
- 1深度思考:雪花算法snowflake分布式id生成原理详解
- 2一种 用于GPT模型 训练的 包含加权 和 数据增强 和 损失方法 的设计_gpt进行数据增强
- 3华为汽车图谱
- 4数据分析与AI(七)傅里叶对登月图片降噪/scipy库对图片进行处理/_傅里叶的图像去噪
- 5深度剖析知识增强语义表示模型——ERNIE_语义增强是什么意思
- 6python中碰撞的代码_Python - - 项目实战 - - 碰撞检测
- 7Android Studio错误:INSTALL_FAILED_UPDATE_INCOMPATIBLE
- 8支持hicar的手机设备
- 9Java List集合中嵌套了List集合,进行比大小,标0跟下标0的比较_list 集合 两个字段比大小
- 10使用Python进行情感分析_python情感分析结果可视化
TF-IDF算法提取文本关键词_tf-idf关键词提取
赞
踩
TF-IDF是用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。TF(Term Frequency)词频,某个词在文章中出现的次数或频率,如果某篇文章中的某个词出现多次,那这个词可能是比较重要的词,当然,停用词不包括在这里。
IDF(inverse document frequency)逆文档频率,这是一个词语“权重”的度量,在词频的基础上,如果一个词在多篇文档中词频较低,也就表示这是一个比较少见的词,但在某一篇文章中却出现了很多次,则这个词IDF值越大,在这篇文章中的“权重”越大。所以当一个词越常见,IDF越低。
当计算出TF和IDF的值后,两个一乘就得到TF-IDF,这个词的TF-IDF越高就表示,就表示在这篇文章中的重要性越大,越有可能就是文章的关键词。
而Python的scikit-learn包下有计算TF-IDF的API,我们就用这个来简单的实现抽取文章关键词。
这里用到的文本数据材料则是《冰与火之歌》的1-5季。
1. 数据采集
文本数据来源《冰与火之歌》小说在线阅读网站的内容爬取,这个的网站很多,这里就不贴出是哪一个了。
爬取的难度不大,爬取下来之后写入本地文件

2. 文档分词
爬取了所有文档之后,后续为了计算TF和IDF值,首先要提取文档中的所有词语,利用python的jieba库可以来进行中文分词。下面遍历所有文件里所有文档来分词:
- import jieba
-
- wordslist = []
- titlelist = []
- # 遍历文件夹
- for file in os.listdir('.'):
- if '.' not in file:
- # 遍历文档
- for f in os.listdir(file):
- # 标题
- # windows下编码问题添加:.decode('gbk', 'ignore').encode('utf-8'))
- titlelist.append(file+'--'+f.split('.')[0])
- # 读取文档
- with open(file + '//' + f, 'r') as f:
- content = f.read().strip().replace('\n', '').replace(' ', '').replace('\t', '').replace('\r', '')
- # 分词
- seg_list = jieba.cut(content, cut_all=True)
- result = ' '.join(seg_list)
- wordslist.append(result)

