
- 1面向 AI 的编程 -- 爬虫实战:爬取某乎粉丝_ai爬虫
- 2ASM Disk Group Will not Mount In Presence Of Duplicate Disks / Devices: ORA-15032, ORA-15017, ORA-15...
- 3AI助力90.4%双11前端模块自动生成_基于ai javascript可视化编辑器
- 4【Bert】(六)句子关系判断--源码解析(bert基础模型)_max_position_embeddings
- 5浅谈sysfs系统--文件和目录的创建_zsfs文件为此系统的信息文件,在exit或quit的时候会自动创建在sfs_cache文件夹下。
- 6gateway集成sentinel配置nacos持久化GatewayFlowRule规则后--GatewayFlowRule规则失效(规则的时间单位和时间粒度失效)_在nacos中持久化的规则 加载了 但是不展示
- 7算法·动态规划Dynamic Programming
- 8Pytorch的安装教程从0开始_pytorch 安装
- 9DevOps 发展史_devops发展史
- 10WOT全球技术创新大会2022即将召开,亮点抢先看
KinectFusion原理介绍_kinect-fusion
赞
踩
1 简介:
2011年所开源的KinectFusion是第一个使用RGBD相机进行实时稠密三维重建的系统(需要GPU,甚至多个GPU或者高性能GPU),当时具有重大的开创意义;其所用的地图为TSDF地图,也对后续稠密地图的发展有着重大的意义。目前很多动态环境下的实时三维重建系统都是在KinectFusion或者ElasticFusion基础上扩展的。
实时三维重建技术与SLAM有很大的相关性,不同之处在于三维重建更关注建图的完整性和精度,而SLAM技术更关注定位精度,建图是为了辅助定位,并不太关注地图的精度以及稠密程度。
原文首发自我的古月居博客:https://www.guyuehome.com/34453
论文地址:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=6162880
代码地址:https://github.com/chrdiller/KinectFusionApp

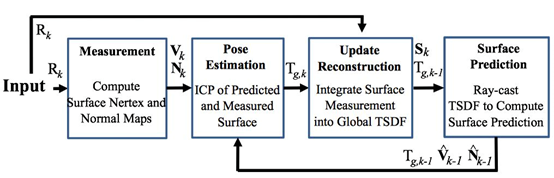
2 基础知识
2.1 点云(Point Cloud)
https://blog.csdn.net/hongju_tang/article/details/85008888
点云是在同一空间参考系下表达目标空间分布和目标表面特性的海量空间点的集合,在获取物体表面每个采样点的空间坐标后,得到的是点的集合,称之为“点云”(Point Cloud)。RGB-D设备是获取点云的设备,比如PrimeSense公司的PrimeSensor、微软的Kinect。点云的法向量是其重要的特征,可用来匹配特征点,ICP匹配点云位姿。目前PCL库已经实现了点云的大量操作,其地位类似于OpenCV之于图像。
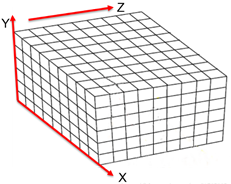
2.1 TSDF(Truncated Signed Distance Function)地图
https://blog.csdn.net/qq_30339595/article/details/86103576
TSDF可以译作截断符号距离函数,其是一种网格式的地图先选定要建模的三维空间,比如
3
×
3
×
3
m
3
3×3×3 m^3
3×3×3m3那么大,按照一定分辨率,将这个空间分成许多小块,存储每个小块内部的信息。TSDF地图整个存储在显存当中而不是内存中,由于每个体素的计算互相并不干扰,所以可以利用GPU的并行特性,并行地对对每个体素进行计算和更新。
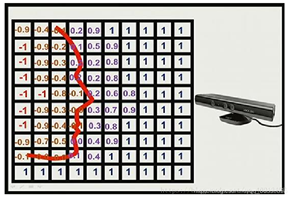
每个TSDF体素内,存储了该小块与最近的物体表面的距离。如果小块在最近物体表面的前方,它就有一个正的值;反之,如果该小块位于表面之后,那么这个值就为负。由于物体表面通常是很薄的一层,所以就把值太大的和太小的都取成1和-1,这就得到了截断之后距离,也就是所谓的TSDF。
3 原理介绍
对于输入的RGB-D图像,首先计算点云及其归一化后的法向量,然后通过ICP算法迭代计算当前帧的相机位姿(输入为三维场景投影得到上一帧的深度图像,以及当前帧的点云),之后将当前点云融合到TSDF地图中,最后通过TSDF地图以及当前帧的位姿,预测(投影)出当前帧的深度图,该深度图用来和下一帧的点云计算下一阵的位姿。

