
- 1百度松果菁英班--oj赛(第一次)_oj赛竹鼠通讯
- 2ROS入门(九)——机器人自动导航(介绍、地图、定位和路径规划)_ros导航是什么
- 3信息安全工程师笔记-10种端口扫描技术概念_端口扫描的四种方式
- 4『SQLServer系列教程』——数据库用户的创建/删除以及授权等操作_sqlserver创建用户
- 5【RxJava】走进RxJava 从关键类开始_rxjava maven
- 6小米路由器4A千兆版刷入OpenWrt教程_小米4a千兆去广告固件
- 7AI数字人未来的优势以及应用场景!_数字人 发展的应用场景 与优势
- 8开箱即用的ChatGPT替代模型,还可训练自己数据(转)_如何自己训练数据 实现gpt类似应用
- 9使用postman时,报错SSL Error: Unable to verify the first certificate_postman ssl error: unable to verify the first cert
- 10Vue3 + Vite 打包优化及配置_vite-plugin-imagemin 打包时间
【人工智能技术专题】「入门到精通系列教程」打好AI基础带你进军人工智能领域的全流程技术体系(机器学习知识导论)_构建鲁棒安全人工智能所需的基础理论与技术体系
赞
踩
零基础带你进军人工智能领域的全流程技术体系和实战指南(机器学习基础知识)
前言
人工智能是一个庞大的研究领域。虽然我们已经在人工智能的理论研究和算法开发方面取得了一定的进展,但是我们目前掌握的能力仍然非常有限。机器学习是人工智能的一个重要领域,它研究计算机如何模拟或实现人类的学习行为,以获取新的知识或技能,并通过重新组织已有的知识结构来不断提高自身的性能。深度学习是机器学习中的一个研究方向,通过多层处理,将初始的“低层”特征表示逐渐转化为“高层”特征表示,从而可以用“简单模型”完成复杂的分类等学习任务。深度学习在人工智能的各个领域都有广泛的应用。
专栏介绍
许多人对AI技术有兴趣,但由于其知识点繁多,难以系统学习,学习没有方向等等问题。我们的专栏旨在为零基础、初学者和从业人员提供福利,一起探索AI技术,从基础开始学习和介绍。让你从零基础出发也能学会和掌握人工智能技术。
专栏说明
本专题文章以及涉及到整体系列文章主要涵盖了多个流行的主题,包括人工智能的历史、应用、深度学习、机器学习、自然语言处理、强化学习、Q学习、智能代理和各种搜索算法。这个人工智能教程提供了对人工智能的介绍,有助于您理解其背后的概念。我们的教程旨在为初级和中级读者提供完整的人工智能知识,从基本概念到高级概念。
学习大纲
与人类所的智能形成对比,人工智能是指机器所显示的智能。 本教程涵盖了以下整体学习路线内容:

前提条件
在学习人工智能之前,需要具备以下基本知识,以便轻松理解一些编程相关的功能。
- 熟悉至少一种计算机语言,如C,C++,Java或Python(推荐Python)。
- 对基本数学有一定的了解,如微积分、概率论、线性代数和数理统计等,不太懂也没事,我也会带着大家进行分析学习。
面向读者
本教程专为对人工智能有兴趣的毕业生、研究生以及将人工智能作为课程一部分的初中级学者设计,同时也包括一些专业人士需要了解的高级概念。
学习目标
本专栏主要提供了人工智能的介绍,可以帮助您理解人工智能背后的概念以及人工智能的应用,深度学习,机器学习,自然语言处理,强化学习,Q学习,智能代理,各种搜索算法等。
-
学习后将掌握:机器学习和深度学习的概念,常用的机器学习算法和神经网络算法。
-
人工神经网络,自然语言处理,机器学习,深度学习,遗传算法等各种人工智能领域的基本概念及其在Python中的如何实现。
-
认识和掌握相关人工智能和Python编程的基本知识。 还会掌握了AI中使用的基本术语以及一些有用的python软件包,如:nltk,OpenCV,pandas,OpenAI Gym等。
核心内容
本章的核心内容路线包括以下四个方面组成,主要围绕着机器学习的相关知识概论和知识基础进行分析和介绍,让大家打好基础。
机器学习的概念定义
说到机器学习,我们就需要在回顾一下人工智能的概念,这样子方便我们进行对比和分析两者之间的关系。
回顾人工智能
【人工智能(Artificial intelligence)是一门涉及理论、方法、技术及应用系统的新兴技术科学,其研究和开发旨在模拟、扩展和延伸人类智能】。人工智能作为一个笼统而宽泛的概念,其最终目标是使计算机能够模拟人的思维方式和行为。虽然人工智能的发展始于上世纪50年代,但由于当时的数据和硬件设备等限制,其发展缓慢。
机器学习概念
【机器学习(Machine Learning)是一种使用数据和算法来模仿人类学习方式的数据分析技术,它是人工智能和计算机科学的产物】。机器学习通过从经验中学习,逐步提高准确性,并能够在不依赖预先确定的方程式模型的情况下直接从数据中“学习”信息。
国外知名学者对机器学习的定义
Well-posed Learning Problem:A computer program is said to learn from experience (E) with respect to some task (T)and some performance measure §,if its performance on T,as measure by P,improves with experience E.(Tom Mitchell,1998)
中文翻译
适定学习问题:据说计算机程序可以从经验中学习(E对于某个任务 (T) 和某个绩效指标 ( P ),如果它的绩效P对T的评价随着经验e的提高而提高(汤姆·米切尔,1998)。

