
- 1是的,Android版Edge浏览器支持Extension(插件/扩展)了
- 2php制作水印图片,PHP实例制作水印图片
- 3springBoot导出excle文件_excelexportutil.exportexcel null
- 4ALSA(一)_gstreamer录音alsasrc
- 5ati-driver在2.16.18-gentoo-r2内核编译有问题及解决方法!!!_uts_release
- 6Android开发_Notification_android notification setongoing
- 7H5 跳转Flutter APP问题:在Flutter中解决H5能够打开APP并接收H5传递的参数_h5打开app指定页面 flutter
- 8stm32之智能小车总结_stm32智能控制小车报告
- 9第一次接触低代码平台 AppCube,还是有点门槛的_winform低代码平台
- 10[AIGC] 使用Spring Boot进行单元测试:一份指南
九大遥感目标检测数据集(附下载链接)_遥感数据集
赞
踩
码字不易,点个赞再走呗
1. UCAS-AOD 3.25G
1.1基本信息
UCAS-AOD (Zhu et al.,2015)用于飞机和汽车的检测,包含飞机与汽车2类样本以及一定数量的反例样本(背景),总共包含2420幅图像和14596个实例。论文中特别提到了目标检测的方向健壮性,所以在数据集标注过程中作者对数据进行了一定程度的筛选,使得图像中的物体方向分布均匀,数据集具体内容如下:

1.2数据说明
1.2.1图像定义
本数据集中目标为航拍图像下的飞机和车辆。
- 1
1.2.2数据来源
使用Google Earth软件在全球部分区域中截取的图像
- 1
1.2.3数据格式
数据集分为CAR、PLANE、NEG三个文件,CAR、PLANE为正例图像,NEG为反例图像。正例图像以P+数字序号命名,反例图像以N+数字序号命名,所有图像为PNG格式,尺寸为1280x659和1372x941。
1.2.4样本标注
UCAS-AOD采用HBB(horizontal bounding box)的标注方法,图像的groundtruth采用txt格式保存,以图像的同名文档方式存储。对于整理好的txt文档数据,每列的属性分别为x1,y1,x2,y2,x3,y3,x4,y4,theta,x,y, width,height,属性说明如下:

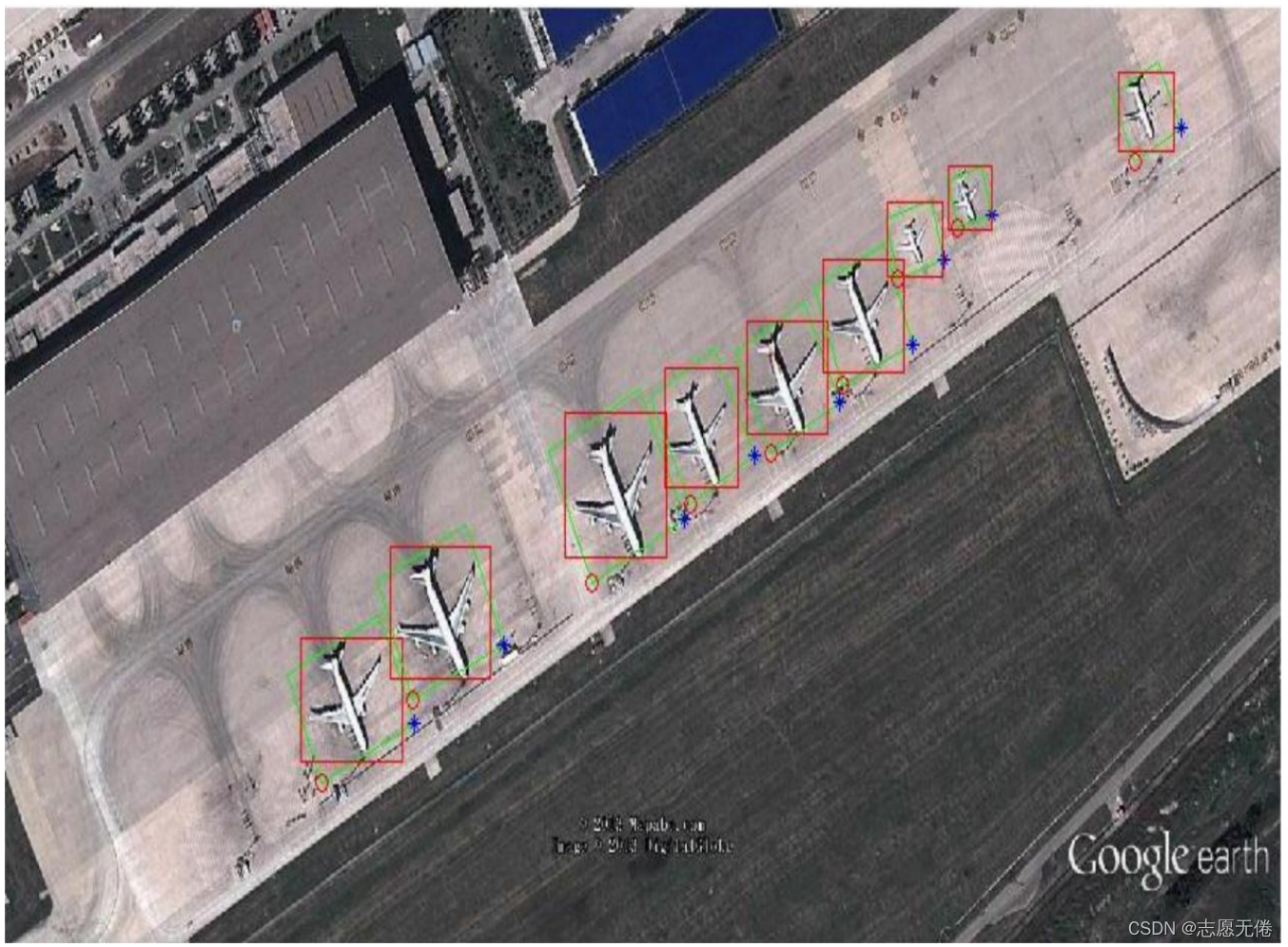
1.3数据示例
x1,y1,x2,y2,x3,y3,x4,y4为飞机的矩形框,即下图中的绿色框;
theta为机尾指向机头的向量与x轴正向的夹角;
x,y,width,height 为飞机的bounding box,即图中的红色矩形框。
具体的标注示意如下图所示:
- 1
- 2
- 3
- 4

2. HRSC2016 -3.86G
2.1基本信息
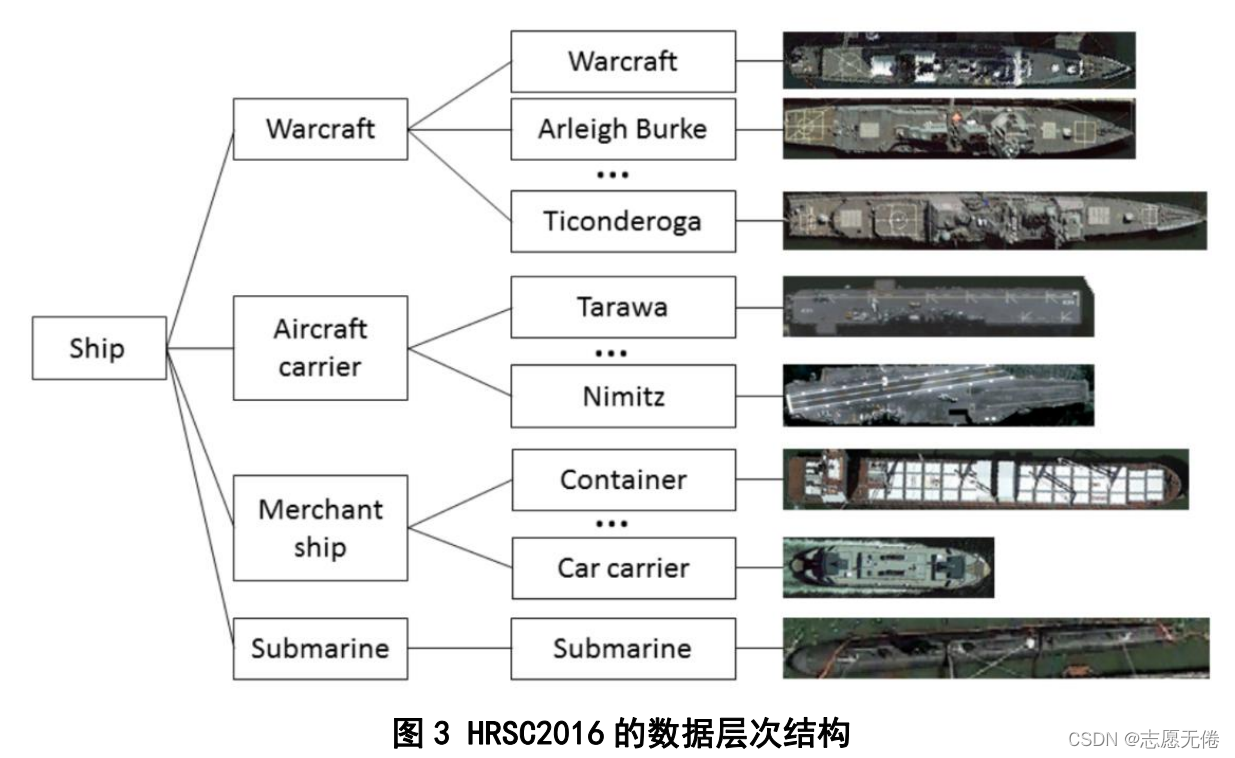
HRSC2016 (Liu et al.,2016)是西北工业大学采集的用于轮船的检测的数据,包含4个大类19个小类共2976个船只实例信息。论文中特别指出他们的数据集是高分辨率数据集,分辨率介于0.4m和2m之间。数据集所有图像均来自六个著名的港口,包括海上航行的船只和靠近海岸的船只,船只图像的尺寸范围从300到1500,大多数图像大于1000x600。
2.2数据说明
2.2.1目标图像定义
本数据集中目标为航拍图像下的船只,包括海上船只与近岸船只。作者在对船只模型进行分类时采用
了高度为3的树形结构,L1层次为Class、L2层次为category、L3层次为Type,类似生物学的分类观
