
- 1二维费用背包问题_二维费用的背包问题
- 2JS数组方法总结shift()、unshift()、pop()、push()、concat()、splice()、filter()、map()、some()、every()、forEach()等方法_javascript shift删除完数据会显示null吗
- 3git基本命令行操作_git 命令行操作
- 4【关联规则数据挖掘】Python实现FP_Growth和apriori算法遇到的各种问题及源码_has no attribute 'issubset
- 5【正点原子Linux连载】二十八章 Linux I2C驱动实验 摘自【正点原子】ATK-DLRK3568嵌入式Linux驱动开发指南
- 6GIt详解
- 7Big-Data-Resources_意大利rosacaraciolo
- 8【云原生】使用PyCharm上传代码到Gitlab仓库并在Jenkins构建_pycharm 如何上傳代碼到gitlab
- 9开源模型应用落地-chatglm3-6b模型小试-入门篇(三)_windows安装chatglm3
- 10智能汽车竞赛摄像头处理(5)——摄像头基本循迹的代码实现:找赛道边线和赛道中线_智能车摄像头寻迹法
【折腾笔记】Windows系统运行ChatGLM3-6B模型实验_windows glm3-6b
赞
踩
【折腾笔记】Windows系统运行ChatGLM3-6B模型实验
准备工作
硬件环境
软件环境
操作系统版本:Windows 10 企业版 22H2
显卡驱动程序:Game Ready
显卡驱动版本:551.61
Python版本:3.10.11
CUDA版本:12.3
软件下载
CUDA:https://developer.nvidia.com/cuda-downloads?target_os=Windows
CHatGLM3-6B:https://modelscope.cn/models/ZhipuAI/chatglm3-6b/files
推理实验
通过一些问题来了解ChatGLM3的推理水平及逻辑运算能力,实验时,均采用一次询问。
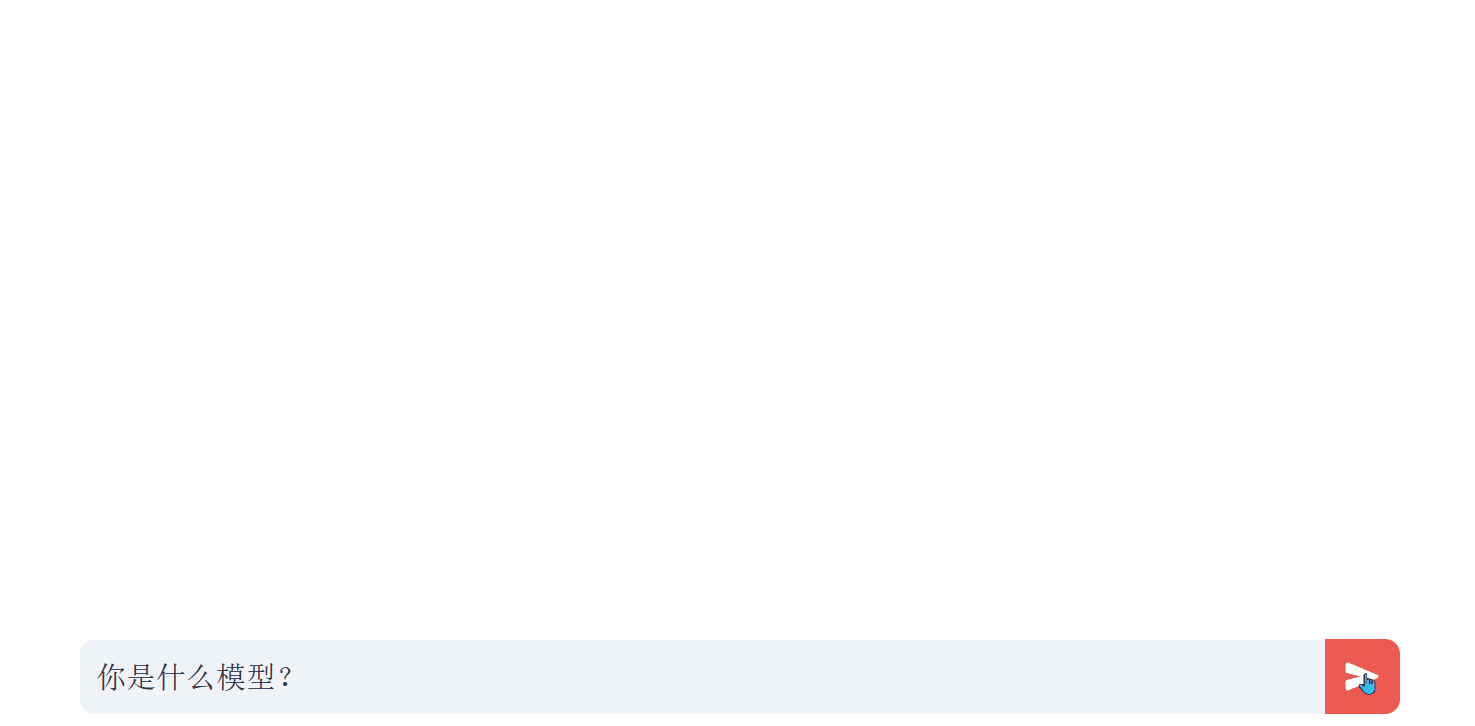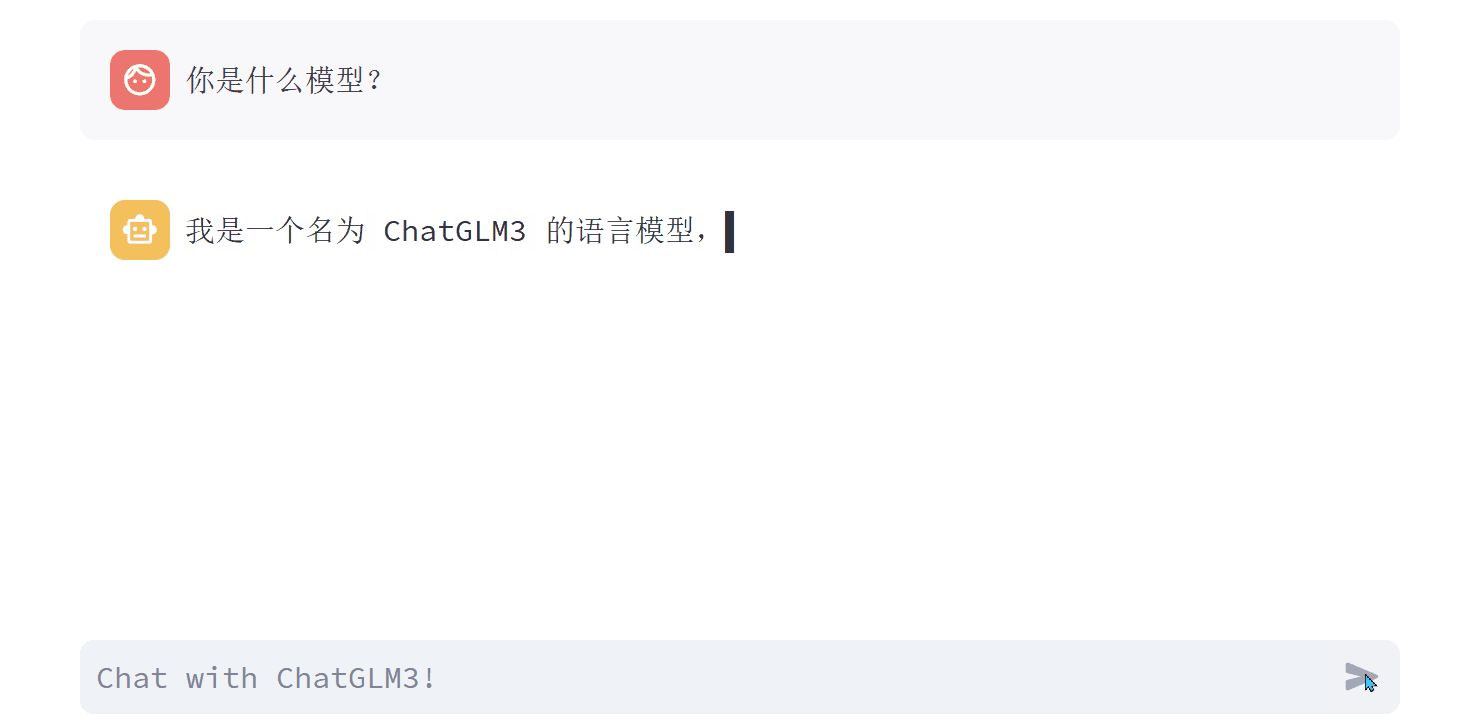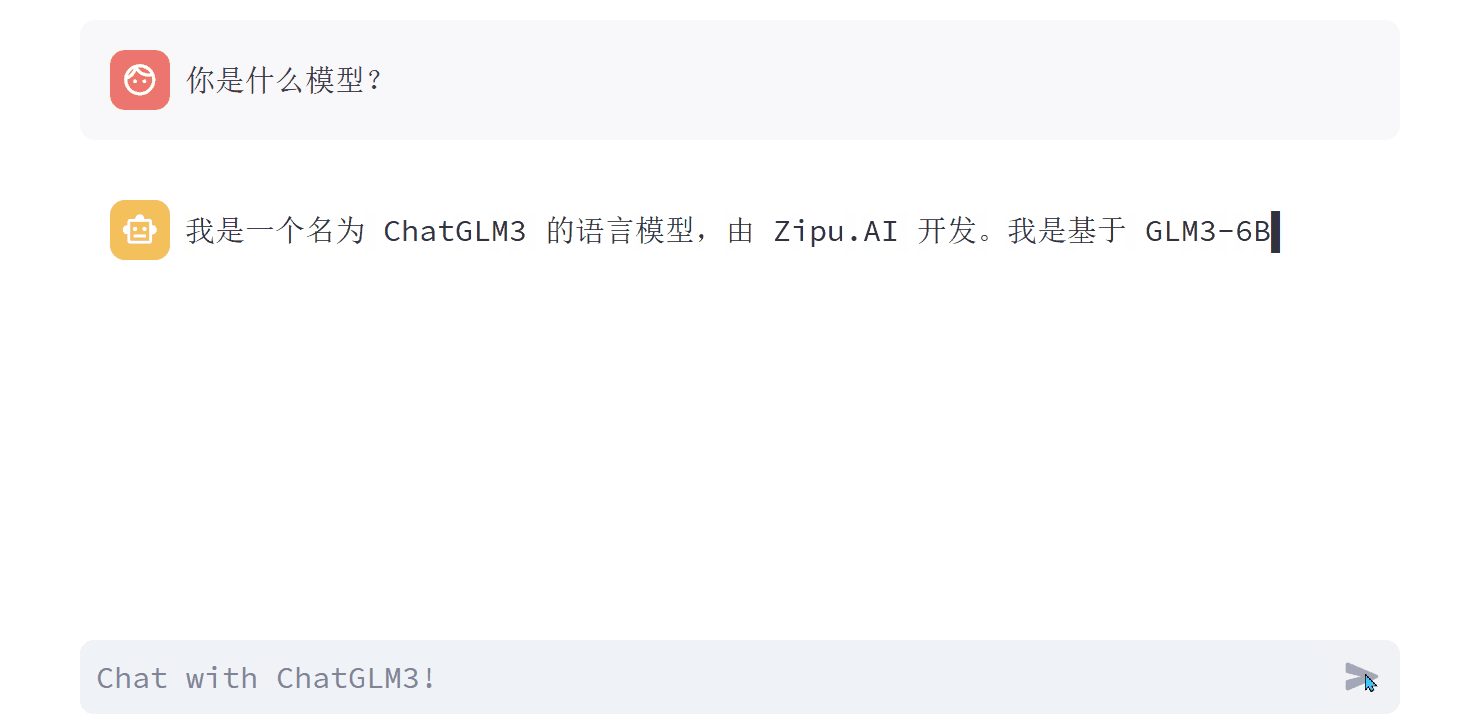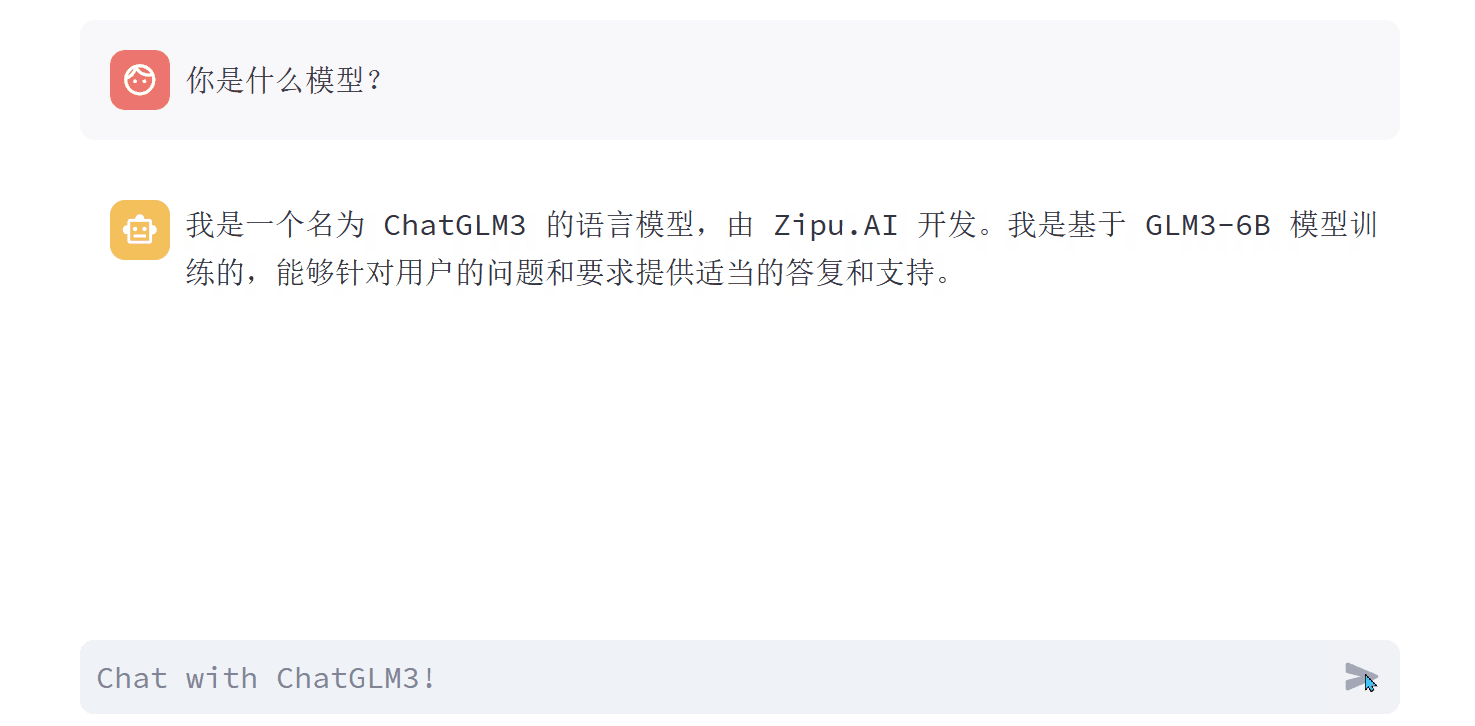
Q1:你是什么模型?
