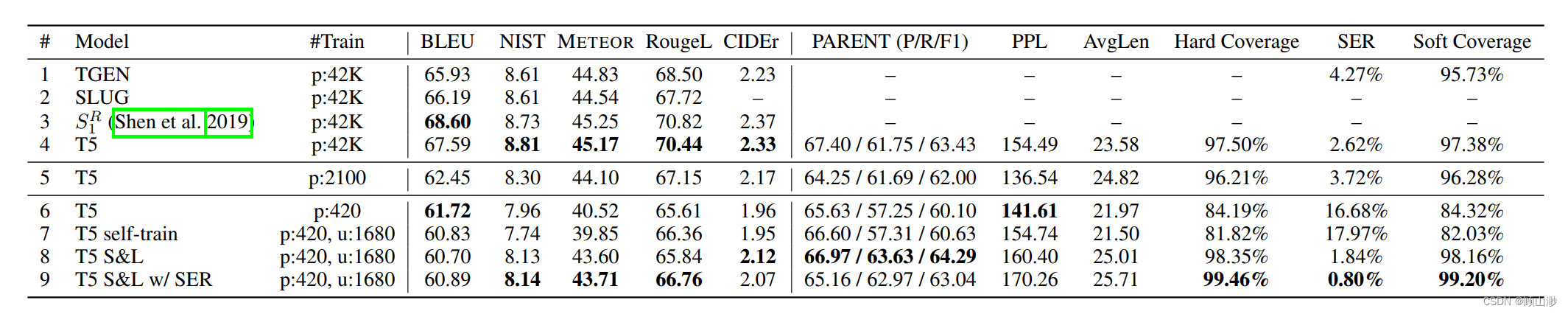
从上表实验结果可以看出,当样本量从42k降低到420时(第4-6行),软、硬覆盖率均有显著下降。但是模型经过微调后(第7-9行),模型性能有了很大提升。
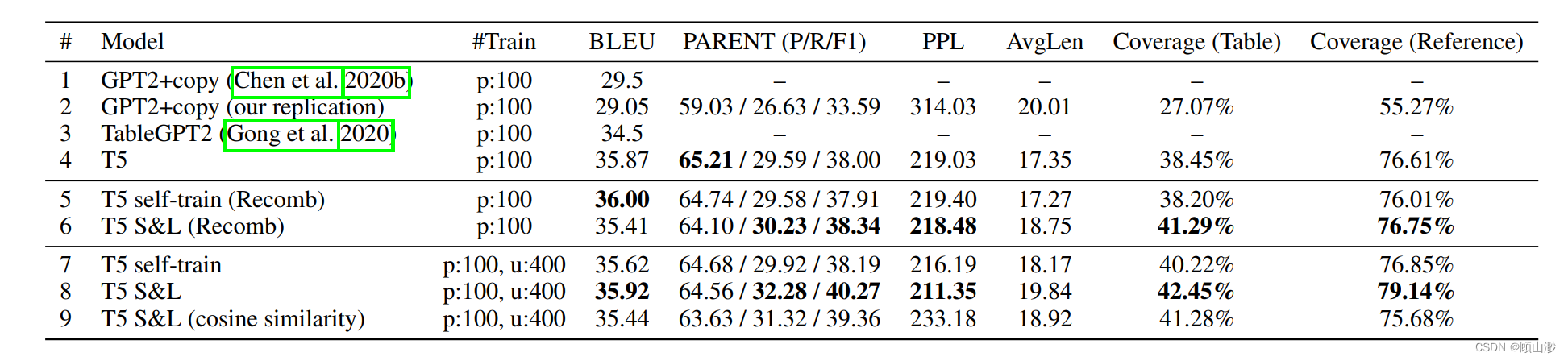
2、WikiBio Dataset
数据集包含了700k维基百科的英文传记信息。
3、Analysis
用人工评估进一步评价模型的覆盖率、流畅度和整体质量。
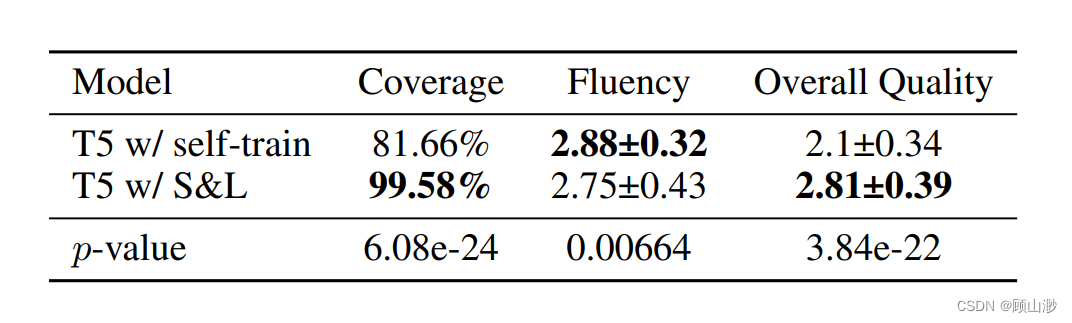
结果自然也是好的。
六、Conclusion
本文提出的S&L模型解决了小样本数据的文本生成任务语义覆盖率低的问题,同时兼具较好的句子流畅度。