点,具体表示如下:
- 1
- 2
- 3
2.2.2数据来源
使用Google Earth软件在全球部分区域中截取的图像,既包括Google Earth默认显示的图片,
又包括相同地点的历史图片。
- 1
- 2
2.2.3数据格式及规模
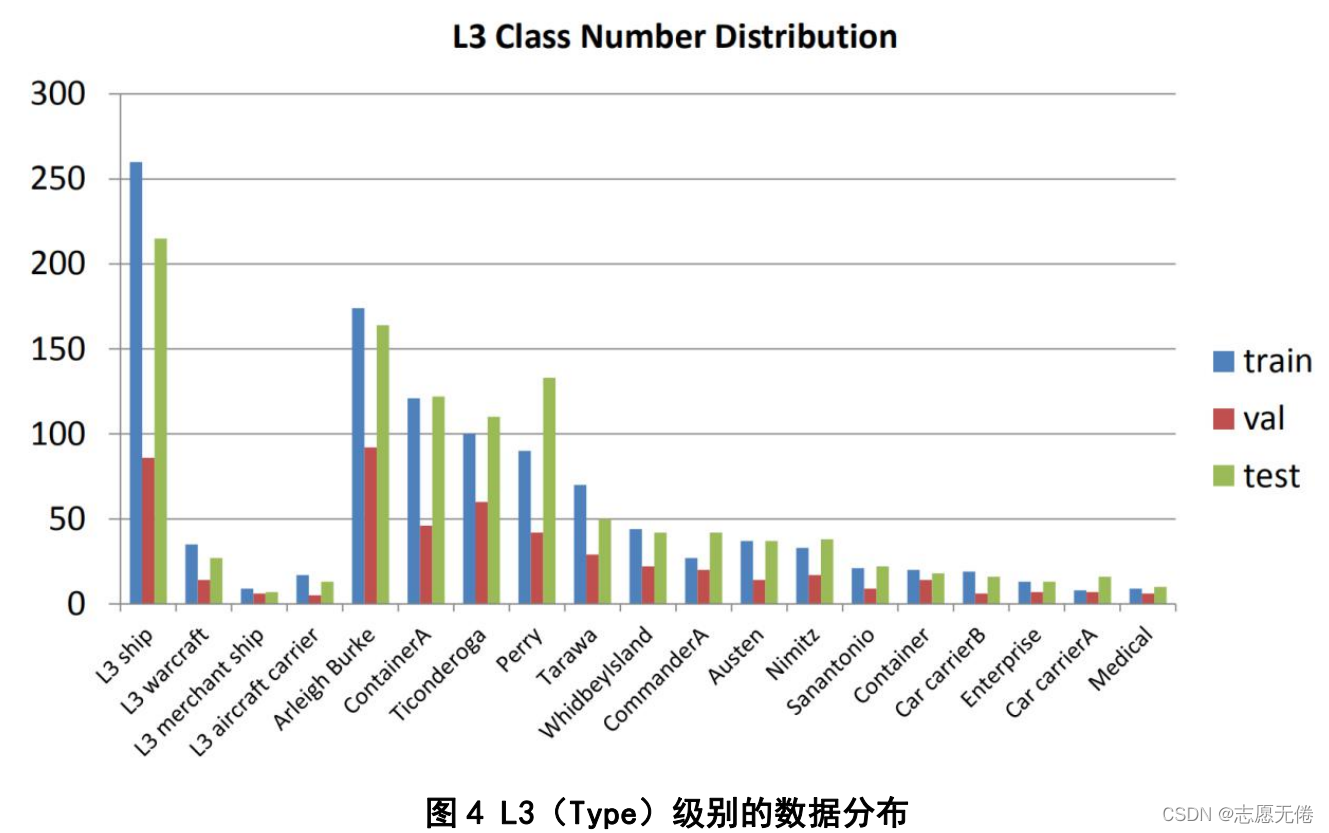
数据集分为Train、Test、ImageSets三个文件。Train、Test目录分为只包含船只图像的AllImages和只包含注释信息的Annotations,图像以港口序号顺序命名、以bmp格式存储,图像的注释信息以xml文件存储。此外,Test文件下的Segmentations文件还包含了船只分割图像,即语义分割的标签,以png格式存储。训练、验证和测试集分别包含436个图像(包括1207个样本)、181个图像(包括541个样本)和444个图像(包括1228个样本)。ImageSets目录下包含train.txt、val.txt、trainval.txt以及test.txt,保存了训练集、验证集、交叉验证集、测试集的图片编号。各类样本在训练集、验证集、测试集中的分布如下所示:
2.2.4样本标注信息
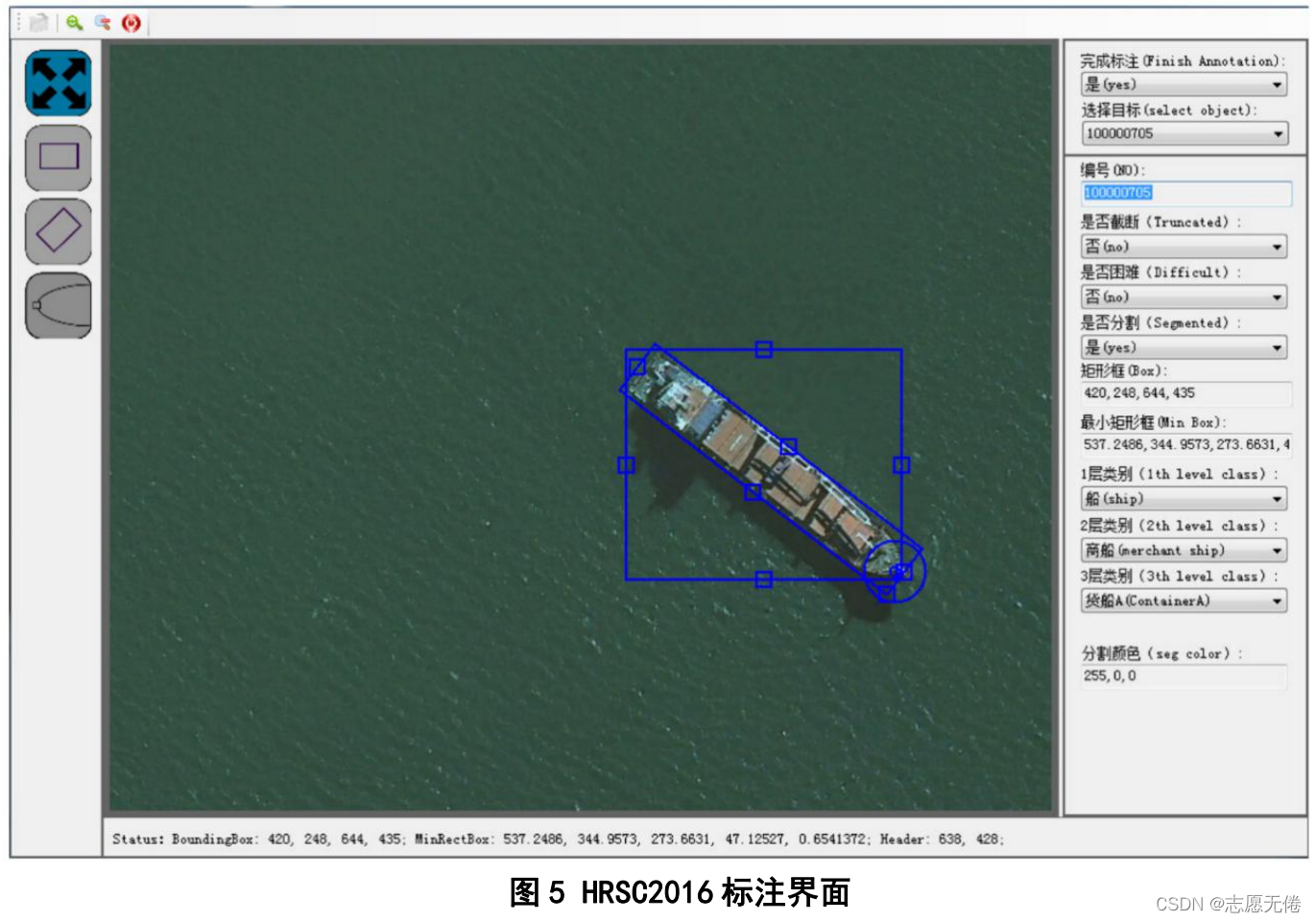
HRSC2016采用OBB(oriented bounding box)的标注方法,提供了三类标注信息,包括bounding box、rotated bounding box和pixel-based segmentation,还包括港口、数据源、拍摄时间等额外信息,部分数据标注展示如下:
<HRSC_Image>
<Img_CusType>sealand</Img_CusType>
<Img_Location>69.040297,33.070036</Img_Location>
<Img_SizeWidth>1138</Img_SizeWidth>
<Img_SizeHeight>833</Img_SizeHeight>
<Img_SizeDepth>3</Img_SizeDepth>
<Img_Resolution>1.07</Img_Resolution>
<Img_Resolution_Layer>18</Img_Resolution_Layer>
<Img_Scale>100</Img_Scale>
<segmented>0</segmented>
<Img_Havemask>0</Img_Havemask>
<Img_Rotation>274d</Img_Rotation>
<HRSC_Objects>
<HRSC_Object>
<Object_ID>100000008</Object_ID>
<Class_ID>100000013</Class_ID>
<Object_NO>100000008</Object_NO>
<truncated>0</truncated>
<difficult>0</difficult>
<box_xmin>628</box_xmin>//bounding box坐标点
<box_ymin>40</box_ymin>
<box_xmax>815</box_xmax>
<box_ymax>783</box_ymax>
<mbox_cx>719.9324</mbox_cx>//旋转后的左上角坐标
<mbox_cy>413.0048</mbox_cy>
<mbox_w>741.8246</mbox_w>
<mbox_h>172.6959</mbox_h>
<mbox_ang>1.499893</mbox_ang>//旋转角度
<segmented>0</segmented>
<seg_color>
