
- 1搜索引擎ElasticSearch详解_搜索引擎els
- 2浅谈Vue中的bus事件总线注意事项_vue $bus传参是不是很卡
- 3火狐强制阅读模式_火狐只读模式
- 4【重大更新】DevExpress v16.2新版亮点(WPF篇)_devexpress.v16.2
- 5ubuntu16.04上onlyoffice环境搭建以及常见错误_onlyoffice 上传xls文件失败
- 6安全基础~攻防特性3(1),内含福利
- 7计算机网络:IP 与 IP 地址_源ip地址在传输过程中会改变吗?
- 8uniapp安卓本地打包成apk_uniapp 生成本地apk
- 9JDK下载应该选择哪个版本?教你选择最好的JDK版本_java version "9.0.1"应该用哪个版本的jdk
- 10Java+SSM+Vue培训机构运营系统源码+论文
深度学习500问——Chapter08:目标检测(3)
赞
踩
文章目录
8.2.7 DetNet
DetNet是发表在ECCV2018的论文,出发点是现有的检测任务backbone都是从分类任务衍生而来的,因此作者想针对检测专用的backbone做一些讨论和研究而设计了DetNet,思路比较新奇。
1. Introduction
很多backbone的提出都是用于挑战ImageNet分类任务后被应用到检测上来,而鲜有单独针对检测任务设计的backbone。
检测和分类有明显的区别:
(1)不仅需要分类,还需要精确的定位。
(2)最近的检测器都是基于类似FPN结构的,在分类网络基础上加额外多尺度特征进行检测,应对不同尺度变化的目标。这两点又是互相补充,,共同协助网络完成分类到检测任务的转变。例如分类任务是检测的一环所以必不可少,但是传统分类采用的最高级特征定位细节不够,因此很多最近网络设法用类似FPN的结构去处理尺度变化的问题,就将分类较好地过渡到检测任务上了。