A1:我是一个名为 ChatGLM3 的语言模型,由 Zipu.AI 开发。我是基于 GLM3-6B 模型训练的,能够针对用户的问题和要求提供适当的答复和支持。
Q2:鲁迅和周树人是什么关系?
A2:鲁迅和周树人是同一人。鲁迅是周树人的笔名,鲁迅是中国现代文学的奠基人之一,他通过鲁迅的作品,倡导了民主与科学的思想,并对照明了封建社会的黑暗面。

Q3:树上有10只鸟,飞走了5只,然后又飞来了3只,请问树上还剩几只鸟?
A3:上面描述的情况可以用数学方法来解决。当有10只鸟在树上时,如果飞走了5只,那么树上剩下的鸟的数量为:
10−5=5
因此,树上剩下5只鸟。但是问题中还有另外的信息,即后来又飞来了3只鸟。所以最终的答案是:
5+3=8因此,树上现在还剩下8只鸟。

Q4:夏天能穿多少穿多少,冬天能穿多少穿多少
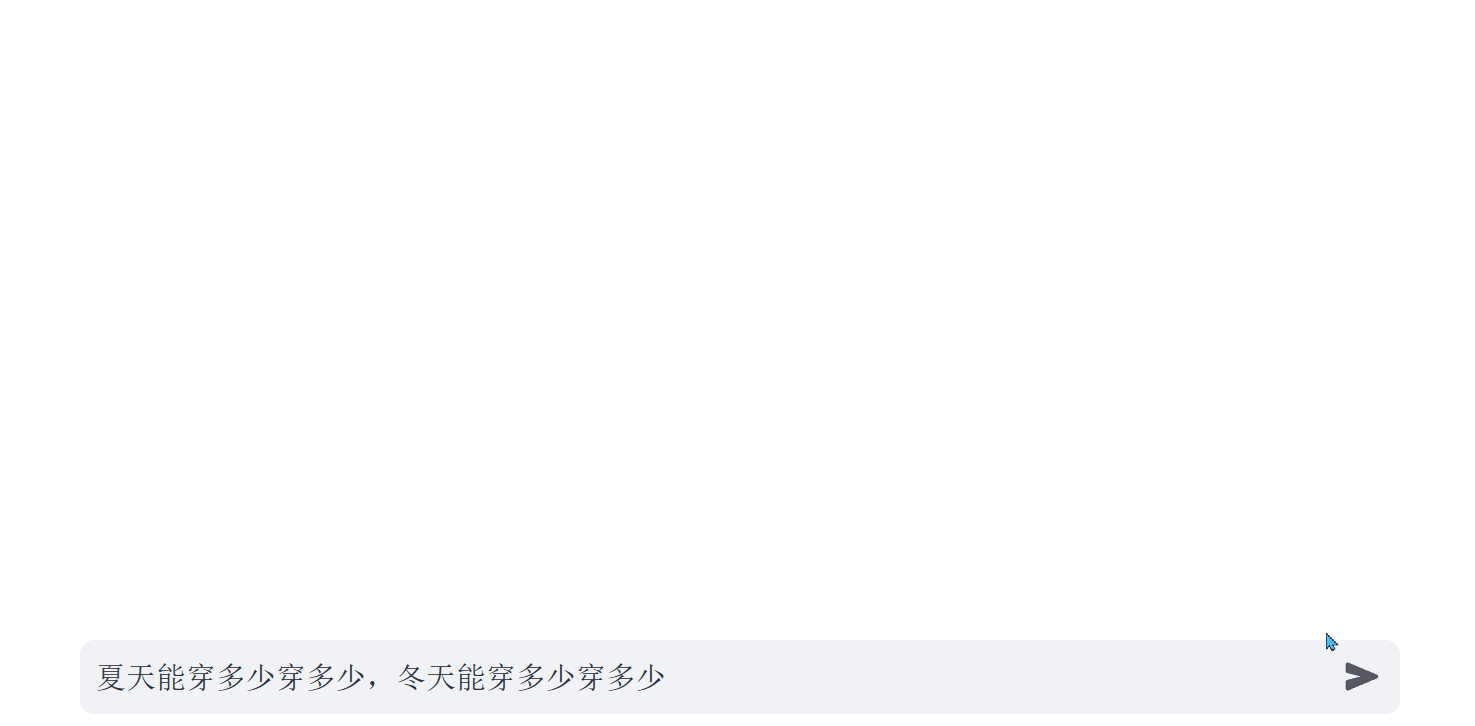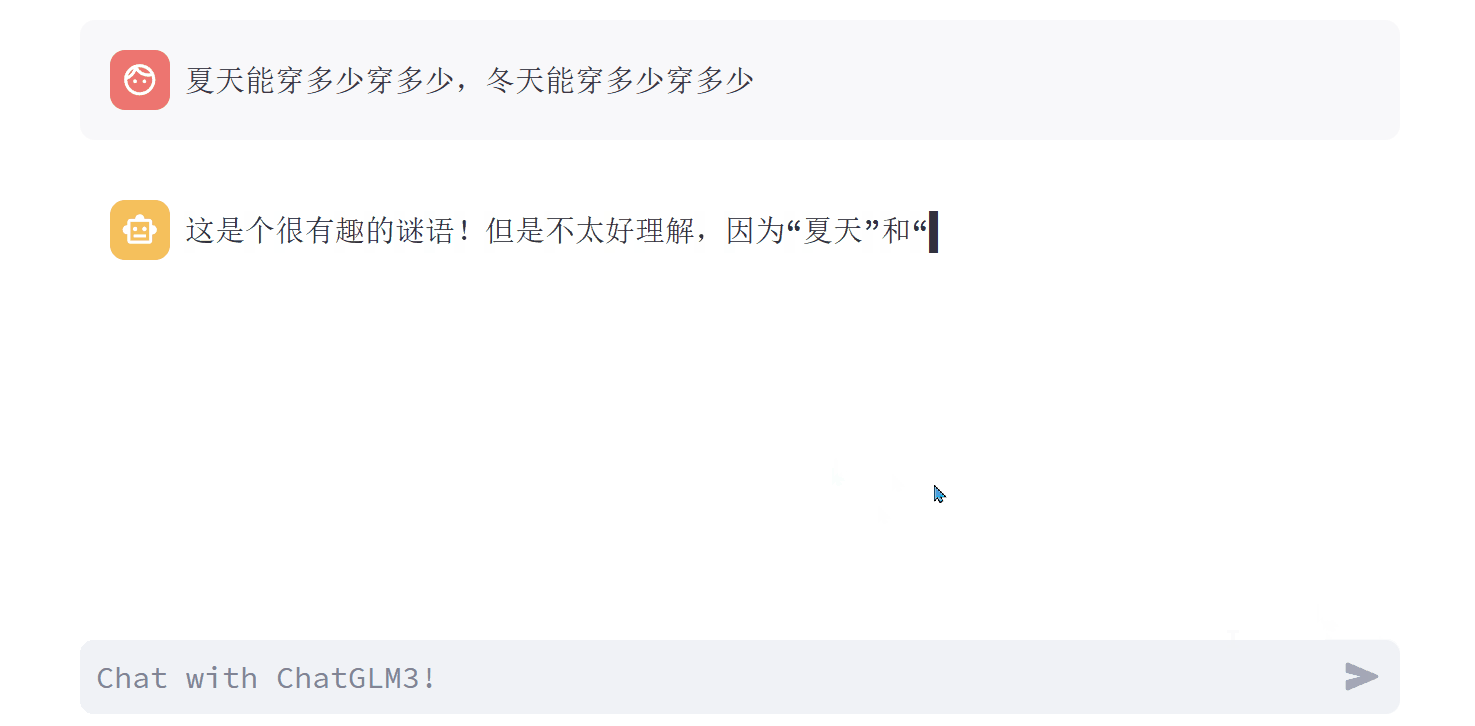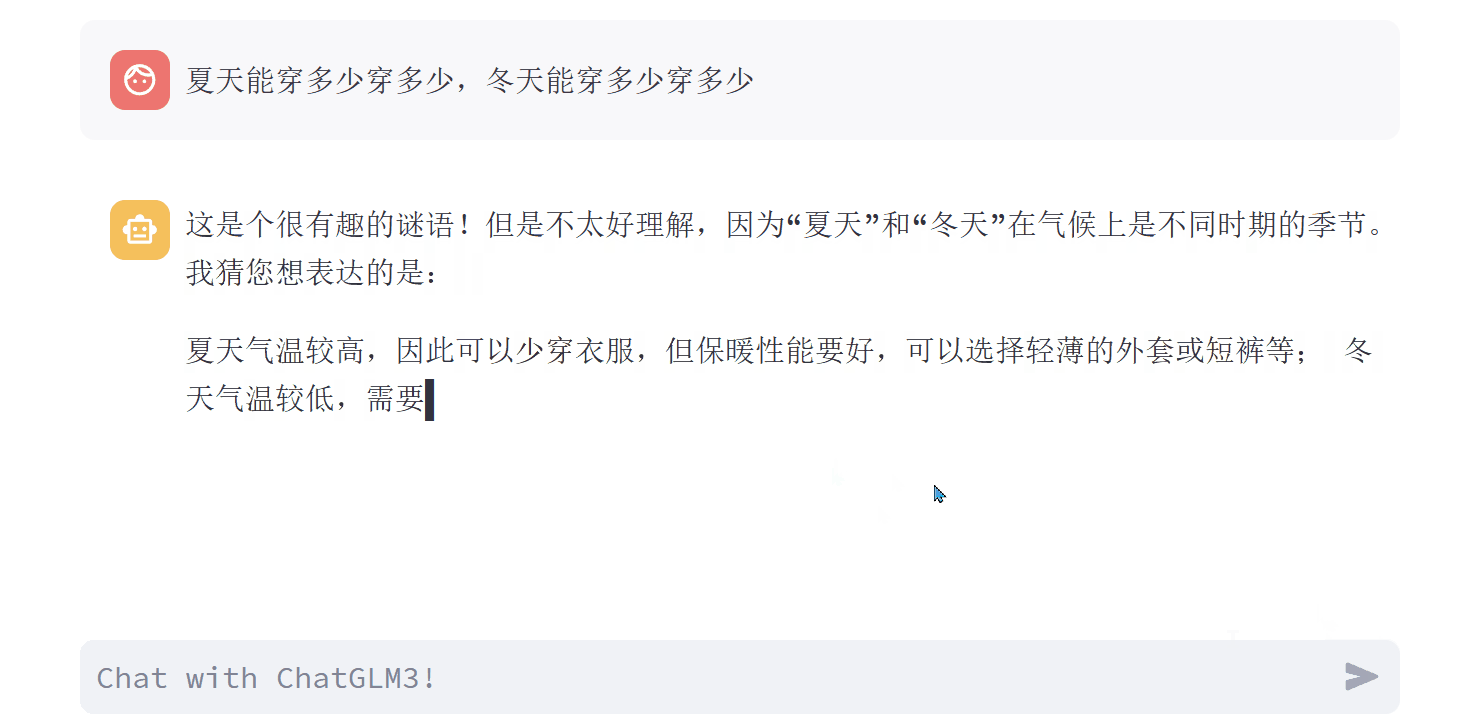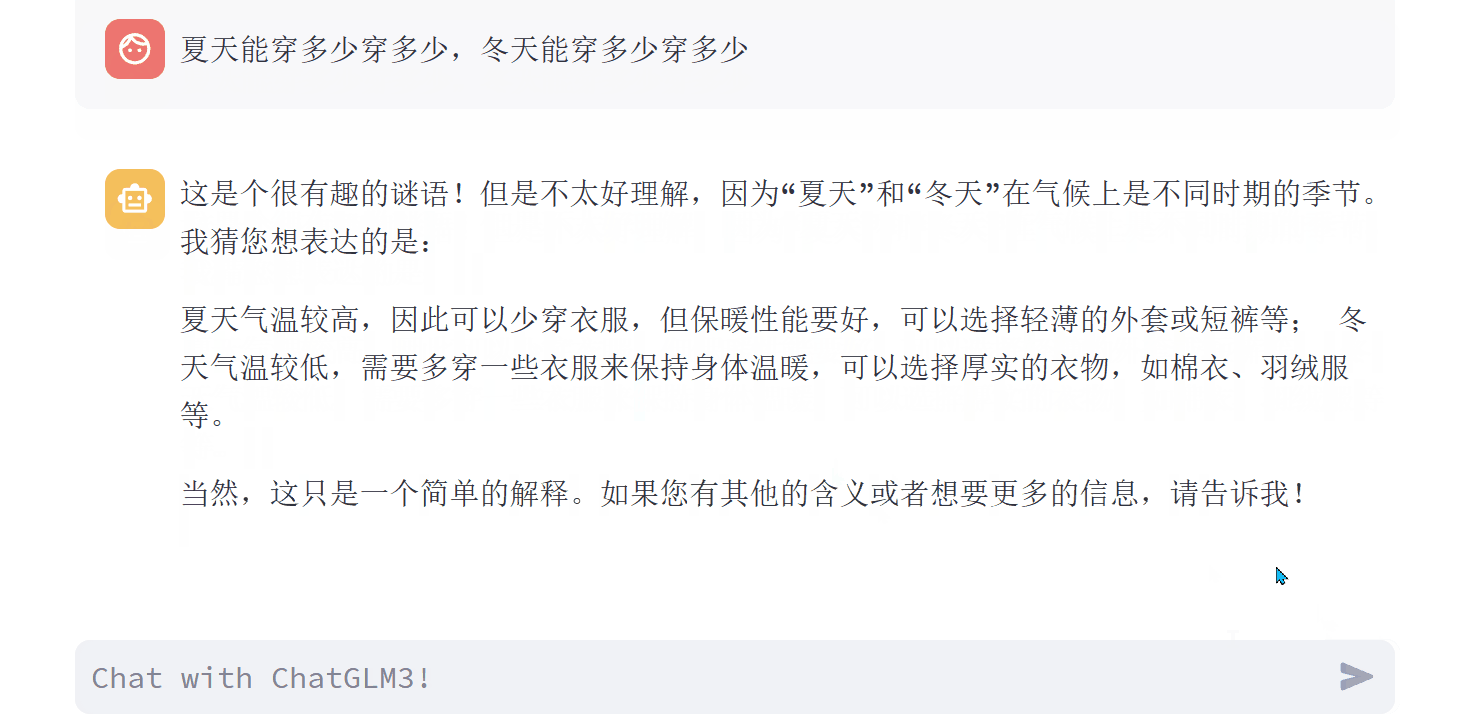
A4:这是个很有趣的谜语!但是不太好理解,因为“夏天”和“冬天”在气候上是不同时期的季节。我猜您想表达的是:
夏天气温较高,因此可以少穿衣服,但保暖性能要好,可以选择轻薄的外套或短裤等; 冬天气温较低,需要多穿一些衣服来保持身体温暖,可以选择厚实的衣物,如棉衣、羽绒服等。
当然,这只是一个简单的解释。如果您有其他的含义或者想要更多的信息,请告诉我!
Q5:你有一桶果冻,其中有黄色、绿色、红色三种,闭上眼睛抓取同种颜色的两个。抓取多少个就可以确定你肯定有两个同一颜色的果冻?