</seg_color>
<header_x>713</header_x>//船头部信息
<header_y>777</header_y>
</HRSC_Object>
</HRSC_Objects>
</HRSC_Image>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
标注页面如下图所示:
2.3数据示例

3. NWPU VHR-10 -73.1M
3.1基本信息
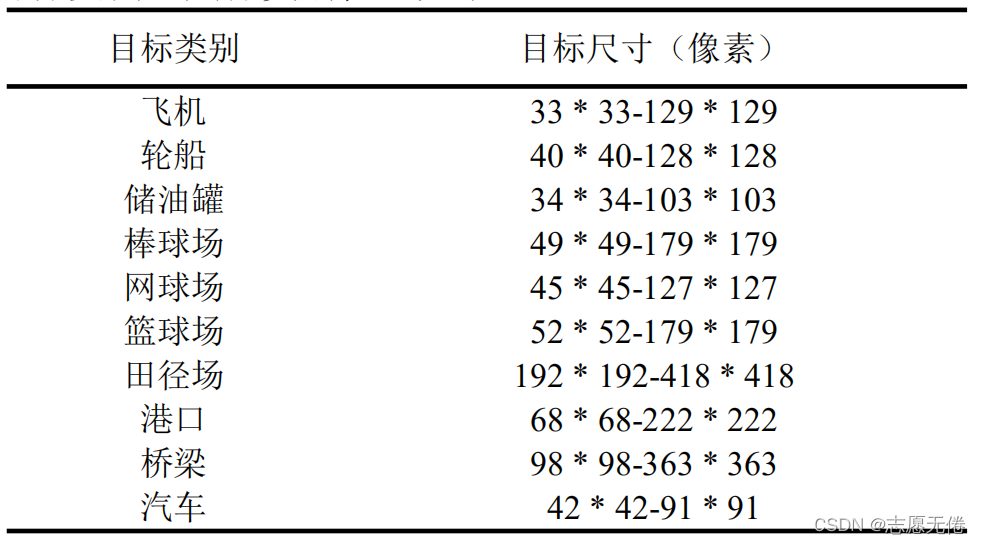
NWPU VHR-10 (Cheng et al.,2016) 这个高分辨率(VHR)遥感图像数据集是由西北工业大学(NWPU)构建的,包含10类正例样本650张以及不包含给定对象类的任何目标的150张反例图像(背景),正例图像中至少包含1个实例,总共有3651个目标实例。具体类别信息如下:
3.2数据说明
3.2.1目标图像定义
本数据集中目标为航拍图像下的目标种类,包括飞机、舰船、油罐、棒球场、网球场、篮球场、田径场、港口、桥梁和汽车共计10个类别。
3.2.2数据来源
715幅高分辨率图像使用Google Earth软件在全球部分区域中截取,85幅超高分辨率图像CIR由德国摄影测量、遥感和地理信息学会(DGPF)提供。Google Earth截取图像的分辨率介于0.5m到2m,CIR图像分辨率为0.08m。
3.2.3数据格式
数据集分为positive image set、negative image set、ground truth三个文件
positive image set目录下为正例图像,negative image set目录下为反例图像
正例、反例图像皆从001开始命名,所有图像为jpg格式。
- 1
- 2
- 3
3.2.4样本标注信息
NWPU VHR-10采用HBB的标注方法。ground truth文件夹包含650个单独的txt文件,每个文件对应于positive image set文件夹中的一个图像,这些文本文件的每一行都定义了一个ground truth边界框,格式如下:
其中(x1,y1)为bounding box的左上角坐标,(x2,y2)为bounding box的右下坐标,a为对象类别(1-飞机、2-轮船、3-储油罐、4-棒球场、5-网球场、6-篮球场、7田径场、8-港口、9-桥梁、10-汽车)。
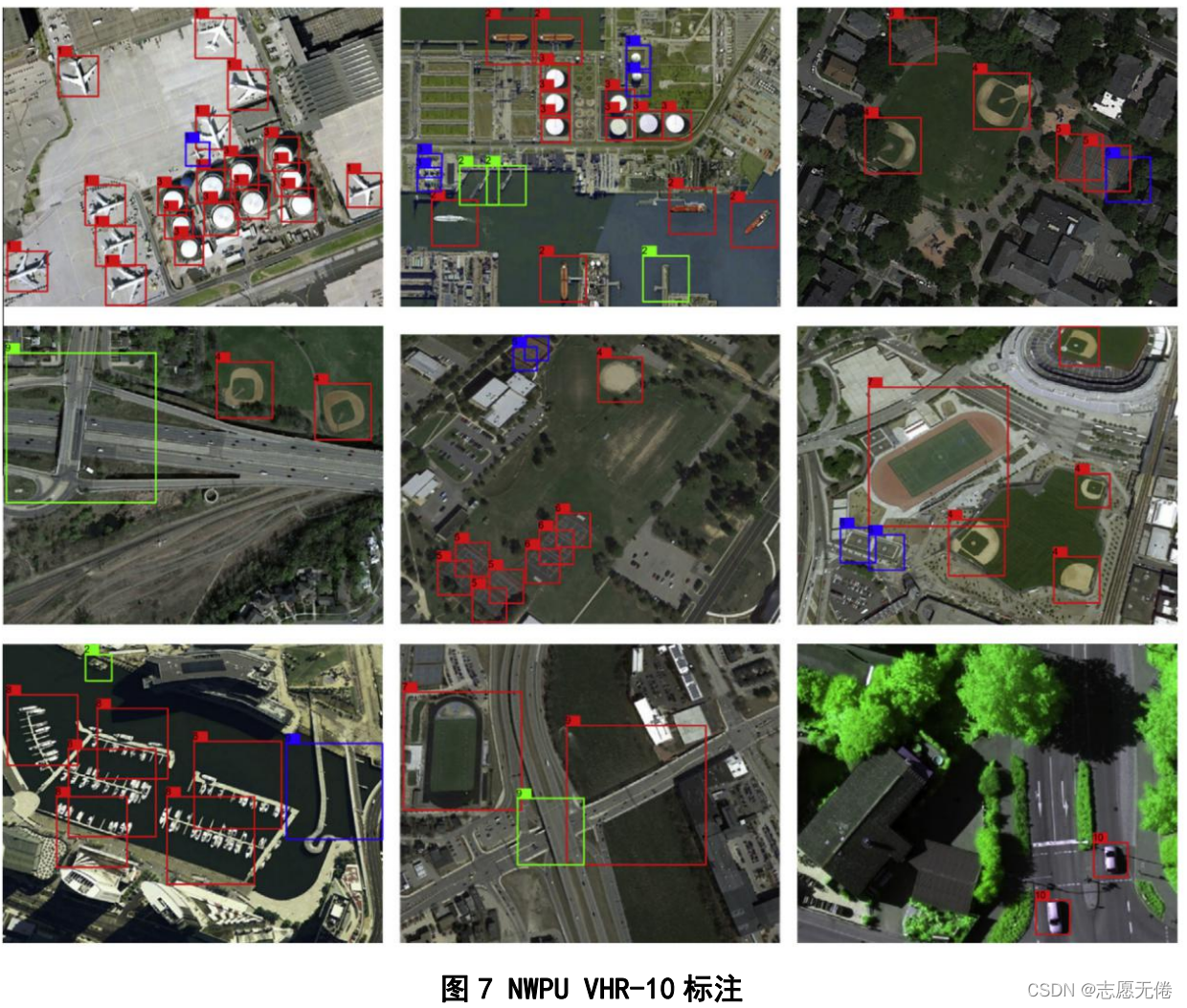
3.3数据示例

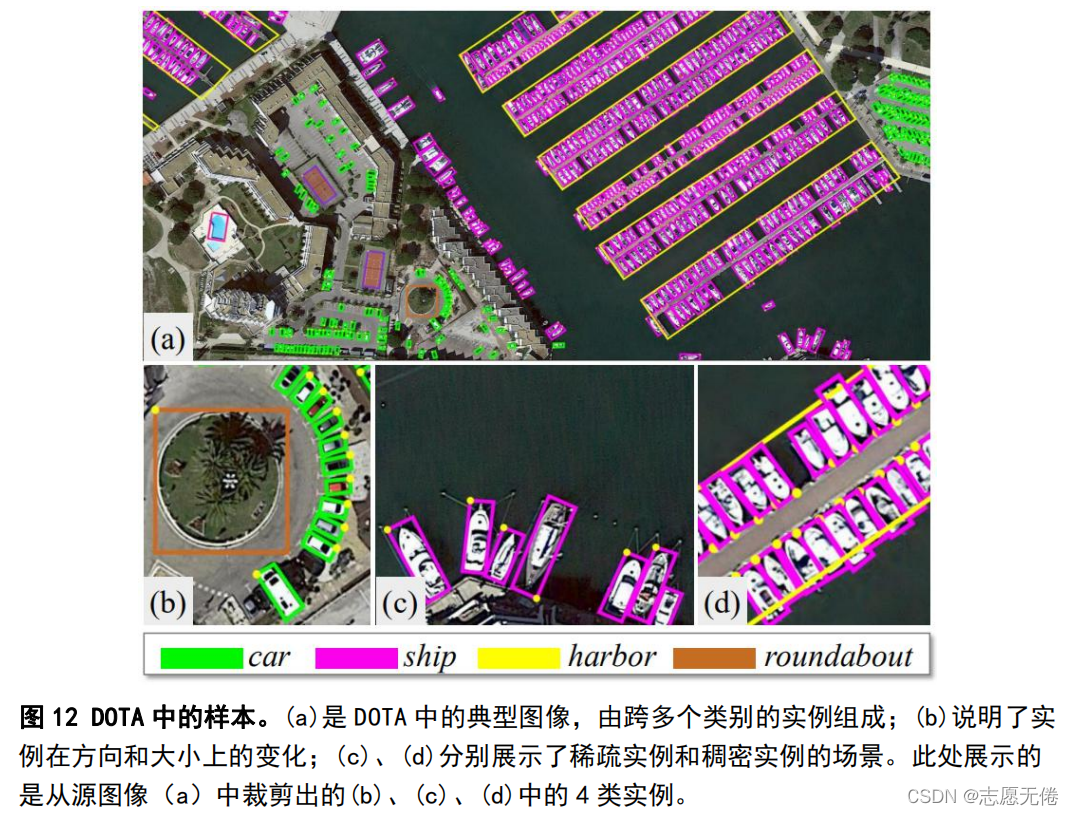
4. DOTA -18.8G
4.1基本信息
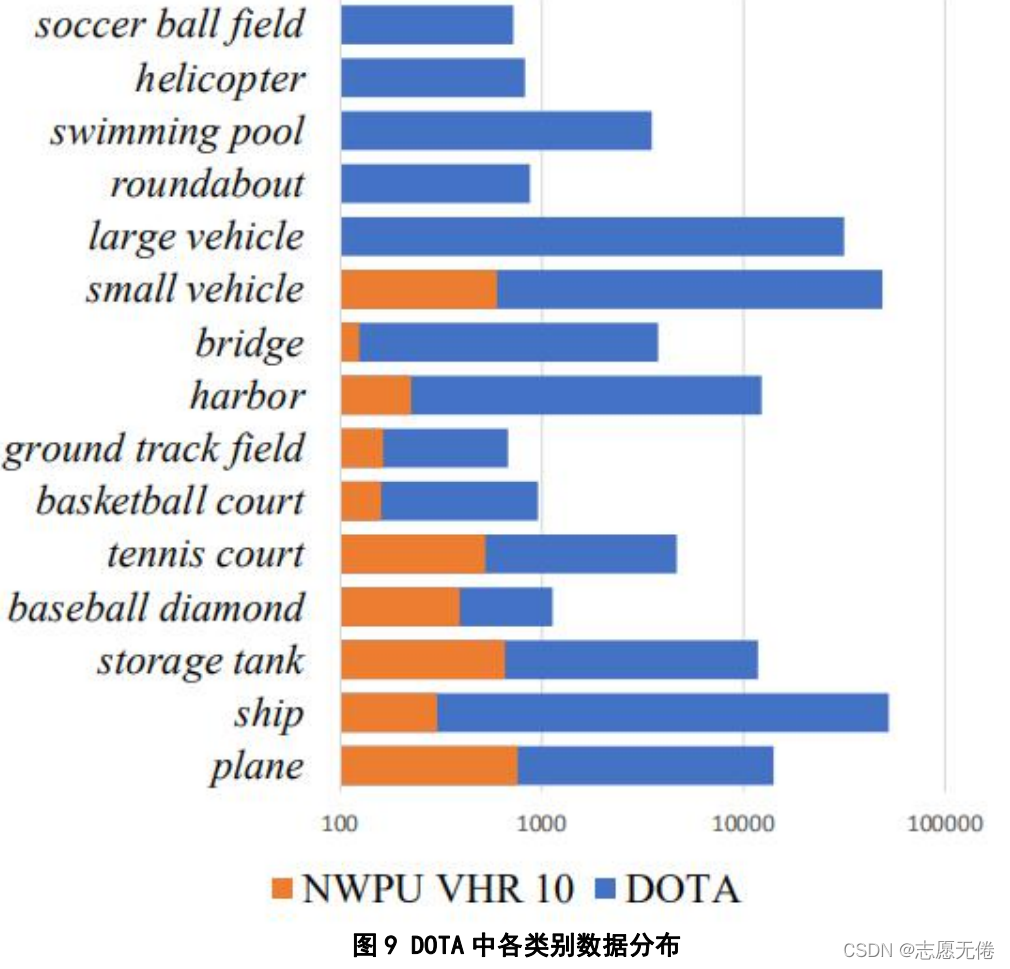
DOTA(Xia et al.,2018)是武大遥感国重实验室和华科电信学院等合作的一个航拍图像数据集,包含2806张遥感图像(图片尺寸800800到40004000),一共188282个实例,分为15个类别:飞机、船只、储油罐、棒球场、网球场、篮球场、田径场、海港、桥梁、大型车辆、小型车辆、直升飞机、足球场、立交路口、游泳池。数据集具体内容如下:
4.2数据说明
4.2.1目标图像定义
DOTA在提出之时可以称得上规模最大的航空图像数据集。DOTA与NWPU VHR-10等数据集相比,前
10类数据虽然都有,但是DOTA的数据量更多、数据注释更加丰富。此外,DOTA还将车辆数据分为大
型车辆与小型车辆,主要考虑两者之间的明显差异性;将直升飞机数据纳入到数据集中,主要考虑移
动目标在航空图片中也有十分显著的作用;将立交路口纳入到数据集中,主要考虑到它在道路分析中
的作用。
