
- 1【Spark编程基础】实验三RDD 编程初级实践(附源代码)_1.编写独立应用程序实现数据去重 对于两个输入文件a和b,编写spark独立应用
- 2es解决只能查询10000条数据方案_es最多10000条
- 3GIT常见问题及其解决方案
- 4使用AI工具Lama Cleaner一键去除水印、人物、背景等图片里的内容_ai去水印 github
- 5华为防火墙:五种NAT类型以及配置NAT策略。_mode pat
- 6微信小程序解析副本内容---比较方便 直接引用插件即可_小程序的 富本 怎么用
- 7kafka部署
- 8Hadoop学习笔记(9)-Spark的jupyter notebook开发环境搭建_jupyter notebook 管理hadoop
- 9java8新特性(2)-Lambda表达式_lambo表达式
- 10JAVA中输入姓名张三_下列程序的功能是:输入一个姓名,程序运行后,输出“姓名Welcome you!”。例如,输出“张三Welcome you!”。请在下面_搜题易...
从ChatGPT到多模态大模型:现状与未来(多模态)
赞
踩
ChatGPT 训练的核心技术主要包括:
- 预训练语言模型;
- 有监督微调;
- 基于人类反馈的 强 化 学 习 (ReinforcementLearningfrom Human Feedback,RLHF)
首先,通过自监督预训练使语言模型从大规模语料库中学习语言规律,具备基础 理解和生成能力;然后,通过构造指令微调数据集 并对模型进行有监督微调,提升模型对人类意图的理解能 力,从而使模 型按要求执行多种任务;最 后,通过基于RLHF,根据人类偏好进一步提升型性能。
GPT系列采 用自回归语言建模预训练,即根据语料中前(i-1) 个单词预测第i个单词。自回归任务天然符合生成 式任务的特点,因此 GPT 系列模型具有较强的文本 生成能力。