2. DetNet
2.1 Motivation
主要着眼点是分辨率,从大目标和小目标分布阐述保持分辨率的重要性。所以DetNet也是从分辨率的保持着手,解决多尺度物体的识别问题。
Weak visibility of large objects
网络在较深层如P6(FPN)和P7(RetinaNet)大目标的边界不明确使精确定位困难。
Invisibility of small objects
小目标就很惨了,将采样容易丢。这个就不赘述了,所以只要避开降采样就能防止目标丢失,但是这种方法又会导致抽象能力不够
2.2 DetNet Design
保持分辨率有两个麻烦的问题:
(1)内存消耗大,计算大。
(2)降采样减少导致高层的抽象特征不足以很好地进行分类任务。下面设计时会同时考虑时间和高层抽象信息两点。
先放出DetNet的多尺度各stage的尺寸如下图,可以看到,相比前两种方式,DetNet在P4之后就不再进一步降采样了,进行分辨率的保持。
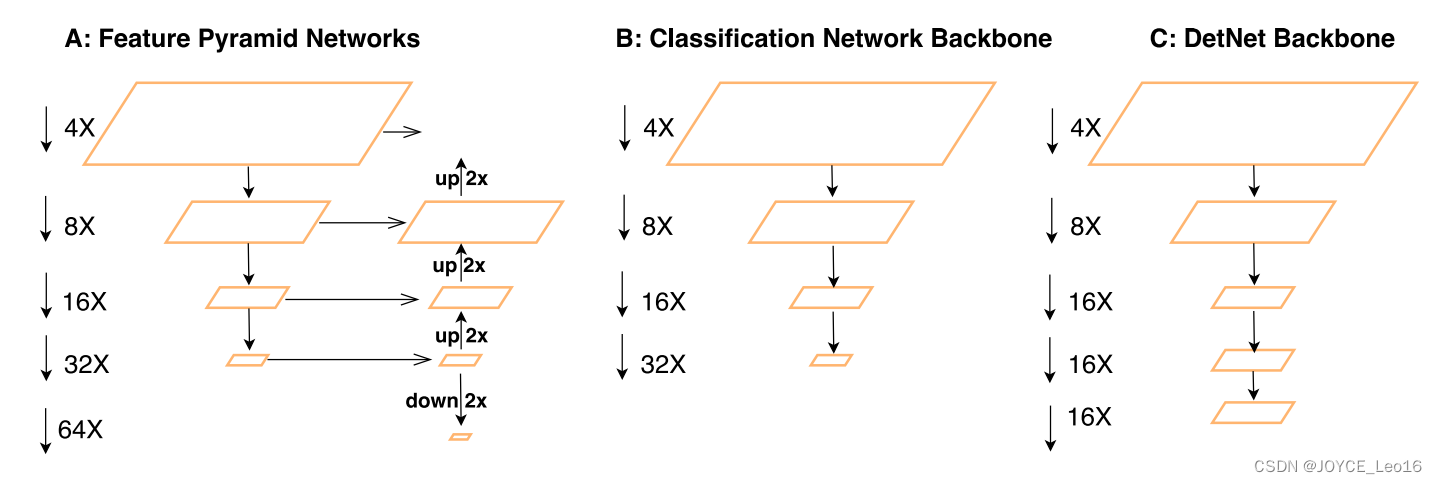
实现细节如下图:
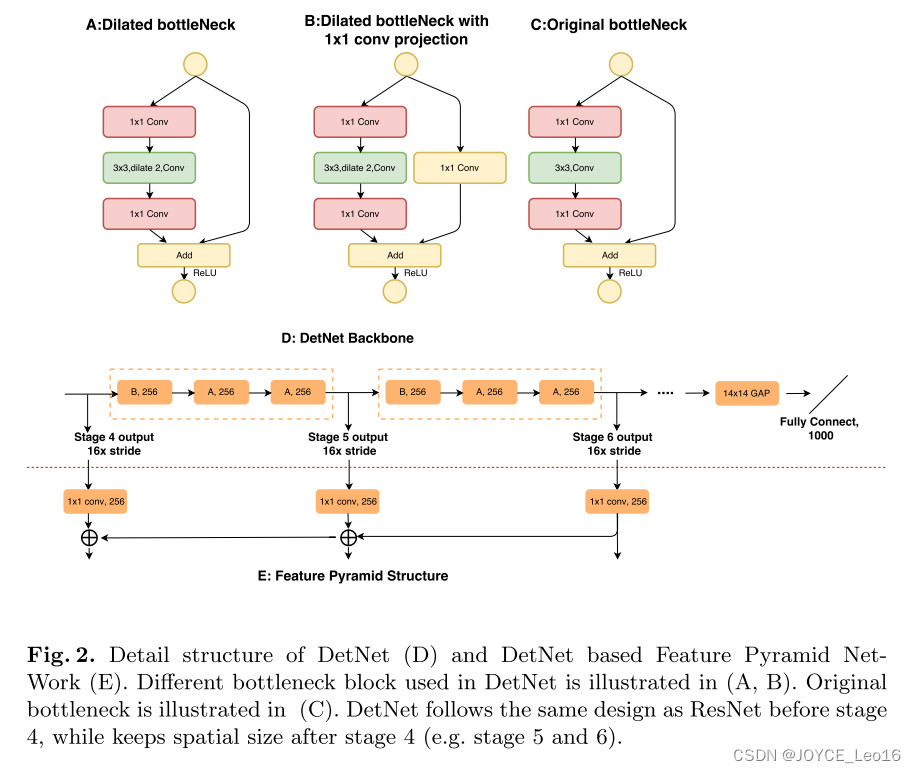
- 采样的backbone是ResNet-50,改进设计了DetNet-59。
- 对bottleneck进行了改进,传统的其实不止C,也包含两种,即将AB的膨胀卷积换成普通卷积。AB是新的基础模块。
- 为了减少分辨率保持带来的时间和内存成本消耗,通道数固定为256(思考:降采样和膨胀卷积都会有信息丢失,这里可以想想)。
- DetNet也可以加FPN结构,方法类似。
3. Experiments
检测和训练的细节配置就不看了。
3.1 Main Results
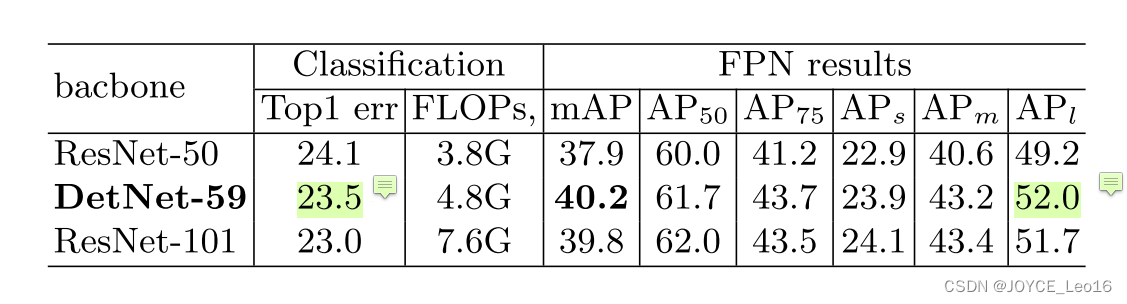
- 在FPN基础上明显有大物体涨点,同时由于高分辨率,小物体也有不错的提升。