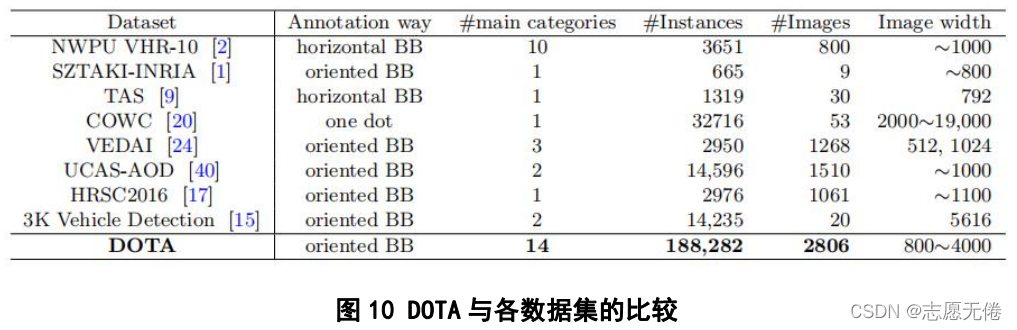
DOTA与当时的航空图像数据集进行了比较,指出了这些数据集普遍存在的缺点:1)数据规模小;
2)类别数量少;3)图像分辨率低;4)注释不丰富,并且无法形成数据与真实世界之间的映射,具体
比较如下所示:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4.2.2图像数据来源
使用Google Earth平台和中国资源卫星数据和应用中心在全球部分区域中截取图像。
- 1
4.2.3数据格式
数据集分为train、val、test三个文件。三个文件下都包含图片数据images文件夹,文件中的图片以
P+图片编号命名,所有图像为PNG格式,图像尺寸介于800*800和4000*4000之间,实例尺寸介于0-
2500像素之间,具体实例尺寸分布如下图所示:
- 1
- 2
- 3
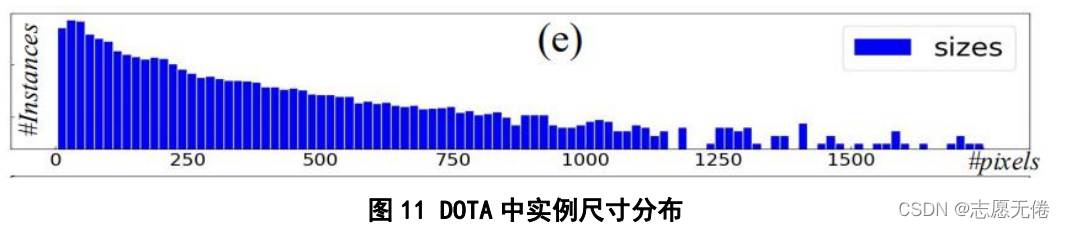
train、val文件下还包含对应图片的标注信息,分为DOTA-v1.0和DOTA-v1.5版本, v1.5包含16个类别中的40万个带注释的对象实例,是v1.0(15个类别)的更新版本。它们都使用相同的航拍图像,但是v1.5修改并更新了对象的注释,主要对v1.0中标注的10像素以下的小对象实例进行了额外注释,v1.5的类别也得到了扩展,增加了集装箱起重机这一类别。
4.2.4样本标注信息
DOTA采用OBB的标注方法,图像的ground truth采用txt格式保存,以图像的同名txt文档存储。图像中
每个实例都由一个四点确定的任意形状和方向的四边形边界框标注,顶点按顺时针顺序排列。文档中
包含10列信息,每列的属性分别为x1,y1,x2,y2 x3,y3,x4,y4,category,difficult,属性说明如下:
- 1
- 2
- 3

4.3数据示例

5. DIOR -7.19G
5.1基本信息
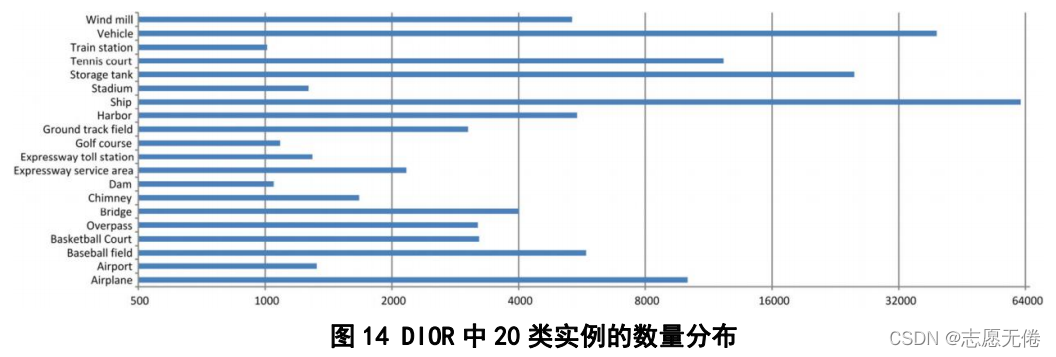
DIOR (Li e al.,2020)是由西工大韩军伟课题组提出的一种用于光学遥感图像中目标检测的大规模基准数据集,包含23463幅遥感图像(图片尺寸为800*800)和190288个实例,同时论文也对近年来基于深度学习的目标检测方法进行了综述。数据集中的实例分为20个类别:飞机、飞机场、棒球场、篮球场、桥梁、烟囱(工业)、水坝、高速公路服务区、高速公路收费站、港口、高尔夫球场、田径场、立交路口、体育馆、储油罐、网球场、火车站、汽车、风力发电机。各实例具体分布如下:
5.2数据说明
5.2.1目标类别选择
DIOR数据集在选择目标类别时,类似于DOTA采取的方法,既选择了之前的数据集普遍存在的类别,
例如NWPU VHR-10中的10个类别,也考虑到了遥感图像目标监测任务的具体需求:
- 1
- 2
1) 交通基础设施在运输分析中至关重要,所以项目组将火车站、高速公路收费站、高速公路服务区等基础设施纳入进DIOR的类别中。
2) 大多数的目标类别是从市中心选取的,DIOR考虑了近郊地区的基础设施,如水坝、风力发电机等设施,用以提高遥感数据的多样性。
5.2.2数据来源
使用Google Earth软件在全球部分区域中截取的图像。
- 1
5.2.3数据格式
数据集分JPEGImages-trainval、JPEGImages-test、Annotations、ImageSets四个文件夹。JPEGImages-trainval、JPEGImages-test中存放遥感图像(二者数量之比接近1:1),图像以5位序号命名,所有图像尺寸均为800*800、分辨率介于0.5m到30m、格式均为JPG。Annotations中存放了23463张图像的注释信息,具体信息如下:
<annotation>
<filename>00001.jpg</filename>
<source>
<database>DIOR</database>
</source>
<size>//图片尺寸及深度
<width>800</width>
<height>800</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>golffield</name>//类别
<pose>Unspecified</pose>
<bndbox>
<xmin>133</xmin>//bounding box坐下角坐标(xmin,ymin)
<ymin>237</ymin>
<xmax>684</xmax>//右上角坐标(xmax,ymax)
<ymax>672</ymax>
</bndbox>
</object>
</annotation>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
可以看得出,DIOR数据集规模虽然大,但是数据注释比较简略,采用了最基础的Bounding box方法,
只包含两个坐标点。ImageSets中存放的是训练集、验证集、测试集的编号,以txt文件存储,用于制
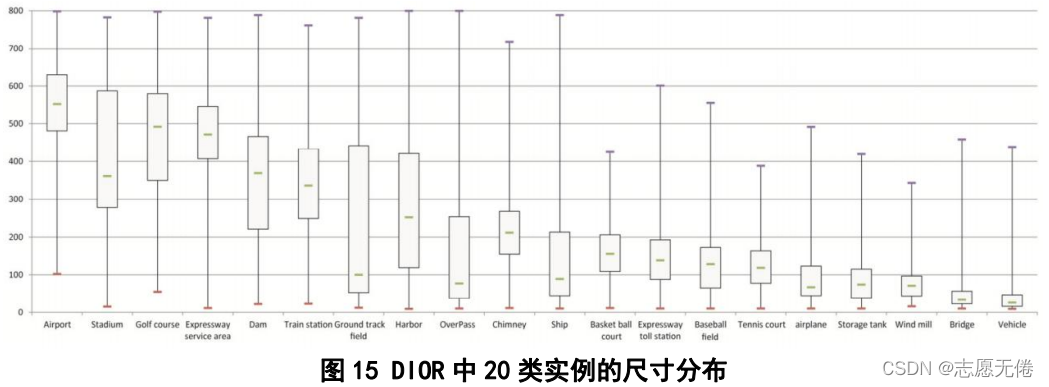
作DataLoader加载数据。另外,图片中各实例的尺寸大小如下:
- 1
- 2
- 3
5.2.4样本标注信息
DIOR采用HBB的标注方法,使用Python脚本Labelme进行图片标注,主要包含目标类别信息及
Bounding Box左下角坐标和右上角坐标信息。
- 1
- 2
5.2.5数据优势
1)数据规模大。DIOR包含23463幅遥感图像及192472个目标实例,包含20类目标。
2)实例对象尺寸丰富。相同实例具有尺寸的多样性,例如大型车辆与小型车辆、大型货轮与小型游艇等,方便对不同尺寸的同类实例进行检测。
3)图像多样性丰富。DIOR数据集采集自全球80多个国家,覆盖了不同的天气、季节、成像条件、图像质量等因素,能够实现与现实世界的映射。
4)高类间(inter-class)相似性和高类内(intra-class)差异性。例如下图所示的第一行图片是不同类别的桥梁和水坝,二者具有类间相似性;第二行图片是相同类别的工业烟囱,二者具有类内差异性。 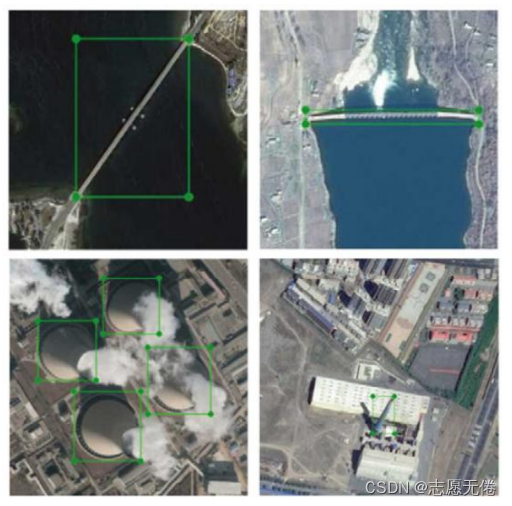
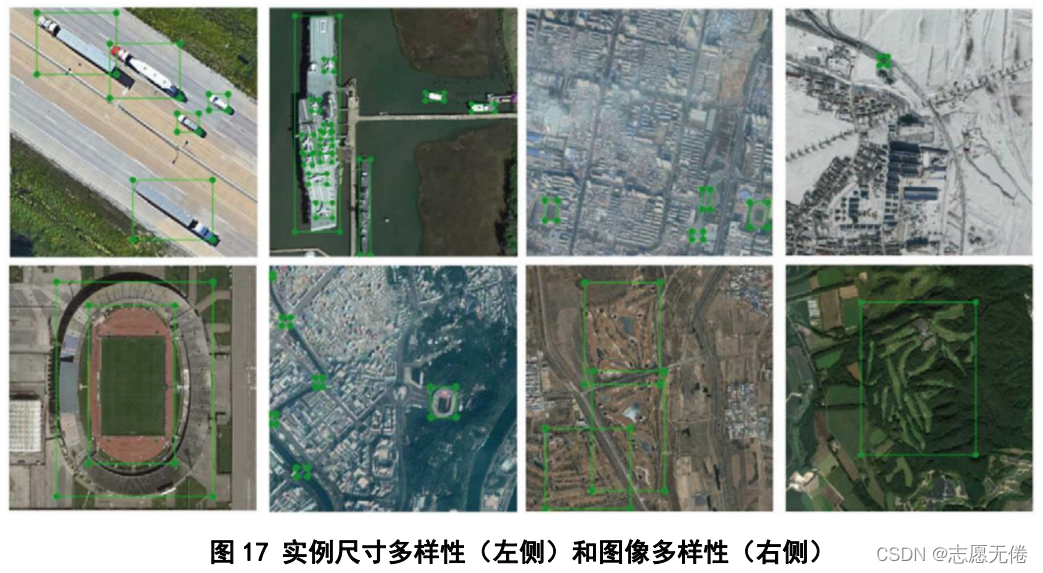
5.3数据示例

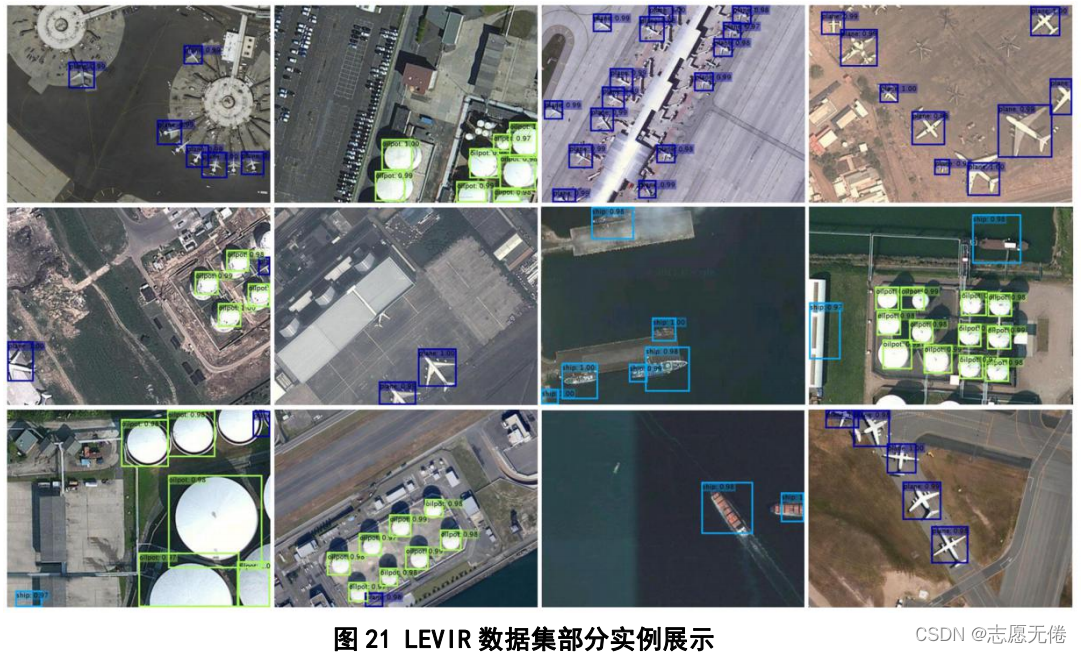
6. LEVIR -1.56G
6.1基本信息
LEVIR (Shi et al.,2018)是由北航史振威教授领导的视觉与遥感实验室提出的一种新的遥感目标检测数据集,包含21952幅遥感图像(图片尺寸为600*800)和11028个实例。数据集中的实例分为3个类别:飞机、船舶、储油罐,其中,飞机实例有4724个、轮船实例有3025个、储油罐实例有3279个。
6.2数据说明
6.2.1目标类别
LEVIR数据集容纳了大多数人类居住环境的地表特征,例如城市、乡村、山地和海洋等区域;不包含
极端的陆地环境,例如沙漠和冰川。数据集中有3种类型的目标:飞机、船舶(包括近海船只和离岸船
只)和储油罐。
- 1
- 2
- 3
6.2.2数据来源
使用Google Earth软件在全球部分区域中截取的图像。
- 1
6.2.3数据格式
