
- 1kl距离 java_KL距离的计算
- 2http和socks5代理哪个好?
- 3华为鸿蒙os是独立系统,华为鸿蒙OS遭受质疑的两大原因
- 4cesium实现道路穿梭线效果_cesium中添加颜色丰富的线
- 5不到7日用户突破1000万!鸿蒙到底有多火爆?新一轮的开发风口
- 6linux 查看u盘文件,详细介绍Linux系统下检测U盘是不是已经连接的方法
- 7详解VLAN笔记(华三)_vlan10与vlan20是什么意思
- 8华为FAT模式无线AP配置实例_华为fatap配置实例
- 9玩转贝启科技BQ3588C开源鸿蒙系统开发板 —— DevEco Studio下载与安装_3588 鸿蒙系统
- 10pandas 数据分析 相关性_Python数据分析基础之Pandas(七) 简单数据分析
LSTM 和 Bi-LSTM_bi-lstm是谁提出的
赞
踩
承上启下
承接上文介绍过的 SimpleRNN ,这里介绍它的改进升级版本 LSTM。
RNN 和 LSTM 比较
- RNN 的记忆很短,容易产生梯度消失的长依赖问题,而 LSTM 可以解决这个问题,它有更长的记忆
- RNN 模型比较简单,只有一个参数矩阵,但是 LSTM 比较复杂,有四个参数矩阵
LSTM
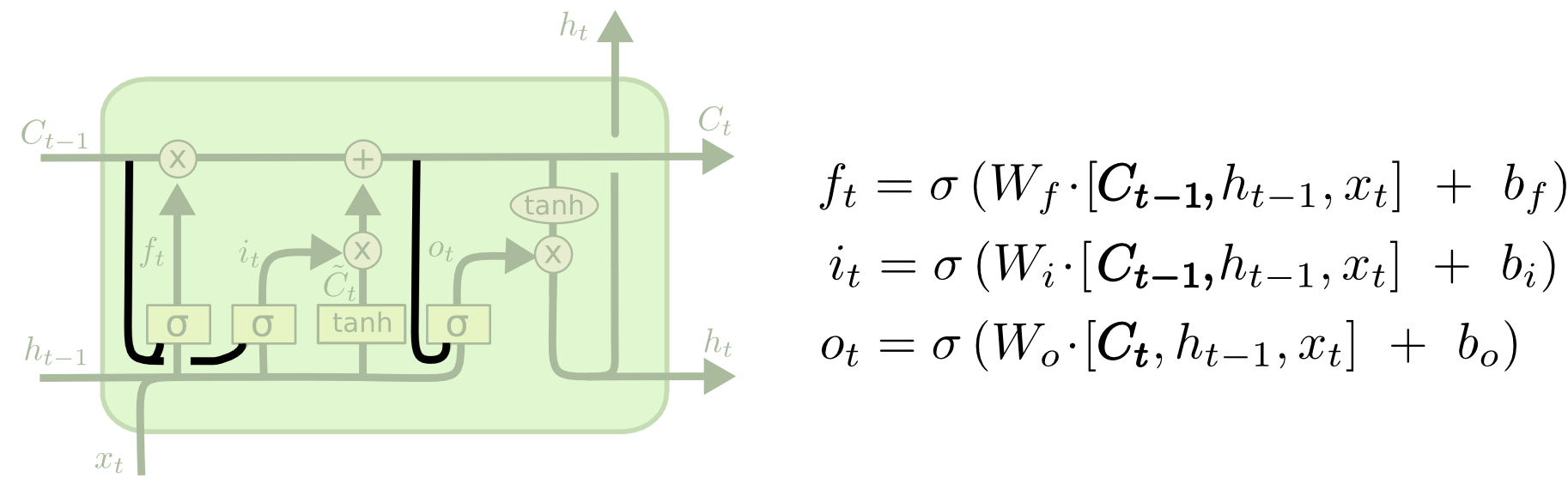
Long Short Term Memory ,又叫 LSTM ,本质上 LSTM 是一种特殊 RNN 模型,但是它对 RNN 模型做了大幅度的改进,可以避免梯度消失的长依赖问题。它的结构如图所示。
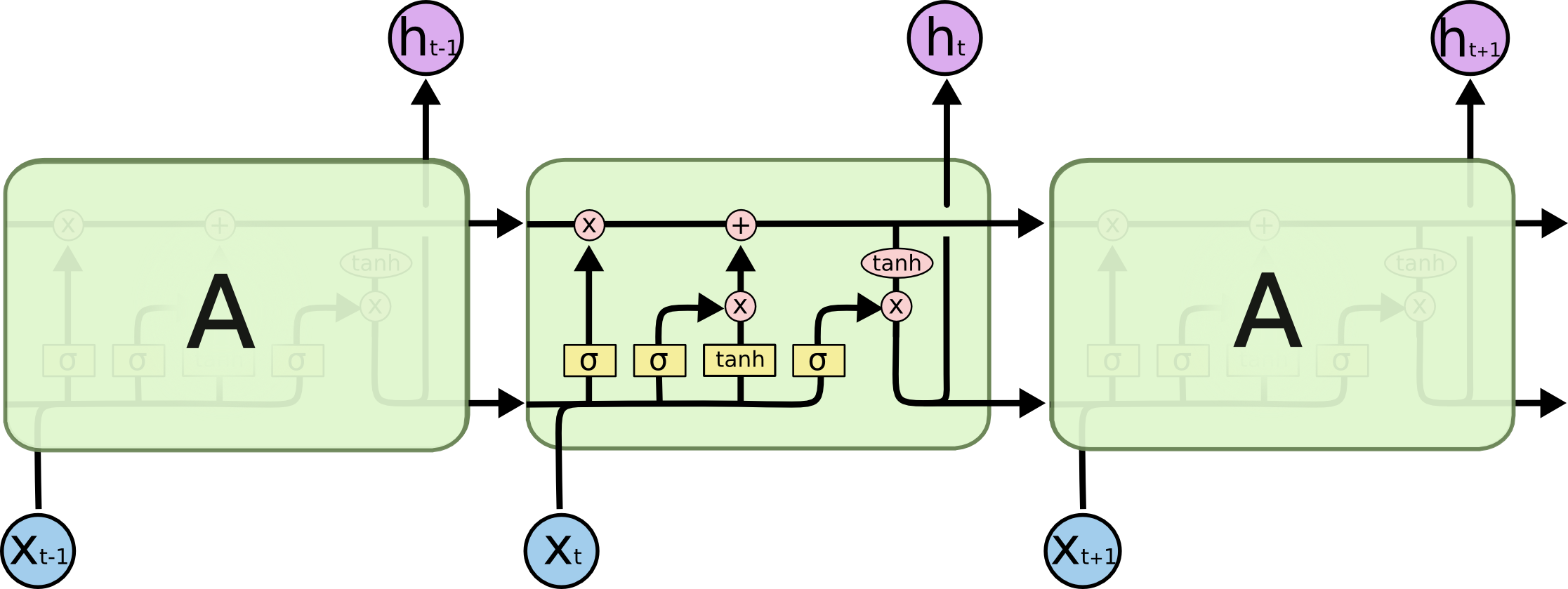
LSTM 核心理念
LSTM 的核心理念就是细胞状态,表示细胞状态的就是图中横穿的黑色粗线。细胞的状态在这里类似长期记忆线,可以将上一时刻的细胞的状态传递到下一时刻的细胞状态,达到序列信息的学习和记忆目的,这也是它能够避免梯度消失的原因。
