
- 1【脚本】7-Zip 批量压缩文件_7zip批量压缩
- 2自媒体内容创作ai写作神器:10款你一定要知道的工具! #科技#学习
- 3画出使用回溯法解0/1背包问题的解空间树_解空间树怎么画
- 4【实战项目】基于AidLux+YOLOv5+ByteTrack实现街道人流统计_yolov5 bytetrack
- 5微信小程序开发中瀑布流布局和图片懒加载
- 6Anroid动画总结三:属性动画插值器_属性动插值器
- 7【正点原子Linux连载】第二十章 Linux自带的LED灯驱动实验摘自【正点原子】ATK-DLRK3568嵌入式Linux驱动开发指南
- 830分钟读懂Linux进程调度(图文并茂)_linux 0.11 dotimer
- 9语音信号线性预测分析(MATLAB实战篇)_信号预测算法
- 10微信小程序开发(1):小程序的执行流程是怎么样的?
【全面了解自然语言处理三大特征提取器】RNN(LSTM)、transformer(注意力机制)、CNN_nlp自然语言 transformer rnn lstm
赞
踩
自然语言处理(NLP)是人工智能领域中一个重要的分支,它的目的是让计算机能够理解和处理人类语言,而特征提取是让计算机理解和处理人类语言时必不可少的过程,除了数据的因素,一个特征抽取器是否适配问题领域的特点,有时候决定了它的成败,而很多模型改进的方向,其实就是改造得使得它更匹配领域问题的特性(引自张俊林老师的文章)。
下面本文从基本结构、工作原理、优缺点和适用场景具体介绍一下这三个主要的特征提取器
一 、RNN
循环神经网络或递归神经网络。顾名思义,RNN在处理序列信息时(比如一段文本)是递归进行,即下一时刻的处理依赖于上一时刻的结果。