LEVIR数据集只包含imageWithLabel这1个文件夹,文件夹下是图像及对应的标注信息,图像从00001开始顺序命名,标注文件格式为txt文档,与对应的图片同名。所有图像尺寸均为600*800、分辨率介于0.2m到1m、格式均为JPG。注释文件中的标注信息也很简略,包含5列属性,具体信息如下:
label使用1、2、3标注,1代表飞机、2代表船舶、3代表储油罐;
xmin-ymax即BB的左下角坐标和右上角坐标。
LEVIR数据集并没有将正例和背景分开,所以虽然有20000+图片,但是实例个数只有10000+,并且背景图片也有相应的txt文件所对应,且txt文件中的内容为空,所以数据集中的txt文件大多数是空文件。
- 1
- 2
- 3
6.2.4数据优势
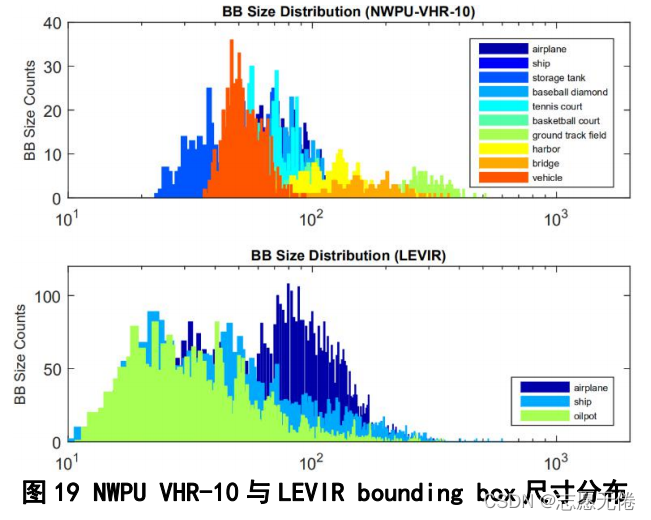
1)实例尺寸分布平衡。
与NWPU VHR-10数据集相比,LEVIR中的实例尺寸分布较为均匀,特别是在10-100像素的实例并没有体现出较大的分布偏差;而NWPU VHR-10中的大尺寸实例与小尺寸实例存在明显的分布间隔。
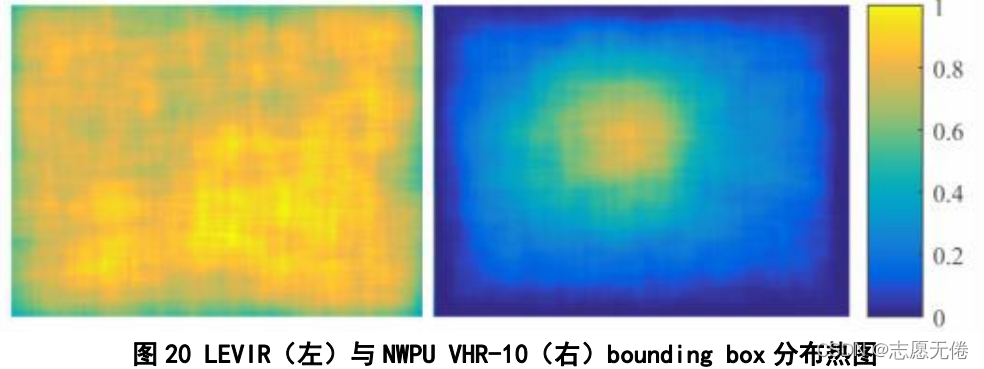
2)实例分布均匀。
与NWPU VHR-10数据集相比,LEVIR中的实例在图像中的位置比较均匀,各个位置都有分布;而NWPU VHR-10中的实例则过于集中在图像的中央,不能体现出实例的平衡性。
6.3数据示例
7. xView -14.2G
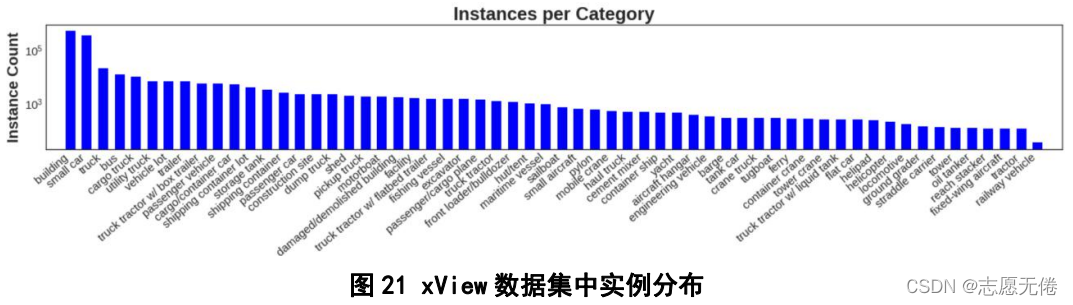
7.1基本信息
xView (lam et al.,2021)是由美国防部创新实验部门举行“xView探测挑战赛”时,推出的一套遥感图像细粒度目标检测数据集,包含1127幅遥感图像(图片尺寸介于20002000和40004000之间)和超过1000000个实例。数据集中的实例分为7个大类和60个子类,7个大类包括飞机、客车、卡车、铁路车辆、工程车辆、船舶和建筑物,部分子类并没有包含在大类之下,如直升机停机坪等。大类具体信息如下:
具体实例分布如下图所示:
7.2数据说明
7.2.1目标类别选择
xView选择了60个类别,采用父类-子类的形式来描述这些类别,但是部分子类并没有所属的父类,在1400平方公里的图像中,有超过100万个对象。
7.2.2数据来源
使用DigitalGlobal在全球部分区域中截取的图像。
- 1
7.2.3数据格式
xView数据集被分割为训练、验证和测试三个集合,按照3:1:1的比例划分为训练集、验证集、测试集。所有图像尺寸介于2000x2000和4000x4000之间、分辨率为0.3m。
7.2.4数据标注
xView数据集的优势很明显,一是数据集大,有超过1M个实例对象;二是数据种类多,包含60个细粒度类别;三是分辨率高,使用Digital Global的WorldView-3卫星采集到的图片分辨率都在0.3m,且分辨率规格相同。
同样,由于xView是以监测遥感图像中目标受损程度的比赛为导向的,数据集质量并不是很高,并且xView对于一些重要的类别的划分比较粗糙,不适合作为细粒度的分析。
7.3数据示例
图22 xView数据集标注示例

8. SIMD -1.07G
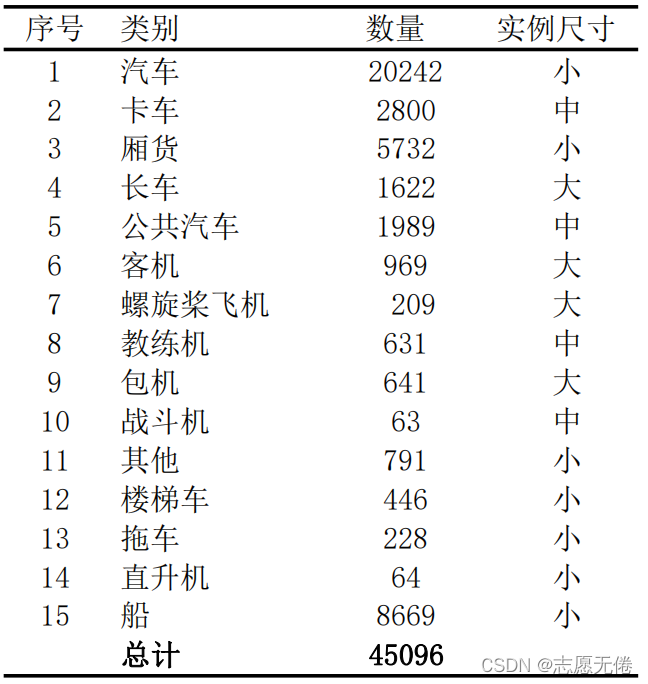
8.1基本信息
SIMD (haroon et al.,2020) 是由巴基斯坦国立科学技术大学提出的主要用于车辆检测的目标检测数据集,包含5000幅遥感图像(图片尺寸:1024*768)和45096个实例。数据集中的实例分为15类,类别信息如下:
8.2数据说明
8.2.1目标类别选择
SIMD主要用于车辆的检测,对车辆进行了细粒度类别的注释;
同时也标注了一定数量的飞机。