机器学习发展历程
1956年,人工智能这一术语被提出,用于探索一些问题的有效解决方案。后来,美国国防部借助“神经网络”这一概念,开始训练计算机模仿人类的推理过程。随着时间的推移,谷歌、微软等科技巨头改进了机器学习算法,并将查询的准确度提升到了新的高度。从2010年起,随着数据量的增加、算法、计算和存储容量的提高,机器学习得到了更进一步的发展。

机器学习和人工智能的关系
机器学习(Machine learning)是人工智能的子集,是实现人工智能的一种途径,但并不是唯一的途径。

它是一门专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能的学科。大概在上世纪80年代开始蓬勃发展,诞生了一大批数学统计相关的机器学习模型。
机器学习和人类学习的对比
计算机模拟人类的学习行为,以获取新的知识或技能,并重新组织已有的知识结构,使之不断改善自身。
人类学习的行为处理模式

机器学习的行为处理模式

经典的「垃圾邮件过滤」应用
通过经典的「垃圾邮件过滤」应用,我们再来理解下机器学习的原理。
应用程序
「垃圾邮件过滤」是一个经典的机器学习应用,可以帮助用户自动过滤掉垃圾邮件,减少骚扰和安全风险。在这个应用中,机器学习的原理是通过对已知的垃圾邮件和非垃圾邮件进行分析和分类,建立一个可用于分类的模型。
原理分析
在这个例子中:
- T:将邮件分类为垃圾邮件和非垃圾邮件
- E:看着你将电子邮件标记为垃圾邮件或非垃圾邮件
- P:正确分类为垃圾邮件/非垃圾邮件的电子邮件数量(或分数)
在训练模型时,我们通过对分类结果的评估,来优化模型的准确性和鲁棒性。最终,模型会根据邮件的内容或其他特征,自动判断是否为垃圾邮件,并进行过滤。这种基于机器学习的垃圾邮件过滤方式,可以有效提高用户的工作效率和信息安全性。
机器学习三要素
机器学习三要素包括数据、模型、算法。
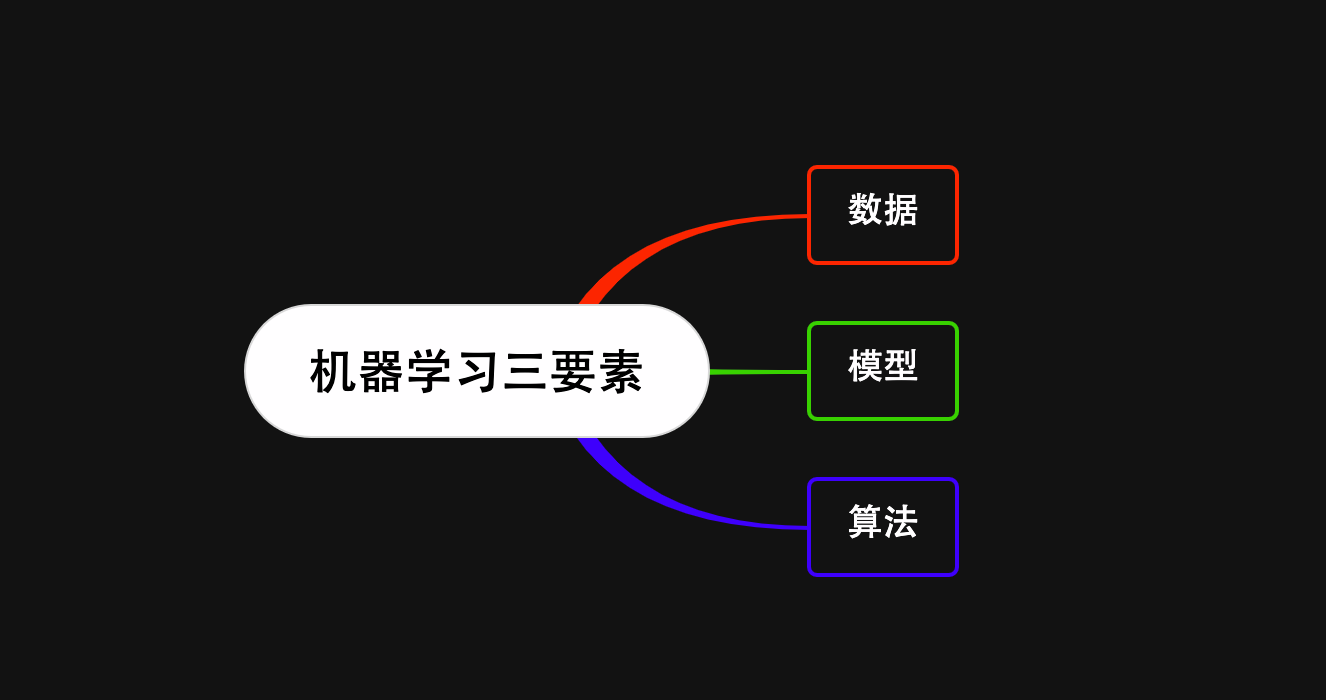
这三要素之间的关系,可以用下面这幅图来表示:

数据(数据驱动)
数据驱动指我们基于客观的量化数据,进行主动的采集、分析和处理,以支持决策的一种方法。

通过数据的收集和分析,我们可以获得更具可信度和准确性的信息和洞察,从而作出更为明智的决策。相对而言,经验驱动则更加依赖主观经验和直觉判断,容易受到情感和偏见的影响,这种“拍脑袋”的方式风险较大,常常不能得出准确的决策。因此,数据驱动的方式更加可靠和客观,已成为现代科学和工业界中不可或缺的一部分。
100100011101000000101000110111010110 100100111101110000001111100110100100 100001101101111101010011100001101001 111111010000110111001010111100001011 110011111101111111100100001110110110 010000110100110110000110000100010000 010101110011001111011001110100010111 001000010101100101000001000010011110 011101001111110010111010101010111100 100010000101100010101101010111000101 010010000100101011110011100001010000 010110000010011101010010101110110001 011011111010111100010100010100010000 011010011011011010001000101111001101 000101000001100110001100100010010110 100101010100010011100101010101111101

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
训练集与数据集
数据驱动中会涉及到以下两个概念(训练集与数据集):
-
训练集(Training Set):训练集是用来训练模型的数据集合。在房价预估中,我们可以使用已知的历史数据来训练模型,例如,历史房价数据、房屋面积、房间数量等特征作为模型的输入,真实房价作为模型的输出。通过训练集的数据,我们可以确定拟合曲线的参数,以建立一个准确的模型。
-
测试集(Test Set):测试集是为了测试已经训练好的模型的精确度而准备的数据集合。在房价预估中,我们可以将未知的数据样本(例如,新的房屋面积和房间数量等特征)作为输入,通过之前训练好的模型来预测它的房价。然后,我们可以将这个预测值与真实的房价进行比较,从而来衡量模型的精确度。通过不断地测试和改进,我们可以得到一个越来越准确的模型,以预测未知的房价。

模型
模型是指为了基于数据X做出决策Y而提出的假设函数。模型可以有不同的形态,常见的有计算型和规则型。
计算型模型是通过对大量的数据进行训练,学习到数据特征之间的关系,并根据这些关系进行决策。常见的计算型模型包括神经网络模型、决策树模型、逻辑回归模型等。
规则型模型则是将人类的专业知识和经验转化为机器可以理解和实现的规则形式,通过规则匹配和逻辑推理来进行决策。常见的规则型模型包括专家系统、知识图谱等。
无论是哪种形态的模型,都需要从数据中学习、提取有用的特征,训练出可以作出准确决策的假设函数。通过不断的优化和调整,模型可以不断提高预测和决策的准确性和鲁棒性。
算法
算法是指学习模型的计算方法,而统计学习则是根据训练数据集,在假设空间中选择最优模型的学习策略。为了得到最优模型,通常需要运用最优化的方法求解。
机器学习算法核心的大体方向是一下这几种算法根基:分类、聚类、异常检查以及回归等。

