
- 1使用模拟退火算法优化XGBoost超参数:如何高效地在Python中找到机器学习算法的最佳超参数组合_xgboost算法参数优化策略
- 2Android Studio加载项目时出现unsupported modules detected错误提示_compilation is not supported for following modules
- 3多租户实现之基于Mybatis,Mycat的共享数据库,共享数据架构
- 4Jenkins 配置插件中国境内镜像源-速度提升很大_sed -i 's/updates.jenkins-ci.org/download/mirrors.
- 5文件IO(IO编程)_文件io编程
- 6毕业设计:python新能源汽车推荐系统 协同过滤推荐算法 Echarts可视化 Django框架(源码)✅_汽车推荐系统数据库er图
- 7Python 基础面经(整理)_python面经
- 8git reset revert回退回滚取消提交返回上一版本_测试问题之前版本中有没有版本回滚
- 9强化学习算法的分类_强化学习模型 分类
- 10AndroidStudio使用程序员字体_android studio中java使用毛笔字体
Spark 系列教程(1)Word Count_案例一:词频分析word_count(spark 版)
赞
踩
基本概要
Spark 是一种快速、通用、可扩展的大数据分析引擎,是基于内存计算的大数据并行计算框架。Spark 在 2009 年诞生于加州大学伯克利分校 AMP 实验室,2010 年开源,2014 年 2月成为 Apache 顶级项目。
本文是 Spark 系列教程的第一篇,通过大数据中的 “Hello World” – Word Count 实验带领大家快速上手 Spark。Word Count 顾名思义就是对单词进行计数,我们首先会对文件中的单词做统计计数,然后输出出现次数最多的 3 个单词。
前提条件
本文中会使用 spark-shell 来演示 Word Count 示例的执行过程。spark-shell 是提交 Spark 作业众多方式中的一种,提供了交互式运行环境(REPL,Read-Evaluate-Print-Loop),在 spark-shell 上输入代码后就可以立即得到响应。spark-shell 在运行的时候,依赖于 Java 和 Scala 语言环境。因此,为了保证 spark-shell 的成功启动,需要在本地预装 Java 与 Scala。
本地安装 Spark
下载并解压安装包
从 Spark 官网 下载安装包,选择最新的预编译版本即可,然后将安装包解压到本地电脑的任意目录。

设置环境变量
为了在本地电脑的任意目录下都可以直接运行 Spark 相关的命令,我们需要设置一下环境变量。我本地的 Mac 电脑使用的是 zsh 作为终端 shell,编辑 ~/.zshrc 文件设置环境变量,如果是 bash 可以编辑 /etc/profile 文件。