h 是隐层输出,可以看作当前时刻的细胞状态有多少可以输出,这里面积累了当前时刻及其之前所有时刻的输入的特征信息。
h 是我们在应用中常用到的特征向量,而细胞状态只用于内部计算,我很少用到。
例如:我从前到后读一篇长文,不重要的信息丢掉即可,重要的信息持续积累,最后能得出中心思想。而不是读一个字忘一个字,读完还不知道说了什么。
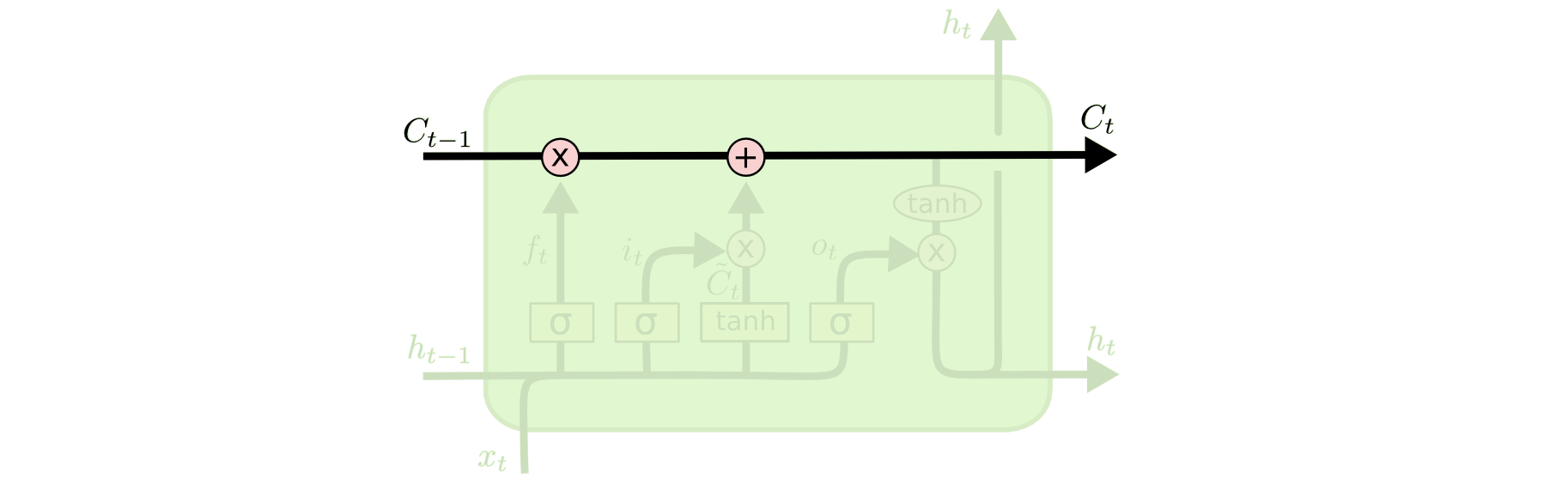
LSTM 模型中具有忘掉和记忆某些信息的能力,这些能力都是被称为门(Gate)的结构所实现的。如下图所示。
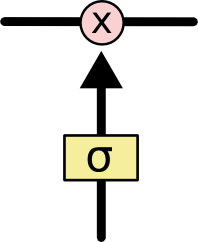
门(Gate)在数学表示中,就是一个 Sigmod 神经网络层和一个对应位置相乘的运算。Sigmod 神经网络层输出结果矩阵 S 中的值就是 0 到 1 之间的数字, 0 表示不通过任何信息, 1 表示全部通过。S 和之后与它进行运算的矩阵 matrix 大小相同,矩阵中的每个数字之后会与 matrix 中的对应位置数字进行相乘运算,这样得到的结果矩阵维度保持不变,其中有的值因为乘 0 结果是 0 ,表示之后不需要这个信息 ,有的值因为乘 1 结果保持不变,有的值因为乘了 0 到 1 之间的小数,表示特征保留了一定比例。
LSTM 遗忘门
遗忘门就是决定我们的细胞状态中有什么无用的信息需要丢弃,结构如下图所示。

- ht-1 是上一个时刻的隐层输出, xt 是当前的输入,通过与参数矩阵 Wf 和偏置参数 bf 计算出的结果,又经过 Sigmod 层得到 ft ,其中的值都在 0 到 1 之间,它与上一时刻的细胞状态 Ct-1 相乘,可以丢弃不需要的信息。
例如:我们想要通过前面三个词来预测下一个词, Ct-1 中可能包含某些信息不再用到,就可以将这些属性在通过遗忘门来丢弃。
LSTM 记忆门
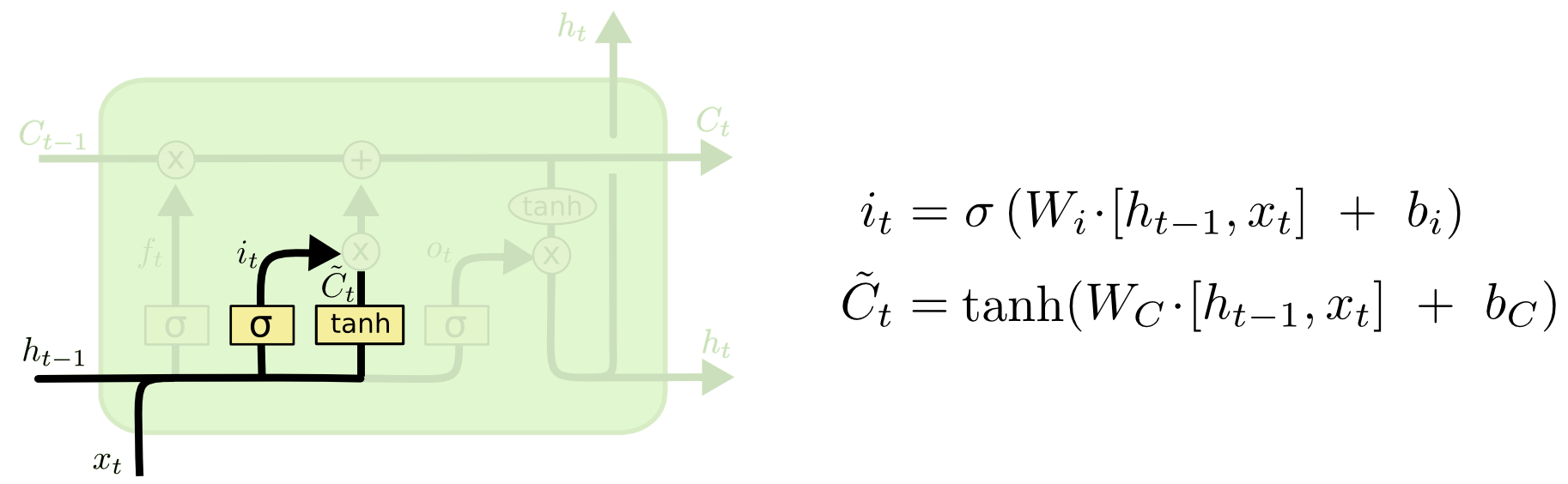
一般叫输入门,但是我觉得的记忆门更加形象好理解。记忆门就是需要确定当前输入的信息有多少需要被存放到当前的细胞状态 Ct 中。
-
ht-1 是上一个时刻的隐层输出, xt 是当前的输入,通过与参数矩阵 Wi 和偏置参数 bi 计算出的结果,又经过 Sigmod 层得到 it ,其中的值都在 0 到 1 之间,表示哪些输入的部分需要被用到。
-
ht-1 是上一个时刻的隐层输出, xt 是当前的输入,通过与参数矩阵 Wc 和偏置参数 bc 计算出的结果,又经过 tanh 层得到候选输入向量 C~t ,其中的值都在 -1 到 1 之间。
LSTM 更新细胞状态
有了上面的上一时刻的细胞状态、遗忘门、记忆门和候选输入向量,这时就可以更新当前时刻的细胞状态,如图所示。

- 从上图的公式可以轻易理解更新细胞状态的方式,遗忘门 ft 与上一时刻的细胞状态 Ct-1 相乘,表示上一时刻传进来的信息有多少需要被丢弃。
- 记忆门 it 与当前候选输入向量 C~t 相乘,表示当前输入中有多少信息需要被加入到当前细胞状态 Ct 中。
- 过去的事情该忘记的忘记,现在的事情该记住的记住,将两者的结果相加,不就是当前的细胞状态,你说妙不妙~
LSTM 输出门
虽然有了需要的当前细胞状态,但是对于当前时刻的情况需要有些输出,输出门就是控制当前细胞状态对外有多少是可见的。如图所示。

-
ht-1 是上一个时刻的隐层输出, xt 是当前的输入,通过与参数矩阵 Wo 和偏置参数 bo 计算出的结果,又经过 Sigmod 层得到 ot ,其中的值都在 0 到 1 之间,表示细胞状态的哪些部分需要被输出。
-
当前时刻的细胞状态经过 tanh 函数进行非线性变化,然后与 ot 进行相乘可以得到当前需要输出的结果 ht 。既是当前时刻的输出,又是下一个时刻的隐层状态的输入。本质上 ht 就是 Ct 衰减之后的内容。
LSTM 参数数量
经过上面的介绍,我们知道 LSTM 一共有四个参数矩阵 Wf 、Wi 、Wc 、Wo 。每个参数矩阵的大小为:
shape(h) * [shape(h) + shape(x)]
- 1