分类算法
分类是一种机器学习模型训练方式,它的训练集和测试集都是标记好的,通过学习并识别数据的相关特征,建立模型对新的未知数据进行分类和预测。

聚类算法
聚类是一种机器学习方法,它可以从海量数据集中识别数据的相似性和差异性,将相似的数据分组聚合为多个类别。通过聚类,我们可以更好地理解数据之间的联系,从而作出更有意义的决策。

异常检测
异常检测是一种数据分析技术,它可以帮助我们识别与正常数据分布规律不同的离群点。通过对数据点进行分布规律分析,异常检测可以帮助我们找到那些与其他数据点异于寻常的数据点,以避免数据误解和错误决策。

回归
回归是一种机器学习算法,它可以根据对已知属性值数据的训练,为模型寻找最佳拟合参数,并用于预测新样本的输出值。通过回归,我们可以构建一个数学模型来描述输入特征和输出变量之间的关系,以预测新的输出值。这种技术可以应用于各种场景,例如股票市场预测,房价预测等。

机器学习的技术分类
机器学习技术可分为三类:监督学习、无监督学习和强化学习,这三类技术是机器学习领域中应用最为广泛的技术,也是现代工业界中普遍采用的技术。

之前在前面的文章介绍了对应的学习概念和算法,那么接下来我就再次巩固和回顾复习一下下面之前的机器学习方向类型。
针对于机器学习技术方向的监督学习、无监督学习和强化学习的各种详细分析和原理详细探究会在“【人工智能技术专题】「入门到精通系列教程」打好AI基础带你进军人工智能领域的全流程技术体系(机器学习算法概论)”进行分析和说明。
监督学习(Supervised Learning)
监督学习(Supervised Learning)是一种机器学习的方法,它必须要确定目标变量的值,以便机器学习算法可以发现特征和目标变量之间的关系。
有标签数据的学习方法,是通过已有的标注数据训练模型,再应用此模型对未知数据进行分类、预测等任务,监督学习算法用于根据已知的输入和输出数据创建模型以进行未来预测。
核心原理
监督学习(Supervised Learning)包括分类和回归两种学习方式,它的训练集具有标记信息。
-
分类算法:我们将数据分为多个离散类别,通过学习已经确定好的类别(即标签),来预测新的未知数据所属的类别。
-
回归算法:我们处理的是连续型数据,它的目标变量是一系列连续值。在回归中,我们基于已知的数据和输出变量之间的关系,建立一个模型,以预测新的未知数据的输出结果。真实的输出结果可以是任何连续值,如价格、温度等。
分类算法逻辑案例简介
样本集:训练数据+测试数据
- 训练样本 = 特征(feature)+目标变量(label:分类-离散值/回归-连续值)
- 特征:独立测量得到的训练样本集的列
- 目标变量:机器学习预测算法的测试结果
- 目标变量:分类问题中的离散值,也可以是回归问题中的连续值。
在分类算法中,目标变量通常是标称型,例如真与假;而在回归算法中,目标变量通常是连续型,例如1~100。
知识数据信息
一般情况下,在分类算法中,可以采用以下几种形式确定一个实例所属的类别:
- 采用规则集的形式确定类别,例如:数学成绩大于90分为优秀;
- 采用概率分布的形式确定类别,例如:通过统计分布发现,90%的同学数学成绩在70分以下,那么大于70分定为优秀;
- 使用训练样本集中的一个实例确定类别,例如:通过样本集合,我们训练出一个模型实例,得出年轻、数学成绩中高、谈吐优雅等特征时,我们认为是优秀。
无监督学习(Unsupervised Learning)
无监督学习(Unsupervised Learning)包括聚类和降维两种方式,其训练集没有标记信息。
从未标注的数据中,通过统计学方法挖掘数据潜在的结构和规律,完成聚类、降维等任务,无监督学习检测输入数据中的隐藏模式以进行预测。
无监督学习的应用包括以下几个方面:
- 聚类:无监督学习可以将数据分成多个类别,使得每个类别内部的数据相似度较高,而不同类别之间的数据差异较大;
- 密度估计:无监督学习可以通过训练样本来确定变量的概率分布,以此得出数据的统计特征;
- 降维:无监督学习可以通过减少数据的维度,使得数据的特征更加容易被观察和理解,通常可以使用二维或三维图形来展示数据信息。