export SPARK_HOME=/Users/chengzhiwei/software/spark/spark-3.1.2-bin-hadoop3.2
export PATH=$PATH:$SPARK_HOME/bin
- 1
- 2
加载环境变量:
source ~/.zshrc
- 1
在终端输入 spark-shelll --version 命令,如果显示以下内容,表示我们已经成功在本地安装好了 Spark。
❯ spark-shell --version
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10, OpenJDK 64-Bit Server VM, 1.8.0_302
Branch HEAD
Compiled by user centos on 2021-05-24T04:27:48Z
Revision de351e30a90dd988b133b3d00fa6218bfcaba8b8
Url https://github.com/apache/spark
Type --help for more information.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Spark 基本概念
在开始实验之前,先介绍 3 个 Spark 中的概念,分别是 spark、sparkContext 和 RDD。
- spark 和 sparkContext 分别是两种不同的开发入口实例:
- spark 是开发入口 SparkSession 实例(Instance),SparkSession 在 spark-shell 中会由系统自动创建;
- sparkContext 是开发入口 SparkContext 实例。在 Spark 版本演进的过程中,从 2.0 版本开始,SparkSession 取代了 SparkContext,成为统一的开发入口。本文中使用 sparkContext 进行开发。
- RDD 的全称是 Resilient Distributed Dataset,意思是“弹性分布式数据集”。RDD 是 Spark 对于分布式数据的统一抽象,它定义了一系列分布式数据的基本属性与处理方法。
实现 Word Count
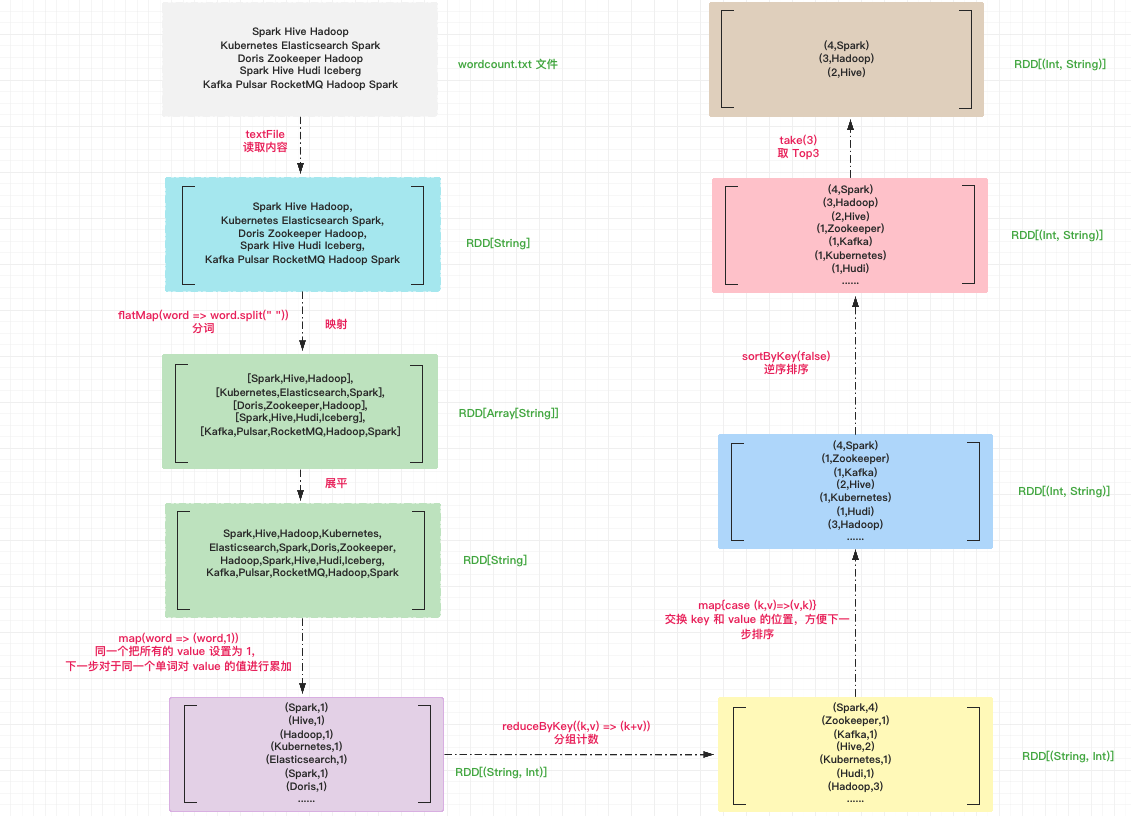
Word Count 的整体执行过程示意图如下,接下来按照读取内容、分词、分组计数、排序、取 Top3 出现次数的单词这 5 个步骤对文件中的单词进行处理。
准备文件
/Users/chengzhiwei/tmp/wordcount.txt 文件中写入以下内容:
Spark Hive Hadoop
Kubernetes Elasticsearch Spark
Doris Zookeeper Hadoop
Spark Hive Hudi Iceberg
Kafka Pulsar RocketMQ Hadoop Spark
- 1
- 2
- 3
- 4
- 5
第 1 步:读取文件