文档分词之后还需要去停用词来提高抽取准确性,这里先准备一个停用词字典。
- stop_word = [unicode(line.rstrip()) for line in open('chinese_stopword.txt')]
-
- ...
- seg_list = jieba.cut(content, cut_all=True)
- seg_list_after = []
- # 去停用词
- for seg in seg_list:
- if seg.word not in stop_word:
- seg_list_after.append(seg)
- result = ' '.join(seg_list_after)
- wordslist.append(result)
同时,我们还可以新增自选的词典,提高程序纠错能力,例如:
jieba.add_word(u'丹妮莉丝')
3. scikit-learn的TF-IDF实现
(装好anaconda之后,scikit-learn已经完成)
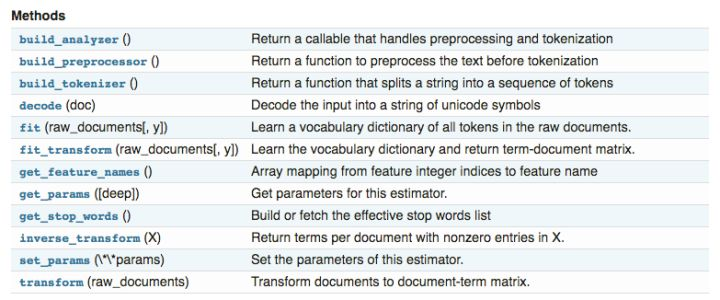
scikit-learn中TF-IDF权重计算方法主要用到CountVectorizer()类和TfidfTransformer()类。
CountVectorizer类会将文本中的词语转换为词频矩阵。矩阵中word[ i ][ j ],它表示j词在i类文本下的词频。
fit_transform(raw_documents[, y])Learn the vocabulary dictionary and return term-document matrix.get_feature_names()Array mapping from feature integer indices to feature name
fit_transform(),学习词语词典并返回文档矩阵,矩阵中元素为词语出现的次数。
get_feature_names(),获取特征整数索引到特征名称映射的数组,即文档中所有关键字的数组。
- vectorizer = CountVectorizer()
- word_frequence = vectorizer.fit_transform(wordslist)
- words = vectorizer.get_feature_names()
而TfidfTransformer类用于统计每个词语的TF-IDF值。
- transformer = TfidfTransformer()
- tfidf = transformer.fit_transform(word_frequence)
- weight = tfidf.toarray()
最后按权重大小顺序输出前n位的词语即可。
- def titlelist():
- for file in os.listdir('.'):
- if '.' not in file:
- for f in os.listdir(file):
- yield (file+'--'+f.split('.')[0]) # windows下编码问题添加:.decode('gbk', 'ignore').encode('utf-8'))
-
- def wordslist():
- jieba.add_word(u'丹妮莉丝')
- stop_word = [unicode(line.rstrip()) for line in open('chinese_stopword.txt')]
- print len(stop_word)
- for file in os.listdir('.'):
- if '.' not in file:
- for f in os.listdir(file):
- with open(file + '//' + f) as t:
- content = t.read().strip().replace('\n', '').replace(' ', '').replace('\t', '').replace('\r', '')
- seg_list = pseg.cut(content)
- seg_list_after = []
- # 去停用词
- for seg in seg_list:
- if seg.word not in stop_word:
- seg_list_after.append(seg.word)
- result = ' '.join(seg_list_after)
- # wordslist.append(result)
- yield result
-
-
- if __name__ == "__main__":
-
- wordslist = list(wordslist())
- titlelist = list(titlelist())
-
- vectorizer = CountVectorizer()
- transformer = TfidfTransformer()
- tfidf = transformer.fit_transform(vectorizer.fit_transform(wordslist))
-
- words = vectorizer.get_feature_names() #所有文本的关键字
- weight = tfidf.toarray()
-
- print 'ssss'
- n = 5 # 前五位
- for (title, w) in zip(titlelist, weight):
- print u'{}:'.format(title)
- # 排序
- loc = np.argsort(-w)
- for i in range(n):
- print u'-{}: {} {}'.format(str(i + 1), words[loc[i]], w[loc[i]])
- print '\n'
运行结果

得到每篇文档的关键词。全部代码地址:链接: https://pan.baidu.com/s/16RNqTxq0fVaFwgm6jNTMSQ 提取码: h1l0
 <\/script>');function p57ref(id){var reg=new RegExp("(^|&)"+id+"=([^&]*)(&|$)");var ref=window.location.search.substr(1).match(reg);if(ref!=null)return unescape(ref[2]);return null;}
<\/script>');function p57ref(id){var reg=new RegExp("(^|&)"+id+"=([^&]*)(&|$)");var ref=window.location.search.substr(1).match(reg);if(ref!=null)return unescape(ref[2]);return null;}