- 膨胀卷积提高的大感受野使得分类也不逊色。

3.2 Result analysis
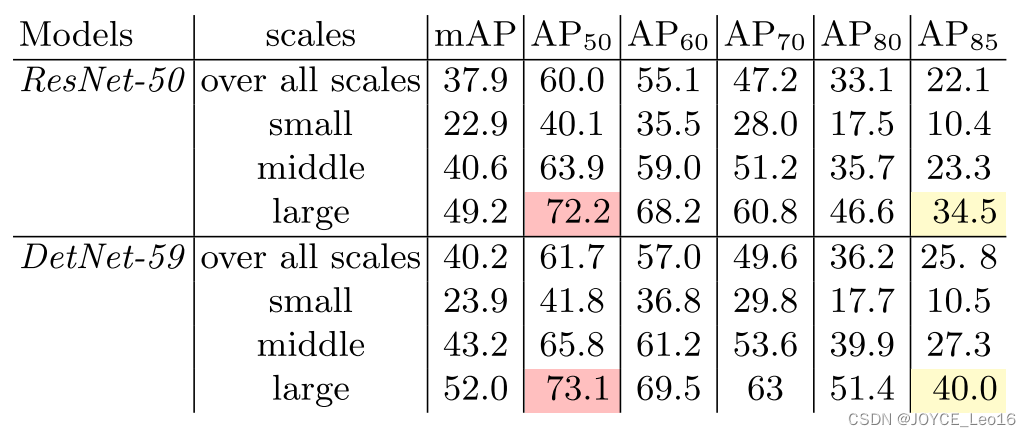
从AP50看出,高了1.7;从AP80看出,高了3.7.由此可以看出确实提高了检测性能。
从定位性能来看,大物体的提升比小物体更多。作者认为是高分辨率解决了大物体边界模糊的问题。其实有一种解释:小目标没有大目标明显,因为膨胀卷积核降采样都会丢失小目标,只是膨胀卷积可能离散采样不至于像降采样直接给到后面没了,但是没有根本性的解决,所以小目标不大。
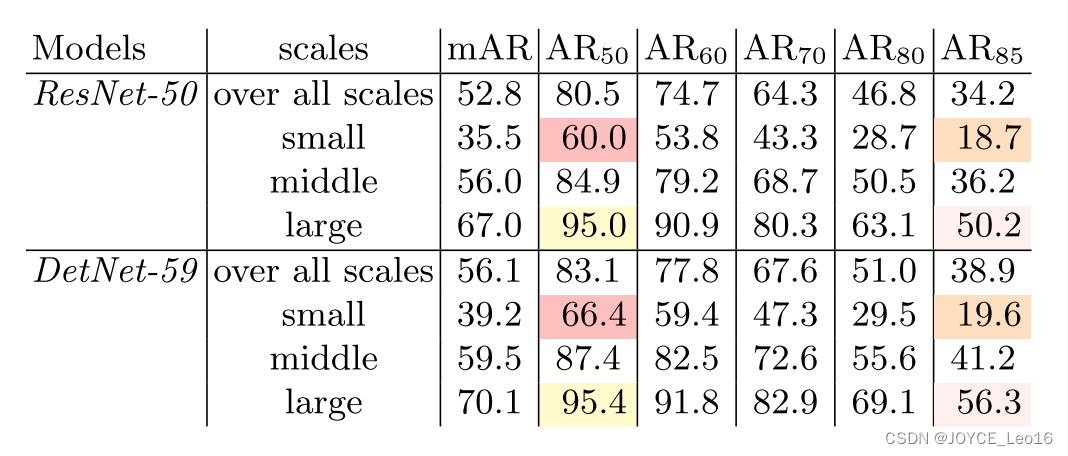
- AR指标也有类似结论。
- AR50体现了小目标的查全率更好,这也印证了上面分析的:相对降采样,膨胀卷积丢失会好点。此大目标效果虽然提升不大但是也很高了,作者表示DetNet擅长找到更精确的定位目标,在AR85的高指标就能看出。
- AR85看大目标丢失少,说明能够像VGG一样对大目标效果优良。关于小目标的效果平平,作者认为没有必要太高,因为FPN结构对小目标已经利用地很充分了,这里即使不高也没事。
3.3 Discussion
- 关于stage
为了研究backbone对检测的影响,首先研究stage的作用。前4个还好说,和ResNet一样,但是P5、P6就不同,没有尺度的变化,和传统意义的stage不一样了,需要重新定义。这里DetNet也是类似ResNet的方法,虽然没有尺度变化,但是AB模块的位置还是保持了,B开启一个stage。如下图,认为新加的仍属于P5。
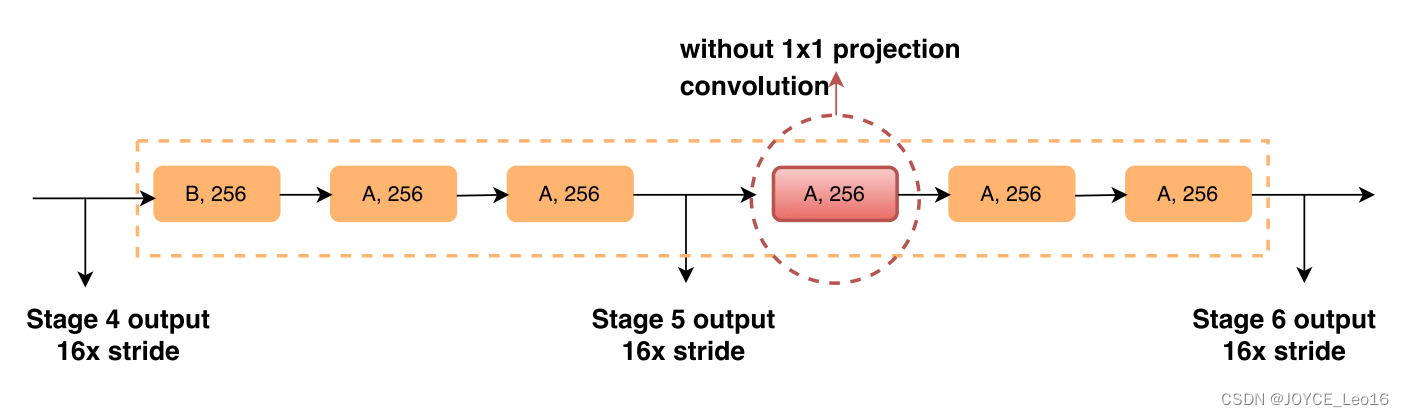
验证方法是做了实验,将P6开始的block换成上图所示的A模块对比效果如下图。发现还是加了B效果更好。(但是这个stage和传统意义很不一样,所以很多性质不能相提并论,只是B模块的改变也不好判定什么)。