3.1 表面测量
根据每帧深度图像可以得到该帧的点云,首先通过双边滤波器去除噪声点云数据,然后计算每个空间点的法向量,计算法向量的具体方法为:
N k ( u ) = v [ ( V k ( u + 1 , v ) − V k ( u , v ) ) × ( V k ( u , v + 1 ) − V k ( u , v ) ) ] N_k(u)=v[(V_k(u+1,v)-V_k(u,v))×(V_k(u,v+1)-V_k(u,v))] Nk(u)=v[(Vk(u+1,v)−Vk(u,v))×(Vk(u,v+1)−Vk(u,v))]
其中:
v [ x ] = x / ∣ ∣ x ∣ ∣ 2 v[x]= x/||x||_2 v[x]=x/∣∣x∣∣2
其本质上就是求当前点与相邻点的向量,然后两向量的向量积(又称外积或者叉积),向量积垂直于两向量,对该项量进行归一化即可得到法向量。这只是最为简单直观的法向表达方式,其只利用三个点来计算法向量,易受噪声影响,还有很多利用邻域点云计算法向的方法,例如PCA方法:https://blog.csdn.net/suyunzzz/article/details/105534206。
3.2 表面预测
KinectFusion并没有直接利用当前帧与上一帧的图像直接通过ICP算法计算位姿,而是通过维护的TSDF地图以及上一帧图像的位姿,投影得到上一帧预测的深度图像(Frame-to-Model)。论文中提到,这样做的效果要比两帧之间直接计算位姿的效果好的多,后者的误差会逐渐累积,严重影响重建精度。
3.3 传感器位姿估计
KinectFusion采用ICP算法估计相机位姿,网上有很多原理讲解。首先将当前帧的点云转换到全局坐标系下(根据当前假设的位姿T),再转换到上一帧的相机坐标系下,将其投影到图像坐标系,计算得到对应前一帧的点,将上述的匹配点进行距离和法向量的对比,看是否是匹配点(有点类似于直接法)。详见博文:https://blog.csdn.net/XBB102910/article/details/52968024。
得到匹配点之后,通过最小化点到平面的距离计算位姿,目标函数为:
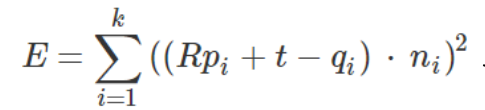

其中 q i q_i qi为当前点云中的一点, p i p_i pi为其匹配点通过位姿变换后的空间点, 为投影过两点的向量,在图中即为向量 d i s i d_i s_i disi,向量乘以di的归一后的法向量 n i n_i ni,即可得到点 s i s_i si到点 d i d_i di切平面的距离,也就是我们所要最小化的误差项。当两点投影过后完全重合,该项为0。
3.4 表面重建更新
最后根据当前帧的深度信息计算TSDF地图,并以加权的形式融合到全局的TSDF中。
4 总结
KinectFusion是第一个使用RGBD相机进行实时稠密三维重建的系统,在当时(2011年)具有非常重大的开创意义,后续很多工作都是在此就基础上开展的,Frame-to-Model的ICP算法依然得到很大的应用。
不足之处:
- (1) TSDF地图需要缓存在显卡中,对显卡性能要求比较高;实时性是建立在GPU加速计算的基础上的,对GPU性能有要求。
- (2) 没有考虑到环境的变换,在动态场景下鲁棒性不够强。
- (3) 没有回环检测等环节,与ORB-SLAM系统的定位精度有较大差距。
参考:
https://www.bilibili.com/video/BV1Ls41167ud?share_source=copy_web
https://blog.csdn.net/fuxingyin/article/details/51417822
https://www.bilibili.com/video/BV117411u7D4?share_source=copy_web

