
- 1技术资源:国内知名技术网站网址_农夫一夜十次
- 2spring框架概述 与 入门案例:IoC/DI_commons-loggins…jar
- 3华为od与中软外包哪个更好_华为员工感慨:天天捞人推OD,用话术忽悠,感觉良心上过不去了...
- 4基于afx透明视频的视觉增强前端方案
- 5阿里云Nodejs SDK——子设备接入物联网平台_const iot = require('./utils/aliyun-iot-sdk.js');
- 6mysql从已有表创建新表_参考原表创建一个新得表结构
- 7Python入门:三种模块实现数据写入 Excel表格_python写入excel单元格
- 8【C语言】将一个正整数分解质因数
- 9蓝桥杯青少年创意编程python初级考察内容_第十一届蓝桥杯青少年创意编程scratch初级组编程题详解...
- 10分布式搜索分析引擎ES_es分布式搜索引擎
超越Transformer!基于Patch的时间序列预测新SOTA!_patch时间序列预测
赞
踩
目前基于深度学习的时间序列预测主要有两大创新方向:一是模型结构创新,以informer为代表;二是数据输入创新,以PatchTST为代表。
在多变量时序预测领域,Patch的使用是为了将时间序列数据转换成适合深度学习模型处理的形式。这有助于提高模型的处理能力和预测精度,同时也优化了模型的计算效率。
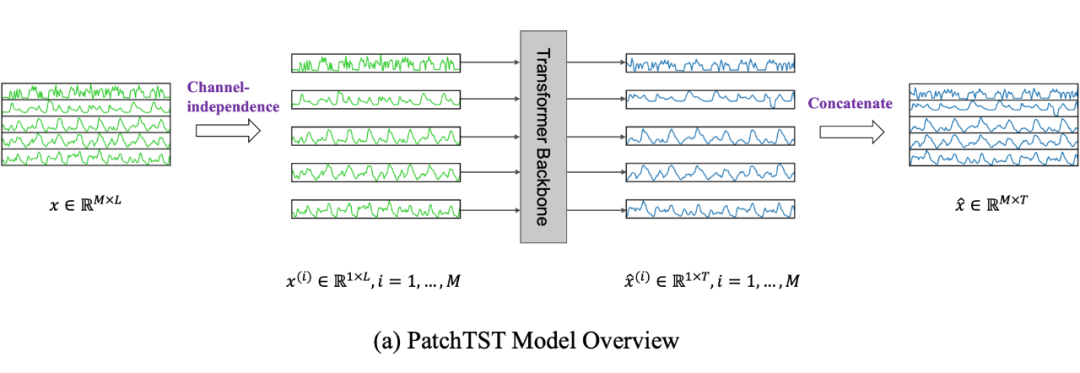
受视觉启发,Patch是近年深度学习时间序列预测的研究新宠,近期提出的SOTA成果为此证明。以PatchTST为例:
PatchTST通过引入patching和channel-independence两个关键设计,能够提取局部语义信息并利用更长的历史窗口进行预测。在监督学习、自监督表示学习和迁移学习等任务中都取得了优异的性能。
PatchTST具有以下几个优点:
1.时间和空间复杂度降低:通过patching操作,可以将输入token的数量从L降低到L/S,从而大大降低了计算时间和内存的复杂度。
2.学习更长的历史窗口:通过增加lookback window L的长度,可以提高预测准确性。而patching操作可以在保持输入token数量不变的情况下,学习更长的历史窗口,进一步提高预测准确性。
3.自监督表示学习和迁移学习:PatchTST在自监督预训练和迁移学习任务中都取得了优异的性能,表明其学习到的表示具有很好的泛化能力。
本文挑选了10个基于Patch的时间序列预测最新成果,可借鉴的方法和创新点我做了简单介绍,原文以及相应代码都整理了,方便同学们学习。
论文和代码需要的同学看文末
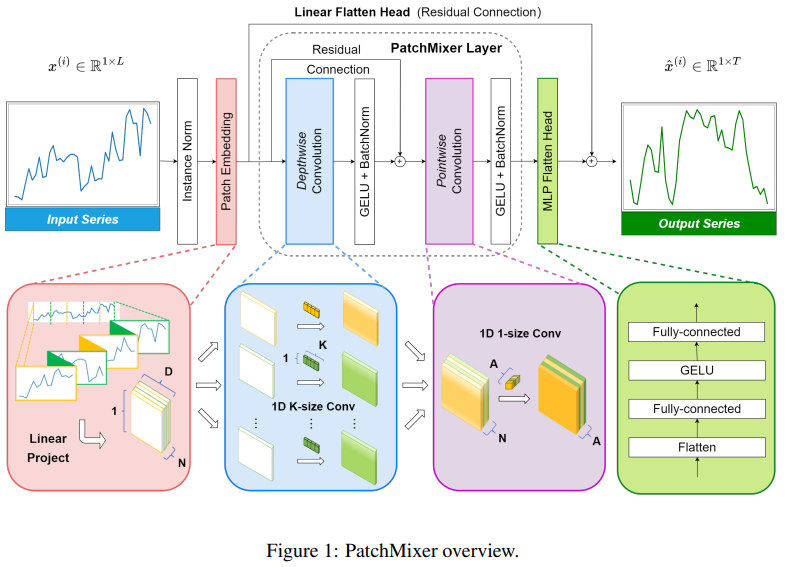
PatchMixer
PATCHMIXER: A PATCH-MIXING ARCHITECTURE FOR LONG-TERM TIME SERIES FORECASTING
方法:论文提出了一种基于卷积架构的新型模型PatchMixer。该模型通过创新的补丁混合设计,有效替代了Transformer中计算开销较大的自注意模块,以揭示时间序列中复杂的时间模式。
创新点:
-
PatchMixer:该模型是基于卷积结构构建的新型模型。它有效地替代了Transformers中计算开销较大的自注意力模块,并利用了一种新颖的补丁混合设计来揭示时间序列中复杂的时间模式。
