
热门标签
热门文章
- 1何时应用 RAG 与微调
- 2FFmpeg常用命令汇总_ffmpeg命令大全
- 3大数据技术学习笔记(十一)—— Flume_大数据学习笔记
- 4【项目实战】npm 删除node_modules的多种方式_npm删除nodemodules
- 5惊叹 | 膜拜一下清华大学特等奖学金的学霸大佬们的简历! -- 我们没有理由不努力!...
- 6HTML-day02-列表标签,表格标签,form表单_列表ul和表格tr的区别
- 7Fastboot 命令报错分析篇_(bootloader) current-slott: not found
- 8周末没有怎么出门,终于解决了word不能另存为UTF8格式txt的问题_文本文档另存utf8没有用
- 9STM32CubeMX + freeRTOS线程操作(二)_oskernelsystick
- 10pytorch模型参数迁移(三种方法)_pytorch模型迁移有哪几种方法?
当前位置: article > 正文
机器学习之基于文本内容的垃圾短信识别_机器学习判断是否为垃圾短信
作者:知新_RL | 2024-04-07 08:25:02
赞
踩
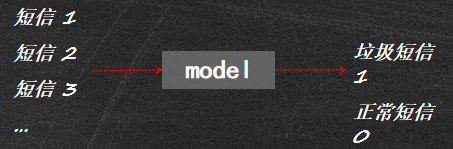
机器学习判断是否为垃圾短信
机器学习之基于文本内容的垃圾短信识别
1.背景与目标
2.数据探索
3.数据预处理
4.文本的向量表示
5.模型训练与评价
1.背景与目标
- 我国目前的垃圾短信现状:
垃圾短信黑色利益链
缺乏法律保护
短信类型日益多变

- 案例目标:垃圾短信识别。
基于短信文本内容,建立识别模型,准确地识别出垃圾短信,以解决垃圾短信过滤问题
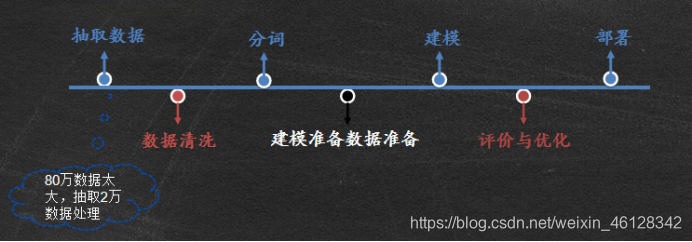
2.数据探索
- 总体流程
- 数据展示

*观察数据,请思考:
建模前需要对文本数据做哪些处理?
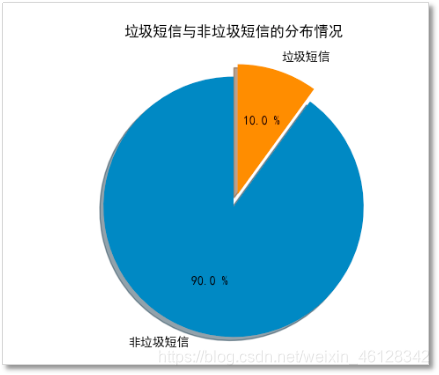
需要怎么评价模型的好坏? - 数据分布
对原始80万条数据进行数据探索,发现数据中并无存在空值,进一步查看垃圾短信和非垃圾短信的分布情况。
- 欠抽样
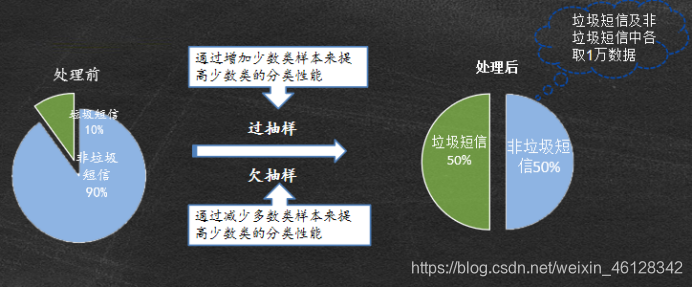
- 数据抽取
随机抽取上文的2W条文本处理后的数据的80%作为训练样本,其余作为测试集样本。
3.数据预处理
步骤:数据清洗----分词—添加词典去停用词—绘制词云
- 去除空格 (空格及全角情况下的空格)

- x序列 (将银行账户、电话、固话、QQ、价格、日期替换成x序列)

- 文本去重
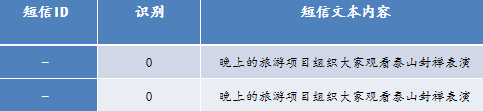
在数据的的储存和提取过程中,由于技术和某些客观的原因,造成了相同短信文本内容缺失等情况,因此需要对文本数据进行去重,去重即仅保留重复文本中的一条记录。
-
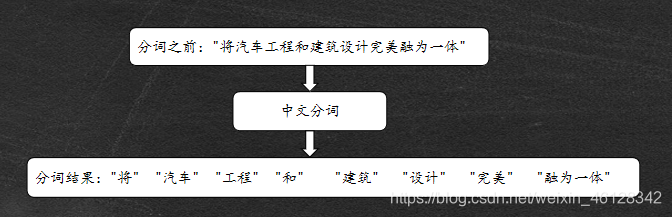
中文分词
中文分词是指以词作为基本单元,使用计算机自动对中文文本进行词语的切分,即使词之间有空格,这样方便计算机识别出各语句的重点内容。
-
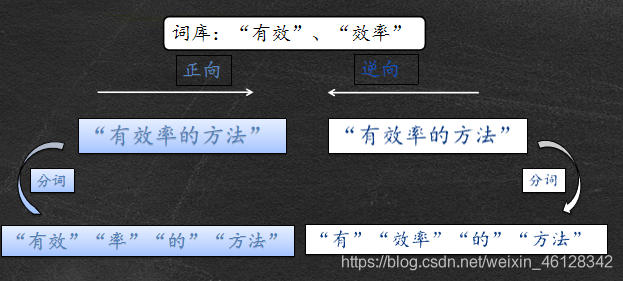
正向最大匹配法
-
NLP概率图:HMM针对中文分词应用-Viterbi算法
利用Viterbi算法找出一条概率最大路径。

-
python 结巴分词(jieba)支持三种分词模式
支持繁体分词
支持自定义词典 -
停用词过滤
中文表达中最常用的功能性词语是限定词,如“的”、“一个”、“这”、“那”等。这些词语的使用较大的作用仅仅是协助一些文本的名词描述和概念表达,并没有太多的实际含义。
而大多数时候停用词都是非自动生产、人工筛选录入的,因为需要根据不同的研究主题人为地判断和选择合适的停用词语。

-
绘制词云图
词云图是文本结果展示的有利工具,通过词云图的展示可以对短信文本数据分词后的高频词予以视觉上的强调突出效果,使得阅读者一眼就可获取到主旨信息。
 垃圾短信
垃圾短信
 正常短信
正常短信
如何将文本数据放入模型?

4.文本的向量表示
- 文本分类实例
1.'My dog has flea problems, help please.’
2.'Maybe not take him to dog park is stupid.’
3.'My dalmation is so cute. I love him.’
4.'Stop posting stupid worthless garbage.’
5.'Mr licks ate mu steak, what can
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/知新_RL/article/detail/377467
推荐阅读
相关标签