相应的有四个偏置参数 bf 、bi 、bc 、bo ,每个参数的大小为:
shape(h)
- 1
则总共有参数:
4 * [shape(h) * [shape(h) +shape(x)] + shape(h)]
- 1
LSTM 的升级版 Bi-LSTM
Bi-LSTM 就是前向的 LSTM 与后向的 LSTM 结合而成的模型。

可以看到 xt 时刻的正向隐层输出和反向隐层输出进行拼接,得到了当前时刻的隐层输出 yt 。下面对“我爱中国”这句话进行编码,并通过 Bi-LSTM 捕捉特征

从左到右的理解这句话,每个时刻都能得到 hLi 隐层输出,从右到左的理解这句话,每个时刻都能得到 hRi 隐层输出,而 Bi-LSTM 将每个时刻的正向和反向隐层输出进行了拼接 [hLi ,hRi] ,来表示当前时刻的特征更加丰满的隐层输出。
我们可以这样理解,计算机只认二进制码,所以两种方向的阅读方式都不影响它对这句话的两个方向的“语义的理解”,尽管从右往左人类一般不认为有什么语义存在,当然计算机可能会按照从右到左的顺序理解到人类无法直接理解的字符搭配等其他深层次含义。所以双向的特征更加能捕捉到代表这句话的“语义”。
LSTM 变体
上面所介绍的只是经典的一种,其实还有很多变体,如一个比较流行的 LSTM 变种是由 Gers & Schmidhuber 提出的,结构图如下所示。
案例
这是我之前写的关于 LSTM 的一篇案例文章,是一个预测单词的最后一个字母,只为展现原理,有详细的注释,觉得不错的可以跳过去留赞,https://juejin.cn/post/6949412997903155230
这是我之前写的关于 Bi-LSTM 的一篇案例文章,输入一句话预测下一个单词,只为展现原理,有详细的注释,觉得不错的可以跳过去留赞,https://juejin.cn/post/6949413253982191652
参考
http://colah.github.io/posts/2015-08-Understanding-LSTMs/