-
深度可分离卷积:通过在PatchMixer中使用深度可分离卷积,取代PatchTST中的自注意机制,可以评估深度可分离卷积的有效性。深度可分离卷积和标准卷积分别使用一个层,并遵循相同的配置。
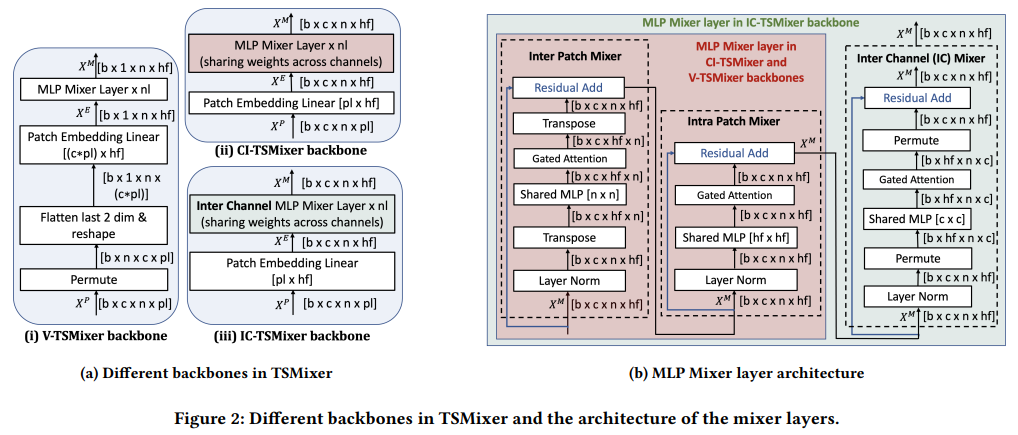
TSMixer
TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting
方法:论文提出了TSMixer,这是一个轻量级、高效的神经网络架构,专门设计用于多元预测和表示学习的纯MLP架构,经过实证验证的时间序列特定增强。作者引入了一种新的混合架构,通过增加各种调和头和门控注意力到独立于通道的主干,显著增强了简单的MLP结构的学习能力,超过了复杂的Transformer模型。
创新点:
-
引入了通道独立性(CI)的背骨结构代替通道扁平化,使CI-TSMixer在性能上超过了V-TSMixer,提升了9.5%。
-
进一步添加了门控注意力(G)和层次调和(H),即CI-TSMixer(G,H),使性能额外提升了2%,总体提升达到11.5%。
-
CI-TSMixer(G,H)在所有数据集上的平均性能优于V-TSMixer达到19.3%。
PITS
LEARNING TO EMBED TIME SERIES PATCHES INDEPENDENTLY
方法:本文提出了一种名为Patch Independence for Time Series (PITS)的方法,它利用非遮蔽的补丁重建作为补丁独立预训练任务,并采用多层感知机(MLP)作为补丁独立的架构。此外,作者引入了互补对比学习来有效地捕捉相邻时间序列信息,其中正样本由互补的随机遮蔽构成。
创新点:
-
作者引入了“Patch Independence for Time Series (PITS)”方法,该方法利用了未掩盖的补丁重构作为预训练任务,以及使用MLP作为补丁独立的架构。
-
作者引入了互补对比学习,以高效地捕捉相邻时间序列信息。通过使用原始样本的两个增强视图进行互补的随机遮盖,形成正样本对。

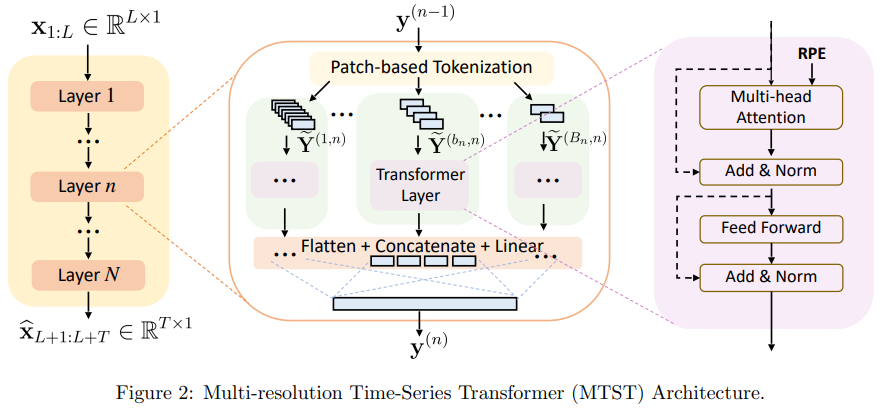
MTST
Multi-resolution Time-Series Transformer for Long-term Forecasting
方法:论文提出了一种新颖的框架,多分辨率时间序列变压器(MTST),它包括一个多分支架构,用于同时建模不同分辨率下的多样化时间模式。与许多现有的时间序列变压器相比,作者采用了相对位置编码,这更适用于提取不同尺度的周期性成分。
创新点:
-
引入了基于patch的时间序列转换器模型(MTST),将时间序列划分为patch,并使用注意力机制来建模patch内的时间模式和patch之间的关系。
-
使用相对位置编码(relative PE)来建模周期模式,相对于绝对位置编码(absolute PE),相对位置编码在时间序列中更能捕捉到重要的周期性模式。这种相对位置编码的设计在预测任务中能提供有用的归纳偏差。
-
在不同的回溯窗口下,MTST相对于其他模型(PatchTST和DLinear)表现出更好的性能,说明MTST在不同时间范围内仍然具有优势。
关注下方《学姐带你玩AI》

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