即:不同于传统的神经网络结构,RNN隐藏层之间的节点不再无连接而是有连接的。
1.RNN单个cell的结构
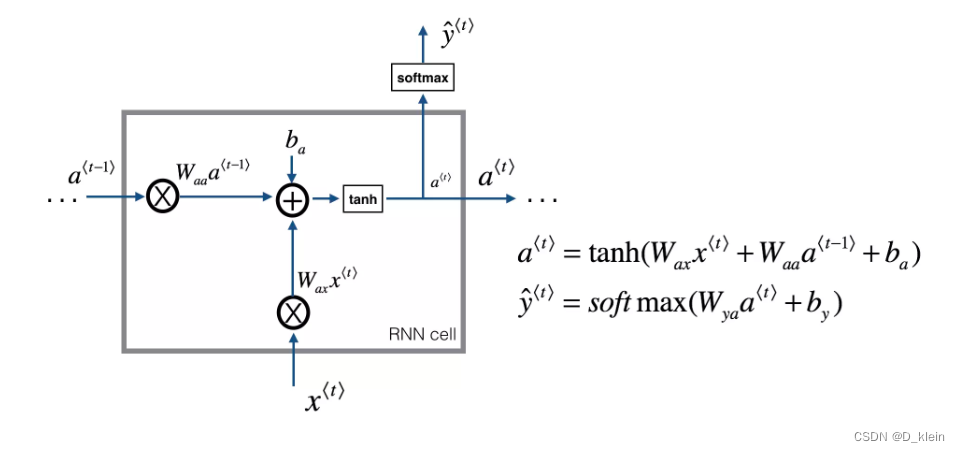
可以看到当前时刻的输出 y^t 和隐藏层状态 a^t 依赖于当前时刻的输入 x^t 和上一时刻的隐藏层状态 a^t-1
2.RNN工作原理
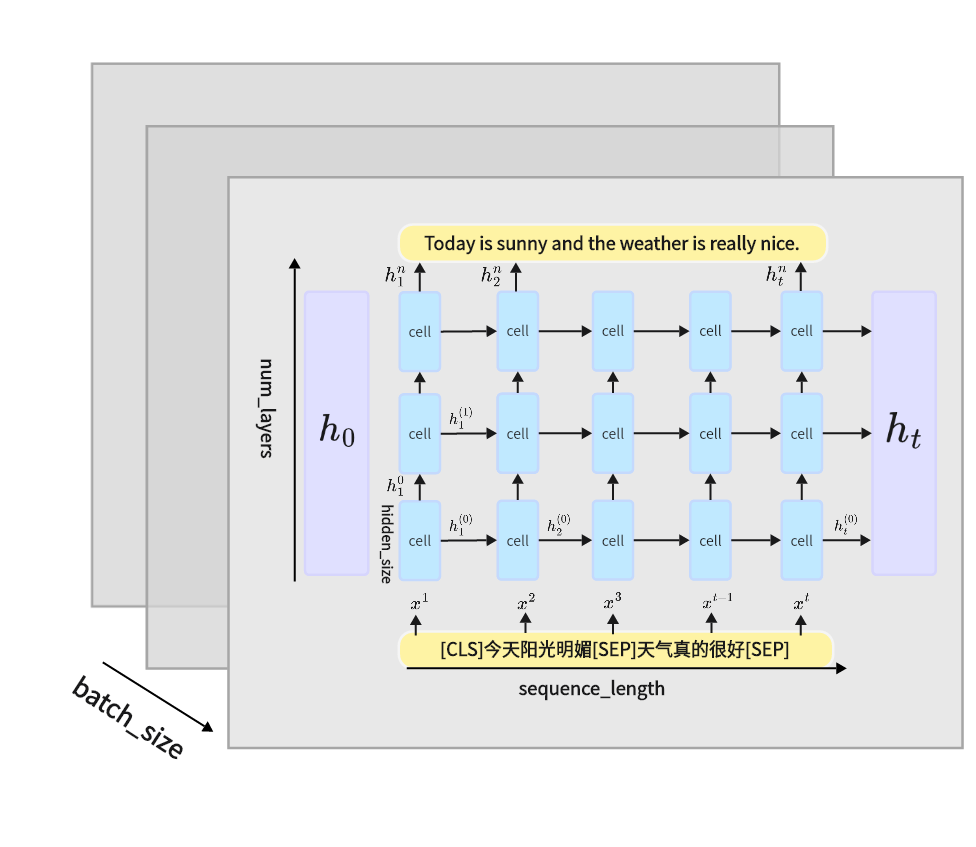
其中一个cell对应于RNN单个细胞的结构,对于上图中的文本翻译问题,输出接收最后一层每个时刻隐藏层的状态,但是对于分类问题,输出只接受最后一层最后一个时刻的隐藏层状态。
3.RNN优缺点
-
优点:
- RNN能够有效地处理序列数据
- 由于权重共享,RNN在内存使用上比全连接网络高效
-
缺点
- 梯度消失和梯度爆炸: 在学习长序列时,RNN容易遇到梯度消失或梯度爆炸的问题,这使得模型难以学习到长距离的依赖关系。
- 难以捕捉长期依赖: 尽管RNN理论上能够捕捉长期依赖关系,但在实际应用中,由于梯度问题,其性能往往受限。
- 并行计算受限: 由于RNN的序列特性,使得其在并行计算上受到限制,影响了训练速度。
二、LSTM
当输入的序列数据足够长,梯度在层之间进行反向传播时容易消失和爆炸,梯度消失会导致RNN会忘记之前学到的内容,而只能保存短时记忆,难以处理长期依赖问题,而梯度爆炸会使其计算量将呈指数级增长,给模型训练带来极大挑战。
为解决RNN梯度消失和难以捕捉长距离依赖问题,LSTM应运而生。传统RNN的做法是将的所有知识全部提取出来,不作任何处理的输入到下一个时间步进行迭代,LSTM的结构更类似于人类对于知识的记忆方式,通过引入细胞状态与三个门控机制来缓解了以上问题。
1.LSTM单个cell的结构