首先,我们调用 SparkContext 的 textFile 方法,读取源文件,生成 RDD[String] 类型的 RDD,文件中的每一行是数组中的一个元素。
//导包
import org.apache.spark.rdd.RDD
// 文件路径
val file: String = "/Users/chengzhiwei/tmp/wordcount.txt"
// 读取文件内容
val lineRDD: RDD[String] = spark.sparkContext.textFile(file)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

第 2 步:分词
“分词”就是把“数组”的行元素打散为单词。要实现这一点,我们可以调用 RDD 的 flatMap 方法来完成。flatMap 操作在逻辑上可以分成两个步骤:映射和展平。
// 以行为单位做分词
val wordRDD: RDD[String] = lineRDD.flatMap(line => line.split(" "))
- 1
- 2
首先使用空格作为分隔符,将 lineRDD 中的行元素转换为单词,分割之后,每个行元素就都变成了单词数组,元素类型也从 String 变成了 Array[String],像这样以元素为单位进行转换的操作,统一称作“映射”。
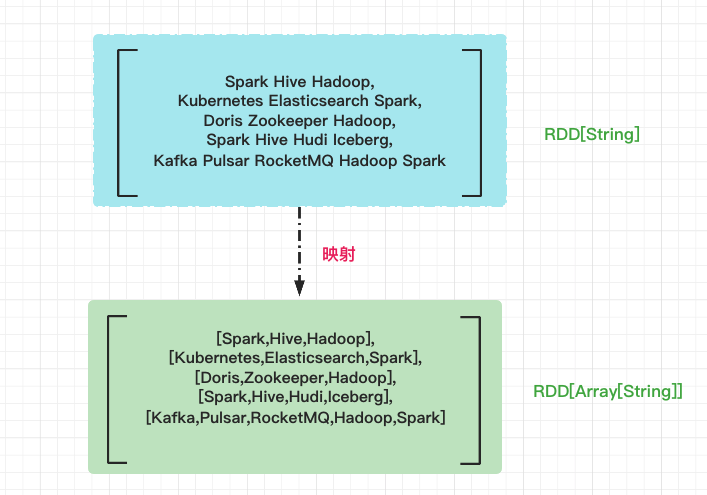
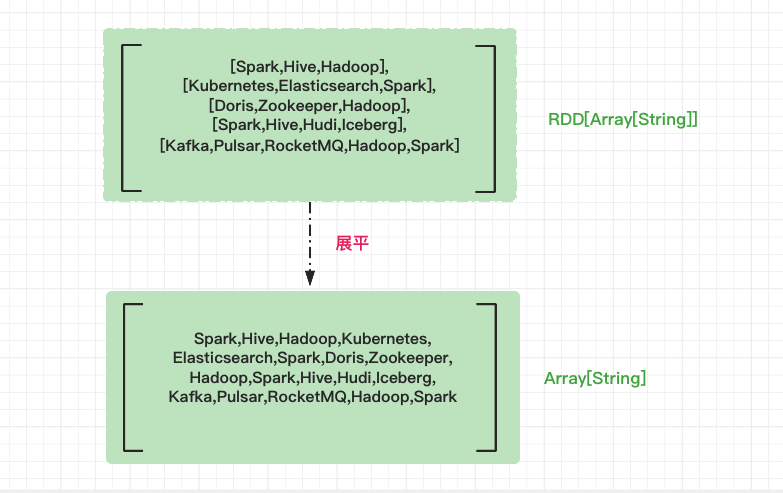
映射过后,RDD 类型由原来的 RDD[String]变为 RDD[Array[String]]。如果把 RDD[String]看成是“数组”的话,那么 RDD[Array[String]]就是一个“二维数组”,它的每一个元素都是单词。接下来我们需要对这个“二维数组”做展平,也就是去掉内层的嵌套结构,把“二维数组”还原成“一维数组”。
第 3 步:分组计数
在 RDD 的开发框架下,聚合类操作,如计数、求和、求均值,需要依赖键值对(key value pair)类型的数据元素。因此,在调用聚合算子做分组计数之前,我们要先把 RDD 元素转换为(key,value)的形式,也就是把 RDD[String] 映射成 RDD[(String, Int)]。
使用 map 方法将 word 映射成 (word,1) 的形式,所有的 value 的值都设置为 1,对于同一个的单词,在后续的计数运算中,我们只要对 value 做累加即可。
// 把RDD元素转换为(Key,Value)的形式
val kvRDD: RDD[(String, Int)] = wordRDD.map(word => (word, 1))
- 1
- 2
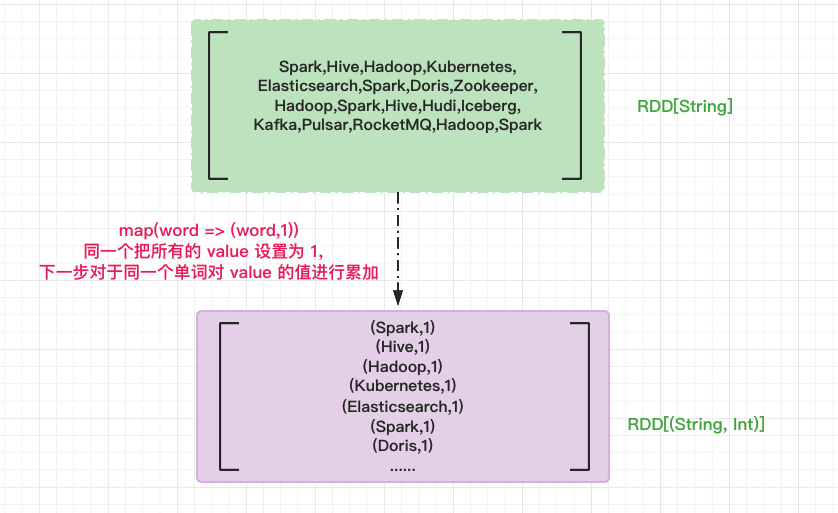
