
- 1小熊派鸿蒙开发板,小熊派-鸿蒙·季开发板入门(一)
- 2ubuntu bds_mcsmanager实例启动失败
- 3最新AIGC创作系统ChatGPT系统源码,支持最新GPT-4-Turbo模型,支持DALL-E3文生图,图片对话理解功能_openai gpt4源代码
- 4层次聚类(Hierarchical Clustering)——CURE算法详解及举例_cure聚类
- 5Airtest如何自动连接重启后的设备并继续执行自动化脚本呢?_airtest 安卓重启
- 6AI Mass人工智能大模型即服务时代:如何训练你的AI Mass模型_大模型训练相关功能模块
- 7如何在Matlab中进行数据插补与缺失值处理_对称插补 matlab
- 8文言一心与文心一言:谁才是正版?_文言一心和文心一言
- 9五子棋算法总结_五子棋各棋推荐权重
- 10神经网络特征可视化新技术:用激活地图集(Activation Atlases)探索神经网络
声音特征提取--Mel梅尔频谱、梅尔倒谱系数MFCC_声音的频谱系数和mfcc
赞
踩
梅尔频谱
声音在任感官中是一维时域信号,直观上很难感受频率域的变化,FFT能将时域信号转换成频域信号,用来分析频域特征,但却缺少时域信息。通常通过短时傅里叶变换STFT,得到二维的图谱,即声谱图,包含了时域和频域的信息,这时得到的语音信号特征就称为线性频谱。
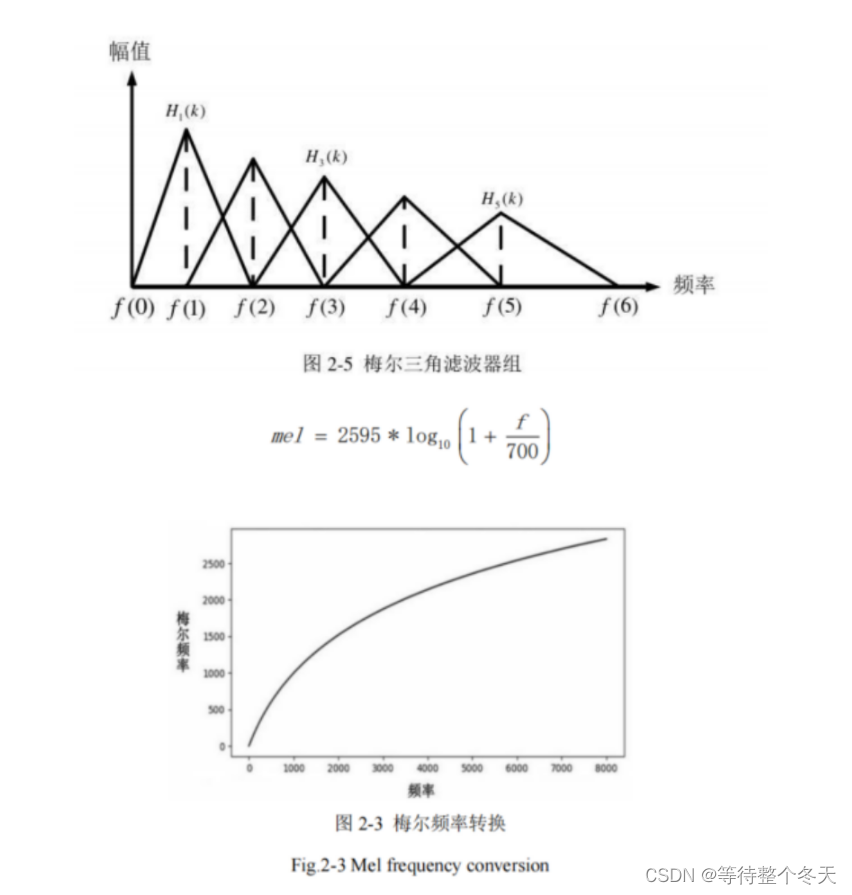
但是人耳感知到的声音高低与声音的原始频率并不呈线性关系,人耳对低频声音更加敏感,低频区域的差异变化比较容易被感受,而对于高频声音的变化感知并不明显。比如10hz和110hz的声音,人耳能够明显感觉到不同,而1000hz和1100hz的声音,人耳感觉会是一样的。频域上相等距离的两对频度,对于人耳来说他们的距离不一定相等。这样的感知是非线性的。
梅尔频谱(Mel spectrogram) 是更加符合人耳的听觉特性的一种频域表示法,声音通过一组梅尔滤波器组映射到梅尔音阶上,滤波器在低频范围内分布密集,在高频范围内分布稀疏,Mel谱是非线性的。这样使得在Mel刻度上相等距离的两对频度,人耳的感知差异也是相同的,即人耳感知和梅尔尺度呈线性关系。在低频段(1000hz),梅尔刻度与正常频度几乎呈线性关系,在高频段,两者呈对数关系。
梅尔频率倒谱系数MFCC
一条音频信号的频谱图中峰值表示信号的主要频率成分,也叫共振峰。主要频率成分包含了声音的识别属性,在声目标识别时,我们需要找到共振峰的位置还有它们转变的过程,所以我们提取的是频谱的包络:一条连接共振峰点的平滑曲线。原始频谱则可堪称两部分组成:包络(大趋势)和频谱细节(小区域波动)。要将包络和细节分开,则需FFT(任何连续信号都可以表示为不同频率正弦波信号的的无限叠加,时域信号FFT后得到不同频率组成及振幅)
音频特征MFCC的提取过程如下
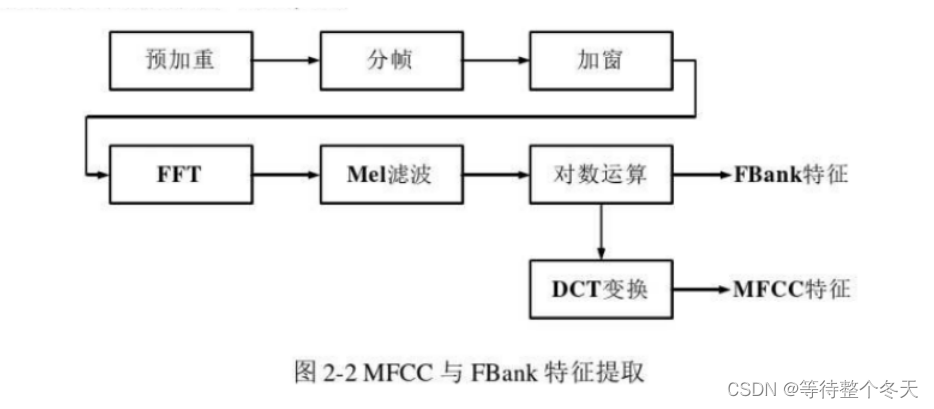
首先是预加重,目的是使高频部分抬升,整个信号的频谱峰值之间的差距减小。分帧、加窗、FFT部分可以看作是短时傅里叶变换STFT。FFT后信号从时域转换到频域,取绝对值得到信号幅度分布在频谱上的情况,对幅度谱计算模平方,得到能量谱分布。将能量谱通过一组梅尔滤波器组,通常用三角滤波器,得到梅尔特征。对梅尔谱取对数、然后进行离散余弦变换,对MEL谱做傅里叶变换相当于傅里叶逆变换,可以获取频率谱的低频信息。变换结果即为MFCC。
具体过程可见理解梅尔倒频谱系数MFCC
参考资料
基于深度学习的中文语音合成技术研究与实现_何东升
基于联合神经网络的水声目标识别技术研究_任晨曦