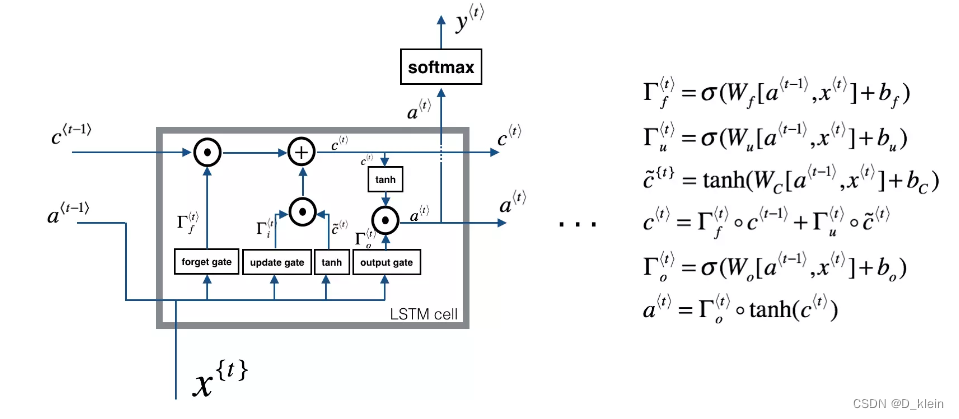
其中,三个门控机制分别指遗忘门、输入门(图中的update gate)和输出门。除此之外,LSTM引入了一个细胞状态变量:c^t,用于记录每个门控机制发挥作用之后,该保留上文(反向LSTM就是下文)的多少信息。
三个门控机制都相当于是一个函数,该函数通过输入的x和输入的隐藏层状态a来不断更新参数,最后经过sigmoid层获得[0,1]之间的值,该值与细胞状态相乘,即实现了信息的遗忘或者保留。
细胞状态也是LSTM能够解决长依赖问题的关键,它能够保存上文中有价值的记忆。
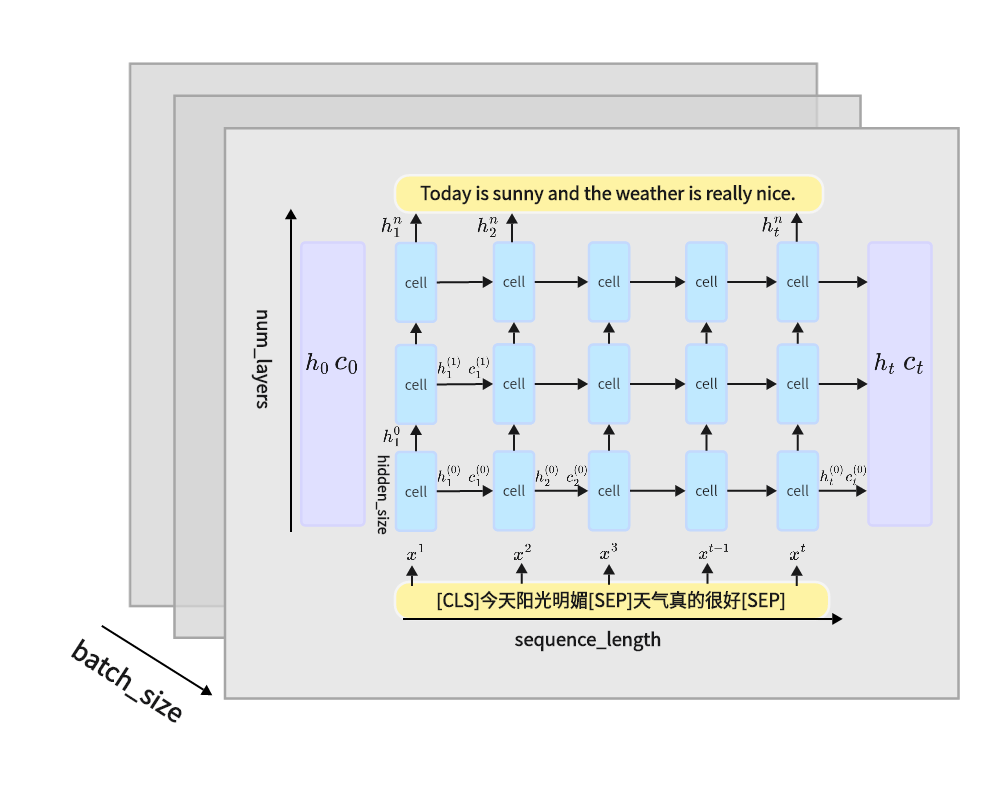
2. LSTM工作原理
其中一个cell对应于LSTM单个细胞的结构,图中的h是隐藏状态,对应于上图中的a;c代表细胞状态。
三、transformer
RNN和LSTM在处理序列信息时,都是递归进行的,transformer则突破了这种限制。transformer是处理序列到序列问题的架构,单纯由self-attention组成,其优良的可并行性以及可观的表现提升,让它在NLP领域中大受欢迎,GPT-3以及BERT、ERNIE等都是基于Transformer实现的。
首先,一个transformer block有两个部分组成:encoder和decoder
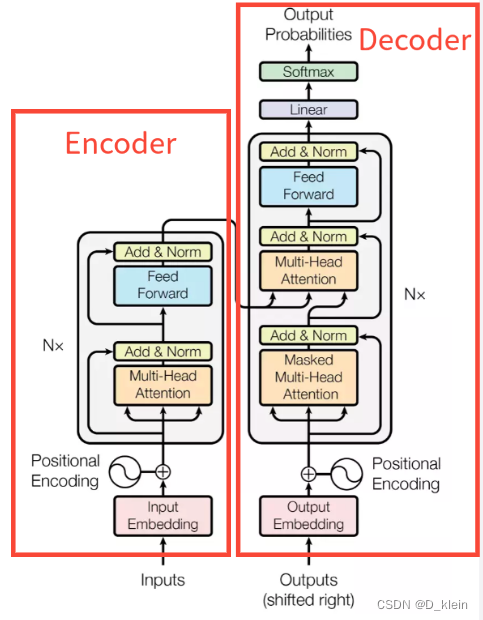
1 Encoder
encoder,编码,主要是用来做特征提取。而能让Transformer效果好的,不仅仅是Self attention,这个Block里所有元素,包括Multi-head self attention,Skip connection,LayerNorm,FF一起在发挥作用,除此之外,position encoding也发挥了很大的作用。