- 1
- 2
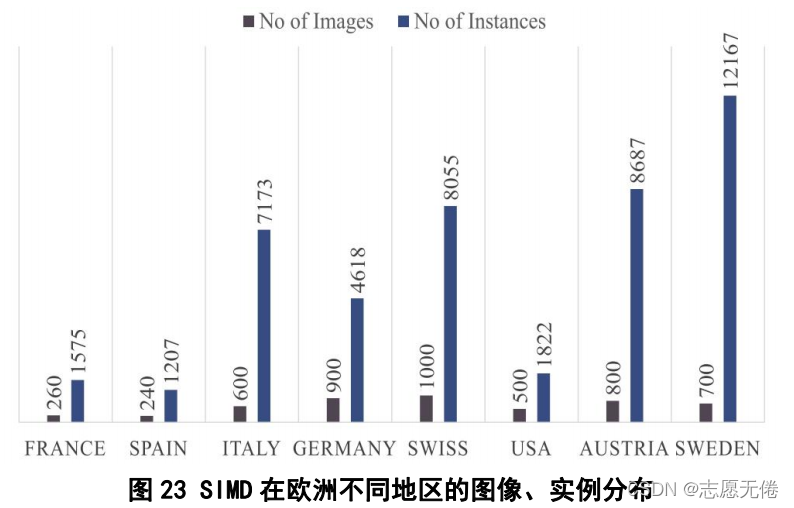
8.2.2数据来源
使用GoogleEarth在欧洲部分公共区域中截取的图像,具体分布如下图:
- 1
8.2.3数据格式
SIMD数据集中的图像分辨率都是1024*768的JPG格式。对于注释文件,SIMD以检测算法为导向,提
供了3种标准的注释格式。
- 1
- 2
1) YOLO格式:注释文件为txt格式,包含(c,xi,yi,w,h)5列属性数据。其中,c为目标对象的类别,(xi,yi)为对象的中心点,(w,h)为对象BB的宽和高,所有的数值都是与实际图像的百分比。
2) Faster
RCNN格式:数据保存在02XML格式的文件中,包含(x1、y1、x2和y2)的边界框信息和类别信息。其中第一个文件中的xi和yi是x、y域中的精确坐标,第二个文件包含用对应的类类型的名称,即汽车、公共汽车、卡车等。
3) Pascal
VOC格式:注释文件为XML格式,类似于上文提到过的XML文件,包含完整的图像信息和每个实例的详细信息。图像信息包括文件名、文件夹、图像分辨率等,实例标签包含实例类型名称和以(xmin、xmax、ymin、ymax)描述的每个实例的坐标。
8.2.4数据优劣
SIMD数据集的优势主要在于车辆数据集划分较细致、数量较多。
但是SIMD有着较为严重的数据不平衡问题,仅汽车1个类别的实例数量就占到了总体实例的1/2,只有
少量的其他类别的实例。
- 1
- 2
- 3
8.3数据示例

9. FAIR1M -42.8G
9.1基本信息
FAIR1M (Sun et al.,2021)是由中国科学院空天信息创新研究院研究团队和国际摄影测量与遥感协会合作,构建的一套目前全球规模最大的遥感图像细粒度目标识别(Fine-grAined object recognItion in high-Resolution remote sensing imagery)数据集,包含15266幅遥感图像(图片尺寸介于10001000和100001000之间)和超过100000(1 Million)个实例。数据集中的实例分为5个大类和37个子类,5个大类分别是:飞机、船舶、汽车、球场、道路,对于飞机这一大类,包含11个飞机型号:波音737、波音747、波音777、波音787、C919、ARJ21、空客A320、空客A220、空客A330、空客A350以及不属于以上10种飞机型号的其他型号飞机。其他大类信息如下:
具体实例分布如下图所示:
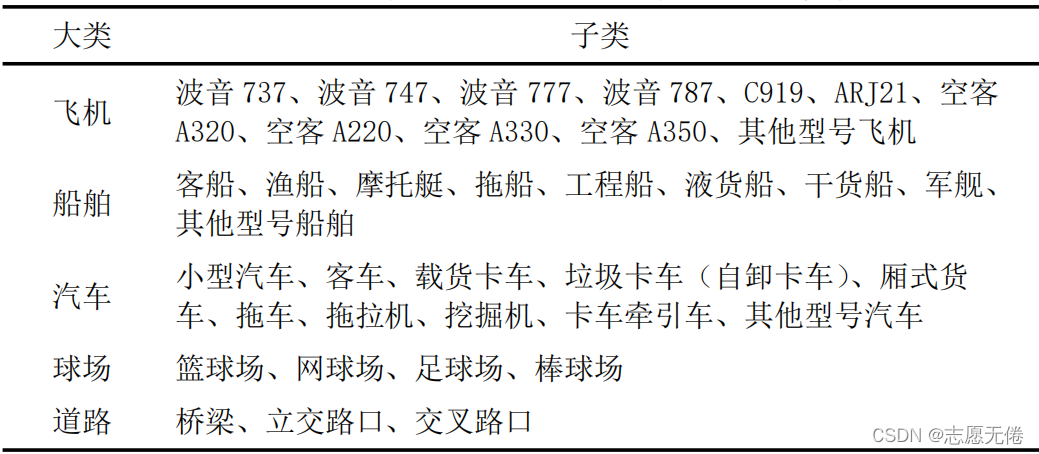
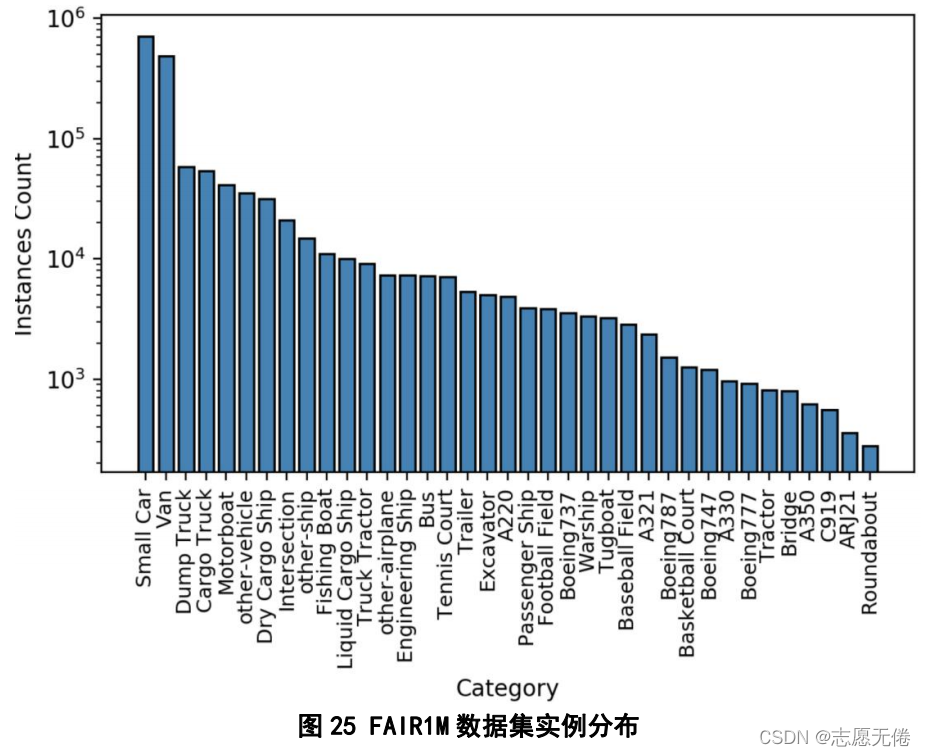
9.2数据说明
9.2.1数据来源
1)使用Google Earth软件在全球部分区域中截取的图像。
2)使用高分卫星在全球不同区域截取的图像,具体分布:
- 1
- 2
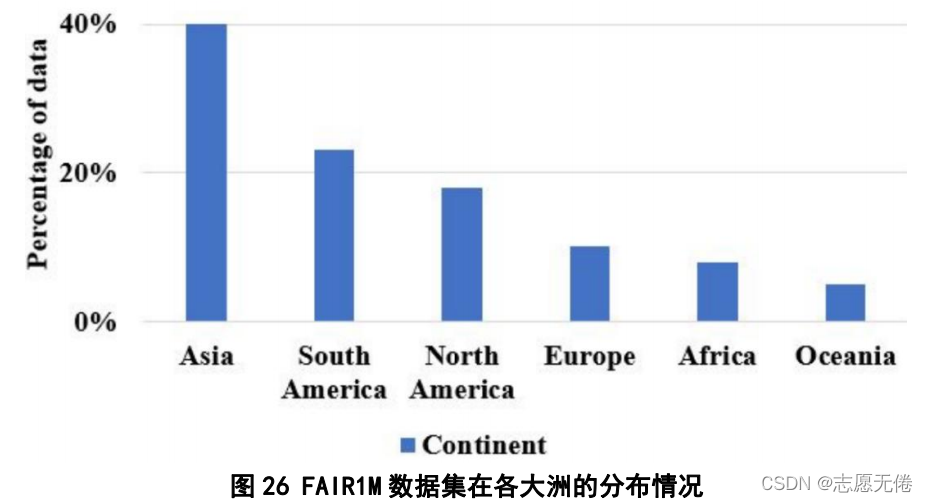
9.2.2数据预处理
为了获得高分辨率、高质量的遥感图像,FAIR1M进行了一定的数据预处理:
1)检查原始数据的质量,并去除有许云彩、噪声和亮点的图像。
2)为了确保同一区域的图像具有相同的定位精度,对多时态和多源图像进行了块调整。
3)使用Pan Sharpening算法融合全色图像来提高多光谱图像的空间分辨率,并使用直方图均衡来调整图像的色调分量。
- 1
- 2
- 3
- 4
9.2.3数据格式
FAIR1M数据集包含train、test两个文件夹,test文件夹下只包含images文件,即图像信息;train文件夹下包含images文件和labelXml文件,前者存有遥感图像,后者是对应的注释信息。