完成了形式的转换之后,我们就该正式做分组计数了。分组计数其实是两个步骤,也就是先“分组”,再“计数”。我们使用聚合算子 reduceByKey 来同时完成分组和计数这两个操作。对于 kvRDD 这个键值对“数组”,reduceByKey 先是按照 Key(也就是单词)来做分组,分组之后,每个单词都有一个与之对应的 value 列表。然后根据用户提供的聚合函数,对同一个 key 的所有 value 做 reduce 运算,这里就是对 value 进行累加。
// 按照单词做分组计数
val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y)
- 1
- 2

第 4 步:排序
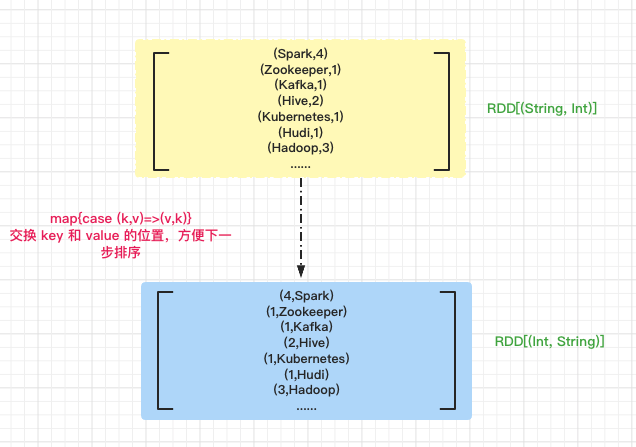
现在得到的 wordCounts RDD 中 key 是单词,value 是这个单词出现的次数,我们最终要取 Top3 出现次数的单词,首先要根据单词出现的次数进行逆序排序。
先交换 wordCounts RDD 中的 key 和 value 中的位置,方便下一步排序。
// 交换 key 和 value 的位置
val exchangeRDD: RDD[(Int, String)] = wordCounts.map{case (k,v)=>(v,k)}
- 1
- 2
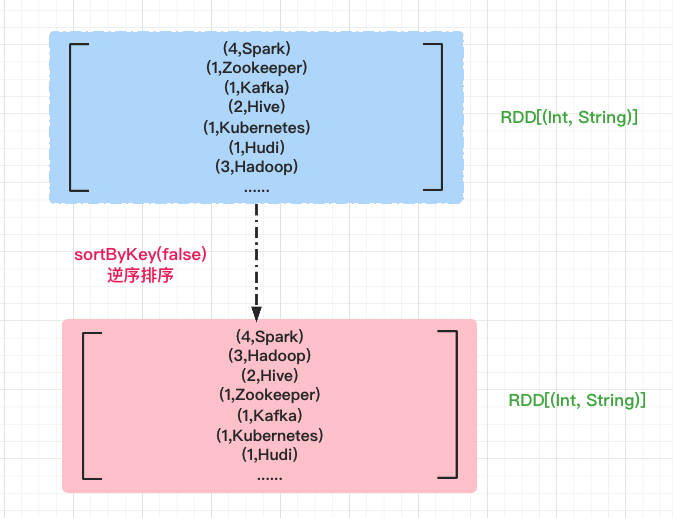
根据单词出现的次数逆序排序,false 表示逆序排序。
// 根据单词出现的次数逆序排序
val sortRDD: RDD[(Int, String)] = exchangeRDD.sortByKey(false)
- 1
- 2
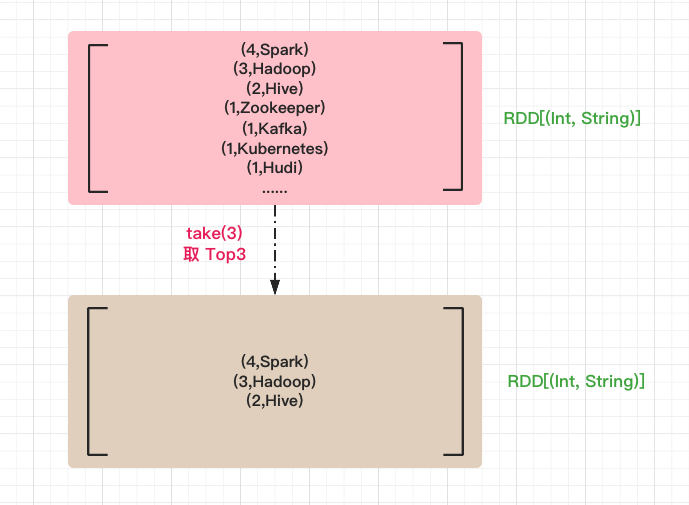
第 5 步:取 Top3 出现次数的单词
使用 take 方法获取排序后数组中前 3 个元素。
// 取 Top3 出现次数的单词
sortRDD.take(3)
- 1
- 2
完整代码
将以下代码在 spark-shell 中执行:
//导包 import org.apache.spark.rdd.RDD //第 1 步:读取文件 // 文件路径 val file: String = "/Users/chengzhiwei/tmp/wordcount.txt" // 读取文件内容 val lineRDD: RDD[String] = spark.sparkContext.textFile(file) //第 2 步:分词 // 以行为单位做分词 val wordRDD: RDD[String] = lineRDD.flatMap(line => line.split(" ")) // 第 3 步:分组计数 // 把RDD元素转换为(Key,Value)的形式 val kvRDD: RDD[(String, Int)] = wordRDD.map(word => (word, 1)) // 按照单词做分组计数 val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y) //第 4 步:排序 // 交换 key 和 value 的位置 val