
- 1Code Review 工具_code review工具
- 2HTTP网络协议,接口请求的内容类型 content-type(2024-04-27)
- 3Oracle-客户端连接报错ORA-12545问题
- 4用机器学习实现情感分析_基于机器学习的情感分析
- 5仿真流程专题----随机振动分析_随机振动仿真分析
- 6哈希表&位图&topk&一致性哈希算法_布隆过滤器 topk
- 7Hadoop实战——MapReduce实现主播的播放量等数据的统计及TopN排序(第二篇)_mapreduce项目实战案例
- 8YOLOv5训练和推理_yolov5推理
- 9移动安全Android逆向系列:Dalvik概念&破解实例_dalvikvm
- 10linux 离线安装rabbitMQ Erlang_离线安装erlang
微软来大招:手机部署堪比GPT3.5高性能大模型!_phi-3支持中文吗
赞
踩
上周 LLaMa3 算是把关注度拉爆了,这才过了几天,微软已经宣布自己的 Phi-3-mini (3.8B) 模型可以媲美 Mixtral 8x7B 和 GPT-3.5 的性能了。
▲图1. Twitter:@haouarin
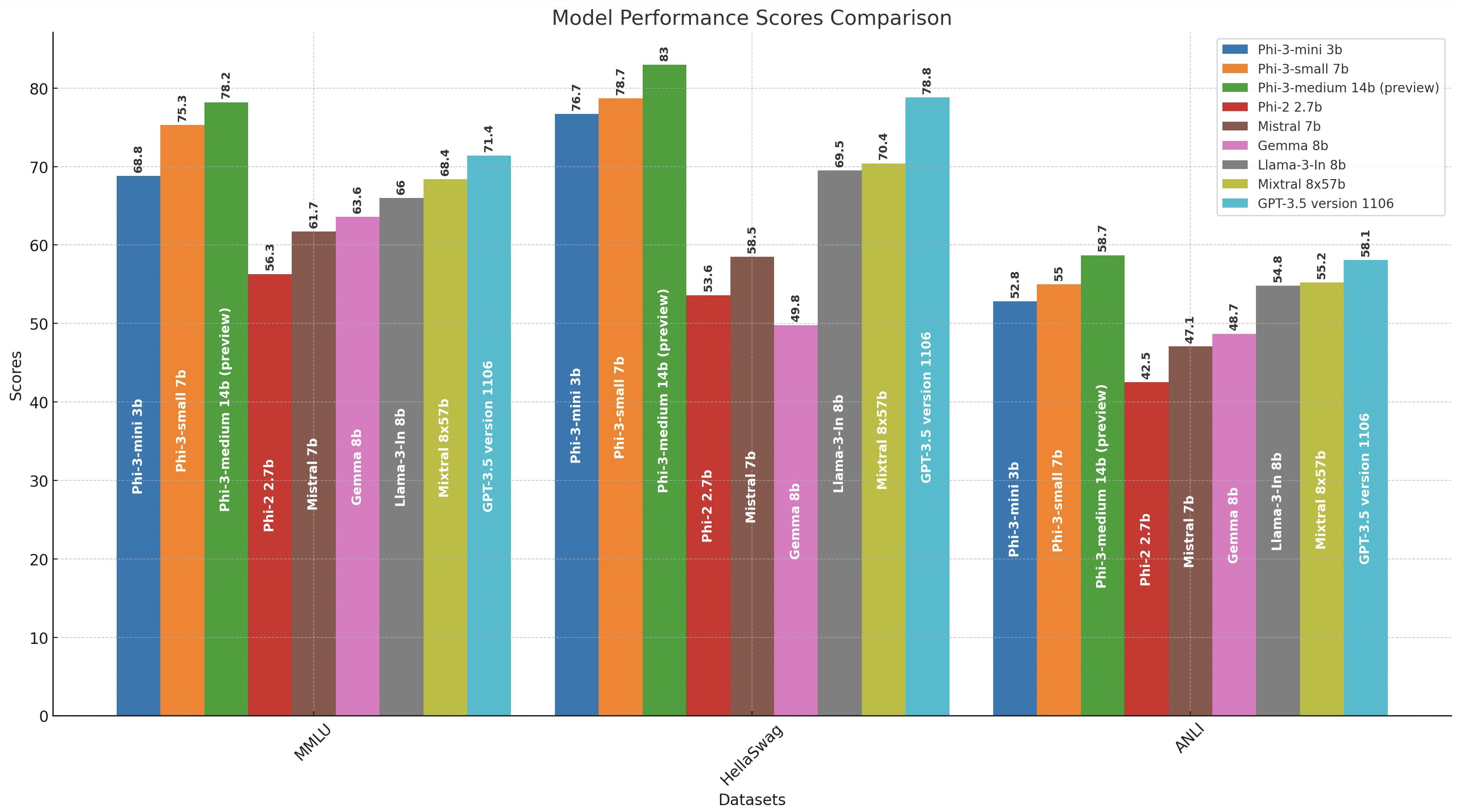
一些直观的数据供参考:
-
Phi-3-mini 在 3.3T token 上进行训练,整体性能与 Mixtral 8x7B 和 GPT-3.5 相当,超越 Llama-3-instruct8b,而Llama-3在15T token上训练,这意味着 Phi-3 数据利用率提高了约4倍;
-
将 Phi-3-mini 模型拓展到 7B (Phi-3-small) 和 14B (Phi-3-medium) 大小,在 4.8T token 上进行训练,两者都比 phi-3-mini 能力更强,例如,MMLU 基准上分别为 75% 和 78%,MT 基准上为 8.7 和 8.9。
面对这样的结果,网友们纷纷表示不敢置信:
Meta 发布 Llama3 不到一周,难以置信微软这么快就发布了 Phi-3,而且看起来很棒!
与此同时,Phi-3-mini 的默认上下文是 4k,但是也引入了一个长上下文版本,拓展到了 128k,称之为 phi-3-mini-128k。
GPT-3.5研究测试:
GPT-4研究测试:
Claude-3研究测试(全面吊打GPT-4):