A5:我们可以通过数学方法来解决这个问题。假设这三种颜色的果冻分别为 A、B 和 C。首先,我们随机地抓取一个果冻,它可能是任何一种颜色。然后我们将它放回,再抓取第二个果冻。有以下几种情况:
抓到两个相同颜色的果冻。此时,已经确定了存在至少两个相同颜色的果冻,不需要再抓取其他果冻。
抓到一个不同颜色的果冻和一个相同颜色的果冻。这时,我们需要再抓取一个果冻来确认是否一定有两个相同颜色的果冻。
因此,为了确保我们可以确定至少有 two 个相同颜色的果冻,我们需要抓取至少 3 个果冻。

Q6:两根绳子粗细不均匀,燃烧时间均为1个小时,燃烧速度不均匀,现给你一个打火机,如何准确度量15分钟时?
A6:要精确地测量15分钟的时间,我们可以通过让这两根绳子分别燃烧来做到这一点。下面是一种方法:
首先,拿着一根绳子并在火焰上点燃它的一端。
当绳子开始烧着的时候,立刻将另一根绳子的两端放在火焰中,使其也燃烧。
当其中一根绳子燃烧完的时候,正是另一根绳子燃烧了15分钟。
因为两根绳子在同一时间内被燃烧,所以当在其中一根绳子燃烧完的时候,另一根绳子正好燃烧了15分钟。