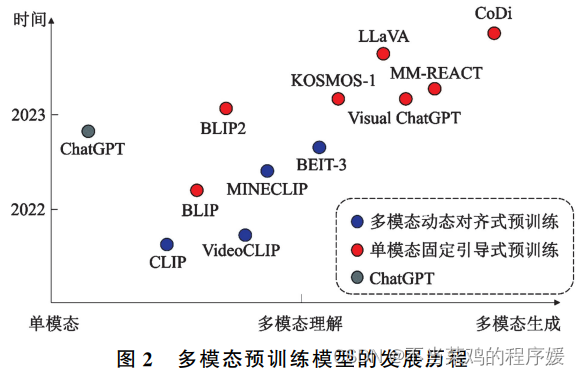
在模型架构方面,应着力探索具备多种模态综合理解与生成能力的预训练模型架构。我国当前的主流多模态预训练模型支持文本、图像输入和文本输出,缺少对更多模态的支持。一方面,现有模型难以处理图文以外的其他模态输入;另一方面,大多数现有模型仅能输出文本,或采用一个单独的图像生成模型实现图像输出,导致图像生成结果与原问题匹配程度较低,目前未能实现同时生成图像、文本等多模态信息。
在模型应用方面,应着力结合领域知识开发专业、可靠的特定领域大模型。我国目前已具备多个领域的专业知识库基础,可结合领域专业知识,通过
对通用领域的预训练大模型进行微调等方式,构建特定领域专用的大模型,相比通用大模型在各领域场景中具备更广泛的应用场景。同时,医学、电商等领域依赖图像、文本等多模态数据的协同分析,因此更需要领域专用的多模态预训练大模型。在模型部署方面,应着力
研究如何降低预训练模型的计算成本。我国乃至全球目前的预训练大模型均依赖大量的训练数据和计算资源,这对大模型的开发和部署使用造成了难以克服的障碍。因此,研究如何降低预训练大模型的计算成本,包括训练数据量、模型参数量等方面,具有重要的研究和应用价值。本章讨论的数据—知识双轮驱动作为路线之一,同时也有其他路线尚待进一步探索。
过去一年主流的多模态大模型按时间顺序进行排列,可以看到这样一张时间线图:
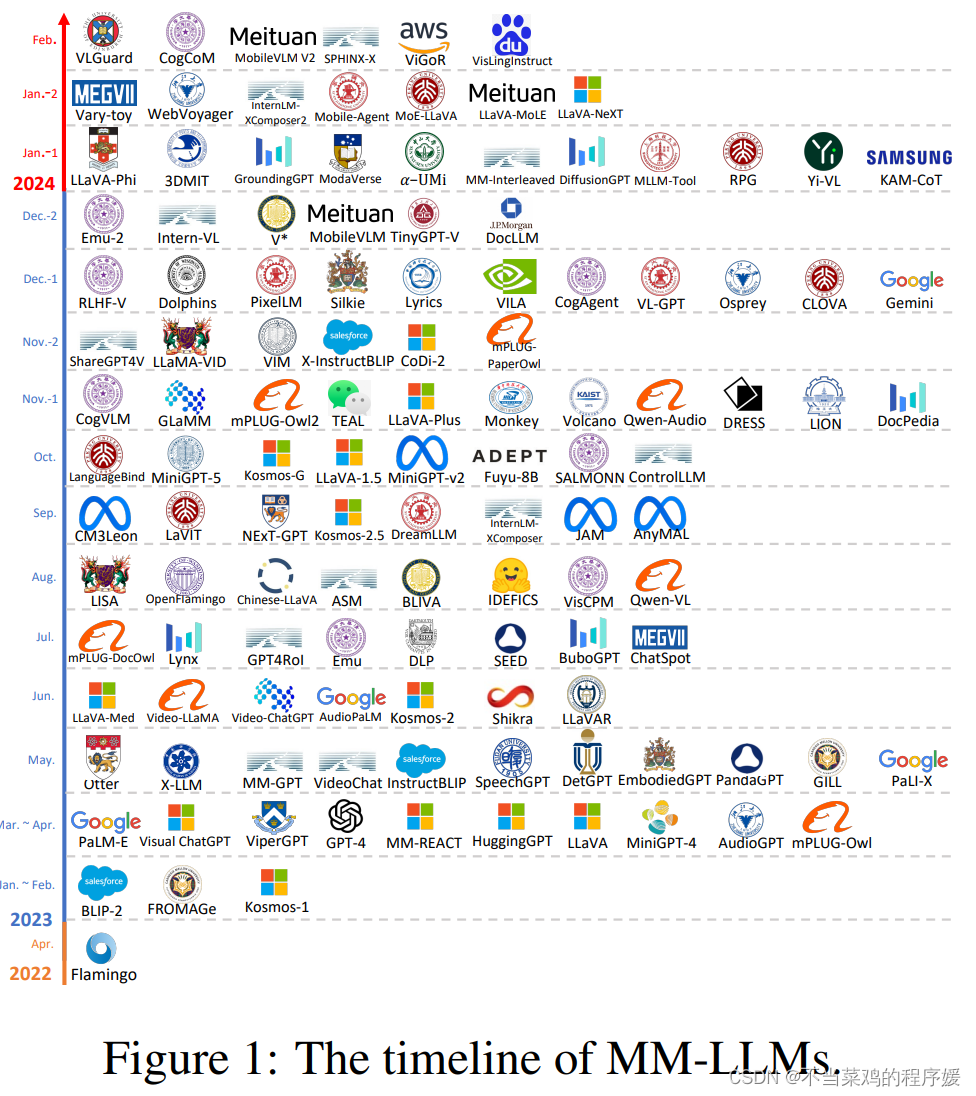 来自论文题目:MM-LLMs: Recent Advances in MultiModal Large Language Models
来自论文题目:MM-LLMs: Recent Advances in MultiModal Large Language Models