而上周非常吸睛的 Llama3系列的上下文长度仅为8k,尽管有活跃的社区可以为其实现各种变种,但是难免让人觉得其8k的上下文不够亮眼...不对,Meta或许就是知道大家魔改的热情空前,所以特意留了一点工作量出来:)
这里附上Phi-3系列在20多个基准上的评测结果:
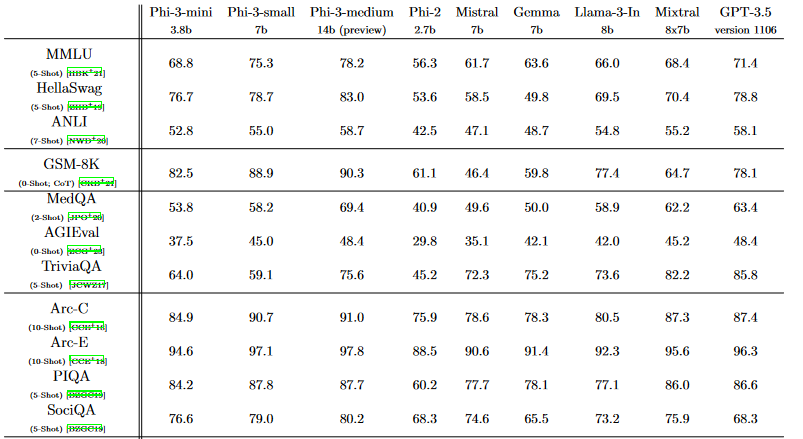
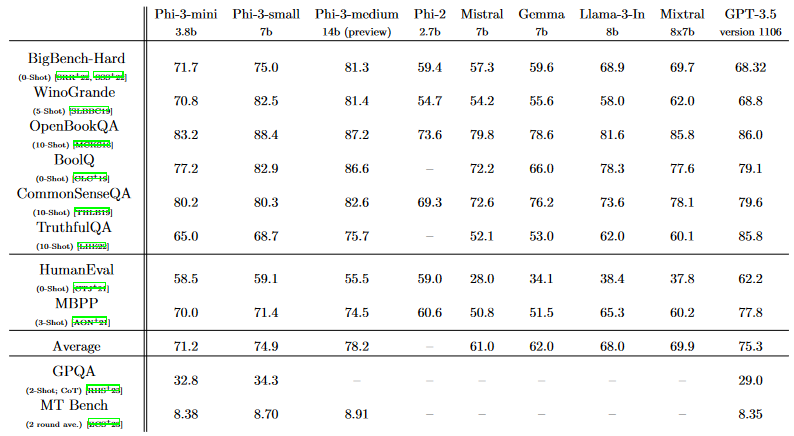
不过,网友们似乎还是不太认可这样的结果:

甚至直言对结果保持怀疑:
Phi-2在 HumanEval 中得到59分?? Llama-3-8b-instruct 也远不止38!

让我恼火的是,当人们发布基准测试结果时,他们经常忽略任何比他们自己的模型表现更好的模型。他们骗不了任何人! 这让人非常反感。我想看看它与更好的模型相比如何,而不仅仅是较弱的模型。
难怪网友们对基准测试的结果越来越不感冒了,毕竟不管各家怎么吹嘘自己的模型,GPT 3.5还是当之无愧的性价比之选,GPT-4更是遥遥领先的标杆。
因此在更全面、足够有说服力的基准测试出来之前,网友们也只能多亲身测试模型的性能惹。
而现在!在huggingface上也可以体验到 Phi-3-mini-4k-instruct 模型啦,赶紧去试试吧,友情提示,使用英文,并且不开启网络搜索的情况下模型还是很不错的!

https://huggingface.co/chat/
当然,网友们对Phi-3系列所用的数据也很感兴趣:

尽管训练数据很少,但Microsoft声称该模型的性能比其前身Phi-2(去年12月发布)要好得多,并且相比参数量更多、训练token数是其5倍的Llama3模型,Phi-3的基准测试的性能具有相当竞争力的,这也能侧面说明数据集的质量确实很高。
不过,对于网友们来说,确实已经见惯了厂商们使用GPT4来处理数据的操作,对于没有公开数据处理流程的厂商来说,这大概率倒是不冤枉hhh:
很高兴看到微软仍然在抄袭OpenAl:他们甚至没有写一个完整的句子来解释他们的数据来源,但是他们引用了他们之前关于GPT-4代码审查的论文。
小型、轻量化的模型是未来吗?
Phi系列模型作为大模型小型化的经典工作,这次更是特别强调其“可以在手机部署”的特性,研究人员称,Phi-3-mini 在 4 bit量化下仅占用约 1.8GB 内存。
研究人员已经在 iPhone 14 上测试部署了 phi-3-mini 量化模型,并使用 A16 Bionic 芯片在设备上本地运行并完全离线,实现每秒超过 12 token的效率!

研究人员甚至还询问了Phi-3为什么(他们)可以在手机上构建性能堪比 ChatGPT 的大语言模型,啊喂你这也太自卖自夸了吧声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