需要注意的是,这种方法需要对火焰进行观察,以确保两边的时间保持一致。同时,要确保在操作过程中不要让自己或其他人接触到火焰或烟雾,以免发生危险。

实验结果
成功加载ChatGLM3-6B模型,由于实验机器只有8G显存,使用的是INT4量化等级进行运行的,加载模型时显存占用4G左右、内存占用2G左右,推理时GPU中的CUDA核心使用率为98%左右,运行速度流畅。
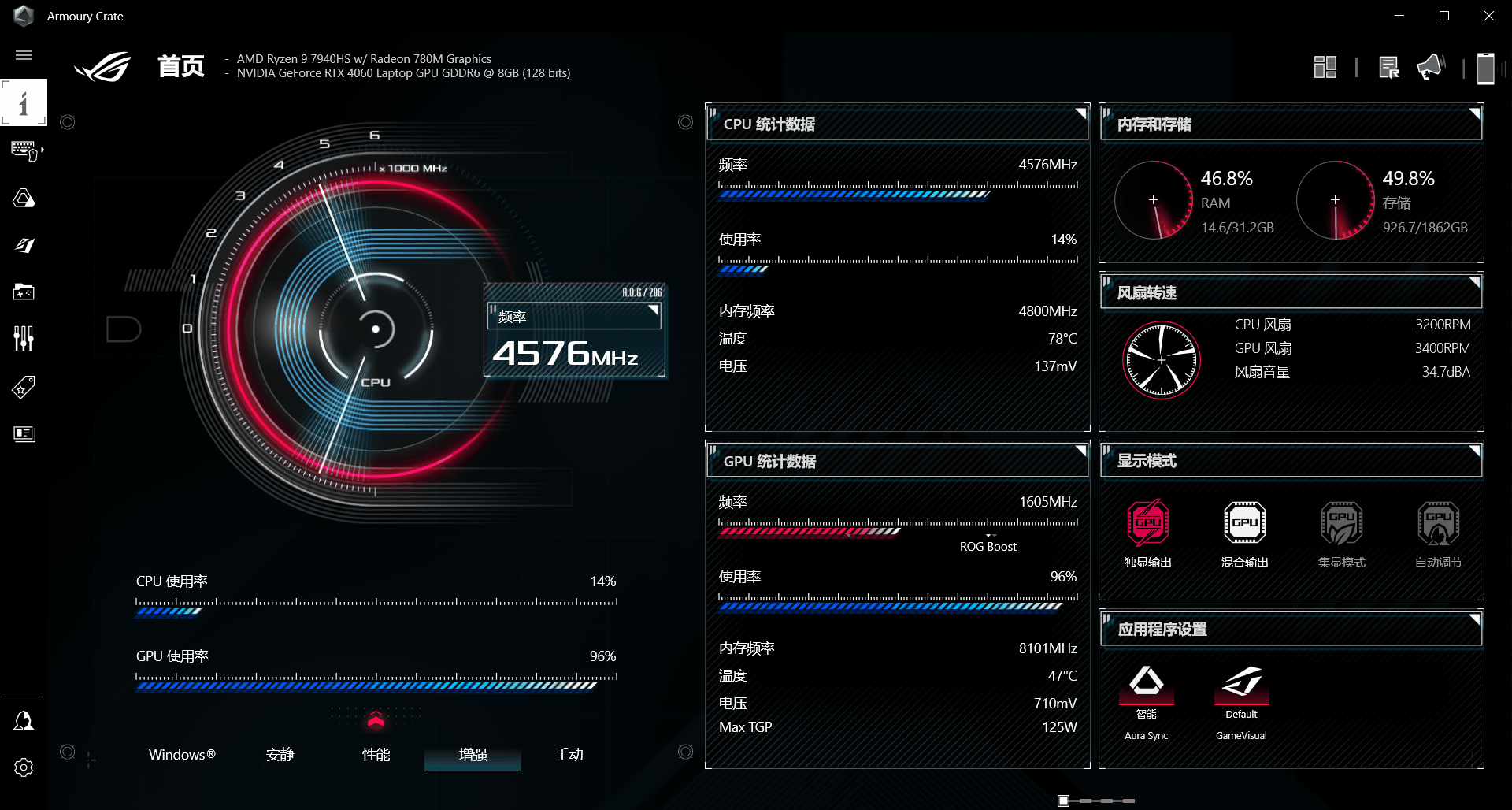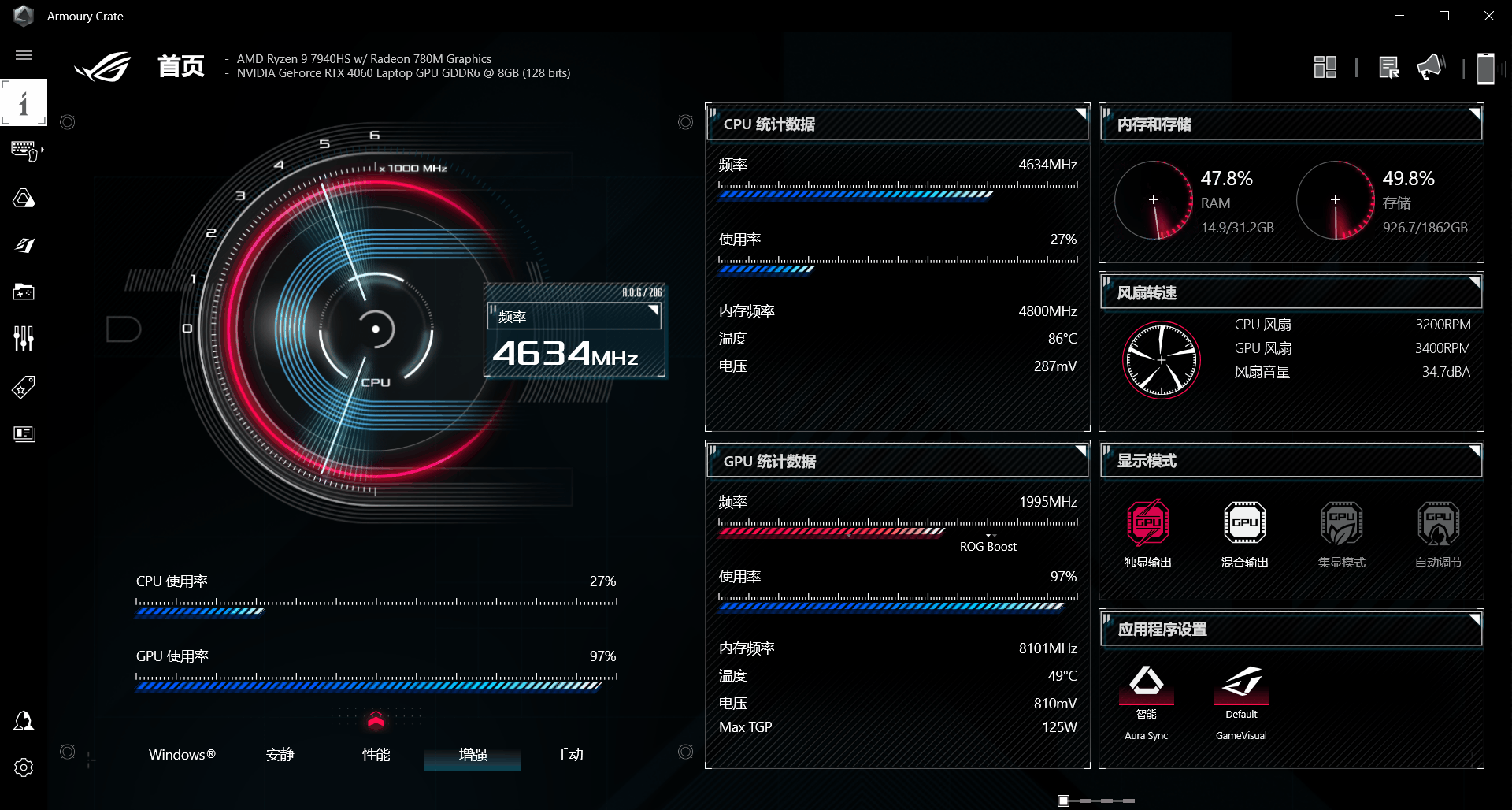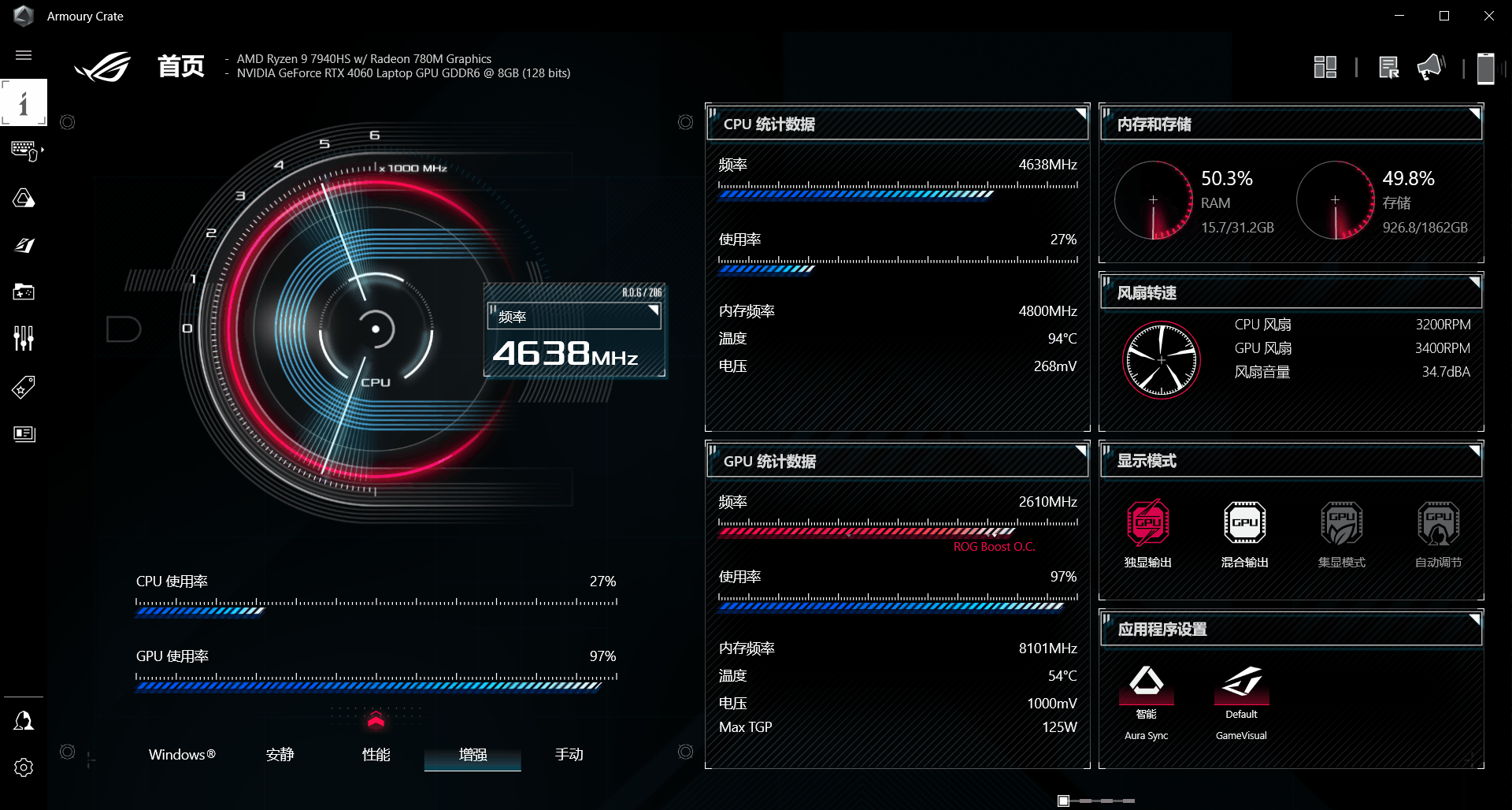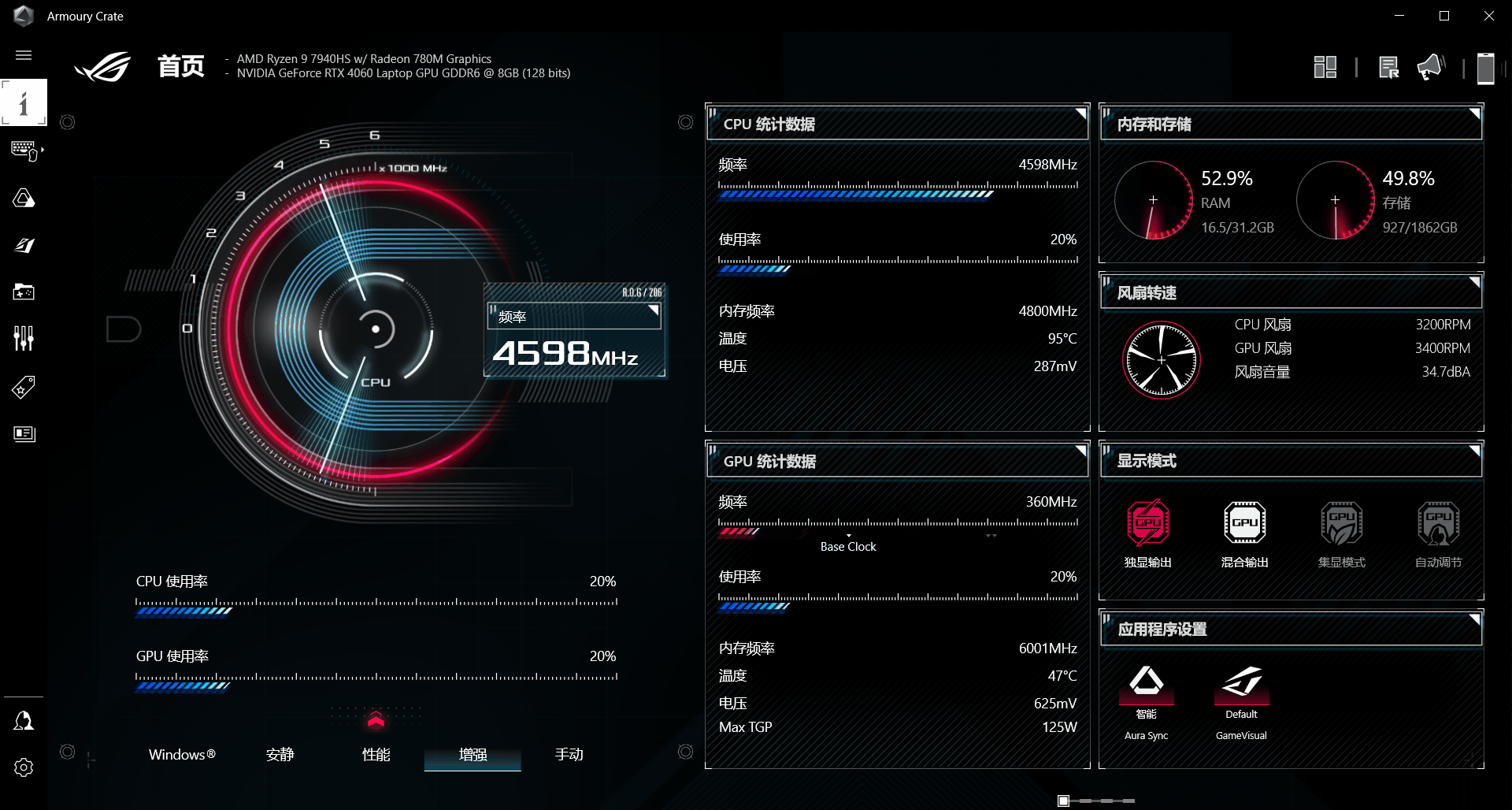
在连续对话中,运行速度流畅。

同时打开多个对话进行推理,开三个以上对话进行推理,流畅度明显降低。

复杂问题推理时偶尔会出现中英混合输出的情况。

由于实验机器显存太小,不足以全量运行ChatGLM3-6B模型,所以无法对不同量化等级的推理精度作比较。
硬件选型
要流畅运行拥有6B参数的ChatGLM3模型,以下是一些建议的最低配置要求。
操作系统:Windows 10/11。Windows 64位版本更为适合运行大型模型。
处理器:不需要特定的CPU型号,但强大的多核心处理器会提供更好的运行效率。
内存:最低8GB,推荐16GB以上,以获得更流畅的体验。
显卡:
对于需要GPU加速的情况,NVIDIA RTX 4090等高端显卡能提供优秀的性能。此类显卡配合至少13GB的显存可以轻松应对模型的需求。
ChatGLM3-6B支持在小于6GB显存的显卡上运行,尽管可能会有性能损失。这意味着即便是中端显卡,只要进行适当的模型量化,也有可能运行该模型。
对于不依赖GPU的场景,模型也能在仅有CPU的系统上运行,虽然性能和响应速度可能会有所下降。
文章出处:https://blog.uptoz.cn/archives/ooEhtRag
作者原创:@小小笔记大大用处 https://blog.uptoz.cn