图像从1开始顺序命名,标注文件格式为xml文档,与对应的图像同名。所有图像尺寸介于10001000和1000010000之间、分辨率介于0.3m到0.8m、格式均为tif。注释文件中的标注信息很丰富,具体内容如下:
<?xml version="1.0" encoding="utf-8"?>
<annotation>
<source>
<filename>0.tif</filename>
<origin>GF2/GF3</origin>
</source>
<research>
<version>1.0</version>
<provider>FAIR1M</provider>
<author>Cyber</author>
<pluginname>FAIR1M</pluginname>
<pluginclass>object detection</pluginclass>
<time>2021-07-21</time>
</research>
<size>
<width>1500</width>
<height>1500</height>
<depth>3</depth>
</size>
<objects>
<object>
<coordinate>pixel</coordinate>
<type>rectangle</type>
<description>None</description>
<possibleresult>
<name>Liquid Cargo Ship</name>//类别
</possibleresult>
<points>
<point>1275.000000,458.000000</point>//x1, y1
<point>1494.000000,88.000000</point>//x2, y2
<point>1417.000000,43.000000</point>//x3, y3
<point>1199.000000,414.000000</point>//x4, y4
<point>1275.000000,458.000000</point>//head,即x1,y1
</points>
</object>
</objects>
</annotation>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
FAIR1M数据集采用OBB的标注方式,使用不规则四边形进行目标注释,四边形的四个顶点分别为
{(xi,yi)|i=1,2,3,4},四个顶点按顺时针排列,点(x1,y1)代表物体的头部。
- 1
- 2
9.2.4数据优势
1)类别细分全,类别数据较为平衡。
相较于其他粗糙的细粒度数据集而言,FAIR1M类别细分程度远超现有数据集,例如xView中只将飞机这一大类分成了2类,而FAIR1M将其分为了11类;并且FAIR1M对于类别进行了一定的平衡处理,各类别数量差异并不太大,而包含15个类别FGSD数据集,单单汽车就占了数据集实例的一半。
2)实例的尺寸、角度变化范围大。
FAIR1M数据集具有超高的空间分辨率,所以能够分辨出不同尺度的物体,来扩展实例大小的变化范围;同时,类内物体也存在角度的变化。
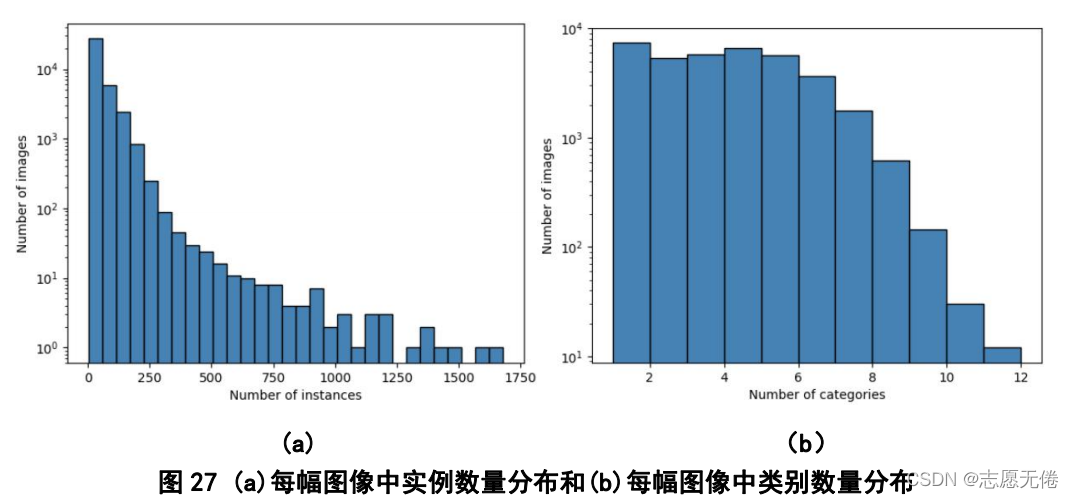
3)高度的类内差异性和类间相似性。
FAIR1M收集了不同季节和天气环境下的相同场景,因此,同一类别的物体有不同的姿态、背景、颜色和光线;不同细粒度类别之间具有相似的外观和形状。
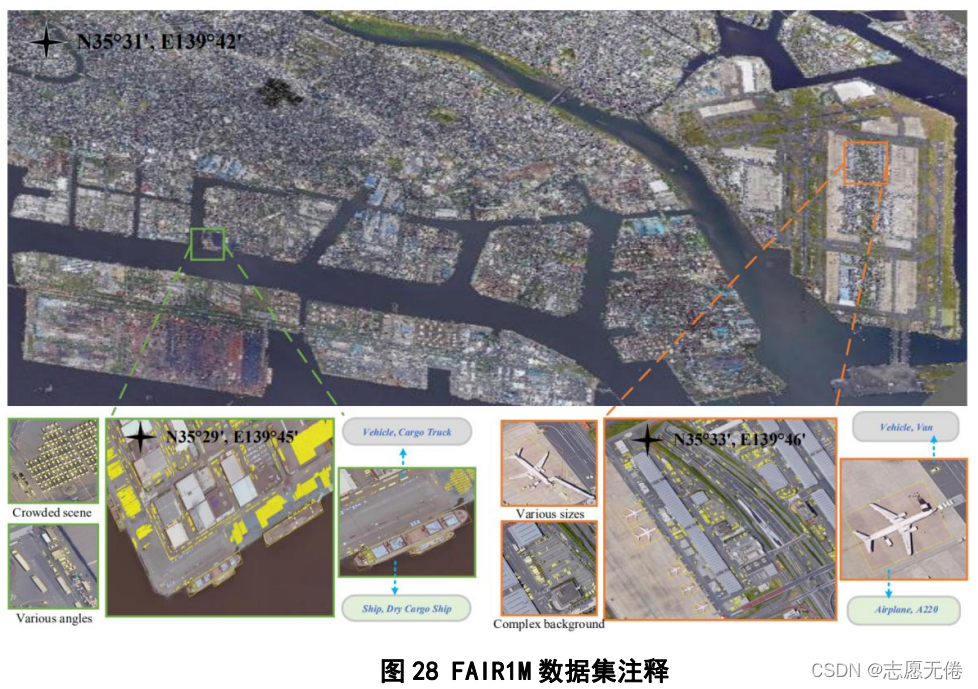
9.3数据示例

附录1 数据集下载地址
关注微信公众号“炼丹小天才” 回复遥感目标检测即可获得下载链接

