
- 1使用langchain与你自己的数据对话(二):向量存储与嵌入_langchain chat with your data
- 2bootstrap-table.js结合java数据字典展示列值_bootstarp table.datatable 列表字典
- 3应用案例分享|3D视觉引导汽车铅蓄电池自动化拆垛
- 4软考中级(网络工程师考核要点)第一章 计算机网络系统(信道特性应用)第五期(曼彻斯特和差分曼彻斯特)重点考_软考网络工程师中级
- 5深度学习目标检测分类学习率调整策略_目标检测算法设置学习率公式
- 6Transformer的PyTorch实现_transformer模型pytorch实现
- 7引入BertTokenizer出现OSError: Can‘t load tokenizer for ‘bert-base-uncased‘._oserror: can't load tokenizer for 'bert-base-uncas
- 8词向量学习总结 [独热表示-分布式表示-word2vec -Glove - fast text - ELMO - BERT]_独热向量是什么
- 9如何根据黄金行情进行交易操作?
- 10消息中间件 Asio (C++)_asio服务端代码
docker安装ollama
赞
踩
拉取镜像
docker pull ollama/ollama运行容器
(挂载路径 D:\ollama 改成你自己喜欢的路径)
CPU only
docker run -d -v D:\ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollamaNvidia GPU(没试过这个)
docker run -d --gpus=all -v D:\ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama运行模型
docker exec -it ollama ollama run llama2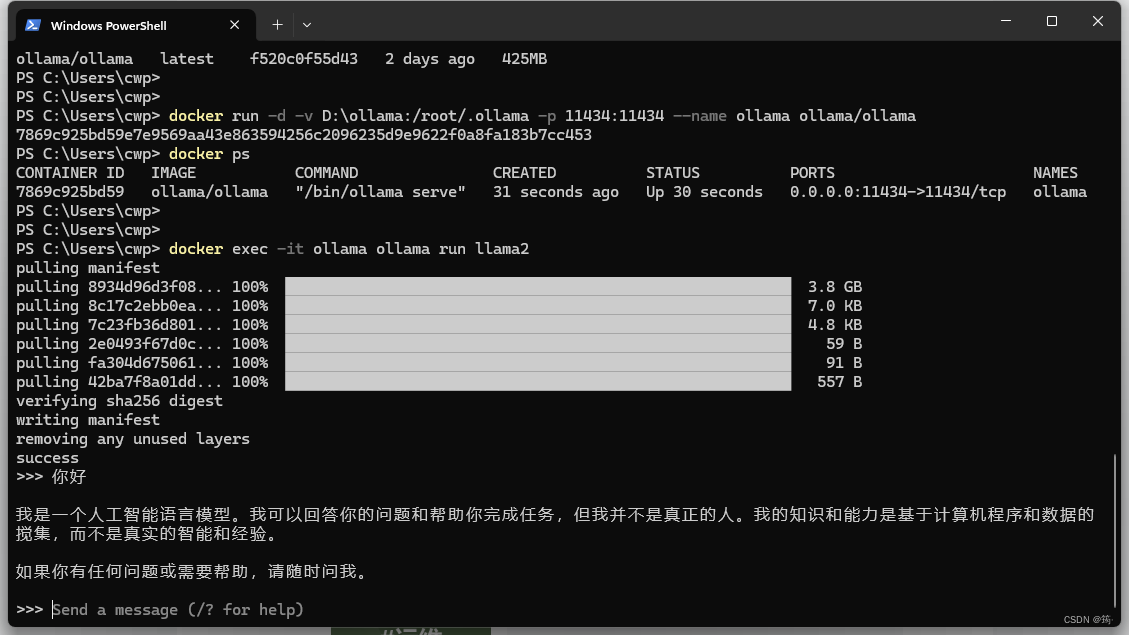
测试了一下,llama2没有gemma:7b聪明,所以,后来我用了
docker exec -it ollama ollama run gemma:7b
上图就是运行成功了,可以在命令行中输入任何问题了。
部署web界面
docker run -p 3000:3000 -e DEFAULT_MODEL=llama2:latest -e OLLAMA_HOST=http://IP地址:11434 ghcr.io/ivanfioravanti/chatbot-ollama:main用浏览器打开http://localhost:3000,即可像使用ChatGPT一样使用自己的私有GPT了。
ollama RestfulApi
POST localhost:11434/api/generate
{
"model": "mistral",
"prompt": "请用中文描述双亲委派机制",
"stream": false
}POST localhost:11434/api/chat
{
"model": "mistral",
"messages": [
{
"role": "user",
"content": "请用中文回答:python,java,c的执行效率比较,并说明原因"
}
]
}
curl http://localhost:11434/api/generate -d '{
"model": "llama2",
"prompt":"Why is the sky blue?"
}'
curl http://localhost:11434/api/chat -d '{
"model": "mistral",
"messages": [
{ "role": "user", "content": "why is the sky blue?" }
]
}'