下面来详细讲解一下各个流程。
(1)position encoding
讲position encoding之前,我们需要回顾一下RNN和LSTM对于文本的处理过程,由于他们都是递归的处理,所以天然的记忆了文本中字或者词语之间的顺序关系,而transformer由于是直接读取所有文字,并行处理,所以其丢失了文本的位置信息,也就是无法理解词语的前后关系。position encoding就是为了解决这个问题,在input_embedding的基础上,对文本的位置进行编码,保留位置信息。
【需要注意的是,这里的位置信息属于相对位置信息,BERT里的position embedding属于绝对位置信息,因为在 BERT 中 Positional Embedding 并没有采用固定的变换公式来计算每个位置上的值,而是采用了类似普通 Embedding的方式来为每个位置生成一个向量,然后随着模型一起训练。因此,这一操作就限制了在使用预训练的中文 BERT模型时,最大的序列长度只能是512,因为在训练时只初始化了 512 个位置向量】。
在Transformer中,作者采用了如公式(1)所示的规则来生成各个维度的位置信息。
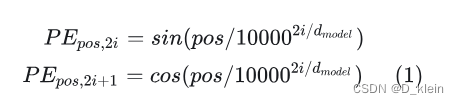
其中,PE就是代表position的编码表示,pos代表一行文本中单个文字的具体的某一个位置, i的取值范围是[0, dmodel/2]代表维度。
(2)multi-head-attention
之后input进入到多头注意力机制(transformer的核心)部分。多头注意力机制是self-attention即自注意力机制的变形,接下来首先讲一下自注意力机制。
