- 1【数据交换格式】网络socket编程温度采集智能存储与上报项目技术------JSON、TLV
- 2【YOLOv8模型网络结构图理解】_yolov8主干网络中的20*20*512*w*r分别代表什么
- 3tortoiseGit使用报错gitlab ssh Please make sure you have the correct access rights and the repos_unencrypted http is not supported for gitlab
- 4hive建表语法,内部表与外部表_create external table if not exists
- 5【附源码】计算机毕业设计JAVA药品管理系统_基于java web的药品管理系统(源码+数据库)
- 6ROS机器人Diego 1#制作(四)base controller---线速度的标定_机器人本体base标定
- 7使用TortoiseGit, 从远程仓库克隆一个项目以及提交,创建分支,合并分支等基本操作_tortoisegit要先克隆项目再创建分支吗
- 8Ubuntu搭建DHCP 和ipv6
- 9事业单位计算机管理职位B,事业单位a类b类c类什么意思
- 10Linux知识点(十四)---监控网络状态_linux 网络ip分配完成 网络状态监听
【赵渝强老师】Kafka的消息持久化_kafka消息持久化详解
赞
踩

1、Kafka消息持久性概述
Kakfa依赖文件系统来存储和缓存消息。对于硬盘的传统观念是硬盘总是很慢,基于文件系统的架构能否提供优异的性能?实际上硬盘的快慢完全取决于使用方式。同时 Kafka 基于 JVM 内存有以下缺点:
-
对象的内存开销非常高,通常是要存储的数据的两倍甚至更高
-
随着堆内数据的增加,GC的速度越来越慢
实际上磁盘线性写入的性能远远大于任意位置写的性能,线性读写由操作系统进行了大量优化(read-ahead、write-behind 等技术),甚至比随机的内存读写更快。所以与常见的数据缓存在内存中然后刷到硬盘的设计不同,Kafka 直接将数据写到了文件系统的日志中:
-
写操作:将数据顺序追加到文件中
-
读操作:从文件中读取
这样实现的好处:
-
读操作不会阻塞写操作和其他操作,数据大小不对性能产生影响
-
硬盘空间相对于内存空间容量限制更小
-
线性访问磁盘,速度快,可以保存更长的时间,更稳定
2、Kafka的持久化原理解析
一个Topic 被分成多 Partition,每个 Partition 在存储层面是一个 append-only 日志文件,属于一个 Partition 的消息都会被直接追加到日志文件的尾部,每条消息在文件中的位置称为 offset(偏移量)。

如下图所示,我们之前创建了mytopic1,具有三个分区。我们可以到对应的日志目录下进行查看。
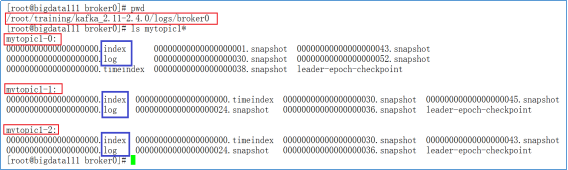
Kafka日志分为index与log(如上图所示),两个成对出现:index文件存储元数据,log存储消息。索引文件元数据指向对应log文件中message的迁移地址;例如2,128指log文件的第2条数据,偏移地址为128;而物理地址(在index文件中指定)+ 偏移地址可以定位到消息。
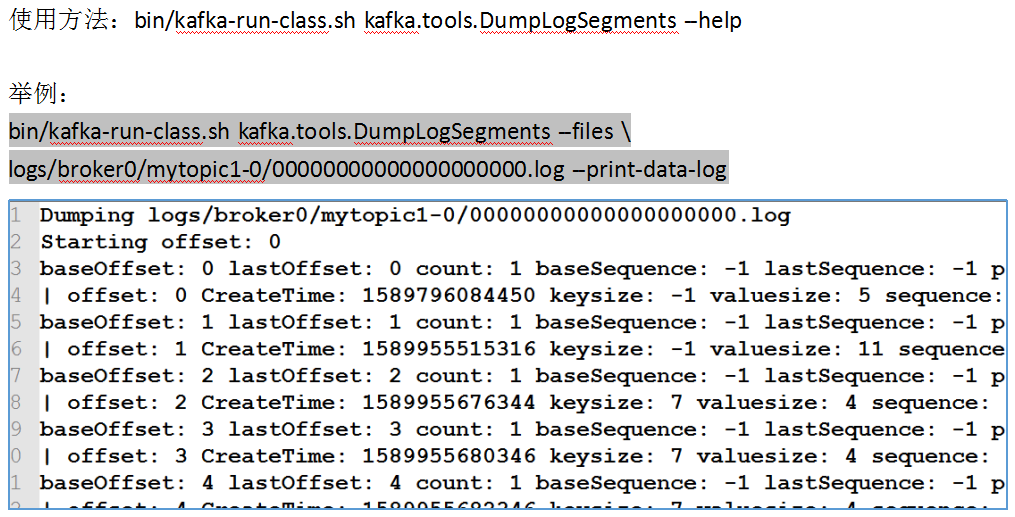
我们可以使用Kafka自带的工具来查看log日志文件中的数据信息: