
淘宝数据可视化大屏案例(Hadoop实验)_hadoop数据分析可视化案例
赞
踩
身处大数据时代,每一天都在产生数据,对于数据的应用是每一个行业的最基本的要求,也是他们立足和竞争商业世界的必要手段。在这个“化数为金”的时代,对数据的敏感程度不仅仅是那些专业人士的目标所向,而是对于每一个人的挑战与机遇。数据分析已经成为21世纪最为广泛的一次信息革命,它终将成为未来最基础的生存技能
数据挖掘——数据清洗——数据分析——数据可视化——数据语言大众化——数据价值化
工欲善其事必先利其器
Hadoop镜像文件,该专栏下的环境,点击此处下载,只需要安装一个vmwear即可,点击加载即可获得Hadoop全套操作组件环境
如果有时间需要自己搭建的,下面有安装包和操作指南链接

项目简介
我们选取了12月1日-18号的数据,进行简单的模拟大数据分析(6万多条,实际项目一般是上亿,文件大小都是TB级,一般的软件无法分析处理,只可以借助Hadoop大数据分析)




项目条件
1.首先要准备数据集

数据集点击此处下载
2.准备环境,Hadoop集群,需要hdfs,hive,Fiume,sqoop等插件,需要提前自己安装,使用12月数据做一个分析
项目步骤
1.启动Hadoop集群并查看
start-all.sh
jps
- 1
- 2

2.配置表支持事务(十分重要)
2.1 改配置文件hive-site.xml 或者 临时设置参数 命令行
<property>
<name>hive.support.concurrency</name>
<value>true</value>
</property>
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value>
</property>
<property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
</property>
<property>
<name>hive.compactor.initiator.on</name>
<value>true</value>
</property>
<property>
<name>hive.compactor.worker.threads</name>
<value>1</value>
<!--这里的线程数必须大于0 :理想状态和分桶数一致-->
</property>
<property>
<name>hive.enforce.bucketing</name>
<value>true</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
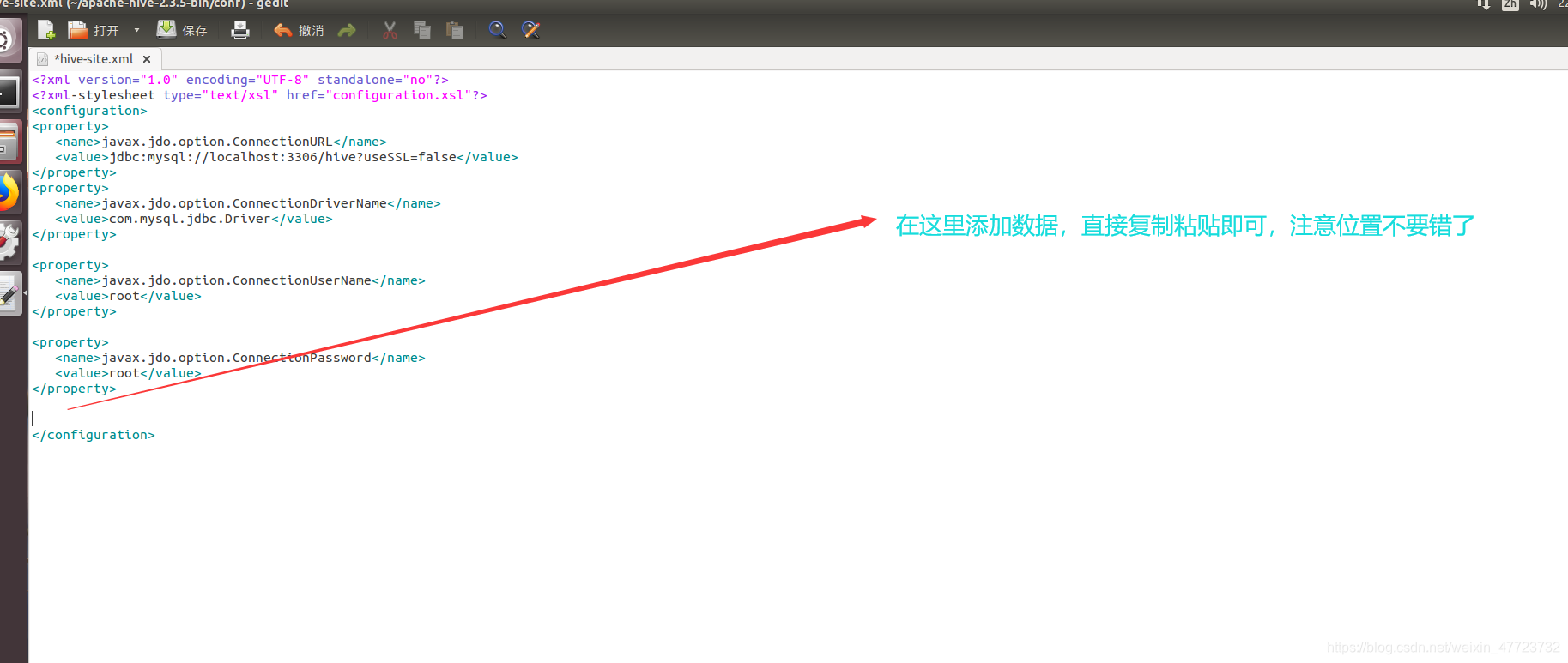
首先在Hadoop计算机里面找到这个文件,因为配置文件已经存在了,我们只需要在后面添加上面的数据即可,操作步骤截图如下:

注意这里修改的是hive文件下面的,也就是第一个文件,不是第二个flume!


2.2 使用vi命令,新建一个file_hive.properties文件,把下面的数据插入到里面
#定义agent名, source、channel、sink的名称
agent3.sources = source3
agent3.channels = channel3
agent3.sinks = sink3
#具体定义source
agent3.sources.source3.type = spooldir
agent3.sources.source3.spoolDir = /home/hadoop/taobao/data
agent3.sources.source3.fileHeader=false
#设置channel类型为磁盘
agent3.channels.channel3.type = file
#file channle checkpoint文件的路径
agent3.channels.channel3.checkpointDir=/home/hadoop/taobao/tmp/point
# file channel data文件的路径
agent3.channels.channel3.dataDirs=/home/hadoop/taobao/tmp
#具体定义sink
agent3.sinks.sink3.type = hive
agent3.sinks.sink3.hive.metastore = thrift://hadoop:9083
agent3.sinks.sink3.hive.database = taobao
agent3.sinks.sink3.hive.table = taobao_data
agent3.sinks.sink3.serializer = DELIMITED
agent3.sinks.sink3.serializer.delimiter = ","
agent3.sinks.sink3.serializer.serdeSeparator = ','
agent3.sinks.sink3.serializer.fieldnames = user_id,item_id,behavior_type,user_geohash,item_category,date,hour
agent3.sinks.sink3.batchSize = 90
#组装source、channel、sink
agent3.sources.source3.channels = channel3
agent3.sinks.sink3.channel = channel3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
vi file_hive.properties
- 1
- 2
该文件用于监听的作用,自动就会在家目录下面,然后我们需要创建几个文件夹,就是下图我备注的那些字段
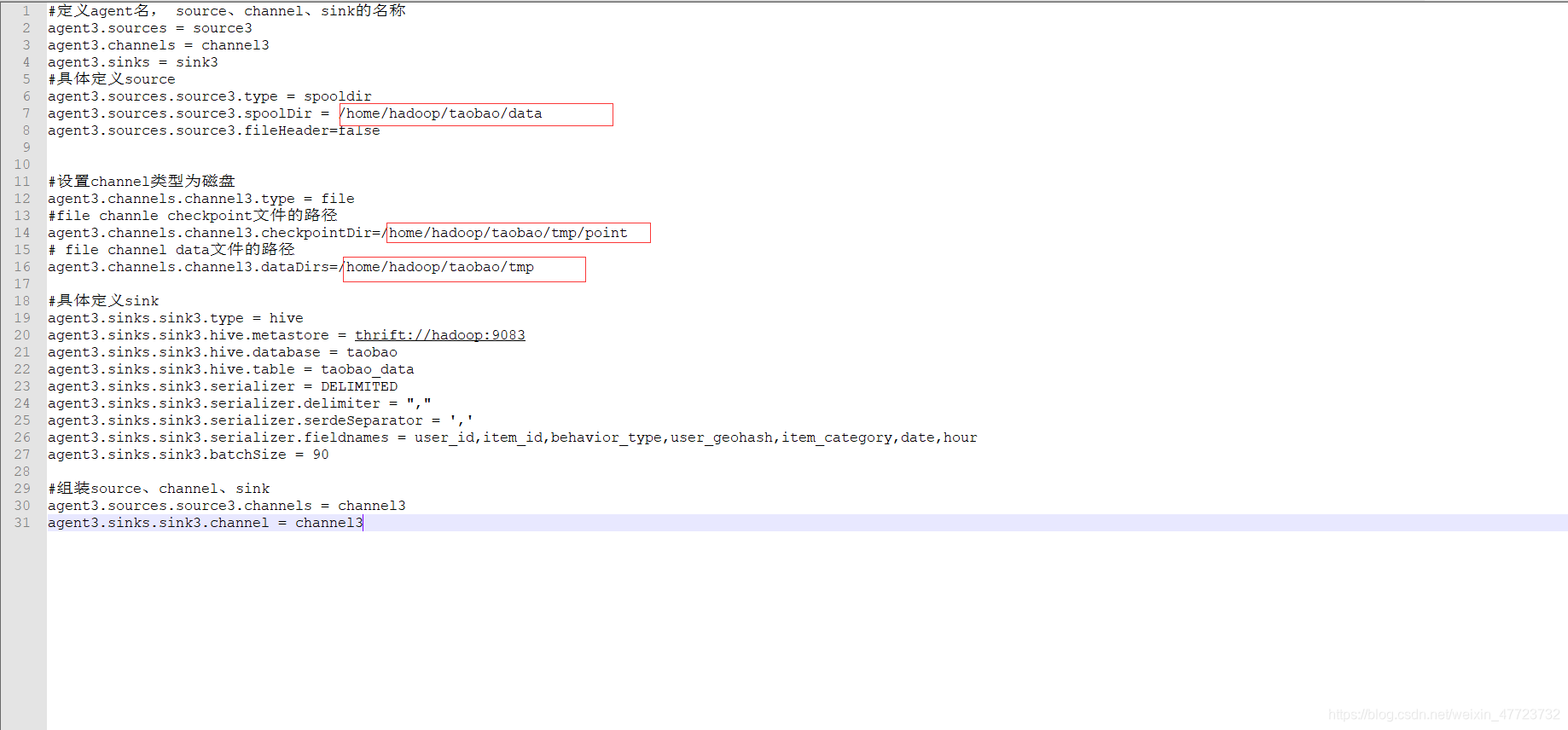
mkdir -p /home/hadoop/taobao/data
mkdir -p /home/hadoop/taobao/tmp/point
- 1
- 2
- 3

3.3 创建数据库
由于版本问题,需要导入指定的jar包
把${HIVE_HOME}/hcatalog/share/hcatalog/下的所有包,拷贝入${FLUME_HOME}/lib
- 1
执行下面的命令:
cd ${HIVE_HOME}/hcatalog/share/hcatalog/
cp * ${FLUME_HOME}/lib/
- 1
- 2
- 3
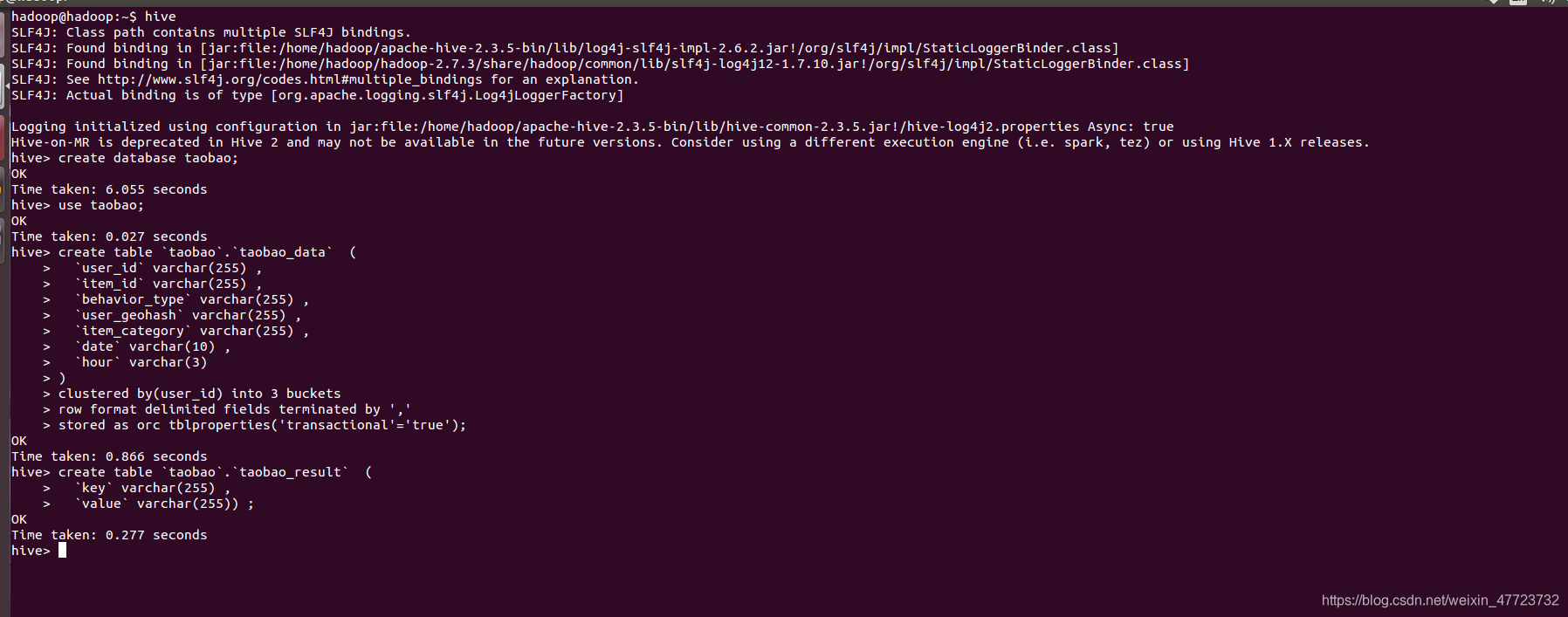
启动hive
hive
- 1
创建数据库并使用
create database taobao;
use taobao;
- 1
- 2
建立表格
create table `taobao`.`taobao_data` (
`user_id` varchar(255) ,
`item_id` varchar(255) ,
`behavior_type` varchar(255) ,
`user_geohash` varchar(255) ,
`item_category` varchar(255) ,
`date` varchar(10) ,
`hour` varchar(3)
)
clustered by(user_id) into 3 buckets
row format delimited fields terminated by ','
stored as orc tblproperties('transactional'='true');
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
创建导出数据表
create table `taobao`.`taobao_result` (
`key` varchar(255) ,
`value` varchar(255)) ;
- 1
- 2
- 3
- 4
4.导入数据
先启动hive --service metastore -p 9083
(这个端口号要配置到flume文件中,可用netstat -tulpn | grep 9083查看端口是否监听)
hive --service metastore -p 9083
- 1
再去启动flume
flume-ng agent --conf conf --conf-file file_hive.properties -name agent3 -Dflume.hadoop.logger=INFO,console
- 1
然后把文件数据导入到,之前创建的data文件夹里面就完成了自动导入
mv /home/hadoop/12yue.csv /home/hadoop/taobao/data/
- 1
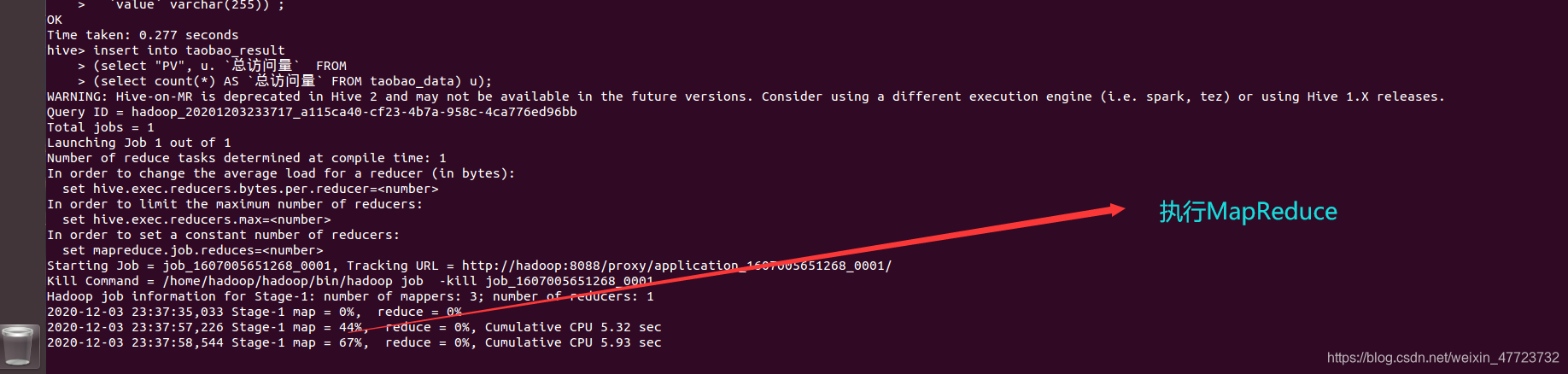
5.数据分析
5.1 把总访问量查询出来,导入到结果表
insert into taobao_result
(select "PV", u. `总访问量` FROM
(select count(*) AS `总访问量` FROM taobao_data) u);
- 1
- 2
- 3
INSERT INTO taobao_result
(SELECT " UV", u. `用户数量` FROM
(SELECT COUNT(DISTINCT user_id) AS `用户数量` FROM taobao_data) u);
- 1
- 2
- 3

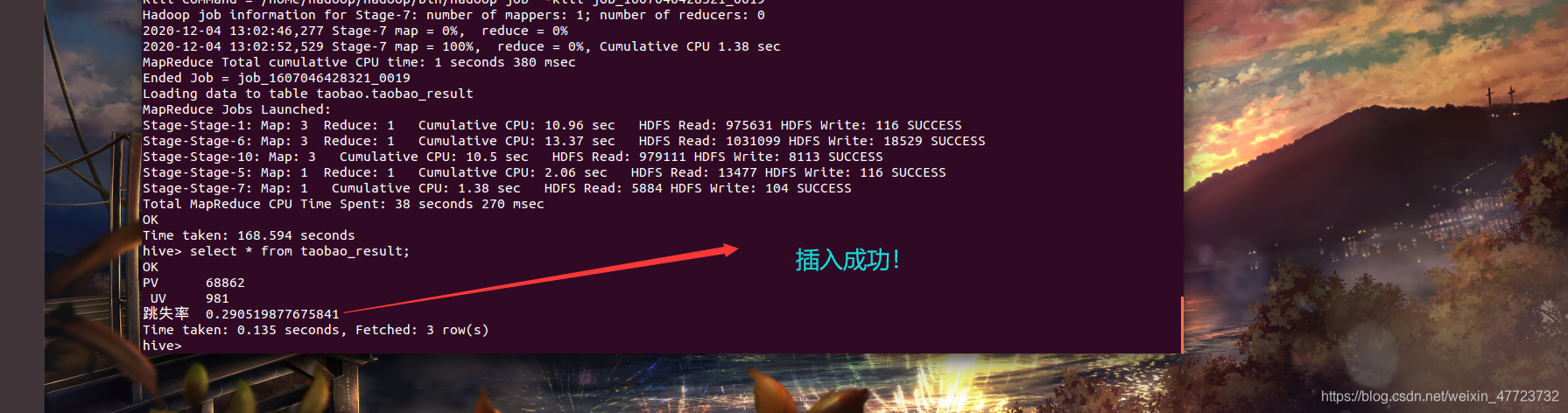
可以查看一下
select * from taobao_result;
- 1

5.2 – 浏览页跳失率:用户仅仅有pv行为,没有其它的收藏、加购、购买行为
INSERT INTO taobao_result
(SELECT "跳失率", u. `总访问量` FROM
(
SELECT b.`仅pv用户` / a.`总用户` AS `总访问量` FROM
(SELECT count( DISTINCT user_id ) AS `总用户` FROM taobao_data) a ,
(SELECT
count( DISTINCT user_id ) AS `仅pv用户`
FROM taobao_data
WHERE
user_id NOT IN ( SELECT DISTINCT user_id FROM taobao_data WHERE behavior_type = '2' ) AND
user_id NOT IN ( SELECT DISTINCT user_id FROM taobao_data WHERE behavior_type = '3' ) AND
user_id NOT IN ( SELECT DISTINCT user_id FROM taobao_data WHERE behavior_type = '4' )) b
) u);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
注意在hive里面不可以使用in not in查询,所以这里要用连接查询解决这个问题
经过大量的测试,我自己写了一个sq语句,也可以达到以上的效果
首先把要插入的信息,查询出来
SELECT "跳失率", u.`总访问量` FROM
(
SELECT b.`仅pv用户` / a.`总用户` AS `总访问量` FROM
(SELECT count( DISTINCT user_id ) AS `总用户` FROM taobao_data) a,
(SELECT count( DISTINCT user_id ) AS `仅pv用户` from (select * from taobao_data) as c LEFT JOIN (SELECT DISTINCT user_id as `id` FROM taobao_data WHERE behavior_type = '2' or behavior_type='3' or behavior_type='4') as d on c.user_id=d.id WHERE d.id is NULL ) as b
) as u;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
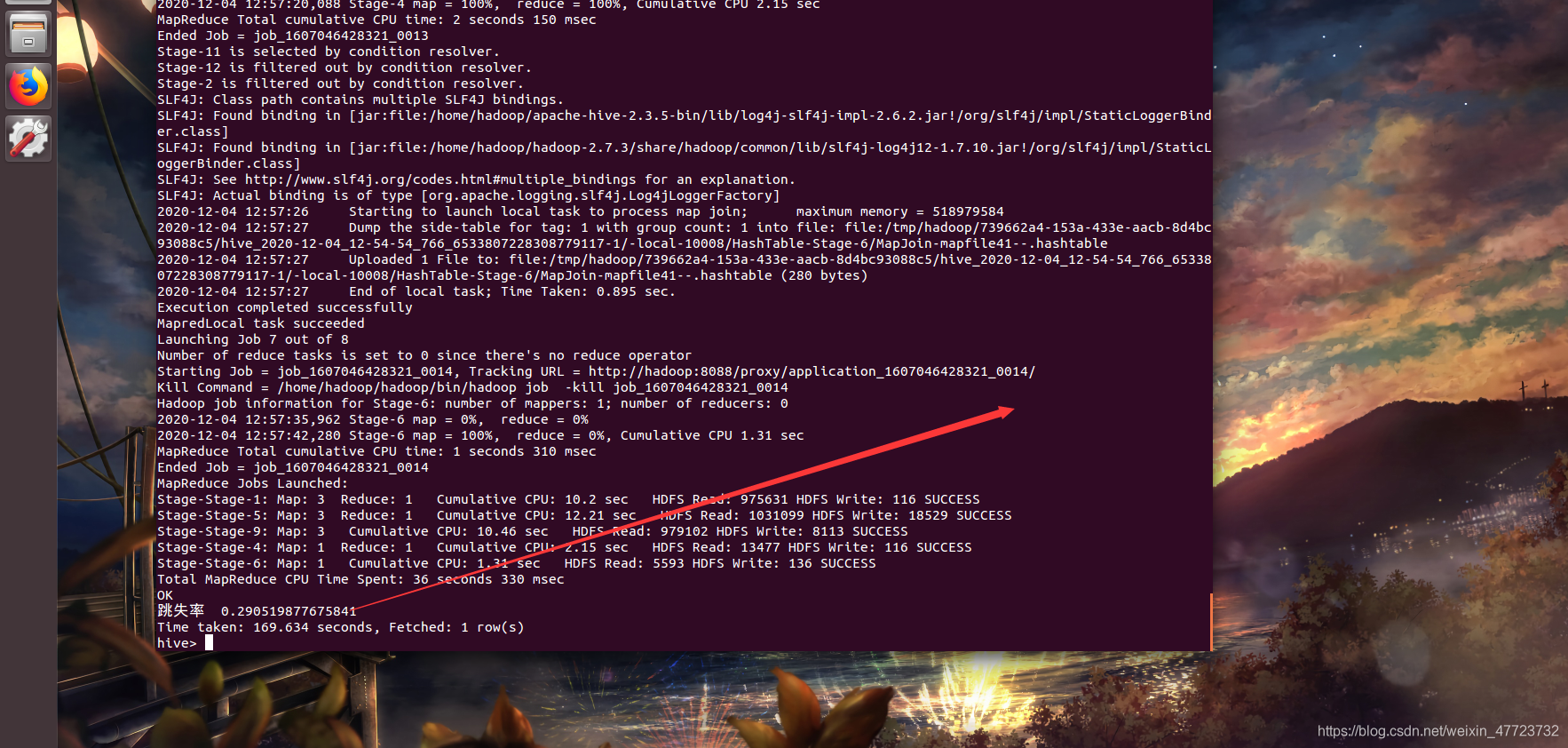 插入
插入
INSERT INTO taobao_result
(SELECT "跳失率", u.`总访问量` FROM
(
SELECT b.`仅pv用户` / a.`总用户` AS `总访问量` FROM
(SELECT count( DISTINCT user_id ) AS `总用户` FROM taobao_data) a,
(SELECT count( DISTINCT user_id ) AS `仅pv用户` from (select * from taobao_data) as c LEFT JOIN (SELECT DISTINCT user_id as `id` FROM taobao_data WHERE behavior_type = '2' or behavior_type='3' or behavior_type='4') as d on c.user_id=d.id WHERE d.id is NULL ) as b
) as u);
- 1
- 2
- 3
- 4
- 5
- 6
- 7

优化代码类型(思路类似)
SELECT count(DISTINCT user_id) from datas left JOIN
(select DISTINCT user_id as t from datas WHERE behavior_type ='2' or behavior_type ='3' or behavior_type ='4') as a on user_id=a.t WHERE a.t is null
- 1
- 2
5.3
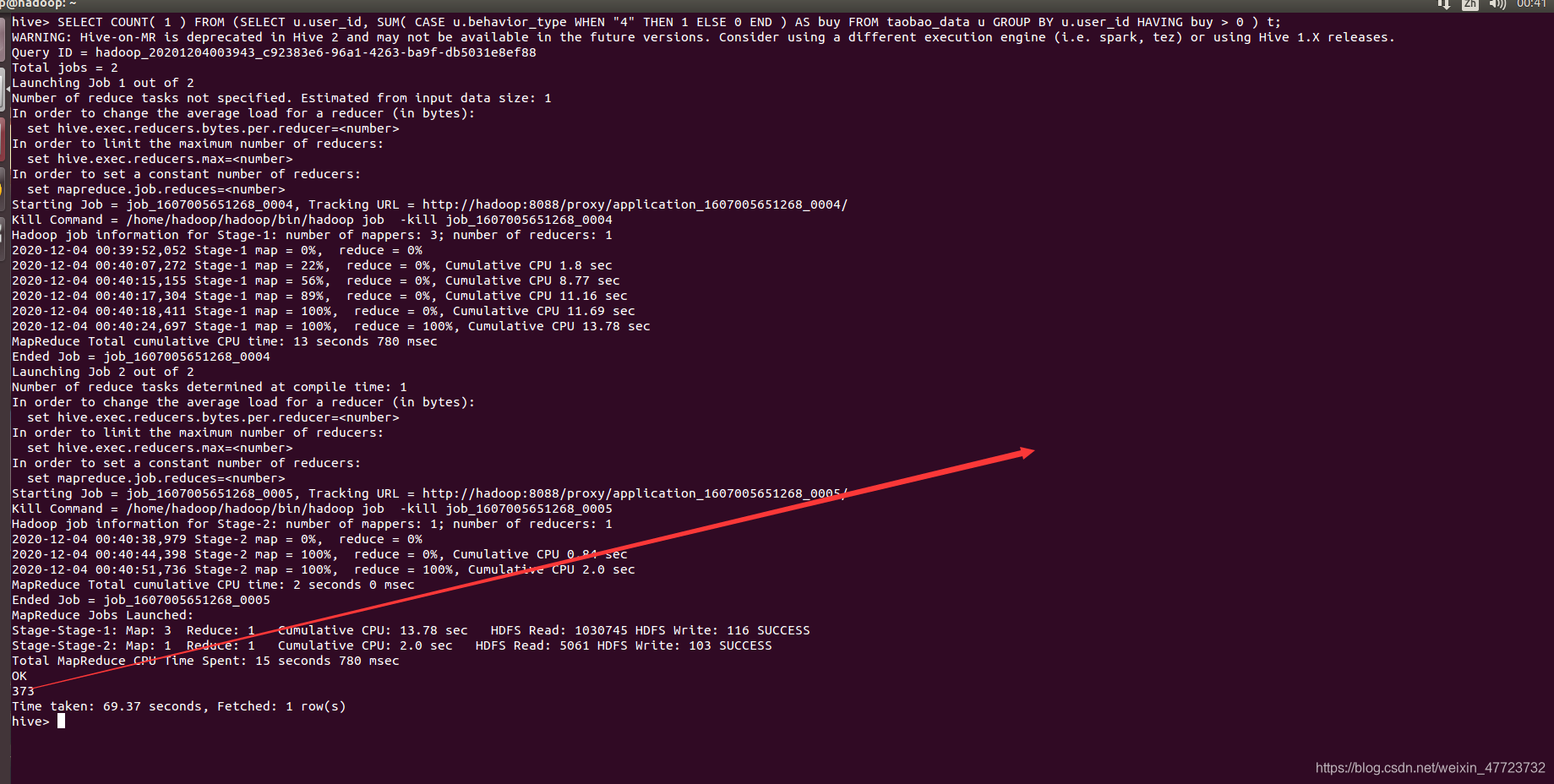
– 有购买行为的用户数量、用户的购物情况、复购率分别是多少?
SELECT COUNT( 1 ) FROM (SELECT u.user_id, SUM( CASE u.behavior_type WHEN "4" THEN 1 ELSE 0 END ) AS buy FROM taobao_data u GROUP BY u.user_id HAVING buy > 0 ) t;
- 1
SELECT COUNT(1) AS `总数`, SUM(CASE u.behavior_type WHEN "1" THEN 1 ELSE 0 END ) AS `点击行为`,SUM(CASE u.behavior_type WHEN "2" THEN 1 ELSE 0 END ) AS `收藏行为`,SUM(CASE u.behavior_type WHEN "3" THEN 1 ELSE 0 END ) AS `加购物车行为`,SUM(CASE u.behavior_type WHEN "4" THEN 1 ELSE 0 END ) AS `购买行为` FROM taobao_data u;
- 1
- 2
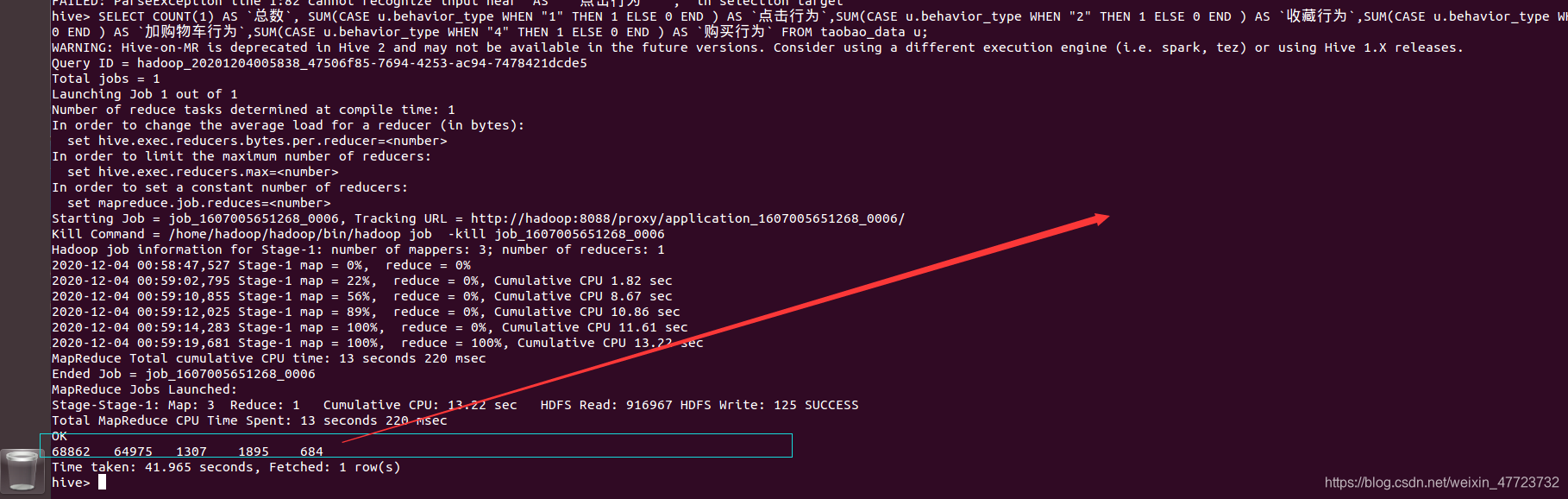
5.4 – 复购率 购买次数大于2的人占总的人数的比率
必须要输入下面代码
set hive.mapred.mode=nonstrict;
- 1
注意这个sq语句里面的4,必须也要用单引号括起来
SELECT t2.repeat_buy/t1.total AS `复购率` FROM
(SELECT COUNT(DISTINCT u1.user_id) AS total FROM taobao_data u1) t1 ,
(SELECT COUNT(1) AS repeat_buy FROM
(SELECT u.user_id, SUM(CASE u.behavior_type WHEN '4' THEN 1 ELSE 0 END ) AS buy FROM taobao_data u GROUP BY u.user_id HAVING buy>1) t) t2;
- 1
- 2
- 3
- 4