可以将注意力机制归纳为两个过程:第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和。而第一个过程又可以细分为两个阶段:第一个阶段根据Query和Key计算两者的相似性或者相关性;第二个阶段对第一阶段的原始分值进行归一化处理,公式如下。
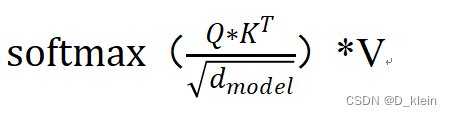
具体过程如下图所示。
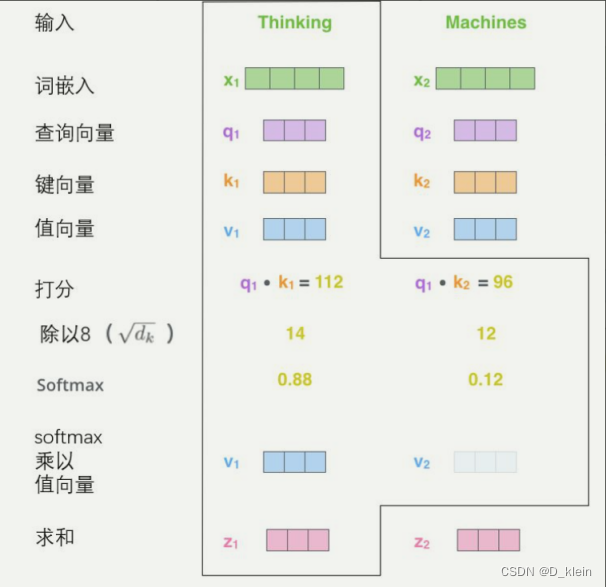
那么Query、Key和Value是怎么得到的呢,在自注意力机制中上述三个向量都来源于input本身,通过可学习的权重W^q 矩阵, W^k矩阵, W^v矩阵获得,所以自注意机制可以捕获一段文字内的各词语之间的语法特征关系。
而多头注意力机制相当于对同一段序列做了多次自注意力机制,其中每个头在不同的表示子空间中学习序列内的关系。 通过这种方式,模型能够同时从不同的角度捕捉信息,增强了模型的表示能力。
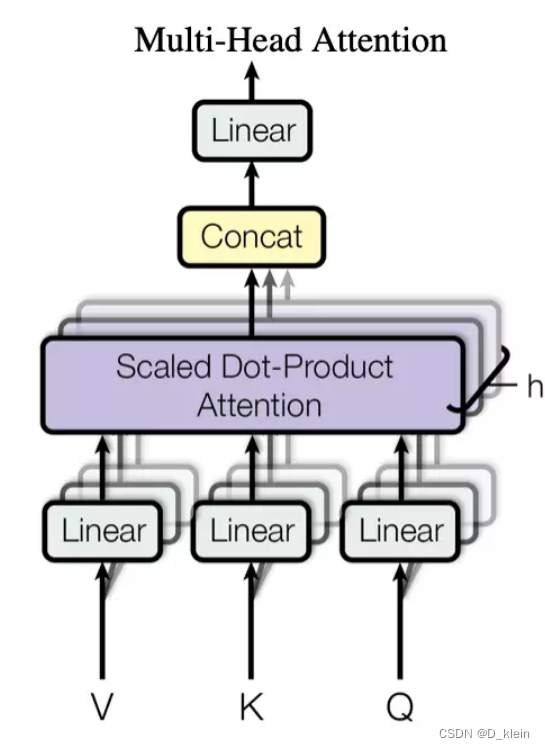
其长距离特征捕获能力主要受到Multi-Head数量的影响,Multi-Head的数量越多,Transformer的长距离特征捕获能力越强。
(3)add&norm 残差链接和归一化
主要有两个主要部分
- 一个残差链接,也叫skip-connection,把上一层的输入和上一层的输出相加,为了解决梯度消失问题。
- 第二个是层归一化,作用是把神经网络中隐藏层归一为标准正态分布,加速收敛。
(4)feed forward & add&norm
将上一个模块的输出经过relu激活函数,残差操作和归一化与(3)相同

