
- 1Android ScrollView简单自动滚动问题总结_android scrollview滑动 时子view ondraw了
- 2在打包一个父级的maven工程时,有一个子工程打包失败,报错:Could not resolve dependencies for project com.x.x._could not resolve dependencies 父子pom
- 3数据分析实战之如何自动化采集数据_数据采集从数据源角度分为
- 4如何使用 Xcode8 进行开发调试_xcode signing
- 5节约编译时间的利器,多线程应用的典范 - Incredi build _incredbuild
- 6文本的特征属性选择_文本的具体性属于文本特征里的那个部分
- 7中文大模型隐私保护哪家强?InternLM 与 Baichuan2 胜出!
- 8VS2015 还是VS2017 好用_OPPO Reno4与荣耀30哪个好用?双11入手哪款才更具性价比?|oppo|手机|vivo|pro|reno...
- 9AI绘画(1)stable diffusion安装教程
- 10今日arXiv最热大模型论文:人民大学发布,拯救打工人!Office真实场景下的大模型表格处理
【AM】Non-Attentive Tacotron_non-attentive tacotron: robust and controllable ne
赞
踩
Non-Attentive Tacotron: Robust and Controllable Neural TTS Synthesis Including Unsupervised Duration Modeling
本文提出了Non-Attentive Tacotron(NAT),基于Tacotron2但是把Decoder与Encoder之间的Attention机制替换成了显式的时长预测。NAT可以用时长标注训练,也可以使用一个细粒度的VAE以无监督或半监督的形式训练。当使用时长标注可以获得时,NAT自然度比Tacotron2稍好一点,但是在稳定性方面,NAT相比Tacotron2有了很大的提升。
本文的主要贡献:
- 提出了Non-Attentive Tacotron架构,用时长预测和上采样模块替换了原本tacotron2中的attention机制,在自然度相当的前提下明显提升了鲁棒性;
- 无监督或者半监督的时长训练方式,允许模型用较少的时长标注;
- 提出了更多的评估指标:unaligned duration ratio (UDR)和ASR word deletion rate (WDR),可以应用大规模的数据对TTS鲁棒性进行评估;
- 引入高斯上采样提升了合成音频的音质;