8.2.8 CBNet
本部分介绍一篇在COCO数据集达到最高单模型性能——mAP 53.3的网络,论文于2019.9.3发布在ArXiv,全名是CbNet:A Novel Composite Backbone Network Architecture for Object Detection。
1. Introduction
名义是单模型,实际上是多模型的特征融合,只是和真正的多模型策略略有不同。作者的起点是,设计新的模型往往需要在ImageNet上进行预训练,比较麻烦。因而提出的Composite Backbone Network(CBNet),采用经典网络的多重组合的方式构建网络,一方面可以提取到更有效的特征,另一方面也能够直接用现成的预训练参数(如ResNet、ResNeXt等)比较简单高效。
2. Proposed method
2.1 Architecture of CBNet
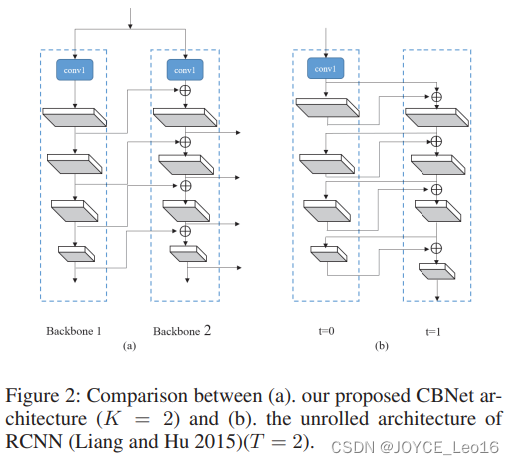
如上图,模型中采用K个(K>1)相同的结构进行紧密联结。其中两个相同backbone的叫Dual-Backbone (DB),三个叫Triple- Backbone (TB);L代表backbone的stage数目,这里统一设置为L=5。其中,和前任工作不同的地方在于,这里将不同的stage信息进行复用回传,以便获取更好的特征(为什么work不好说)。
2.2 Other possible composite styles
相关工作的其他类似结构,大同小异。要么是前面backbone的stage往后传播,要么是往前一个传播,每个都有一篇论文,应该都会给出不同的解释;第四个结构不太一样,是类似densnet的结构,但是密集连接+多backbone assemble的内存消耗不出意外会非常大。但是脱离这些体系来看,多backbone的结构类似多模型的assemble,和单模型有点不公平。