 5.5 分析用户在哪个时间段最为活跃,包括日期和时间
5.5 分析用户在哪个时间段最为活跃,包括日期和时间
SELECT `date`,count(*) as `t` from taobao_data GROUP BY `date` ORDER BY `t` DESC;
- 1

SELECT `hour`,count(*) as `t` from taobao_data GROUP BY `hour` ORDER BY `t` DESC;
- 1

导出数据
去自己的Navicat里面执行去试试也可以
CREATE DATABASE taobao;
create table `taobao`.`taobao_result` (
`key` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`value` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
 虚拟机执行也可以
虚拟机执行也可以
show create table taobao_result
- 1

在终端界面运行
sqoop export --connect jdbc:mysql://localhost:3306/taobao --username root -P --table taobao_result --export-dir /user/hive/warehouse/taobao.db/taobao_result -m 1 --input-fields-terminated-by '\001'
- 1
 查询一下数据是否导入成功
查询一下数据是否导入成功

OK!
可视化展示——基于Python里面的pyecharts库

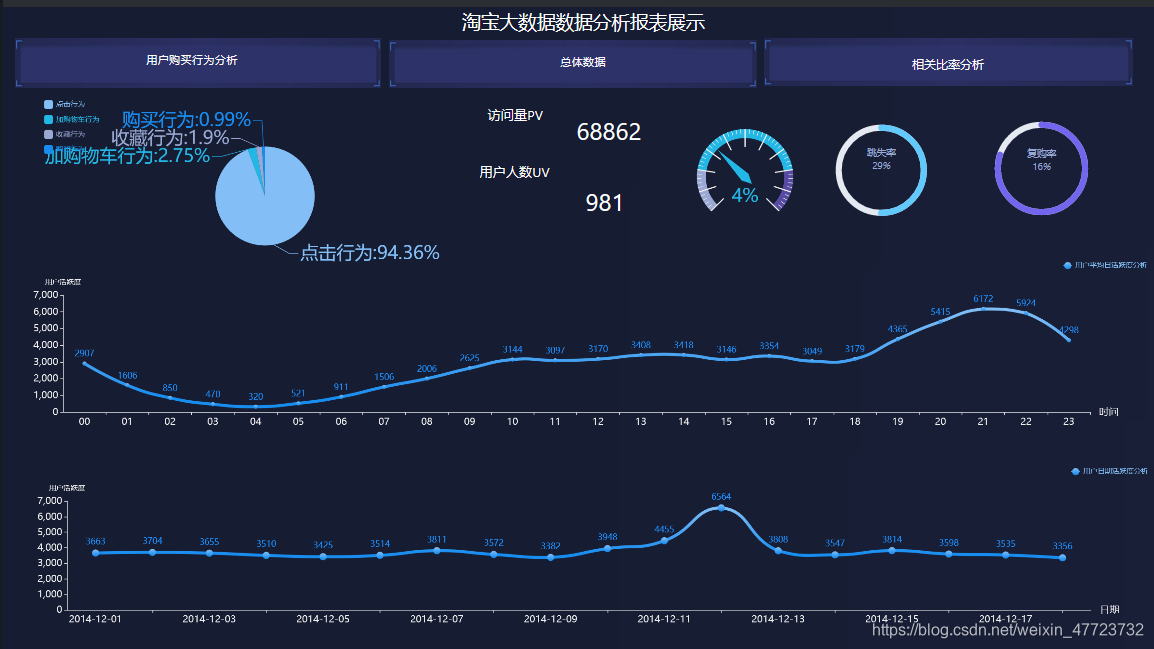
1.有不同的用户访问,按照IP地址来确定,对比之后用户点击率还是比较高的,和用户人数形成了极差,说明该电商还是比较吸引人,有大量的浏览量,说明网站还是比较吸引人,流量价值比较高,可以加大对广告的投入赚取利益。
 2.只看不买不收藏的用户占比总人数约1/3,说明还是比较可观,可以加大对网站信息化的建设以及,吸引更多的人,同时减少跳失率
2.只看不买不收藏的用户占比总人数约1/3,说明还是比较可观,可以加大对网站信息化的建设以及,吸引更多的人,同时减少跳失率



3.通过对用户的购买行为数据分析可知,用户主要对其内容感兴趣,访问量比较的大说明网站的种类还是比较的丰富,用户喜欢逛,但综合下来购买占比相对较少,但网站的流量比较大,可以发挥该优势,提高用户的收藏率和购买率,以及加入购物车行为,这就需要增加产品的质量,吸引更多的人愿意一次性购买(淘宝的特点,都喜欢逛)
 有图可知,复购率约占比4/25,说明二次购买的人数还是不够多,需要加强质量管理,同时增加一些二次购买福利,留住顾客
有图可知,复购率约占比4/25,说明二次购买的人数还是不够多,需要加强质量管理,同时增加一些二次购买福利,留住顾客

 分析可得用户喜欢在活动前后大幅度浏览网站,同时大部分人喜欢在6点(下班之后)浏览网页,到了晚上9点和10点带到高峰,建议在这段时间加强对网站的维护和广告的投入,达到相关的作用
分析可得用户喜欢在活动前后大幅度浏览网站,同时大部分人喜欢在6点(下班之后)浏览网页,到了晚上9点和10点带到高峰,建议在这段时间加强对网站的维护和广告的投入,达到相关的作用
项目总结
对于hive里面的数据操作,最为重要的就是sq语句的书写:
1.在MySQL里面可以运行的sq语句在hive里面未必可以运行成功,因为hive对sq语句要求的更为严格,其次hive里面不支持in not in 子查询,我们需要使用left join on 或者其他方法去实现相关功能的查询。
2.hive里面有时会报一些字段错误,那么很有可能就是sq语句书写的不够规范,其次在MySQL里面可以用‘’来表示子查询字符串,也就是一些表的字段名,但是hive里面有时候需要用Esc下面的那个符号,建议最好使用那个,以免报错。另外在使用sq语句在hive里面创建表格的时候注意大小写,create table …
3.导入数据的时候注意步骤不要出错了以及一些配置文件。
4.使用sqoop导出数据需要在mysql 里面提前创建好表格,从hive表导出,最终在MySQL里面进行相关查询,以及可视化分析。
5.只要hive报错语法错误,那么就按照最标准的语法格式书写准没错,亲测实用!
思路:首先准备好配置文件以及数据,导入只需移动进去,导出还需要查看该表的位置,至于中间的数据分析,必须熟练的掌握MySQL的查询语法。
我们在想,要是Python可以直接连接hive就好了,那么我们在Python环境里面执行查询语句,自动把数据集传给变量,然后利用可视化库进行展示,一键化岂不是很方便。确实可以,这个需要安装一些Python第三方库连接虚拟机里面的hive,这样我们进行大数据分析也就方便多了。
每文一语
学会尝试,说不定下一个幸运儿就是你!