exchangeRDD: RDD[(Int, String)] = wordCounts.map{case (k,v)=>(v,k)} // 根据单词出现的次数逆序排序 val sortRDD: RDD[(Int, String)] = exchangeRDD.sortByKey(false) // 第 5 步:取 Top3 出现次数的单词 sortRDD.take(3)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
输出结果如下,可以看到 Top3 出现次数的单词分别是 Spark,Hadoop,Hive。到此为止,我们成功实现了 Word Count 的功能。
Array[(Int, String)] = Array((4,Spark), (3,Hadoop), (2,Hive))
- 1
简化写法
上面实现 Word Count 的代码看起来稍稍有些复杂,我们可以使用链式调用的写法将上面的代码简化成一行代码,通过 . 的方式调用 RDD 中的方法,返回结果是新的 RDD,可以继续用 . 调用新 RDD 中的方法。
//读取文件
//sc 表示 sparkContext 实例
sc.textFile("/Users/chengzhiwei/tmp/wordcount.txt").
//根据空格分词
flatMap(line => line.split(" ")).
//分组,统一把 value 设置为 1
map(word => (word,1)).
//对相同 key 的 value 进行累加
reduceByKey((k,v) => (k+v)).
//把(key,value)对调,目的是按照计数来排序,(Spark,4) => (4,Spark)
map{case (k,v)=>(v,k)}.
//降序排序
sortByKey(false).
//取前 3
take(3)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
Scala 语言为了让函数字面量更加精简,还可以使用下划线 _ 作为占位符,用来表示一个或多个参数。我们用来表示的参数必须满足只在函数字面量中出现一次。因此上面的写法可以进一步简化为以下代码:
//读取文件
sc.textFile("/Users/chengzhiwei/tmp/wordcount.txt").
//根据空格分词
flatMap(_.split(" ")).
//分组,统一把 value 设置为 1
map((_,1)).
//对相同 key 的 value 进行累加
reduceByKey(_+_).
//把(key,value)对调,目的是按照计数来排序,(Spark,4) => (4,Spark)
map{case (k,v)=>(v,k)}.
//降序排序
sortByKey(false).
//取前 3
take(3)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
欢迎关注


