
- 1leecode-1379-找出克隆二叉树中的相同节点_code1379
- 2web课程设计——仿小米商城(10个页面)HTML+CSS+JavaScript web前端课程设计 web前端课程设计代码 web课程设计 HTML网页制作代码
- 3java比较两个实体类及属性差异工具类(简版)_java实体类属性差集
- 4SpringbootV2.6整合Knife4j 3.0.3 问题记录_springboot2.6对应的knife版本
- 5Python自然语言处理学习笔记(2):Preface 前言
- 6MATLAB中的曲线拟合_matlab的linefit
- 7《.Net 基础系列》- IO操作
- 8分析Java8中的stream.map()函数_java 8 stream map
- 9多目标跟踪:视觉联合检测和跟踪
- 10概率论与数理统计B 重点/笔记梳理 第二章_概率论与数理统计考点归纳两点分布
模型量化 | Pytorch的模型量化基础_pytorch 量化模型
赞
踩
量化简介
量化是指执行计算和存储的技术 位宽低于浮点精度的张量。量化模型 在张量上执行部分或全部操作,精度降低,而不是 全精度(浮点)值。这允许更紧凑的模型表示和 在许多硬件平台上使用高性能矢量化操作。 与典型的 FP32 模型相比,PyTorch 支持 INT8 量化,
- 模型大小减少 4 倍
- 内存带宽减少 4 倍
- INT8 计算的硬件支持通常为 2 到 4 个 与 FP32 计算相比,速度快几倍
量化主要是一种技术 加速推理,量化仅支持前向传递 运营商。
PyTorch 支持多种量化深度学习模型的方法。在 大多数情况下,模型在 FP32 中训练,然后将模型转换为 INT8 中。此外,PyTorch 还支持量化感知训练,这 使用以下方法对前向和后向传递中的量化误差进行建模 假量化模块。请注意,整个计算是在 浮点。在量化感知训练结束时,PyTorch 提供 转换函数,用于将训练好的模型转换为较低精度的模型。
在较低级别,PyTorch 提供了一种表示量化张量和 使用它们执行操作。它们可用于直接构建模型 以较低的精度执行全部或部分计算。更高级别 提供了包含转换 FP32 模型的典型工作流的 API 以最小的精度损失降低精度。
pytorch从1.3 版开始,提供了量化功能,PyTorch 1.4 发布后,在 PyTorch torchvision 0.5 库中发布了 ResNet、ResNext、MobileNetV2、GoogleNet、InceptionV3 和 ShuffleNetV2 的量化模型。
PyTorch 量化 API 摘要
PyTorch 提供了两种不同的量化模式:Eager Mode Quantization 和 FX Graph Mode Quantization。
Eager Mode Quantization 是一项测试版功能。用户需要进行融合并指定手动进行量化和反量化的位置,而且它只支持模块而不是功能。
FX Graph Mode Quantization 是 PyTorch 中一个新的自动化量化框架,目前它是一个原型功能。它通过添加对函数的支持和自动化量化过程来改进 Eager Mode Quantization,尽管人们可能需要重构模型以使模型与 FX Graph Mode Quantization 兼容(符号上可追溯到 )。请注意,FX Graph Mode Quantization 预计不适用于任意模型,因为该模型可能无法符号跟踪,我们将它集成到 torchvision 等域库中,用户将能够量化类似于 FX Graph Mode Quantization 支持的域库中的模型。对于任意模型,我们将提供一般准则,但要真正使其工作,用户可能需要熟悉,尤其是如何使模型具有符号可追溯性。torch.fxtorch.fx
PyTorch量化结构
- PyTorch 具有与量化张量对应的数据类型,这些张量具有许多张量的特征。
- 人们可以编写具有量化张量的内核,就像浮点张量的内核一样,以自定义其实现。PyTorch 支持将常见操作的量化模块作为 和 name-space 的一部分。
torch.nn.quantizedtorch.nn.quantized.dynamic - 量化与 PyTorch 的其余部分兼容:量化模型是可跟踪和可编写脚本的。服务器和移动后端的量化方法几乎相同。可以轻松地在模型中混合量化和浮点运算。
- 浮点张量到量化张量的映射可以使用用户定义的观察者/假量化模块进行自定义。PyTorch 提供了适用于大多数用例的默认实现。
【量化张量,量化模型 ,工具上的量化】
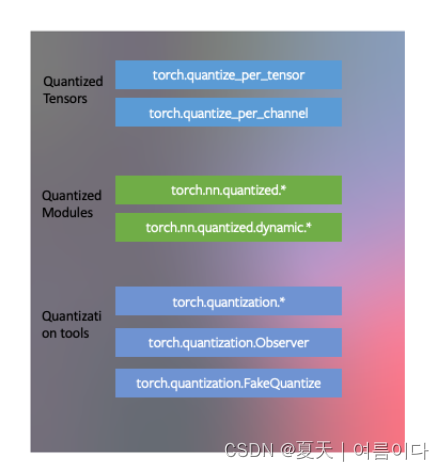
PYTORCH的三种量化模式
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/377533
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