强化学习(Reinforcement Learning)
强化学习(Reinforcement Learning):通过稀疏和延迟的反馈标签来进行学习。
根据环境的响应及其反馈,动态调整策略,不断优化学习过程,从而达到最优化目标的一种学习方式。
强化学习能够使用来自其自身行为和经验的反馈,通过反复试验在交互式环境中学习。
常见机器学习算法
针对于机器学习算法的各种详细分析和原理详细探究会在“【人工智能技术专题】「入门到精通系列教程」打好AI基础带你进军人工智能领域的全流程技术体系(机器学习算法概论)”进行分析和说明。
目前的人工智能领域,有多种流行的机器学习算法,其中包括:

- 神经网络(Neural networks):神经网络模拟人脑的工作方式,适用于自然语言翻译、图像识别、语音识别和图像创建等应用;
- 线性回归(Logistic regression):用于基于不同值之间的线性关系进行数值预测,例如可以用于预测房价;
- 逻辑回归(Clustering):用于分类反应变量的预测,例如答案为“是/否”的问题,适用于垃圾邮件分类和生产线上的质量控制等应用;
- 聚类(Cluserting):采用无监督学习,可以识别数据中的模式并进行分组;
- 决策树(Decision tress):用于预测数值或将数据分类,具有易于验证和审计的优点;
- 随机森林(Random forests):采用多个决策树结果的组合来预测值或类别。
机器学习的实际应用
机器学习应用广泛,以下是一些最常见的应用场景:

- 图像识别:机器学习可以用于识别图像和视频中的物体、人像、地点等;
- 语音识别:机器学习可以将语音转换为文本,反之亦然;
- 自然语言处理:机器学习可以用于理解和解释人类语言;
- 推荐系统:机器学习可以根据用户过去的行为向用户推荐产品或服务;
- 异常检测:机器学习可以用于检测数据中的异常模式或行为;
- 欺诈检测:机器学习可以用于检测金融交易中的欺诈活动;
- 预测性维护:机器学习可以用于预测机器或设备何时可能发生故障;
- 机器人:机器学习可以用于教机器人执行任务;
- 自动驾驶汽车:机器学习可以用于使汽车能够自动驾驶,例如Google的Naymo、Tesla的FSD以及百度的Apollo自动驾驶系统。
内容总结
机器学习概念定义
机器学习是模拟人类学习行为的计算机科学领域,旨在通过赋予机器获取新知识和技能的能力,实现人工智能系统的智能化。机器学习利用先进算法进行深层次的统计分析和计算,实现自主学习和智能化决策。它能够识别、分类、预测等各类任务,并从现实世界中学习模式和规律。
机器学习的技术分类
机器学习技术可以主要分为三类:监督学习、无监督学习和强化学习。这三种技术在机器学习领域中应用广泛,也在现代工业界中被广泛采用。
数据
数据驱动是人工智能(AI)中的一种方法,通过对大量数据的处理、分析和整理等操作,利用数据模型和算法来实现智能应用。
模型
模型是指为了基于数据X做出决策Y而提出的假设函数。模型可以有不同的形态,常见的有计算型和规则型。
算法
算法是学习模型的计算方法,而统计学习是选择最优模型的学习策略。为了得到最优模型,需要使用最优化方法进行求解。
常见机器学习算法
以下是机器学习中常见的几种算法:
- 神经网络(Neural networks):模拟人脑的工作方式,适用于自然语言处理、图像和语音识别等应用;
- 线性回归(Logistic regression):基于不同值之间的线性关系进行数值预测,例如可以用于预测房价;
- 逻辑回归(Clustering):用于分类反应变量的预测,例如答案为“是/否”的问题,适用于垃圾邮件分类和生产线上的质量控制等应用;
- 聚类(Clustering):采用无监督学习,能够识别数据中的模式并进行分组;
- 决策树(Decision trees):用于预测数值和分类,具有易于验证和审计的优点;
- 随机森林(Random forests):采用多个决策树结果的组合来预测值或类别。
机器学习的实际应用
机器学习可以应用于图像识别、语音识别、自然语言处理、推荐系统、异常检测、欺诈检测、预测性维护、机器人和自动驾驶汽车等领域,从而实现诸如检测异常、预测机器故障和自动驾驶等多种人工智能应用。