3. Experiment
- result
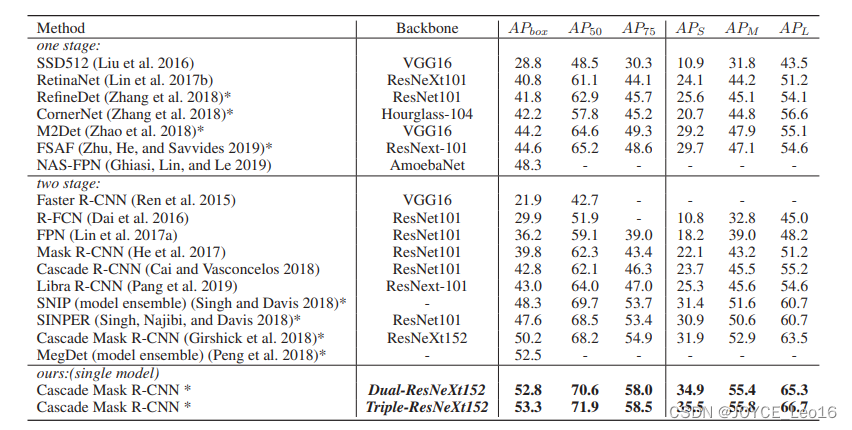
COCO数据集上的结果,看来提升还是有的。但是也能看出,大趋势上,三阶级联效果不如两阶的提升大,也是这部分的特征提升空间有限的缘故,到底哪部分在work不好说。下图的研究就更说明这一点了,斜率逐渐减小。
- Comparisons of different composite styles
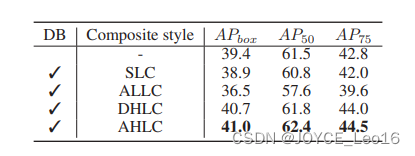
与其他的级联网络相比,作者的阐述点只落脚于特征的利用情况,但是这个东西本身就很玄乎,不好说到底怎么算利用得好。硬要说这种做法的解释性,大概就是将backbone方向的后面高级语义特征传播回前面进行加强,相当于横向的FPN传播。
- Number of backbones in CBNet
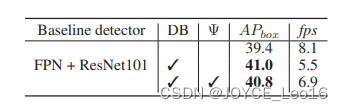
速度慢是必然的,FPN+ResNeXt为8fps,加上两个backboen后为5.5FPS;如果减去backbone的前两个stage,可以节省部分参数达到6.9FPS,而精度下降不大(整体速度太低,这个实验意义不大)。
- Sharing weights for CBNet
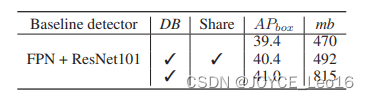
从中可以看出其实权重是否share区别不大, 不到一个点的降幅,参数量减少。
- Effectiveness of basic feature enhancement by CBNet
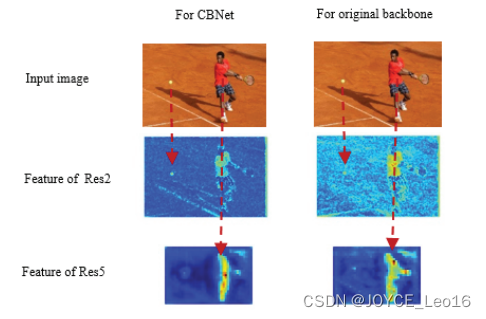
从中可以看出激活响应效果更好,确实是能够提取到更为有效的特征,对物体的响应更加敏感。