- 支持全局和细粒度的时长控制;
1. Model
模型结构如下图所示。Duration预测模块对encoder的输出上采样,与fastspeech中的直接复制同,本文采用了高斯上采样,在计算loss时,duration以秒为单位,在上采样用到duration时,他们被转换成帧;
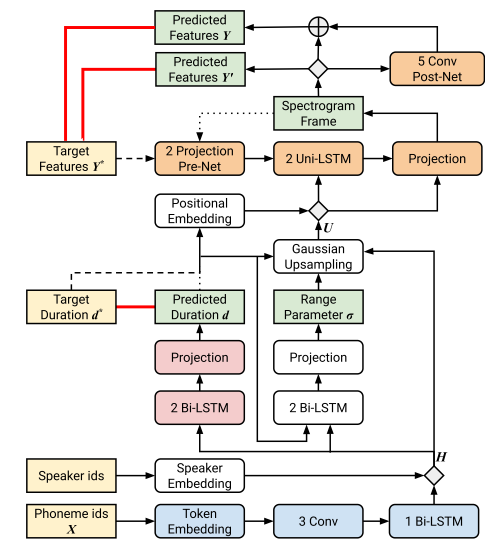
1.1 Gaussian upsampling
高斯上采样过程需要每个token的时长和range parameter。range parameter表示的是当前token的影响范围;duration表示的是当前token持续的时长;二者决定了当前token高斯上采样的分布。上采样结束后,会经过一个transformer中用到的sinusoidal positional embedding。上采样过程如下图所示:
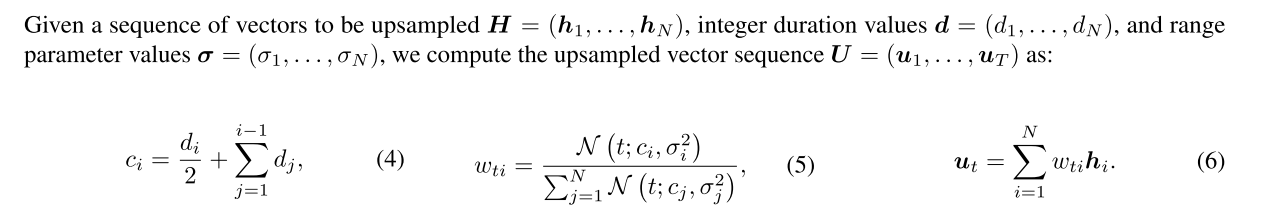
高斯上采样的好处主要在于他是一个可微的操作,对半监督和无监督的时长模型非常关键,保证梯度可以从mel loss最终流到duration predictor。
1.2 Training loss
训练过程中,loss包括mel loss和duration loss;其中mel loss包括了postnet之前和之后的mel与target mel的L1和L2 loss,duration loss是L2 loss。
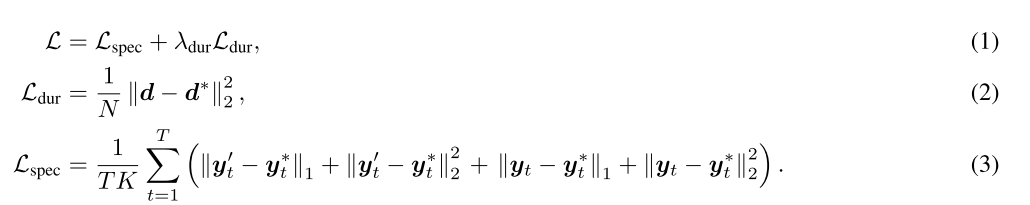
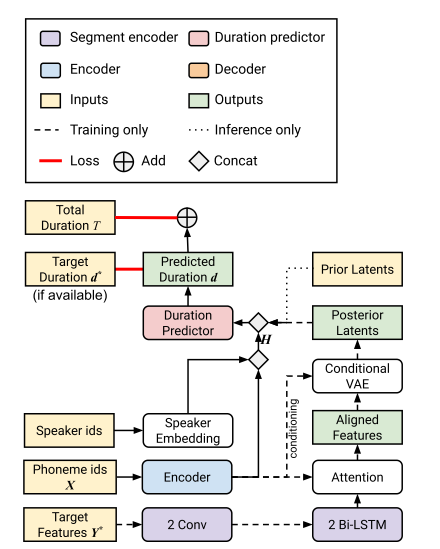
1.3 Unsupervised and semi-supervised duration modeling
一个简单的想法是将duration predictor预测出的duration(而不是真实的duration)用于训练,用一个scale调节duration的和与mel length mismatch,然后再补充一个duration的和与mel length 的loss即可。但是文中说这种方法没有生成令人满意的自然度的语音。最终采用的结构如下图所示。
2. Experiments
2.1 Naturalness
与GMMA Tacotron2相比,NAT稍好一点。
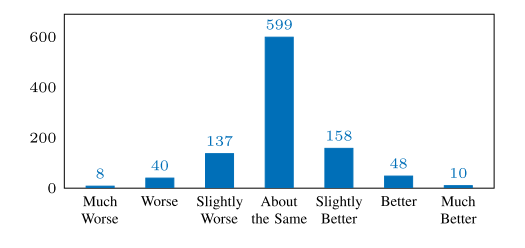
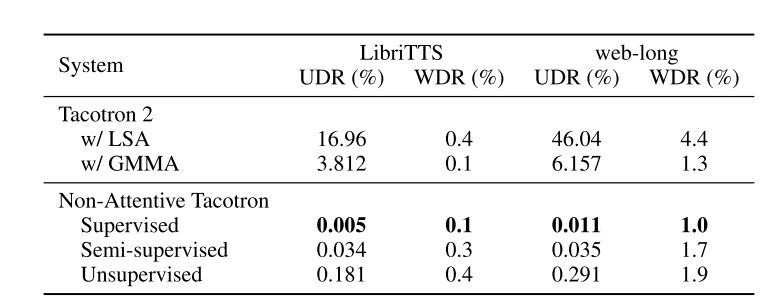
2.2 Robustness
鲁棒性有明显提升。
- 相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

